
建筑设计项目任务书的评价指标提取方法研究
2020-04-28 02:10刘佳凝LIUJianing
世界建筑 2020年4期
关键词:绘制
刘佳凝/LIU Jianing
建筑设计任务书是建设项目必不可少的重要设计依据,其合理性直接影响着建筑创作的过程和最终设计方案的质量;然而,在当今的实践中,任务书往往由业主等非专业人士主导编制,其中所提出的设计依据与设计要求,往往过于随意草率,或是罗列了诸多信息,但却缺乏理性与科学依据。因此本文致力于在收集得到的112 份真实的任务书样本的基础上,立足于任务书本身的特性,尝试对任务书的评价找到一套通用性的标准,为行业实践中的建筑师与项目业主,提供一个任务书自查的简单工具,同时也可以作为任务书编制的参考导则。
1 生成任务书评价指标体系的基本思路
观察本研究所收集得到的112 份任务书样本,不难发现,任务书一般呈文档形式,平均字数(中文)在10,000 字左右,涉及内容复杂多样,信息含量巨大;不同项目的任务书样本之间虽各不相同,但亦有一定的规律可循,在条目层级一般按照大致相同的几大成分进行组织,而条目层级之下的具体文本内容,又有很大一部分具体陈述内容的遣词造句,可以被一个通用的高频词库所覆盖;而一些低频词、特异词,则代表了项目的特殊性,也非常可能具有较高的风险。
考虑到任务书文本的以上特性,加之目前已经收集到上百份任务书样本,随着样本库的积累完善,参与评价分析的文本数据量还会不断快速增加,对于这样数量级的文本数据进行分词、词频统计、抽取关键词、相似度计算等文本挖掘的处理与分析,进而找寻得到任务书的评价要素,进行风险识别与判定,人工方法显然不是合适的选择,借助计算机的数据挖掘能力则体现出一定的优势。
对于任务书的文本数据而言,对其进行评价的具体工作,可以转译为发现样本文句词语层面的差异,甚至是语义层面的谬误。为了实现这一设想,本研究提出参考风险评估的基本框架,将任务书评价的主要方法思路定义为:一份任务书样本中都有什么主要成分?这些主要条目是怎样具体叙述的?具体叙述的内容是否具有风险?如果有风险会产生什么样的后果?作为任务书的编制者或评价者应该如何应对可能产生的风险和后果?
