基于半监督宽度学习系统的气温空间插值
2020-04-22 13:33武淑红王耀力
科学技术与工程 2020年2期
王 涛, 武淑红, 王耀力
(太原理工大学信息与计算机学院,晋中 030600)
实际生活中受到地形、经济等多方面条件的限制,气象站点的设置很不均匀,这就导致一些地区的气象数据获取困难。近年来通常是通过对这些地区的气象数据进行空间插值预测来获取整个地区完整且准确的气象数据[1]。由于气象因子的形成是一个复杂的非线性过程,因此大部分学者采用神经网络方法进行气象插值研究。Snell等[2]第一次将人工神经网络应用于气温空间插值且预测精度高于反距离加权法和泰森多边形等传统插值方法。王兆礼等[3]采用BP神经网络对降雨量进行空间插值预测。Tang等[4]构建了基于粗糙集的径向基神经网络插值模型用于解决实时气象数据不完整、存在缺失的问题。Appelhans等[5]使用14种机器学习方法对Kilimanjaro山南部斜坡的温度变量的空间插值进行了测试和评估。邱云翔等[6]将粒子群算法优化的反向传播(back-propagation,BP)神经网络分别用于三峡区间流域日、月和年降雨的空间插值预测研究。李纯斌等[7]以甘肃省降水量为研究对象构建基于BP神经网络和支持向量机的降水量空间插值模型。王亚琴[1]采用在输入与输出之间加直接连接的BP神经网络进行气温插值预测,实验结果表明BPNN-DIOC(back-propagation neural network with direct input-output connections)预测精度更高。
然而,传统神经网络方法需要复杂的结构调整和大量的网络训练计算,耗时较长。针对这些问题,Chen等[8]提出的宽度学习系统(broad learning system,BLS)提供了一种高效率的训练方法,因其简单、高效等优点广泛地应用于各种分类和预测任务中。因此,基于宽度学习方法提出了一种半监督宽度学习模型(semi broad learning system, SBLS)用于解决气温空间插值问题。因为宽度学习属于有监督学习方法,故结合稀疏编码算法来更好地利用数据内部的结构和特征,首先利用稀疏编码进行字典学习,然后将字典映射到一个代码向量来重建样本数据,最后将新的样本数据引入宽度学习系统建立半监督宽度学习模型(SBLS)。

