
防止暴露位置攻击的轨迹隐私保护
2020-04-09 14:49刘向宇陈金梅夏秀峰ManishSingh宗传玉
计算机应用 2020年2期
刘向宇,陈金梅,夏秀峰,Manish Singh,宗传玉,朱 睿
(1.沈阳航空航天大学计算机学院,沈阳110136;2.惠灵顿理工学院信息与商科学院,新西兰下哈特5010)
0 引言
近年来,随着定位技术和位置感知设备的发展,移动用户的位置和轨迹信息被大量地收集和发布。对于轨迹信息的挖掘和分析,产生了许多新型的应用。例如,通过分析特定区域中用户的轨迹信息可以帮助投资者进行商业决策,比如在哪里建立商场;同时,政府机构可以通过分析城市中的车辆轨迹来优化交通管理系统和交通路线的设计,发现不合理的道路规划。虽然发布轨迹信息在与其相关的决策和应用中发挥了极大的作用,但是也存在着严重的个人隐私泄露威胁,如果恶意攻击者获取到轨迹信息,就可以通过数据挖掘技术获取到用户轨迹数据中的隐私信息:家庭住址、工作单位、兴趣爱好、生活习惯和健康状况等,将给用户带来严重后果[1-2]。因此,对轨迹信息的隐私保护受到了国内外学者的广泛关注。
目前轨迹隐私保护技术大致分为三类:假轨迹、轨迹泛化和轨迹抑制。其中,假轨迹隐私保护方法具有机制简单、计算量小、不需要可信的第三方实体,且能保留完整的轨迹信息等特点,在实际研究中得到了广泛的应用。但是现有的假轨迹保护方法在生成假轨迹时没有考虑用户的暴露位置,可能会降低轨迹的隐私保护程度甚至直接泄露用户的真实轨迹。
图1(a)为用户的真实轨迹tr,其中l2为用户t2时通过微博发布动态显示的位置,攻击者可以获取此信息。当用户发布轨迹时,使用现有的假轨迹隐私保护方法来隐匿该轨迹,轨迹匿名要求是3-匿名,即识别真实轨迹的概率不大于1/3。例如图1(b)中的d1和d2为采用文献[3]中的随机法生成的两条假轨迹,和真实轨迹tr组成轨迹集来进行轨迹匿名。然而,由于攻击者知道用户t2时出现在位置l2,而轨迹d2在t2时没有经过位置l2,故攻击者可识别出其为假轨迹,从而识别真实轨迹的概率变为1/2,大于轨迹隐私要求的1/3,导致轨迹隐私泄露。本文将这种攻击方式定义为暴露位置攻击(具体定义后文给出)。
针对此问题,本文提出了一种假轨迹隐私保护算法,其基本思想是构建k-1 条与真实轨迹相似且包含暴露位置的假轨迹来隐匿真实轨迹。值得一提的是,轨迹隐私保护既意味着整个轨迹不被识别,也意味着轨迹中的敏感位置(除暴露位置外的其他位置)不被识别。图1(c)为添加假轨迹后的轨迹集。每条假轨迹都包含暴露位置l2。实验结果表明,本文算法可以有效保护用户的真实轨迹。
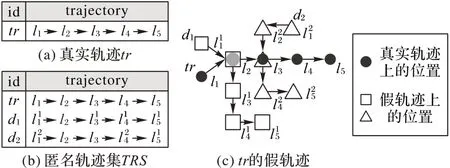
图1 真实轨迹tr、随机法生成的tr的假轨迹和tr的匿名轨迹集Fig.1 Real trajectory tr,dummy trajectories of tr generated by random algorithm and the anonymized trajectory set TRS of tr
1 相关工作