任务书文本数据的评价方法步骤可以设计为:(1)对任务书文本进行分词和向量化处理;(2)对得到分词的任务书文本数据进行文本挖掘,统计词频TF、文档频率DF,TFIDF 等参数信息;(3)以词频分析为依据,提取出关键词、特异词等等;(4)通过高频词、关键词确定任务书都有什么要素,也即列出任务书所有可能的待评条目;(5)将得到的待评条目与已有研究做交叉对比,保证得到一份尽可能全面的任务书待评要素清单 ;(6)通过对待评要素(关键词)的全文检索,整理出待评条目的具体内容,包括常见的形式和内容,有关联关系的条目,每一例任务书中的相关具体段落等等;(7)针对特异词的全文检索内容,结合对应待评条目的具体内容,定位可能存在风险的地方,分析有可能出现什么问题(潜在风险事件),判定待评条目是否应进一步确定为风险评价指标;(8)对经过筛选确定为风险评价指标的条目,归纳其风险形态,衡量其重要程度,得出其指标权重(图1)。
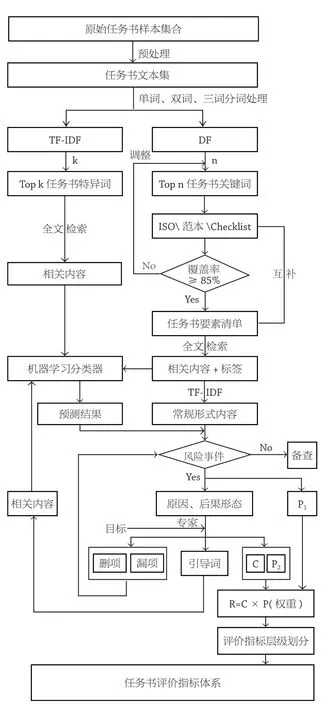
1 任务书评价指标提取方法思路图(绘制:刘佳凝)
2 任务书评价体系的指标确定
为了构建任务书评价的指标体系,从系统逻辑的角度出发,首先需要厘清任务书有哪些要素可以被评价,也即是找出任务书的所有待评要素,然后再行分析判断,甄别待评要素是否可以进一步构成评价指标。
任务书评价指标有3 个可能来源:策划理论、相关规范和任务书样本。本文主要研究的是从任务书样本中,通过文本挖掘和风险识别方法所能获得的评价指标,而理论和规范两个途径所归纳得到的指标,则将作为参考和补充。
2.1 关键词的抽取
计算机并不能真的理解任务书文本的语义及其所指代的内容信息,讨论计算机文本数据的挖掘方法,最为基础的概念之一便是词频(Term Frequency)。词频(TF)是表示某一词语在文档中出现频率的参数,由该词在文档中出现的频数,与整篇文档的词语数相除得到:
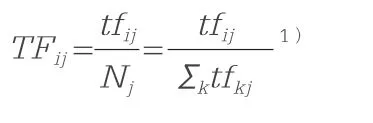
另外一个重要的概念是文档频率(Document Frequency)。文档频率(DF)是表示某一词语在整个文档集中出现频率(按文档记)的参数,通过一个文档集中出现某一词语的文档个数,除以文档集文档总个数D 计算得到。由文档频率可以延伸出一个相关的概念——逆向文档频率(Inverse Document Frequency);逆向文档频率(IDF)是DF 的一种变形,某一词语的IDF 由总文档数目D除以包含该词语的文档的数目,再将得到的商取对数得到,一般的计算公式写作:
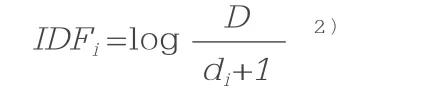
由词频和逆向文档频率的概念组合,可以得到的TF_IDF:

TF_IDF 是一种文本信息检索与数据挖掘最常用的加权技术,通过对一个词语的TF_IDF 值进行统计,可以评估含有该词的文档在整个文档集合中的特殊程度。
TF_IDF 比单一的TF、IDF 有着诸多优良特性。TF 的缺陷在于仅考虑了词语的“热度”;如“的”这样的助词在任何一篇文档中都会有很高的词频,但却没有什么实际意义。IDF 的主要思想是:在一个文档集中,包含词语的文档越少,也就是越小,则IDF 越大,说明词语具有很好的文档类别区分能力;但IDF 没有考虑词语在文档内的普遍性,一个生僻词也极大可能具有较高的IDF。而当某词语在某一文档内具有高词频,在整个文档集中却是低文档频率时,才会产生高TF_IDF 值。不难理解,这样的词语不仅对于某一篇文档很重要,同时对将这篇文档区别于其他文档的贡献较大;因此,TF_IDF 可以过滤掉寻常的词语,而倾向保留对分类重要的词语。

2 词频向量的两种形式示意(图片来源:http://brandonrose.org/clustering)
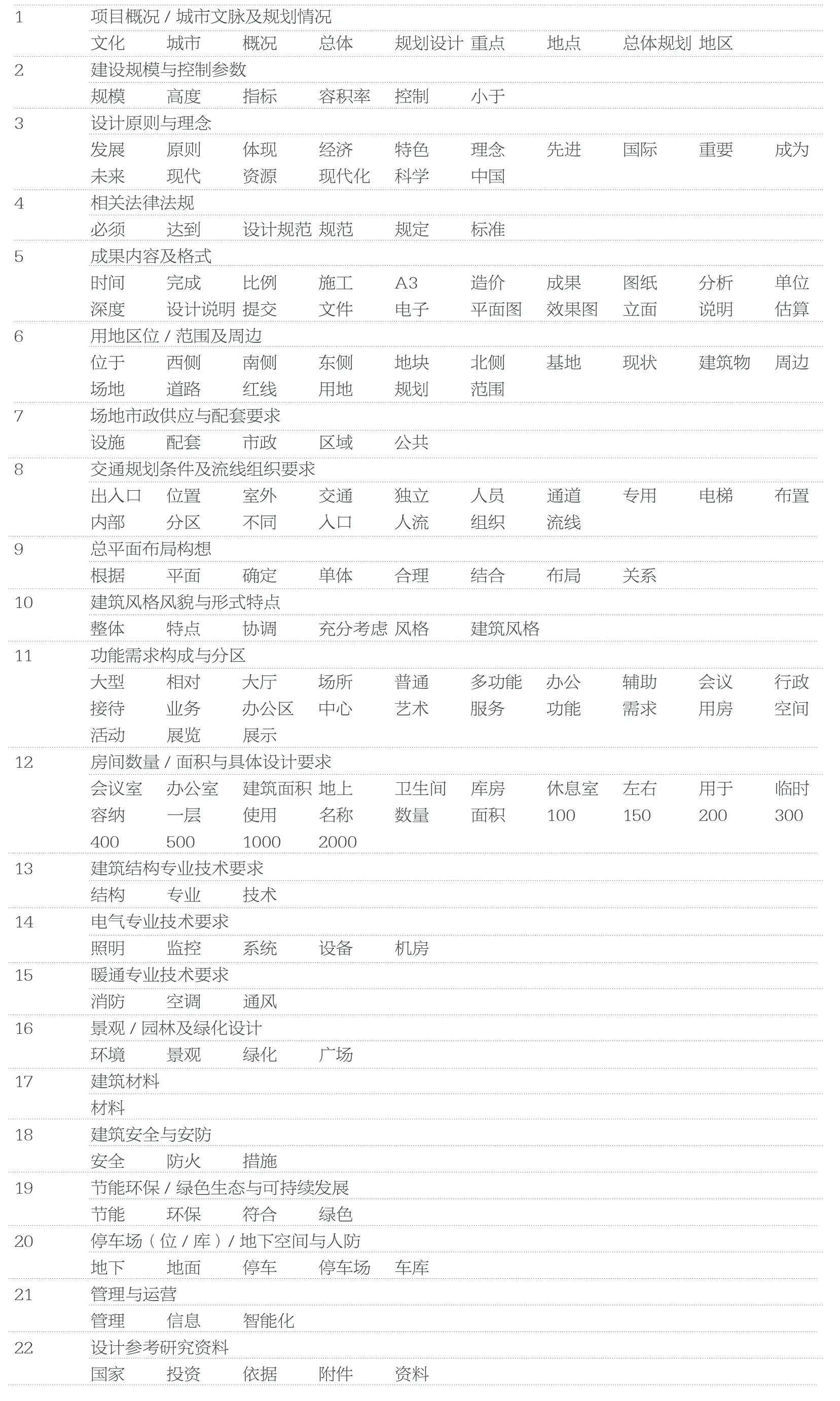
表1 任务书关键词组列表及待评要素名称(绘制:刘佳凝)
