
基于ARIMA时序算法的车站人流密度预测模型
2020-04-06 09:25赵天成王玉潇王国臣
数字通信世界 2020年3期
赵天成,王玉潇,王国臣
(山东科技大学,泰安 271000)
1 基于ARIMA时间序列算法的人口流量密度预测模型
现如今,经济水平的提高和人口的增长使得公共场所的拥挤问题日益严重,而易拥堵点人流的监控也逐渐成为城市规划的重点,而现有的人口密度检测多采用像素法,人口密度的预测多采用简单的线性拟合预测,检测成本高,预测精准度差,为解决这类问题,我们设计并完善了一种基于ARIMA时间序列算法的人口流量密度的预测模型,并运用于公共汽车站人口流量密度预测和相关车辆的宏观调度问题的解决,进而反作用于车辆到站时间和最优路线变化,实现公交车的“智慧调度”。
2 ARIMA模型的建立与求解
2.1 ARIMA模型的建立
根据泰安市某一站点的人流数据,剔除噪声数据后,划分为数据集与测试集,并加入每日的天气情况、温度变化、道路拥堵程度等指标建立ARIMA模型对车站人流量进行预测。首先,我们建立了ARIMA预测模型[1],具体的建模过程如下:
(1)对获取的数据进行预处理。
(2)将非平稳序列转变为平稳序列。如果序列是非平稳的,使用一阶或者多阶差分的方法对数据进行平稳化处理,如果数据有噪声值,则需进行数据预处理,直到数据的自相关系数和偏相关系数值都异于零。
(3)依据时间序列的识别准则,建立时间预测模型。
(4)进行参数估计,检验是否具有统计学意义。
(5)进行假设检验,诊断残差序列是否为白噪声。
(6)利用已通过检验的模型进行预测分析。
为了直观地了解ARIMA的预测过程,我们绘制了如图1所示。

图1 ARIMA预测流程图
ARIMA预测模型的先对非平稳的指标数据Yt进行d次差分处理,然后再将原d次差分进行还原,最红可以得到Yt的预测数据。ARIMA(p,q)的一般表达式为:
Xt=φtXt-1+…+φpXt-p+εt-θ1εt-1-…-thetaqεt-q,tε
式中,非负整数p为自回归阶数,φ1,…,φp为自回归系数,左式为自回归部分,右式为滑动平均系数,Xt为变量数据的序列。
当q=0时,模型成为AR(p)模型:
Xt=φtXt-1+…+φpXt-p+εt,tε
当p=0时,模型成为MA(q)模型:
Xt=εt-θ1εt-1-…-θpεt-p,tε
对以上建模过程有了初步了解后,我们进行了详细建模,具体过程如下:
2.1.1 ARIMA模型的识别
通过计算预处理后的系列Xt的自相关函数(ACF)pk和偏自相关函数(PACF)pkk来进行模型识别,具体的计算公式为:
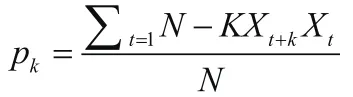
φ11=p1
φk+1,k+1=(pk+1-∑j=1kpk+1-jφkj)(1-∑j=1kpjφkj)-1
根据上述计算结果,可以确定符合Xt的具体模型。
2.1.2 参数估计和模型定阶
参数估计和模型定阶是建立变量预测模型的重要内容。在ARIMA模型的基础上,利用最小二乘法对ARMA(p,q)的自回归系数、滑动平均系数以及白噪声方差等进行估计,得出φ1,…φp,θ1,…,θq,σ2。
我们利用AIC、BIC准则进行模型定阶,首先要检验所建立模型是否能满足平稳性和可逆性,即要求下式根在单位圆外,具体公式如下:
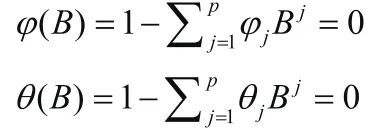
通过上式进一步判断上述模型的残差序列是否有白噪声,如果是,则通过检验,否则,需要重新进行模型的识别。
2.1.3 变量值预测
根据前面建立的预测模型,使用进一步预测的方法对Xt进行预测,并考虑dci差分以及还原为变量Yt的预测结果。
2.2 ARIMA模型的求解
下面介绍对车站人流量的预测过程,首先,我们利用Python将该车站的人流数据和天气等因素指标数据导入,并转换为列表数据。为初步了解数据,我们绘制了如图2所示的人流情况变化图。
通过变化图我们发现,车站人流密度在一定范围内上下波动,但因为ARIMA模型对时间序列的要求是平稳性,而通过变化图发现该趋势并不平稳,因此我们对该数据进行了差分处理,得到一阶差分后的数据如图3所示。

图2 人流密度变化图

图3 一阶差分图
为了得到最好的差分效果,我们绘制了二阶差分图与一阶差分图进行对比,二阶差分图如图4所示。

图4 二阶差分图
通过二阶差分图与一阶差分图的对比,我们发现二者差距不大,为了计算的方便性,我们取一阶差分结果进行下面的分析。
我们绘制了平稳时间序列的自相关和偏自相关图,得到如图5所示结果。