轨迹k-匿名是轨迹隐私保护方法之一,其主要思想是由匿名服务器挑选k-1 条其他用户的轨迹与该用户轨迹组成轨迹集,且这k 条轨迹无法区分。Monreale 等[4]提出了一种基于空间泛化和k-匿名的方法对原始GPS 轨迹进行转换,在已有的轨迹数据集中实现真正的匿名;Xu 等[5]使用不同移动用户的历史足迹来形成匿名区域,并构建k-1 条历史轨迹;Abul等[6]提出NWA(Never Walk Alone)方法,并通过轨迹聚类和空间转移实现(k,δ)-anonymity;Huo 等[7]提出YCWA(You Can Walk Alone)方法,通过对轨迹上停留点泛化来保护轨迹隐私。
轨迹抑制法是指选择性地发布轨迹数据,将敏感或频繁访问的位置去除。Gruteser 等[8]根据某个区域的用户访问量将地图划分为敏感区域和非敏感区域,当用户进入到敏感区域时,抑制或推迟更新其位置,非敏感区域不受控制;Terrovitis 等[9]提出通过抑制处于敏感区域的位置来使轨迹泄露的风险低于用户设定的隐私保护阈值;赵婧等[10]提出基于轨迹频率处理轨迹数据来保护轨迹隐私。
假轨迹隐私保护的主要思想是由用户自己生成k-1 条假轨迹,与真实轨迹组成轨迹集进行发布,其基本思想最早是由Kido 等[3,11]提出;Lei 等[12]通过随机模式和旋转模式来生成假轨迹;Wang 等[13]通过算法求出最佳旋转角度来生成假轨迹,并将部分数据信息存储在雾结构中进行物理控制,保证用户的隐私;雷凯跃等[14]生成假轨迹时考虑了轨迹中相邻位置的时间可达性和时空关联性;Wu 等[15]考虑了用户的移动模式,基于重力模型定义了连续位置熵和轨迹熵来度量轨迹保护程度,并基于此提出了假轨迹隐私保护方法。
然而现有的假轨迹隐私保护算法在生成假轨迹时没有考虑用户的暴露位置,使得攻击值很容易利用暴露位置识别出某些假轨迹,甚至真实轨迹。本文以此为出发点,设计假轨迹隐私保护方案。
2 预备知识
本文涉及的变量说明如下:位置是地图上的一个兴趣点(医院、餐厅、商店、银行等),表示为l=(x,y),其中:x为经度,y为纬度。直接使用l代表位置。一条轨迹是由n个具有时空特性的位置组成的序列,可以将真实轨迹表示为tr={(l1,t1),(l2,t2),…,(ln,tn)},假轨迹表示为d={(l'1,t1),(l'2,t2),…,(l'n,tn)},其 中(li,ti)表 示 用 户ti时 在 位 置li签 到,且1 ≤i ≤n。| tr |表示轨迹的长度。由tr和k-1 条假轨迹组成的轨迹集为TRS={tr,d1,d2,…,dk-1}。
定义1暴露位置。 给定一条真实轨迹tr={(l1,t1),(λ,tλ),…,(ln,tn)},λ 为用户在tλ时通过移动设备发布至社交网络且所有人可知的位置,此时称λ 为tr 在tλ时的暴露位置。该条轨迹中可以有多个暴露位置,用EL={(λ1,tλ1),(λ2,tλ2),...(λm,tλm)}(m <n)表示tr 的 暴 露位置集。轨迹中除暴露位置外的其他位置为敏感位置。
如图1(a)所示,l2为暴露位置,轨迹中的其他位置{l1,l3,l4,l5}为敏感位置。
定义2暴露位置攻击。假设攻击者知道用户轨迹中的某些位置,当其利用这些位置进行隐私攻击时,称为暴露位置攻击。