图2 宽度学习系统网络结构图[8]
1 相关知识
1.1 宽度学习系统
传统的神经网络算法如反向传播(back-propagation,BP)神经网络网络,因其反向传播计算耗时长、容易陷入局部最优等缺陷,网络的预测性能往往受初始化区域的影响较大。为了有效解决这些问题,不少学者致力于寻求结构简单的单层网络模型,利用岭回归直接求解全局最优来优化网络的效率,因此基于宽度的网络结构逐渐发展起来[9]。典型的方法有:单层前馈神经网络(single layer feedforward neural networks, SLFN)[10]、随机向量功能链接网络(random vector functional link neural network, RVFLNN)[11]、极限学习机(extreme learning machine, ELM)[12]等。
宽度学习系统(broad learning system, BLS)是一种具有平面功能链路结构的随机向量单层神经网络,是典型的RVFLNN[13]。传统的功能链接神经网络如图1所示。然而,与原始的RVFLNN不同的是,输入与输出之间的直接连接被一组映射特征所替代,通过特征映射将输入样本变换为特征节点,特征节点再经由非线性映射生成增强节点。特征节点和增强节点共同作为系统的输入,经由连接矩阵线性输入。不同于传统神经网络算法采用梯度下降法等求解权值,迭代耗时长且容易陷入局部最优,宽度学习系统采用岭回归广义逆直接求解连接权值。网络的结构示意图如图2所示。

图1 功能链接神经网络结构图[8]
1.2 稀疏编码
稀疏编码(sparse coding)是深度学习的一个重要分支,能够很好地提取数据集的特征,在分类和回归问题中都取得了成功。该算法是一种无监督学习算法,它通过寻找一组“超完备”基向量来更加高效地表示样本数据。“超完备”基可以更有效地找出隐含在样本数据内部的结构和模式。稀疏编码是将输入样本X分解为多个基元的线性组合,这些基前面的系数表示输入数据的特征,其分解公式表达为
(1)
式(1)中:φi是分解的基向量;ai是基向量对应的系数。为保证找到的基向量能更容易地学到输入数据内在的结构和特征,一般要求基向量的个数k非常大,至少比X中元素个数n要大,因此,分解系数a不能唯一确定,要对其作一个稀疏性约束,即最小化以下函数:
(2)
