
基于人工嗅觉系统的土壤有机质检测方法研究
2020-04-01 08:11朱龙图李名伟夏晓蒙黄东岩贾洪雷
农业机械学报 2020年3期
朱龙图 李名伟 夏晓蒙 黄东岩 贾洪雷
(1.吉林大学生物与农业工程学院,长春 130022;2.吉林大学工程仿生教育部重点实验室,长春 130022)
0 引言
土壤有机质是指土壤中各种含碳有机物,包括植物和动物残体、土壤生物的细胞和组织,以及这些生物残体不同阶段的分解物质[1],它是土壤肥力和养分的重要指标。土壤有机质对土壤的阳离子交换能力、土壤结构、水分入渗率、持水能力、土壤的可蚀性和保持性、农药吸附等理化、生物特性有很强的影响[2]。因此,测量土壤有机质含量、掌握其动态变化对改善土壤结构和指导农业生产具有重要意义。
目前,测量土壤有机质含量的方法有重铬酸钾容量法、CO2检测法和灼烧法等[3]。其中,重铬酸钾容量法因测量结果准确、适用于批量测量而被广泛使用,也是我国测量土壤有机质含量的标准方法。然而,该方法需要在实验室进行分析处理,存在操作复杂、耗时长、成本高和破坏性大的缺点[4]。因此,对快速、经济、无损、准确的土壤有机质含量预测方法的需求越来越大[5]。近年来,由于近端土壤遥感技术的普遍应用,可见光和近红外(Vis-NIR)漫反射光谱法受到关注,并被认为是一种可行的土壤分析方法[6-10]。光谱分析法虽然准确,但其缺点是易受土壤粒度、土壤湿度和氧化铁的影响[11-13]。
土壤中气体的产生和消耗主要与土壤中的微生物活动过程有关[14],而土壤有机质是土壤微生物生命活动所需养分和能量的主要底物[15]。在微生物的降解过程中,养分和能量的供应底物在土壤中产生许多挥发性有机化合物(Volatile organic compounds,VOCs)和气体[14]。因此,土壤中的VOCs和气体必然与土壤有机质存在某种相关性,这种相关性为土壤有机质的快速、低成本检测提供了可能。气体检测成本很低,尤其是基于固态化学传感器的检测[16]。然而,土壤气体的组成成分复杂[17],采用单一的气体传感器对其识别很困难。由金属氧化物半导体(Metal oxide semiconductor,MOS)气体传感器阵列和模式识别组成的人工嗅觉系统(又称为电子鼻)被认为是实现复杂气体检测的有效手段。虽然人工嗅觉系统不会给出任何关于挥发性气体化合物的具体信息,也不会给出它们的特性[18],但是借助适当的模式识别算法,人工嗅觉系统可以识别特定样本的气体模式,进而将不同样本区分开来[19-20]。目前,人工嗅觉系统在食品和饮料、医药、环境保护、工业生产和军事等领域有着广泛的应用[21-24],且在土壤特性检测方面也有研究报道。例如,LAVANYA等[25]应用电子鼻测量了土壤中腐植酸和黄腐酸的含量,ANDRZEJ等[26]采用电子鼻评估了土壤湿度状况。但电子鼻(或称人工嗅觉系统)在土壤有机质含量方面的检测却鲜有文献报道。
针对上述问题,本文提出一种基于人工嗅觉系统的土壤有机质检测方法。首先,采用10个由不同温度控制的MOS气体传感器构建检测阵列;然后,以此阵列获取土壤挥发性有机化合物的响应曲线;通过提取曲线上的最大值、最小值、平均值、平均微分系数、响应面积、第30秒的瞬态值以及第60秒的瞬态值等7个特征来构建嗅觉特征空间;最后,对特征空间优化后,采用回归算法建立预测模型。
1 土壤样品采集及特征空间构建
1.1 研究区域及土壤样品
本研究126份土壤样品采集于吉林省各个地区,采样点分布如图1所示。