例如用户针对tr发布的轨迹集为TRS,tr的暴露位置集为EL,攻击者利用暴露位置(λi,tλi)∈EL 作为先验知识对轨迹集TRS 进行攻击,当TRS 中某条轨迹在tλi时刻未经过暴露位置λi时,可识别出其为假轨迹,从而导致用户轨迹隐私泄露。如图1(b)所示,攻击者利用l2攻击,轨迹d2在t2时未经过位置l2可识别出其为假轨迹。
定义3轨迹泄露率TE。假设用户发布的轨迹集为TRS,攻击者利用其背景知识对TRS 进行识别,推测出用户真实轨迹的概率。

其中|TRS'|表示被攻击者识别为假轨迹的数量。
定义4平均位置泄露率ALE。假设用户针对tr 发布的轨迹集为TRS,tr 的长度为n,暴露位置集为EL,个数为m(m<n),除暴露位置外的其他时刻ti对应的位置集为Li,在这个时刻泄露真实位置的概率为1/Li,那么对于整个轨迹而言,平均位置的泄露率为:

定义5(p,k)-anonymity。给定tr 的轨迹集TRS,轨迹匿名阈值p、k(p≤k),如果TRS 中任一敏感位置的位置泄露率不大于,轨迹泄露率不大于,则认为轨迹集TRS 满足(p,k)-anonymity。
如图1(c)所示的轨迹集满足(2,3)-anonymity。
定义6位置距离。给定两个位置li和lj,位置距离定义为位置间的欧氏距离。
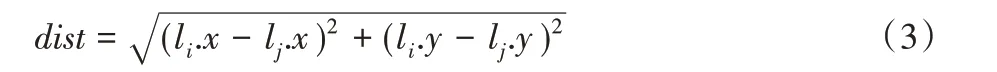
定义7轨迹距离。给定两条轨迹tr1={l1,l2,…,ln},,轨迹距离定义如下:
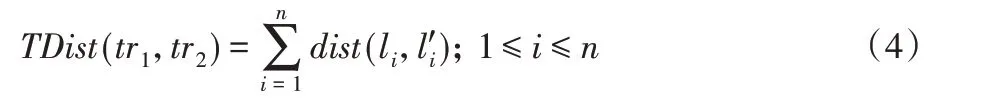
定义8轨迹距离阈值。给定两条轨迹tr1和tr2,若α ≤TDist(tr1,tr2)≤β,则认为tr1和tr2之间的轨迹距离满足轨迹距离阈值(α,β)。
问题1 给定用户真实轨迹tr,暴露位置集EL,轨迹距离阈值(α,β),轨迹隐私要求阈值(p,k),采用假轨迹隐私保护方法使得生成的轨迹集满足(p,k)-anonymity。
3 基于假轨迹的隐私保护算法
本文提出的基于假轨迹的轨迹隐私保护(Dummy-based Trajectory Privacy Protection,DTPP)算法的主要思想是生成k-1 条假轨迹与真实轨迹组成可供发布的轨迹集,代码如算法1 所示。该算法既要求保护轨迹,又要求保护位置,所以每一条假轨迹既要尽可能地在形状上与真实轨迹相似,又要增加轨迹集中敏感位置处的假位置数。DTPP 首先通过候选假轨迹生成算法DTC(Dummy Trajectory Candidate)得到Score 值降序排列的假轨迹候选集第2)行)。Score是一个启发式函数,其值度量了假轨迹在轨迹相似性和位置多样性两方面的影响。Score 值越大表明该假轨迹与真实轨迹越相似,且能提供更多的假位置。然后循环选择Score 值最大(即在Candtr顶端)的假轨迹加入到轨迹集中,直到生成k-1条假轨迹(第3)~5)行)。DTPP 生成轨迹集后,依次判断每个敏感位置处的位置数是否满足位置匿名阈值p,若不满足,说明用户该敏感位置处的假位置无法使轨迹集满足(p,k)-anonymity(第7)~9)行),需要将其抑制,才能保证用户的隐私安全。最后DTPP返回轨迹集合(第10)行)。