式(2)中:第一部分是使稀疏编码算法为输入数据提供一个高拟合度的线性表达式,第二部分是稀疏惩罚项,即使得分解系数a变得稀疏。
2 基于半监督宽度学习系统的气温空间插值模型
为使气温空间插值有更高的预测性能和更少的时间损耗,对宽度学习系统进行了一定程度的创新和改进,提出了能更高效地找出样本数据内部特征的半监督宽度学习系统(semi broad learning system, SBLS)。
2.1 半监督宽度学习系统
半监督宽度学习系统(SBLS)是利用稀疏编码算法进行特征提取的宽度学习结构。该算法的训练过程分为可分为三个部分:首先,利用稀疏编码进行字典学习,然后将字典映射到一个代码向量来重建样本数据;其次,将新的样本数据映射到特征层,然后经过非线性映射将特征层映射到增强层,最后,将特征层和增强层作为整体输入连接到输出层;通过岭回归直接求解从输入层到输出层的连接权值。
2.1.1 字典学习
将稀疏编码算法看成是构造包含k个向量的字典D,通过将字典映射到一个代码向量来重建输入样本X的一种方法。字典D可由优化以下函数得到:

(3)
式(3)中:代码向量s(i)是与字典D关联的每个x(i)的新表示形式;字典D是无监督特征表示的关键,通过不断更新字典D和代码向量s(i)使得上式最小,每次迭代分两步,第一步固定字典D,逐个使用样本数据X来优化代码向量s(i),第二步固定系数,一次性处理多个样本数据对基向量进行优化。不断迭代直至收敛,这样就得到一组能有效表示输入样本的超完备基,即字典。一旦字典确定,将输入样本映射到新的特征向量的函数f(x;D)就可以确定。对于任意非线性函数g(),式(4)是得到新的特征向量的首选。
f(x;D)=g(DTx)
(4)
2.1.2 特征映射
将重建的样本数据表示为R,通过函数φi(RWei+βei),i=1,2,…,n生成第i组映射特征Zi,特征映射的权重Wei是从分布密度ρ(ω)中随机抽样,具体说就是,映射特征的维度由Wei决定。最后,将特征映射的第i个集合表示为Zi≡[Z1,Z2,…,Zi],增强节点的第j组集合表示为Hj,是由函数ξj(ZiWhj+βhj)映射来的。同样地增强节点的第j个集合也表示为Hj≡[H1,H2,…,Hj],并且增强节点的随机权重Whj也是从分布密度ρ(ω)中抽样得到的。对于给定的输入数据R,假设宽度学习网络有n组映射特征,每组映射特征有k个节点,特征映射的过程可由式(5)表示:
Zi=φ(RWei+βei),i=1,2,…,n
(5)
n组映射特征的集合记为Zn≡[Z1,Z2,…,Zn],第m组增强节点的生成过程由式(6)表示:
Hm≡ξ(ZnWhm+βhm)
(6)
因此,上述构建的半监督宽度学习系统可表示为
Y[Z1,Z2,…,Zn|ξ(ZnWh1+βh1),…,ξ(ZnWhm+βhm)]W′=[Z1,Z2,…,Zn|H1,H2,…,Hm]Wm=[Zn|Hm]Wm
(7)
式(7)中:矩阵Wm是由[Zn|Hm]的伪逆推导出来的:
Wm=[Zn|Hm]+Y
(8)
在本算法中,矩阵的伪逆由岭回归直接逼近得到,公式为

[Zn|Hm][Zn|Hm]T}-1[Zn|Hm]T
(9)
式(9)中:λ是常规的L2范数正则化。最后,预测值可由式(10)计算得到:
Y=[Zn|Hm]Wm
(10)
该模型的主要学习步骤如下:
(1)对于输入数据,数据预处理是很重要的,为消除不同数据类型的量纲造成的差异,将数据归一化到[0,1]。另外,为克服相邻向量间的相关性应对数据进行白化。
(2)对于给定的未标记数据,可以无监督地学习上一节描述的字典矩阵D。此外,它的列提供样本数据的稀疏投影。
(3)字典确定后,将输入样本映射到新的特征向量的函数就可以确定。
(4)将得到的新特征向量引入宽度学习系统进行分类预测等研究。
因此,基于稀疏编码的半监督宽度学习算法的步骤见表1。

表1 半监督宽度学习算法步骤
2.2 基于半监督宽度学习系统的气温空间插值模型
图3表示基于半监督宽度学习系统的气温空间插值模型的结构图。在构建好半监督宽度学习模型的基础上,以相关气象数据作为系统的输入,经训练得到的输出为预测气温值。
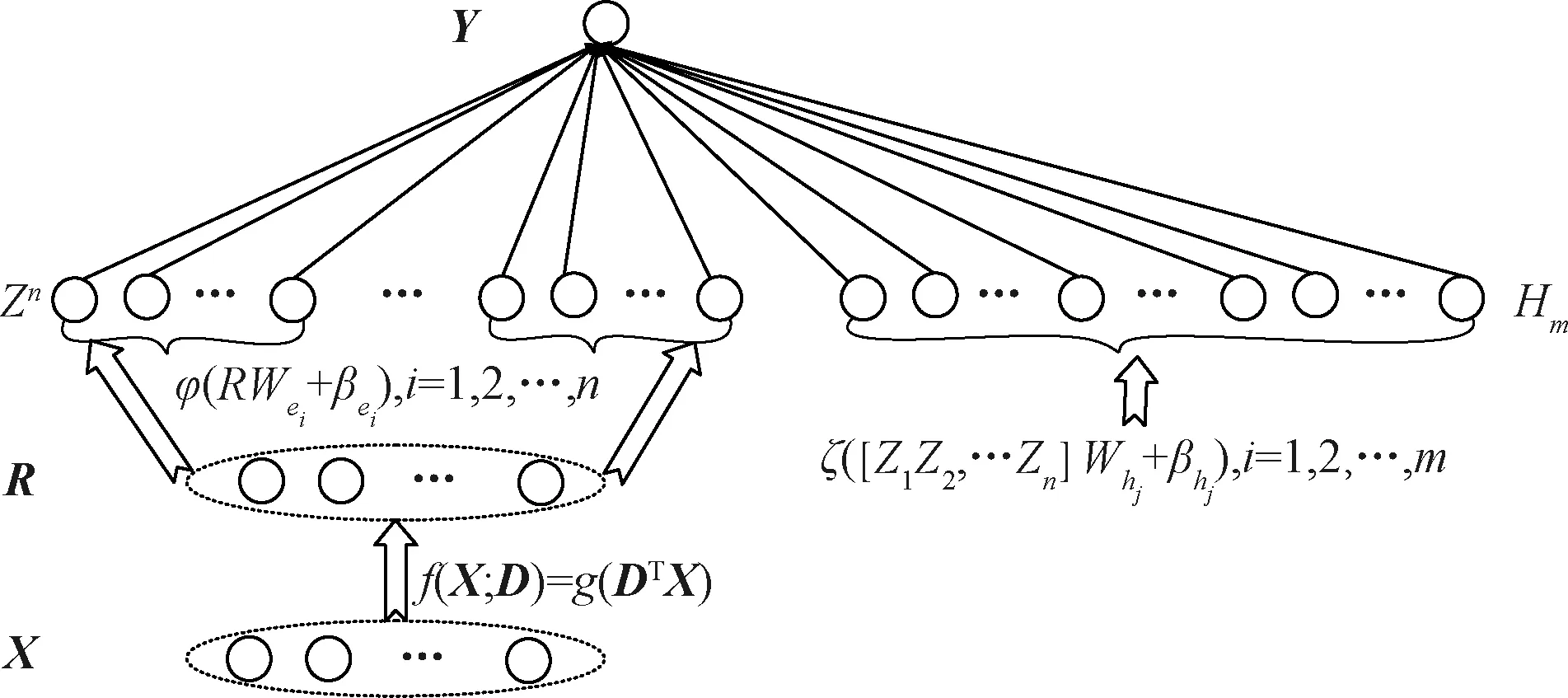
图3 基于半监督宽度学习的气温空间插值模型
3 实验结果分析
3.1 山西省气象站点累年值日值气温
以山西省气象站点的数据进行实验,相关数据包括山西省108个气象站点所处位置的经、纬度和海拔,以及1981—2010年累年值日值气温。山西省大部分地区在5、6、7月份气温较高,空气干燥,风力也较大,属于森林火灾高发期。仅选取5月1—5月7日的日值气温进行气温空间插值预测研究。