具体到任务书样本的文本数据的语义挖掘,高词频的词表征了一份任务书最关注的内容,说明了具体的建设项目设计的核心问题,或多方面多角度相关的复杂问题;高文档频率的词揭示了不论建设项目类型的各种任务书,所关注的一些共性问题,可以对应验证通用型范本各条目的实践效力。词频和文档频率指示出了不同意义下的“高频词”,表征了任务书的主要内容分布,因此本研究分别抽取了累计词频和文档频率排名前300 的词,并取两者的交集,定义为任务书的“关键词”集合,共计235 个,它们是生成任务书评价待评要素清单的核心载体。
而高TF_IDF 值的词,是指示出任务书文档区别于彼此的特征词,可以理解为任务书中具有一定“特异性”的词,根据前文所述的定义和分析可知,表征了少数几个任务书中高频出现的特殊性内容,可以作为引导词,返回任务书原文中找到相关内容,对单一任务书实现潜在风险的定位。因此,本研究抽取了TFIDF 值排名前300 的词,剔除了其中词频TF 或逆向文档频率IDF 畸高的词语,并通过卡方值等参数进行词集调整,最终确定了135 个“特异词”,留待进行风险识别和搜索时使用。

3 关键词层次聚类树状图(部分)(绘制:刘佳凝)

4 关键词相似性及K均值聚类散点图(部分)(绘制:刘佳凝)
2.2 待评要素清单的整理
通过文本挖掘抽取得到的关键词与特异词,从整体上来看结果比较理想,但是单个词语所显示的信息非常零散混乱,大多数关键词单独不能完整表意,还有不少被分别统计的关键词,实际上属于同一个信息类别;这是文本挖掘中使用分词和向量化等处理不可避免的缺陷。这种过度的拆解需要适当进行“合并同类项”的操作,尽可能引申还原出其所代表的一类信息,才能成为用于风险识别的待评要素清单。
而使用计算机进行文本数据挖掘的另一个优势是,可以统计得到“词频向量”和“位置向量”(图2),考虑到若是两个关键词的相关性较大,那么它们在任务书中应该经常相伴出现,它们在文档中出现的频率和位置也会相似,也即文献共现词,因而通过应用聚类、机器学习等方法,进行词频向量和位置向量的数学计算,便可以使计算机拥有对任务书关键词语义相似性判断的能力,进而完成关键词主题分类与整理组合的工作。