算法1 假轨迹隐私保护算法DTPP。
输入 真实轨迹tr,暴露位置集EL,轨迹匿名阈值(p,k),轨迹距离阈值(α,β);
输出 包含k条轨迹的轨迹集。

3.1 轨迹度量
本文使用轨迹相似性(表示为Sim(d,tr))和位置多样性(表示为Div(d,TRS))来度量假轨迹的影响,为了最大化假轨迹的作用效果,本文设计了如式(5)所示的启发式来选择假轨迹。

轨迹相似性Sim(d,tr)的定义如式(6)所示,它显示了假轨迹与真实轨迹之间的形状相似度,通过假轨迹与真实轨迹对应位置间的位置距离的方差来度量。为了与语义信息相匹配,通过对其取倒数即可达到“Sim(d,tr)越大,假轨迹与真实轨迹越相似”的效果。
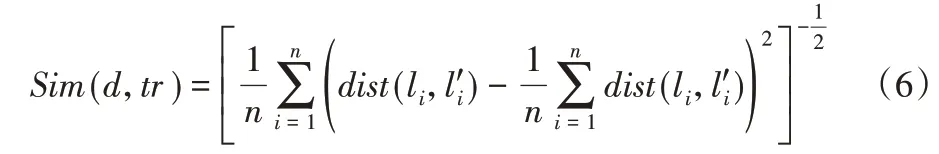
位置多样性Div(d,TRS)的定义如式(7)所示,它表示加入假轨迹后,轨迹集中有数量变化的位置集数占总位置集数的比例。其中div(l'i,Li)表示位置集Li在添加假位置l'i后的数量变化,有变化为1,无变化为0。
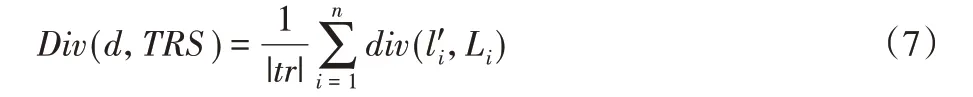
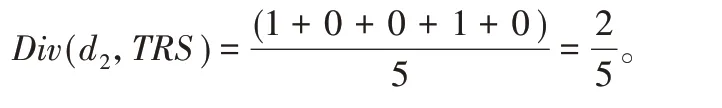
3.2 生成假轨迹候选集
在DTPP 算法中,通过候选假轨迹生成算法DTC(见算法2)生成候选假轨迹。本文通过连接假位置构造假轨迹,试想一条有s 个敏感位置的轨迹,每个敏感位置处产生m 个假位置,如果使用枚举法来产生假轨迹,则有ms条轨迹,假轨迹数量随着敏感位置数呈指数增长。考虑到真实轨迹具有时空特性,假轨迹相邻位置间应满足时空可达性,所以本文根据假轨迹相邻位置间是否可达把假轨迹候选集建模为有向图,正式化为 图G={V,E}。V={(v10,v11,…,v1m),(v20,v21,…,v2m),…,(vn0,vn1,…,vnm)},其中:vi0为真实位置,vij为假位置;E 是边的集合,表示轨迹中相邻位置间可达。时空可达性由式(8)判断,vmax是用户在真实轨迹中的最大速度。很明显,如果式(8)不成立,则说明用户ti时从vij出发不能在ti+1之前到达位置vi+1,j。
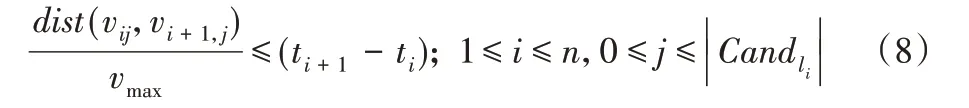
如图2 所示,为图1(a)中的轨迹和其假位置候选集构成的轨迹有向图,其中位置v20为暴露位置。如果两个位置点可达,则两个位置之间有一条边。
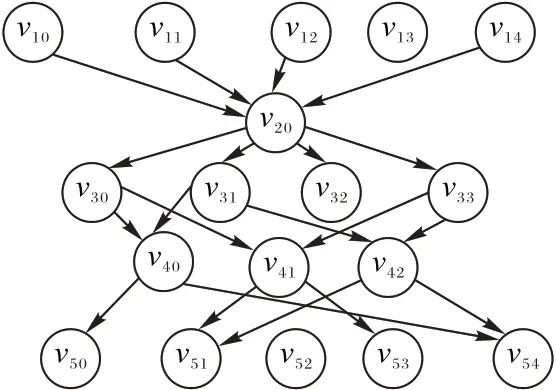
图2 轨迹有向图Fig.2 Trajectory directed graph
为了便于计算假轨迹与真实轨迹的轨迹相似性和轨迹距离,同时实现有向图的建立,采用如图3 所示的邻接表存储结构。其中:id 为位置的逻辑地址;vij为位置;Dist=dist(vi.j+1,vi0)为假位置与对应真实位置之间的位置距离;Reach 为该位置在(ti+1-ti)内可以到达的位置集合,在这里不直接存储位置,而是存储位置的逻辑地址,节省存储空间。
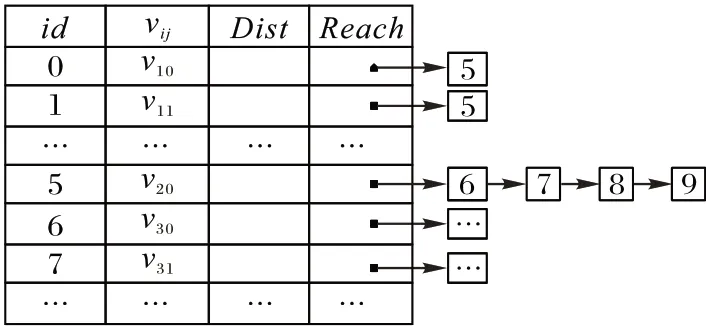