图1 研究区域及采样点分布图
吉林省地貌差异明显,地势由东南向西北倾斜,呈现东南高、西北低的特点。吉林省的主要土壤类型为暗棕壤、黑钙土、白浆土、草甸土和黑土,主要种植作物玉米、大豆、小麦。由于频繁的耕作导致土壤退化,施用化肥成了农业生产不可或缺的选择。因此,研究土壤特性有助于优化施肥、改良土壤结构。采样时间为2018年秋季,采样前除去杂物和浮土,采样深度为5~20 cm。每个样品以S形布点采样,一个样点采集11个点位的土壤,均匀混合后,挑出落叶、秸秆和石块,然后用“四分法”保留1 kg土壤样品。根据试验需求,将每个土壤样品分成两份,一份用于化学测量分析,另一份用于人工嗅觉分析。化学测量分析所用的各个土壤样品经标记后送往实验室,24℃无风自然条件下风干。人工嗅觉分析所用的土壤样品通过喷施蒸馏水和风干的方法使各样品的相对湿度为65%,然后分别称取80 g置于250 mL的密闭集气瓶内,之后将集气瓶存放在通风良好的黑暗房间里24 h。
1.2 土壤样品化学分析
用于化学分析的各土壤样品,经自然干燥、研磨、过0.25 mm筛网处理后,采用重铬酸钾容量法测量。测量结果采用SPSS 13统计描述,结果如图2所示。图2中,土壤样品的有机质质量比范围为10.62~48.79 g/kg,均值为23.44 g/kg。土壤有机质含量的变异系数(Variable coefficient,CV)为32.17%,说明样本有机质含量分布呈现出较大的空间变异性。K-S检验值是0.224(P>0.05),表明样本数据服从正态分布。

图2 土壤有机质含量统计性描述结果
1.3 人工嗅觉系统结构及工作原理
人工嗅觉系统主要由传感器阵列、信号处理模块、数据采集卡和计算机等构成,如图3所示。其中,传感器阵列采用单类传感器阵列,即由多个型号相同传感器构成。检测阵列由10个SGAS707型传感器构成,放置在密闭测试盒内。SGAS707型传感器是美国集成设备技术公司(Integrated Device Technologies,Inc.,IDT)生产的一款用于检测VOCs的专用MOS气体传感器,其内部集成了一个加热电阻,可进行温度调制,能为传感器提供不同的工作温度。传感器阵列通过FFC软线与信号处理模块相连接。数据采集卡通过杜邦线连接信号处理模型的输出接口,用于实时采集传感器的输出值Vout,并将采集到的数据传输到计算机。信号处理模块包括了温度调制电路和测量输出电路,如图4所示。

图3 人工嗅觉系统装置

图4 信号处理模块
图中Vheat为加热电阻的供电电压,通过一个三端电压调节器LM317对其进行调制,进而为传感器提供一个恒定工作温度。调节电阻PR1,可以改变Vheat。在测量单一组分挥发性气体(如辛烷、甲醛和异丁烯等)时,IDT公司推荐SGAS707型传感器的最优工作温度为150℃。然而,诸多研究[27-29]已经证实,MOS气体传感器在不同的工作温度下,其对不同组分气体分子的吸附能力不一样。因此,通过温度调制可以提高传感器阵列对混合气体的检测灵敏度。为了提高单类传感器阵列对复杂土壤气体的选择性以及灵敏性,本文采用不同的Vheat对SGAS707型传感器的工作温度进行差异性调制。设计中,10个传感器的Vheat分别设置为1.25、1.50、1.75、2.00、2.25、2.50、2.75、3.00、3.25、3.50 V。
系统工作时,先启动测试按钮,然后采用氦气清洗密闭测试盒,待传感器阵列输出值稳定后,停止洗气并关闭测试按钮;接着,再使用一个20 mL的注射器抽取集气瓶顶部的土壤气体,并通过密闭测试盒上面的注射孔快速转移至密闭测试盒内,同时开启测试按钮。当采样时间到达100 s时,停止采样,并重新用氦气清洗密闭气室,以便进行下次测量。一般情况下,较高的采样频率更能反映传感器的响应,但会增加后期数据处理的难度,而较低的采样频率会造成关键数据的丢失。测试过程中,采样频率设置为10 Hz。
人工嗅觉系统测量土壤VOCs的典型响应曲线如图5所示(以土壤有机质质量比为27.95 g/kg的土壤样品为例)。图中S1~S10分别为10个传感器编号。从图5可以看出,10 Hz的采样频率能够有效地获得传感器的响应变化曲线,确保了适宜的数据量。此外,不同温度控制下的传感器对土壤VOCs的响应不同,表现出特定的选择性和灵敏性。然而,在传感数据测量中,由于外部环境变化、测量系统本身误差,响应曲线将不可避免产生一些毛刺。