图5 自相关和偏自相关图
通过图5可知,自相关图显示有两阶超出了置信范围,偏相关图1到2阶滞后,超出了置信范围,因此我们考虑了三类模型,并利用三种准则进行了验证[2],得到如表1所示结果。
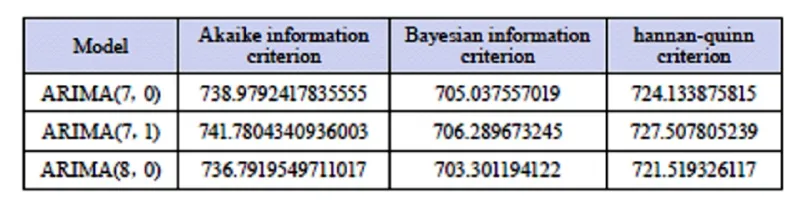
表1 模型比较
可以看到ARMA(8,0)的aic,bic,hqic值均最小,所以选择该模型。
2.3 模型检验与预测
确定模型后,我们进行了DF检验,得到的结果为2.00716981985,接近于2,所以无自相关性。
接下来我们利用Q-Q图检验该模型是否符合正态分布,结果如图6所示。

图6 正态分布图
通过图6可以看出该模型符合正态分布。
明确我们得到了较好的模型后,我们利用Python进行了模型的预测,得到了如图7所示结果。

图7 模型预测图
通过图7预测的数据可以看到,在接下来的时间序列中,此车站人流密度仍处于平稳状态,呈现先上升后下降再上升的变化趋势,但波动程度较小,说明随着时间的增加,车站人流逐渐趋于稳定。
我们利用python通过划分训练集与测试集,取一部分测试数据与预测的人流密度进行比较,对测试数据与车站人流密度简化后作比较得到模型准确率。模型优化前预测值的准确率为0.8137254901960784,预测准确率较高。
2.4 模型优化
为了更进一步对我们的模型进行优化,提高车站人流密度的预测精度,我们建立了基于k-means聚类的ARIMA组合模型。
2.4.1 聚类分析
通过对数据的观察与筛选后,我们使用k-means聚类算法[3]对筛选后的数据集进行了研究分析,首先要确定聚类算法中类的种数k,我们使用了手肘法和轮廓系数法,具体过程如下:

图8 手肘图
(1)手肘法。我们让k值从1开始取值直到取到10,对每一个k值进行聚类并且记下对应的SSE,然后画出k和SSE的关系图,最后选取肘部对应的k值作为我们的最佳聚类数,利用python得到图8所示结果。
由图8可知肘部对应的k值为3,故对于数据集的聚类而言,最佳聚类数应该选3。
(2)轮廓系数法。该方法的核心指标是轮廓系数,某个样本点xi的轮廓系数定义如下:

式中,a是xi与同簇的其他样本之间的平均距离;b是xi与最近簇中所有样本的平均距离,称为分离度。同样对k值从1到10取值,得到聚类数k与轮廓系数的关系如图9所示。

图9 轮廓系数图
可以看到,轮廓系数最大的k值仍然是3,这表示我们的最佳聚类数为3。在手肘图中k的值也为3,因此最终选取k值为3进行聚类分析。
在进行聚类分析之前,我们先对数据集中的数据进行标准化,取k值为3,最大循环次数为500,利用sklearn.cluster包中的KMeans方法进行聚类,统计出各个类别的数目,其中编号为0的类包含197条数据,编号为1的类包含283条数据,编号为2的数据包含67条数据,并生成新的聚类分类表附件二,接下来我们找到聚类的中心点,进行横向连接,得到聚类中心对应的类别下的数目,并重命名表头,为了方便对数据进行操作,我们利用TSNE方法对数据进行了降维操作,对不同的数据进行格式转换,最终利用matplotlib库中的plot方法做出了可视化的聚类图像,见图10。
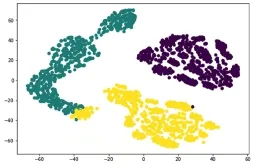
图10 聚类结果
由图10结果显示,聚类结果分离度较好,我们分析了聚类算法生成的附件二,对每一类的数据分别进行了预测,发现每一类的预测精确率均达到了85%以上,其中类别编号为1的类预测准确率为0.8921568627450981,因此可以应用基于k-means聚类的ARIMA组合模型进行评估。
3 结束语
本文在优化人口流量密度预测的算法上,从整体非线性变化、周期性变化、特殊值处理和误差消除几个方面完善预测结果的准确性,相较于传统方法,自主性和准确性更高,成本更低,再结合k-means聚类算法,实现算法的动态更新,完美解决了公交车站点车次调度问题,进而可以优化乘客对相关车次的到站时间和最优路线更改,实现“智慧公交”。具有较大的市场需求和广阔的应用前景。
猜你喜欢
数学杂志(2022年5期)2022-12-02
湘潭大学自然科学学报(2022年2期)2022-07-28
新世纪智能(数学备考)(2021年5期)2021-07-28
医学食疗与健康(2021年27期)2021-05-13
现代临床医学(2021年2期)2021-03-29
现代计算机(2018年27期)2018-10-25
雷达学报(2017年6期)2017-03-26
婚育与健康(2016年12期)2016-12-29
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