图3 轨迹有向图的存储结构Fig.3 Storage structure of trajectory directed graph
算法2 候选假轨迹生成算法DTC。
输入 真实轨迹tr,暴露位置集EL,位置匿名阈值p,轨迹距离阈值(α,β);
输出 假轨迹候选集Candtr。

在算法2 中,由于每条假轨迹都是以真实轨迹中的第一个位置l0或Candl0中的假位置为起始位置,以真实轨迹的最后一个位置ln或Candln中的假位置为结束位置,因此,通过在图G上以li∈{l0∪Candl0}为开始节点进行深度优先遍历便可得到所有可能的假轨迹(第5)、6)行)。若假轨迹与真实轨迹之间的距离满足轨迹距离阈值(α,β),计算该条轨迹的Score值,将其加入到假轨迹候选集Candtr中(第7)~10)行)。
接下来通过轨迹有向图生成算法TDG(Trajectory Directed Graph,见算法3)介绍轨迹有向图的建立,首先将li和Candli合并为Vi,得到有向图中所有的点(第3)、4)行)。然后判断相邻位置vij和vi+1,j间的时空可达性,若可达,则存在边最后得到有向图G(第5)~14)行)。
算法3 轨迹有向图生成算法TDG。
输入 真实轨迹tr,假位置候选集Candl;
输出 轨迹有向图G。
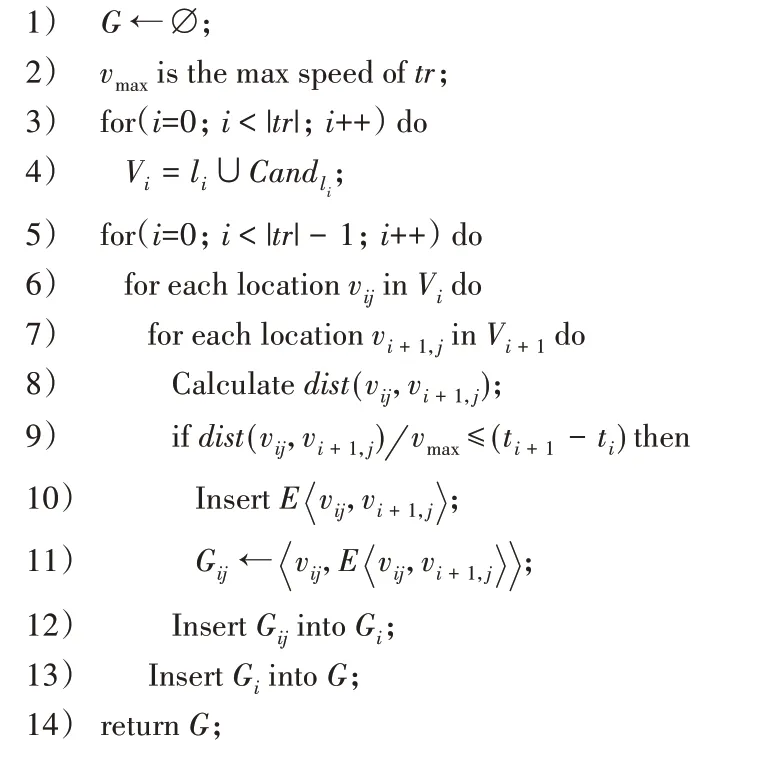
3.3 生成假位置候选集
本节介绍候选假位置生成算法DLC(Dummy Location Candidate)生成假位置候选集。考虑到真实生活中,攻击者很容易从网上获取到地图信息,所以他可以根据轨迹中位置所处的地理环境特征来识别假位置,从而排除假轨迹。例如,如果攻击者捕获到轨迹集中的某条轨迹的某个位置是湖泊,则可以推断出该条轨迹为假轨迹。因此,本文使用地图中真实且有意义的位置点作为假位置来保护轨迹隐私。
为了提高程序的运行效率,本文通过网格划分地图。根据轨迹距离阈值(α,β)将网格单元大小设置为2β。如图4(a)所示,如果敏感位置正好在网格中心,则只需要查找一个网格;如图4(b)所示,若敏感位置不在网格中心,也只需要查找4个网格,大大缩短了查询时间。
在算法DLC 中,首先根据轨迹距离阈值上限β 将地图划分为网格单元大小为2β×2β 的网格(第2)行)。对于轨迹中的位置,若为暴露位置,则其假位置候选集为∅(第4)、5)行);若为敏感位置,根据位置坐标查找网格并遍历其中的位置l'i,若,则将l'i加入到候选集Candli中(第6)~10)行)。记|Candli|为位置候选集中位置的个数,若|Candli|<p,则将真实轨迹中该位置删除(第11)、12)行)。因为当|Candli|<p 时,说明li处于地理位置密度稀疏区域,无法生成足够多的假位置来隐匿用户的真实位置,只能将其抑制。
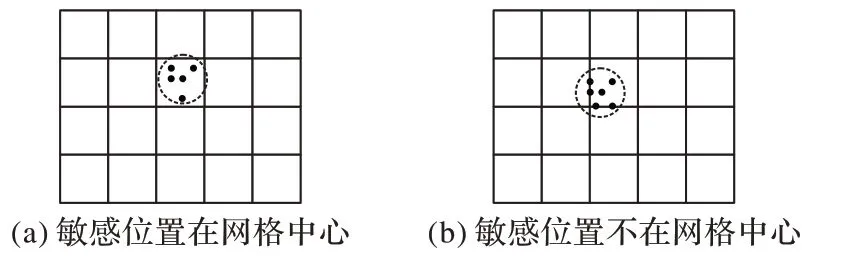
图4 不同敏感位置的查询网格Fig.4 Query girds of different sensitive locations
算法4 候选假位置生成算法DLC。
输入 真实轨迹tr,暴露位置集EL,位置匿名阈值p,轨迹距离阈值上限β;
输出 假位置候选集Candl。

3.4 算法的安全性、复杂度理论分析