图5 传感器响应曲线
为了消除毛刺的不利影响,采用一维中值滤波算法对系统输出响应曲线进行平滑处理,并设置平滑点数为30。图6为滤波后的响应曲线。为减少后期数据处理难度、加快预测模型测量效率,本研究选取测量开始后的前60 s数据作为分析区域。

图6 滤波后的传感器响应曲线
1.4 特征提取
从传感器响应曲线上提取恰当的特征构建嗅觉特征空间是建立预测模型的前提条件。常用的特征提取方式包括[30]:最大值(Maximum value)Vmax、最小值(Minimum value)Vmin、平均值(Mean value)Vmean、平均微分系数(Mean differential coefficient value)Vmdc、响应面积(Response area value)Vra、时刻t的瞬态值Vt和稳态值Vs等。本研究在提取的数据分析区域采用Vmax、Vmin、Vmean、Vmdc、Vra、第30秒的瞬态值V30和第60秒的瞬态值V60这7个特征来构建特征空间。其中,Vmdc和Vra的计算式分别为
(1)
(2)
式中Di——第i个采样数据,V
N——Di的个数
Δt——采样间隔时间,s
经过特征提取后,每个传感器响应曲线上的7个特征将被提取,而传感器阵列由10个传感器构成。因此,一个样品将被提取70个特征,所有土壤样品将形成一个126×70的嗅觉特征空间。为了消除量纲和数量级对特征的影响,采用z-score方法对选取的特征进行标准化处理[31]。
1.5 训练集与测试集划分
为建立一个适当的预测模型,需要将嗅觉特征空间划分为训练集和测试集两部分。训练集可用于训练模型,测试集可以对模型预测性能进行测试。合理的划分训练集和预测集有利于模型性能提升,采用Kennard-Stone算法给出的较为合理的划分比例[32],即训练集和测试集之比为7∶3。
2 模型构建方法
2.1 PLSR模型
主成分因子(Principal component factor,PCF)数量是造成PLSR模型过拟合或欠拟合的主要因素。本研究采用留一交叉验证法结合赤池信息量(Akaike information criterion,AIC)准则来判断最优PCF数量。其中,赤池信息量(AIC值)计算公式为
AIC=MlgPrss+2p
(3)
式中M——训练集样本数目
Prss——训练集样本的预测残差平方和
p——PCF数量
2.2 SVR模型
SVR是一种基于支持向量机(Support vector machine,SVM)的回归技术[33]。LIBSVM工具箱提供了两类回归方法:ε-SVR和ν-SVR。本研究采用ε-SVR建立回归模型,应用径向基函数(Radial basis function,RBF)作为核函数。惩罚因子c(c>0)和内核参数g是影响SVR建模的两个主要参数。本文为了优化SVR模型,采用网格搜索法和5-折交叉验证法,并结合交叉验证均方误差(Mean square error of cross-validation,MSECV)来确定参数组合(c,g)的值。MSECV越小,参数c和g的组合越佳。
2.3 BPNN模型
BPNN是一种典型的多层前向型神经网络。本文采用3层网络构建BPNN模型,隐含层最优神经个数计算公式为
(4)
式中h——隐含层神经元节点数
n——输入节点数
m——输出节点数
α——1~10的正整数
其中,n等于用于建模的特征向量数量,m为预测因变量数量,本文只对有机质含量作预测,所以m为1。
为了确定BPNN模型隐含层神经元节点数h,首先根据式(4)确定h的范围,然后基于h的每一次不同值在训练集上分别训练10个不同的BPNN模型,并计算这10个BPNN模型对训练集样本的预测均方根误差(Root mean square error,RMSE)的平均值,记为MRMSE,最后根据MRMSE来确定h值。MRMSE越小,对应h值用于建模的效果越好。
在BPNN建模及h的优选中,隐含层神经元的激活函数选用S形传递函数tansig,输出层神经元的激活函数采用线性传递函数purelin,并且设置训练的迭代1 000次,学习率为0.01,目标误差为0.001。
2.4 模型评价指标
土壤养分预测模型的常用评价指标有决定系数(Coefficient of determination)R2、均方根误差(RMSE)和预测偏差比(Ratio of prediction derivation,RPD)。R2越接近1表明模型的拟合效果越好;RMSE用于表征模型预测值和测量值之间误差,RMSE越小,表明模型的预测精度越高。RPD是样品标准差与预测均方误差之间的比值,用于对模型性能进行进一步评价。一般RPD越大,模型性能越好。RPD在土壤检测方面,可分为3个等级[34]:A级(RPD大于等于2.0)表示模型性能非常好,可以进行准确的定量检测;B级(RPD大于1.4小于2.0)表示模型一般,可进行较为粗略检测;C级(RPD小于等于1.4)表示模型性能很差,不可用于定量检测。
3 结果与分析
3.1 初步建模评估结果
根据Kennard-Stone分配方法,可以将126个土壤样品的嗅觉特征空间分成两部分,即前88个样本数据作为训练集,剩余的38个样本数据用作测试集。分别构建PLSR、SVR和BPNN预测模型,并采用训练集对各模型的建模参数进行优化。PLSR模型的参数PCF可通过AIC随PCF数量变化曲线来确定,如图7a所示。最优的PCF数量可以根据较小的AIC值来确定。但是当PCF数量选择过大时,会使模型的复杂度增加。因此,从图7a可以看出,将PFC数量设为3用于构建PLSR模型较为适宜。SVR模型的参数组合(c,g)经网格搜索法和5-折交叉验证法优化后,可设为c=2,g=0.015 6,如图7b所示。建立BPNN模型时,较小的MRMSE更有利于优选出合适的隐含层神经元节点数。因此,根据图7c,可将BPNN建模的隐含层神经元节点数设定为10。在确定各预测模型的最佳建模参数后,分别构建PLSR、SVR和BPNN模型,并用训练集对各模型进行训练,同时采用测试集对模型进行预测。预测结果如图8所示。