选取前70%的76个气象站点的相关数据作为训练样本来构建基于半监督宽度学习的气温空间插值模型,其余的32个站点的数据作为测试样本,以实验整个区域的气象数据空间化。输入因子为气象站点所处位置的经度、纬度和海拔,输入因子为该站点的日值气温,该模型的拓扑结构如图4所示。为实现对不同类型的数据进行统一分析以提高预测精度,将数据按式(11)进行归一化处理。

(11)
式(11)中:Tk表示原始数据;Tmax和Tmin分别表示原始数据的最大和最小值;tk表示原始数据的归一化值。
3.2 对比实验
为评测半监督宽度学习模型(SBLS)的性能,进行了该模型与BP神经网络以及原始宽度学习系统(BLS)的比较。BP神经网络采用只有一层隐含层的结构,使用五折交叉验证法来确定隐含层节点个数。BLS以只经过归一化的原始数据为输入数据。
将以上三种方法均用于山西省108个气象站点1981—2010累年值日值气温的插值预测研究。每次试验进行5次取平均值。预测精度通过均方根误差(RMSE)、平均百分比误差(MAPE)和时间来评估。三种方法对32个测试站点的插值结果的RMSE和时间消耗分别见表2和表3,BP算法的预测值(Pre_BP)、BLS算法的预测值(Pre_BLS)及SBLS算法的预测值(Pre_SBLS)与真实值(Actual)的比较如图5所示,由此可得以下结论。
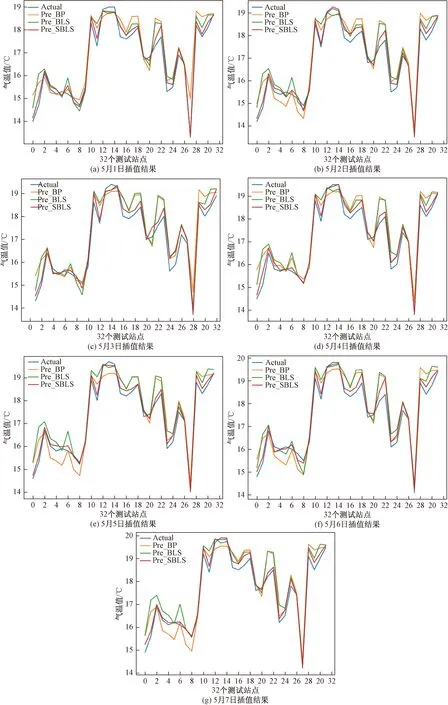
图5 32个测试站点5月1—7日在三种方法下的插值结果
(1)在本数据集上采用SBLS的RMSE最低,因为与BLS相比,SBLS加入了特征提取,更有效地找到样本数据内部的结构和特征。
(2)BLS所用时间最短,SBLS次之,BP所用时间最长。因为BLS通过岭回归直接求解连接权值而且结构简单,而BP神经网络在使用梯度下降法更新参数时需要数次迭代。
(3)相比于BLS、SBLS所用时间长是因为稀疏编码找字典时耗费大量时间。
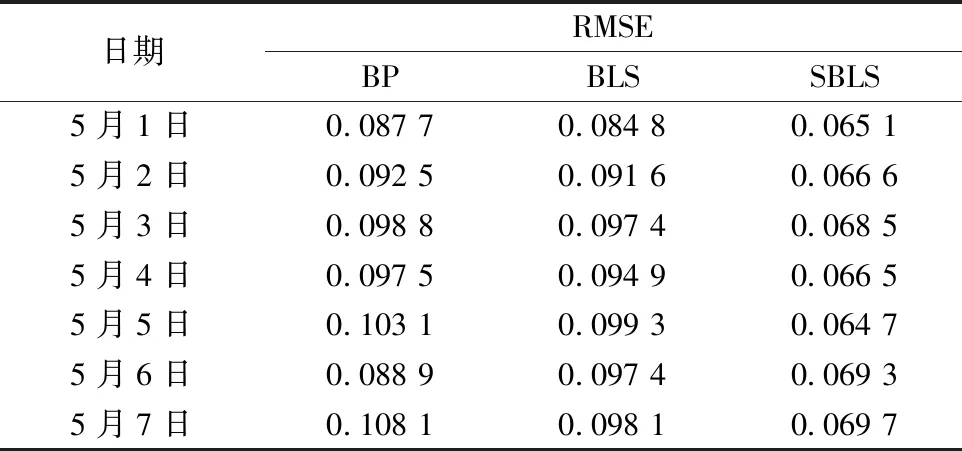
表2 三种方法对测试站点插值结果的RMSE(5月1—7日)

表3 三种方法的时间消耗
3.3 参数分析
在SBLS中调整的参数有:每组映射特征包含的节点数、映射特征组数和增强节点数。将映射特征数记为N2,增强节点数记为N3,RMSE与N2、N3的关系如图6所示,由图6可得以下结论。
(1)随着N2和N3的增加,数据集的RMSE呈现先下降后上升的趋势,这是因为SBLS的预测能力随着N2和N3的增加而逐渐增加并趋于饱和。