假设用户轨迹的长度为n,有m 个暴露位置,s 个敏感位置,那么n=s+m。
定理1采用基于假轨迹的轨迹隐私保护算法(算法1)对用户轨迹进行保护后,得到的轨迹集满足(p,k)-anonymity。
证明 轨迹中有s 个敏感位置,轨迹匿名阈值为(p,k)。算法4 为每个敏感位置生成假位置候选集,若其候选集中的位置数小于位置匿名阈值p,则将该位置删除,所以轨迹中剩余的敏感位置处的位置数至少为p。算法2 生成假轨迹候选集,假设每个敏感位置处有p 个位置,理论上有ps条轨迹,而实际中,由于不只有p个位置,轨迹数会更多,足够产生k条轨迹。算法1 通过调用算法2,启发式地选择假轨迹,直到轨迹集中有k 条轨迹,并且判断轨迹集中敏感位置处的位置匿名程度,若不满足p,将该敏感位置删除,从而保证轨迹集中的敏感位置都满足p 匿名。综上,通过算法1 生成的轨迹集满足(p,k)-anonymity。
算法复杂度分析:在算法DLC 中,敏感位置通过查询网格获取假位置候选集,假设|Dl|为查询网格中的假位置数量,因为算法的时间复杂度为s ⋅|Dl|+m,s ⋅|Dl|≫m,所以复杂度为O(s ⋅|Dl|)。在算法TDG 中,需要n ⋅(|Candli|+1)2时间生成有向图,其中|Candli|为每个敏感位置的候选位置数,时间复杂度为O(n ⋅(|Candli|+1)2)。在算法DTC 中,首先调用算法DLC,然后调用TDG,最后执行深度优先遍历获取假轨迹候选集,最多耗时(|Candli|+1)s,即任意相邻位置间都满足时空可达性,当假位置数量过多时,可能导致有向图很庞大,但是其执行时间最多与前人算法中的枚举方式时间相同。实际上,通过实验可以发现,此种情况发生的概率很小,所以算法DTC的 时 间 复 杂 度 为O(Max(n ⋅(|Candli|+1)2,(|Candli|+1)s))。DTPP 算法通过调用算法DTC 获取k-1条假轨迹,DTPP 执行一次DTC,之后更新Candtr中的Score 值,耗时为n ⋅(|Candli|+1)2+(|Candli|+1)s+(k-2)|Candtr|,所 以DTPP 算 法 的 时 间复杂度为O(Max(n ⋅(|Candli|+1)2,(|Candli|+1)s))。
4 实验评估与分析
本章对提出的假轨迹隐私保护算法进行性能分析和评价。实验中用户的轨迹数据来自斯坦福大学复杂网络分析平台公开的两个真实数据集Brightkite和Gowalla,同时也得到了这两个数据集所在州California 的地图数据,包括21 047 个节点和21 692 条边。本文从两个轨迹数据集中分别选取了5 000个用户的5 000条轨迹数据进行实验,表1显示了实验数据的其他相关信息。

表1 实验数据统计信息Tab.1 Statistics of datasets
首先通过实验获得本文DTPP 算法中最优轨迹距离阈值;然后通过与基于重力模型的假轨迹隐私保护方法(记为GM)[15]和基于随机法的假轨迹隐私保护方法(记为SM)[10]进行比较来分析本文算法的性能;最后评估本文算法涉及的参数对算法的影响。在测试中:匿名阈值k和p的取值范围分别是[6,27](默认为15)、[3,9](默认为3),暴露位置集|EL|取值范围为[1,4](默认为1)。