图7 各模型的建模参数优选结果
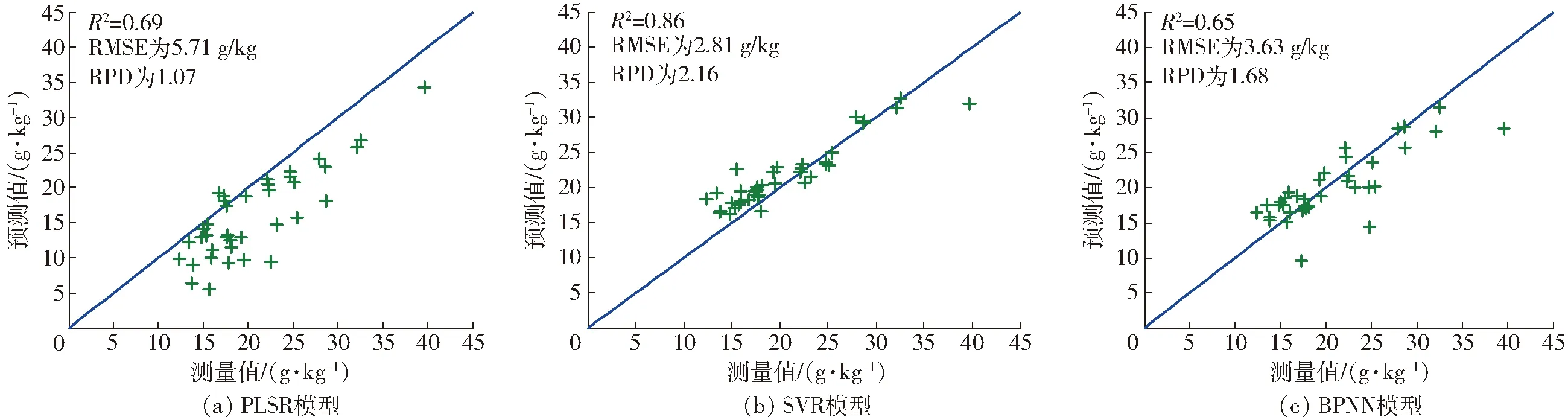
图8 各模型预测结果
图8显示3种模型的R2分别为0.69、0.86和0.65;RMSE分别为5.71、2.81、3.63 g/kg;RPD分别为1.07、2.16和1.68。这表明,土壤嗅觉特征空间与土壤有机质含量之间存在一定的相关性。但是,土壤嗅觉特征空间并没有得到充分的优化,因此需要进一步的分析来确定是否存在其他干扰。嗅觉特征空间的优化主要包括异常样本剔除和特征降维这两种处理。它可以消除异常样本和冗余特征对模型的干扰,达到准确建模、预测的目的。
3.2 异常样本剔除结果
异常样本产生的主要原因可能是操作不当、人工嗅觉系统本身的误差或温度、湿度等外部因素。异常样本对模型的预测精度具有重大影响。因此,有必要对异常样品进行识别和去除。MCS方法是基于预测误差(或者预测残差)对异常样本的敏感性而提出的,被证明是一种有效的异常样本剔除方法[35]。

