
基于社会化标注的协同过滤算法
2020-03-27 08:49周康渠
探索科学(学术版) 2020年12期
杨 晨 周康渠
重庆理工大学 机械工程学院 重庆400054
引言
在web3.0时代,互联网用户从信息的消费者转变成了信息的生成者,社会化标注这一自下而上的分众分类方式也逐渐兴起,如图书网站豆瓣读书、图片共享网站Flickr等。这些网站允许用户自主上传资源,对网站上的资源自由添加标签来对资源进行描述,并与网站上的其他用户分享。随着网站上资源的积累,如何为用户找到其感兴趣的资源成为了这些网站面临的一大挑战,而基于一些推荐算法的推荐系统,成为了解决这一问题的主要方法。
协同过滤算法是目前应用最为广泛的一种推荐算法,然而随着网络上资源数量的迅速积累,协同过滤算法常常面临数据稀疏、冷启动等问题。在协同过滤算法中引入语义,可以缓解协同过滤算法所面临的数据稀疏和冷启动问题,是一种有效提高推荐效率的方法。随着社会化标注的进行,形成的标签集对资源的内容或语义进行了揭示[1]。现在已经有了一些利用社会化标注系统中标签间的语义关系来缓解协同过滤算法所面临的数据稀疏和冷启动问题的研究。

1 基于社会化标注的协同过滤算法
本文的算法依据标签共现矩阵以及标注频率建立标签树,结合标签共现矩阵以及标签树结构综合确定标签之间的综合语义相似度,依据资源的标注情况以及标签间的语义相似度来计算资源间的语义相似度,并用资源语义相似度对用户的评分矩阵进行填充,用填充后的用户评分矩阵来找寻用户的邻近用户,从而实现资源的推荐。
1.1 标签树的构建 本文在Paul H 等[4]提出的标签树的构建方法上,依据标签间的相似度以及标签标注的资源数量来实现标签树的构建。标签的相似度计算方法有很多,其中基于标签共现的标签相似度计算是使用的非常多的一种。标签共现是指两个不同标签对于一个相同的资源进行标注,而这种共现关系表明两个标签之间存着某种程度上的语义关系,对于标签相似度大于一定阈值的一个标签对,则认为其存在语义关系。在知识分类体系中,父概念比子概念的内涵更抽象,外延更广泛,在标签间树的构建过程中,即认为父标签会比子标签标注更多的资源。标签树的构建包括以下步骤:数据预处理及标签筛选、建立基于共现的标签相似度矩阵、建立标签树。
1.1.1 数据预处理及标签筛选 由于社会化标注大多是在无监督的情况下进行的,具有不规范性。因此需要对标注数据进行预处理,包括对标注数据中的大小写进行统一,删除不能识别的字符,并对同义词、缩写等进行合并等。在数据预处理后,筛选出用于构建标签树的标签。
1.1.2 建立基于共现的标签相似度矩阵 对于筛选出的标签集合,建立维度为n×n的标签共现矩阵O,n为筛选出的用于构建标签树的标签的个数。
由于两两标签的使用频次会对他们的共现频次产生影响,难以反应两个标签之间真正的语义关系,为了消除标签的热门程度带来的影响,引入Ochiia系数将标签共现矩阵O 转换成标签相似度矩阵,从而反映出标签间的实质性共现关系,计算公式如下:


随着资源数量的增加,用户评价过的资源往往只占资源总量的一小部分,尤其是新用户,因此用户矩阵往往面临数据稀疏的问题。通过引入资源间的语义关系,可以对用户未评价过的资源的评价情况进行预测。
1.2.1 标签综合语义相似度计算 在将标签构建成标签树后,标签之间具有了一定的语义结构。本文使用梁俊杰[5]等提出的语义相似度计算公式来计算标签树中各标签的基于结构的语义相似度。
结合基于共现的语义相似度以及基于结构的语义相似度,来计算标签间的综合语义相似度,计算公式如下:

其中S(i,j)代表标签i和标签j之间的综合相似度,S1(i,j)代表标签i和标签j之间基于共现的语义相似度,S2(i,j)代表标签i和标签j之间基于结构的语义相似度,α为调节系数。
1.2.2 资源语义相似度计算 由于资源的标注情况反应了资源的属性,因此可以依据标注于资源的标签来对资源进行分类,分类步骤如下:
(1)筛选出标注于资源的标签中属于标签树且标注次数大于阈值的标签,组分该资源的分类标签集。
(2)若筛选出的标签在标签树中为父子节点,则选择在标签树中层级最深的标签作为该资源的类。
资源分类后,按照资源的分类结果计算资源间的语义相似度,计算公式如下。

3 算法验证
3.1 实验数据 实验采用Movielens的电影-评分数据集中用户对于电影类目为Sci-Fi的电影的评分,由于要通过电影资源的社会化标注信息来对电影资源进行分类,因此筛选出213个被标注次数大于10次的电影资源,并筛选出进行评分次数大于10次的3047个用户。即实验数据集中包含3047个用户对于213个电影资源的99364条电影评分,评分分数为1~5分。将其中80%的数据用作训练集,20%的数据用作测试集,验证本文算法。

其中N 为预测的资源评分集合,pi为该资源的预测评分,ri为该资源的实际评分,lenth(N)为集合N的长度。
3.3 实验结果 为了验证本文算法的效果,选取传统的基于用户的协同过滤算法与本文算法进行比较。图1是当最邻近值K取不同值时各算法MAE的大小对比。
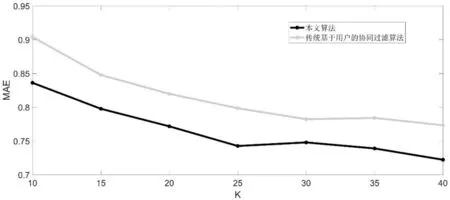
图1 K取不同值时各算法MAE的大小比较
由实验结果可知,无论K 取何值,本文的算法的MAE值要远低于传统基于用户的协同过滤算法。这表明本文算法能有效缓解数据稀疏何问题,从而提高推荐效果。
4 结语
本文提出了一种基于标签共现和标注频率建立标签树的方法来挖掘标签间的语义关系,并通过资源的标注情况以及标签间的语义关系来确定资源间的语义关系,并将这种语义关系与传统的协同过滤算法相结合,来对用户评分矩阵进行填充的推荐算法。通过在Movielens数据集上对本文提出的算法进行验证,实验结果证明本文提出的算法能够有效提高推荐效果。但本文算法也存在一定的局限性,一方面在标签语义挖掘的过程中标签可能会存在一词多义的问题,后续可以与连边社团检测算法进行结合。另一方面本文只考虑了资源间的语义相似度,而用户之间也存在语义相似度,后续可以综合考虑用户和资源的语义相似度来对算法进行进一步改进。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
大众投资指南(2021年23期)2021-12-06
今日农业(2021年15期)2021-11-26
少先队活动(2021年5期)2021-07-22
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
长江学术(2016年4期)2016-03-11
体育科技(2016年2期)2016-02-28
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