本实验的软硬件环境如下:1)硬件环境:Intel Core i5 2.33 GHz,4 GB DRAM。2)操作系统平台:Microsoft Windows 7。3)编程环境:Java,IDEA。
4.1 最优轨迹距离阈值
本节通过测试DTPP 算法在不同轨迹距离下的轨迹相似性、平均位置泄露率和运行时间来获得最优轨迹距离阈值(α,β)。
由图5 可知:1)随着轨迹距离的增大,轨迹相似性逐渐降低,平均位置泄露率逐渐降低,运行时间逐渐增加。这是因为随着轨迹距离的增加,更多的假位置加入到轨迹集中,而所有的假轨迹都要经过暴露位置,导致轨迹相似性降低;相应地,平均位置泄漏率减小,运行时间增加。2)当轨迹距离为2 km时,虽然轨迹相似性很高,但平均位置泄漏率却很大,Gowalla数据集甚至达到了60%;当轨迹距离大于6 km 时,轨迹相似性在减小,但平均位置泄露率基本稳定于20%。3)当轨迹距离小于6 km 时,本文DTPP 算法的运行时间在4 s 以内,所以本文把轨迹距离阈值设为(α,β)=(3,6)。4)从两个数据集比较上来看,Gowalla 数据集在轨迹相似性和平均位置泄露率方面比Brightkite 略好,但运行时间比Brightkite 稍长,这是因为Gowalla 数据集中的位置分布密度要略高于Brightkite 数据集。

图5 轨迹相似性、平均位置泄漏率和运行时间随轨迹距离的变化Fig.5 Trajectory similarity,average location disclosure rate and running time varying with trajectory distance
4.2 性能分析
本节通过轨迹泄露率、轨迹相似性和算法运行时间来比较DTPP 算法、GM 和SM 的性能。由图6~8 可知:1)轨迹相似性随着轨迹数量的增多而减小。DTPP 算法的轨迹相似性比GM 算法低约5%,这是因为DTPP 算法考虑了暴露位置,导致假轨迹与真实轨迹对应位置之间的位置距离差异性较GM 算法要大一些,而GM 算法考虑了用户的移动模式,产生的假轨迹与真实轨迹更为相似,但算法DTPP 的轨迹相似性却远高于SM 算法,是SM 算法的4 倍左右。2)当轨迹中存在暴露位置时,由于DTPP 算法考虑了暴露位置,攻击者无法利用此信息识别假轨迹;而GM 算法在生成假轨迹时,与真实轨迹没有交点,导致攻击者可以利用暴露位置100%识别出真实轨迹;SM 随机生成假轨迹,所以可能经过暴露位置,但平均轨迹泄露率却高达约50%。3)三个算法的运行时间随着轨迹数的增多而增加。DTPP 算法的运行时间与RM 算法相差不大,都低于5 s,但远低于GM 算法。这是因为GM 算法在生成假轨迹时,应用枚举法列举所有可能的假轨迹,其运行时间随着位置数呈指数增长,而DTPP 算法通过构建合理的数据结构缩减了假轨迹候选集,节省了运行时间。
综上所述,可以得出DTPP 算法在考虑暴露位置的同时,能保持较高的轨迹相似性且花费很少的运行时间,所以DTPP算法能有效保护用户的真实轨迹。
4.3 参数评估