图10 去除异常样本后各模型的预测结果
本文采用MCS对嗅觉特征空间的异常样本进行检测,具体步骤如下:首先,在嗅觉特征空间中随机选择70%的样本作为训练集,剩余30%的样本用作验证集;其次,基于训练集数据计算PLSR的最佳主成分因子数,并构建PLSR预测模型;之后,应用构建的PLSR预测模型对验证集进行预测,并计算验证集样本的预测残差;然后,重复上述过程进行多次循环采样,可获得所有样品的预测残差分布;最后,计算各样本预测残差的平均值(Average value,AVG)和标准偏差(Standard deviation,STD),并根据AVG-STD分布图检测异常样本。
图9为采用MCS方法得到的AVG-STD分布图。在运行MCS方法时,将循环采样次数设定为5 000次。图中结果表明,1、2、22、64、32号样本属于离群点,可视为异常样本。这是因为这几个样本不稳定,也不适用于基于其余样本构建的模型。

图9 预测残差平均值与标准差的关系
去除这5个异常样本后,首先按照前文所述方法重新划定训练集和测试集,此时训练集包含85个样本数据,测试集包含36个样本数据。之后,再基于新的训练集重新优化各模型的建模参数,得到PLSR的PFC为4,SVR的参数为c=4.12和g=0.011 8,BPNN的隐含层神经元节点数为12。然后,再次建立新的PLSR、SVR和BPNN预测模型,测试集的预测结果如图10所示。图10显示3种模型的R2分别为0.75、0.89和0.84;RMSE分别为5.68、2.74、3.15 g/kg;RPD分别为1.09、2.29和1.97,优于去除异常样本前预测结果。
3.3 PCA降维结果
特征向量是影响模型性能的另一个重要因素,这是因为原始特征空间中包含了大量的与建模无关的冗余信息。采用未降维的特征空间直接建立模型将导致较大的计算量,并且会干扰模型的预测精度。主成分分析(PCA)是一种较通用的特征降维方法[36],其通过计算原始特征空间的协方差矩阵的特征向量,将高维空间向量线性变换为分量不相关的低维空间向量。为了优化土壤嗅觉特征空间,本研究采用PCA方法作为特征降维手段,步骤如下:①计算嗅觉特征空间的协方差矩阵。②求出协方差矩阵的特征值及其对应的特征向量,并根据特征值的大小对特征向量进行排序,得到特征向量矩阵。③选择特征向量矩阵的前k(1≤k<70)个向量,则可将原始的嗅觉特征空间降为k维,其中k即为主成分数,可通过方差信息累计贡献率G(k)来确定,计算公式为
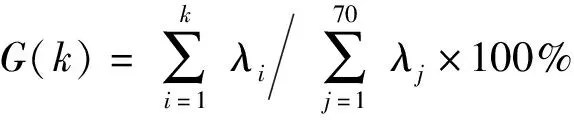
(k=1,2,…,69)
(5)
(6)
式中λi——协方差矩阵第i(i λj——协方差矩阵第j(j≤70)个排序后特征值 αi——第i个主成分的方差信息贡献率 当G(k)大于一个设定的值时,可得到一个降至k维矩阵。 为了获取PCA对特征空间的优化结果,对去除异常样本的土壤嗅觉特征空间(121(样本)×70(维特征))采用PCA方法降维,并设置G(k)为95%,得到如图11所示结果。从图11可以看出,当主成分数k为2时,G(k)大于95%,表明采用2个主成分基本能够反映原来特征空间的大部分信息。采用经PCA降维后的特征空间数据分别对新建立的PLSR、SVR和BPNN模型进行训练与测试,得到各模型的预测结果如图12所示。图中,PLSR的最优建模参数PFC为2,SVR的最优建模参数分别为c=104.2和g=0.000 2,BPNN的最优隐含层神经元节点数为14。