(2)过低的N2和N3会导致预测结果的RMSE较高,过高的N2和N3会增加额外的计算。
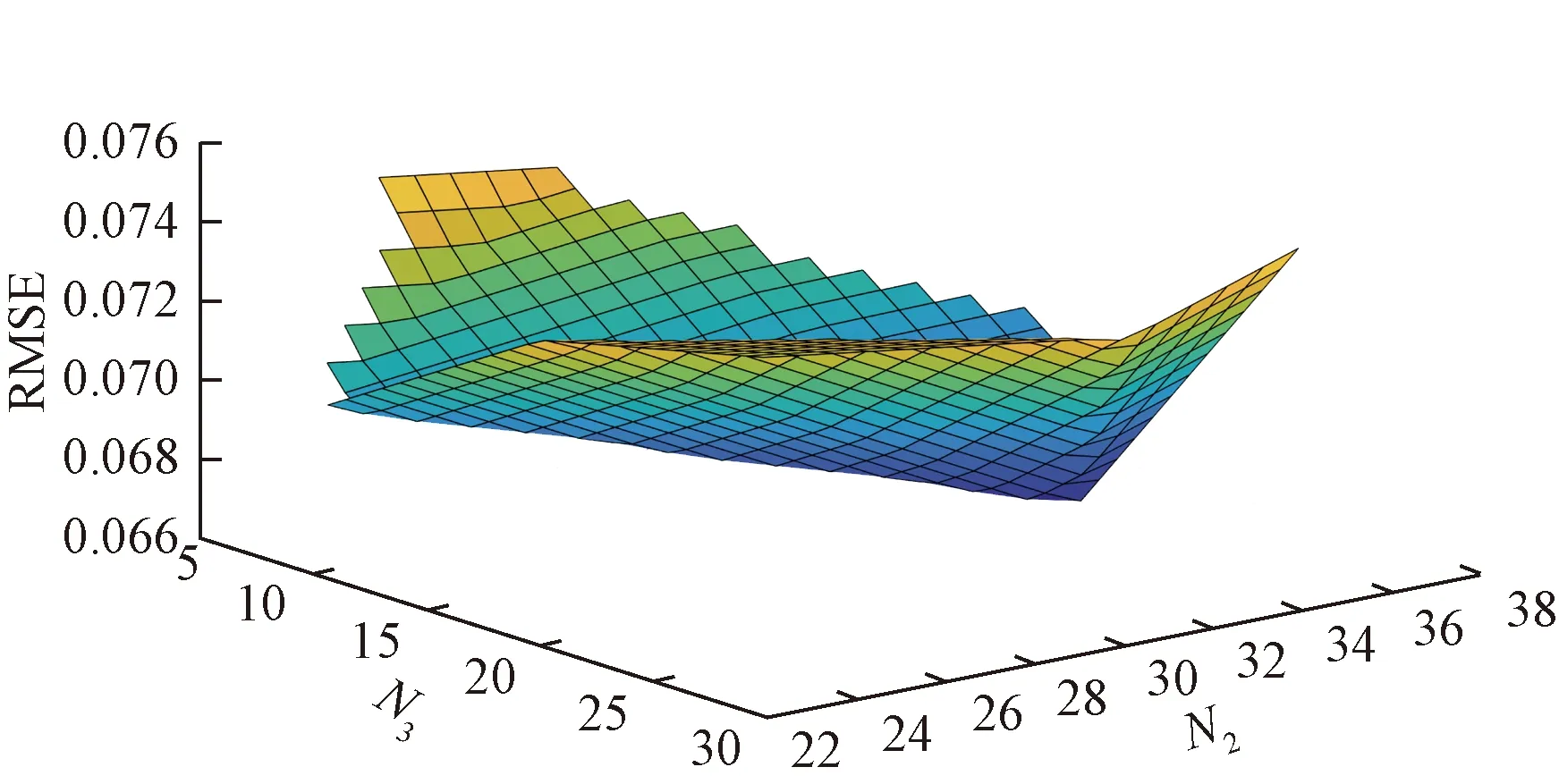
图6 RMSE与N2、N3关系图
3.4 结果分析
(1)从预测精度来说,本文SBLS的预测性能更高,因为它利用稀疏编码将原始输入数据映射到一个新的特征向量,充分发掘了数据内部的结构和特征。
(2)从消耗时间来看,与BP神经网络相比,BLS和SBLS消耗的时间更少,原因是宽度学习需要训练的参数远少于BP神经网络需要训练的参数,而且宽度学习使用岭回归直接求解,无需反复迭代。宽度学习的单隐层简单结构也是训练时间更短的原因,但由于对照的BP神经网络也只采用一层隐含层,故此点不作考虑。相比于BLS、SBLS由于使用额外的计算来获取字典,因此更耗时。
(3)不能保证从具有任何参数设置的SBLS中获取最低的RMSE,这是由于节点太少的话,在映射过程中会丢失很多信息。
另外,对提出的SBLS的缺点总结如下。
(1)与其他插值算法类似,BLS和SBLS都对输入敏感。
(2)如果在映射特征层和增强层设置太多节点会占用大量内存空间。
4 结论
为提高气温空间插值的预测性能并减少训练时间,对宽度学习系统进行一定程度的改进,提出了能更高效地找出样本数据内部特征的半监督宽度学习模型(SBLS),其使用稀疏编码找到一个字典来重建输入样本,然后通过宽度学习来进行插值预测。在山西省1981—2010累年值日值气温数据集上的实验结果表明,SBLS不仅可以获得更高的预测精度,而且比传统BP神经网络耗费更少的时间。此外,对气温的研究只考虑了3个影响因子,未来还可以将SBLS用于更多影响因子的气象空间插值研究中去。
猜你喜欢
导航定位学报(2022年3期)2022-06-10
小学阅读指南·低年级版(2019年11期)2019-07-01
新生代(2018年16期)2018-10-21
小天使·一年级语数英综合(2017年11期)2017-12-05
北京航空航天大学学报(2017年2期)2017-11-24
读者(2016年14期)2016-06-29
人生十六七(2015年5期)2015-02-28
计算技术与自动化(2014年1期)2014-12-12
销售与市场·管理版(2009年21期)2009-09-03