本节通过实验评估DTPP 算法涉及的参数对算法性能的影响。
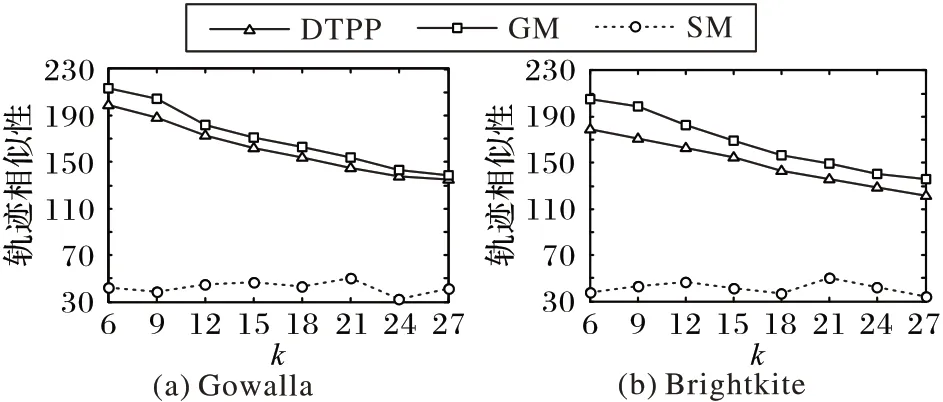
图6 轨迹相似性随k的变化Fig.6 Trajectory similarity varying with k
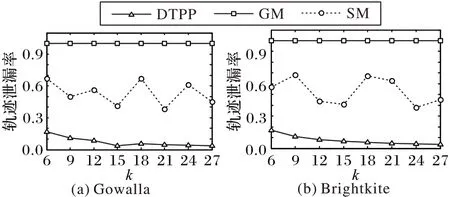
图7 轨迹泄漏率随k的变化Fig.7 Trajectory disclosure rate varying with k
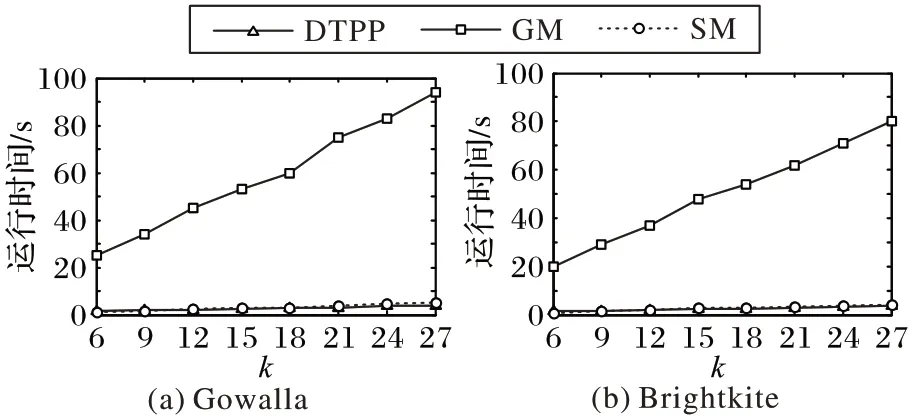
图8 运行时间随k的变化Fig.8 Running time varying with k
首先评估暴露位置数|EL|对轨迹相似性和运行时间的影响。由图9可知:1)当暴露位置数|EL|在(1,3)区间时,轨迹相似性随着暴露位置数的增加而减小;当|EL|>3 时,轨迹相似性随着暴露位置数的增加而增大。这是因为开始时暴露位置数的增加导致轨迹之间的位置距离差异增大,当暴露位置数增加到一定程度后,轨迹之间重合的部分变多,轨迹相似性相应提高。2)DTPP 算法的运行时间随着暴露位置数的增加较大幅度地降低,当暴露位置数大于2时,运行时间均低于1 s。这是由于暴露位置数的增多导致生成候选假位置集和假轨迹集时间大幅减少。
接下来通过位置抑制比来衡量轨迹匿名阈值中的p 对算法的影响。将位置抑制比定义为轨迹中被抑制位置数占总位置数的比例。由图10 可知:位置抑制比随着位置匿名阈值p的增大而增大,但位置抑制比没有超过10%,说明DTPP 算法在满足位置匿名要求的前提下,不需要抑制太多的位置。
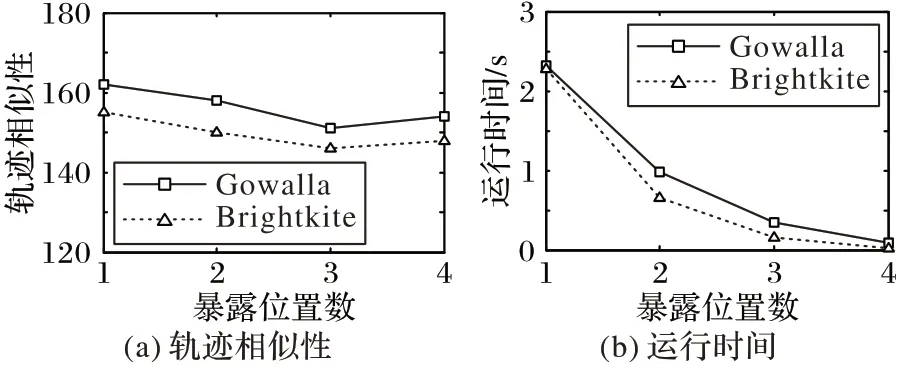
图9 暴露位置数|EL|对DTPP的影响Fig.9 Effect of|EL|on DTPP
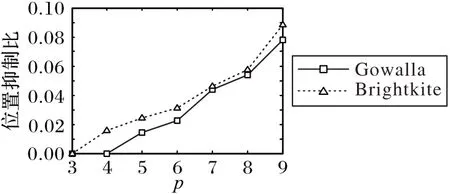
图10 位置匿名阈值p对DTPP的影响Fig.10 Effect of p on DTPP
5 结语
本文首次提出应用假轨迹保护轨迹隐私时考虑用户的暴露位置,并基于此研究了一种轨迹隐私保护算法DTPP。该算法基于网格查找假位置候选集,并利用轨迹相邻位置间的时空可达性构建轨迹有向图存储假轨迹候选集,建立了启发式规则选择假轨迹,使得假轨迹在保护真实轨迹时具有更好的轨迹相似性。基于真实轨迹数据集进行实验,结果表明DTPP算法能够有效保护轨迹隐私免受暴露位置攻击。由于本文采用真实地图上的位置点作为假位置,因而适合保护分布在地理位置密度较密集区域中的轨迹。对于分布于地理位置密度稀疏的轨迹,需要抑制敏感位置,导致信息损失较大。针对此问题的解决方式,还需要进一步研究。
猜你喜欢
现代电子技术(2022年11期)2022-06-14
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
智能计算机与应用(2020年4期)2020-08-31
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
数理化学习·高一二版(2009年2期)2009-03-30