图12显示,3种模型的R2分别为0.86、0.91和0.85;RMSE分别为2.49、2.05、2.68 g/kg;RPD分别为2.49、3.02和2.32。 图11 PCA主成分累计贡献结果 图12 PCA降维后各模型的预测结果 图8、10、12分别显示了嗅觉特征空间优化前后,不同测定算法所建模型的预测效果。为了更直观地对比分析,将各模型的性能评价指标列于表1。从表1可得出,与未优化前模型性能相比,经MCS方法剔除异常样本后,PLSR、SVR和BPNN模型的R2分别提升了8.7%、3.5%和29.2%,RMSE分别降低了0.5%、2.5%和13.2%,RPD分别提升了1.9%、6.0%和17.3%。由此可见,所有模型的性能指标均得到了提升,这说明MCS方法能有效地检测出异常样本。 在剔除异常样本的基础上,进一步应用PCA方法对特征空间降维,结果表明PLSR、SVR和BPNN这3种模型预测性能得到了更进一步的提升。其中R2再次提升了14.7%、2.2%和1.2%;RMSE再次降低了56.2%、25.2%和14.9%;RPD再次提高128.4%、31.9%和17.8%。 表1 模型性能对比结果 如果在未优化的特征空间上直接建模、训练和预测,根据土壤性质RPD的分类方法,只有SVR模型具有较好的预测性能,属于A级(RPD为2.16);BPNN模型属于B级(RPD为1.68),预测性能一般,但其拟合效果(R2=0.65)较差;而PLSR的预测等级为C级(RPD小于1.4),表现出较差的预测性能。经异常样本剔除、特征降维后,PLSR、SVR和BPNN等3种模型预测等级均达到了A级(RPD大于2.0),这表明异常样本和冗余特征信息对模型预测性能有很大的影响。在优化后的特征空间上建模,3种模型的预测指标R2均不小于0.85,表现出较强预测性能。然而,SVR的预测能力(R2=0.91、RMSE为2.05 g/kg、RPD为3.02)明显高于PLSR和BPNN,而PLSR的预测性能略优于BPNN。这可能因为SVR是基于结构风险最小化的模型,其对数据规模和数据分布的要求比较低,具有优异的泛化能力[37]。此外,结合网格搜索法和5-折交叉验证法来优化选取SVR参数在一定程度上也提升了SVR的学习能力。 (1)提出了一种基于人工嗅觉技术的土壤有机质含量检测方法,结合蒙特卡罗抽样(MCS)和PCA特征降维两种手段,实现了土壤嗅觉特征空间的优化。采用PLSR、SVR和BPNN等3种回归算法,构建了土壤嗅觉特征空间与土壤有机质含量之间的关系模型。模型预测结果表明,这3种预测模型对土壤有机质含量均有较高的预测能力,其中SVR模型的预测性能最好,可对土壤有机质含量进行准确预测。 (2)采用人工嗅觉技术测量土壤有机质含量是可行的。考虑到研究区域的土壤样本具有较大的空间变异性,因此可以认为该测量方法是稳健的。研究结果可作为土壤有机质含量检测的一种参考方法。

3.4 比较分析

4 结论
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
初中生世界·九年级(2020年2期)2020-04-10
故事作文·高年级(2019年6期)2019-06-20
电子制作(2018年17期)2018-09-28
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
Coco薇(2016年8期)2016-10-09
西南学林(2011年0期)2011-11-12