本文通过K 均值聚类和层次聚类两种方法,尝试对235 个任务书关键词进行了聚类,得到了图3、图4 的初步结果。在这一基础上,通过人工识别解读、归纳命名的方式进一步整理,得到表1。
任务书样本的数据挖掘是本研究任务书风险评价指标的第一来源,这主要是出于提升建筑问题评价客观性的考虑;但不可忽视的是,经验主义和人工知识领域亦可以提供非常具有价值的评价指标,并形成对计算机数据挖掘结果的验证和补充。通过总结理论和规范,并向有关专家咨询意见,本文对表1 中的任务书待评要素全面性进行了检查,获得了一些候补项与补充意见,在对这些反馈进行筛选与综合后,在表1 罗列的待评要素基础上,再增加12 个任务书待评要素3)。经过进一步分类整理与编号,得到表2。

表2 任务书待评要素(绘制:刘佳凝)
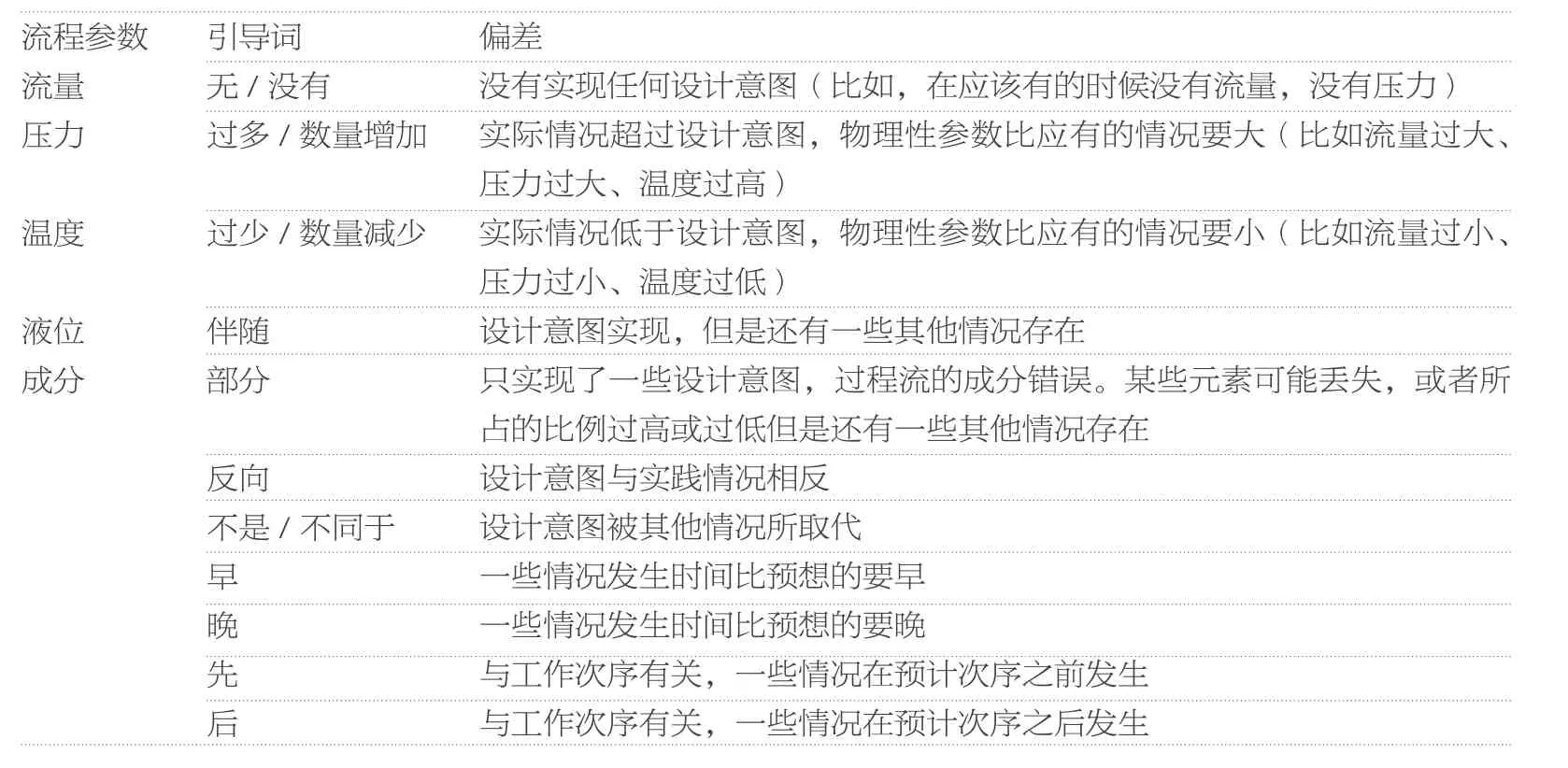
表3 HAZOP 流程参数与引导词[14]
2.3 风险指标的识别与判定
在得到任务书的待评要素清单之后,便需要对这些待评要素进行风险内容的识别与判定。考虑到任务书的文本特性和前文所做的分解工作,风险识别与判定这部分工作可以参考借鉴工业领域中的危险与可操作性分析(Hazard and Operability Analysis,以下简称“HAZOP 法”)。HAZOP 法是经典的应用于工业流程和系统的风险识别方法,其主要思想是:首先将流程或系统分割为多个研究节点,对节点的设计意图和正常状态给出明确的定义,再采用头脑风暴的形式使用引导词或流程参数,提出节点可能出现的偏差和风险(表3)。
HAZOP 法中的一个核心概念——风险引导词,结合到任务书的文本挖掘上,前文通过任务书样本库搜索得到的具有高TFIDF 值的135 个“特异词”,正是对应的任务书风险引导词。这里有一个默认的设置,即越“新奇”、越“诡异”、越“不常见”的词,就越“危险”,可以认为其指示了风险内容,至少是有可能有风险的内容;这符合文本数据对象和任务书文档库的现实特征,因此有理由将“特异词”作为任务书搜索风险时的引导词。
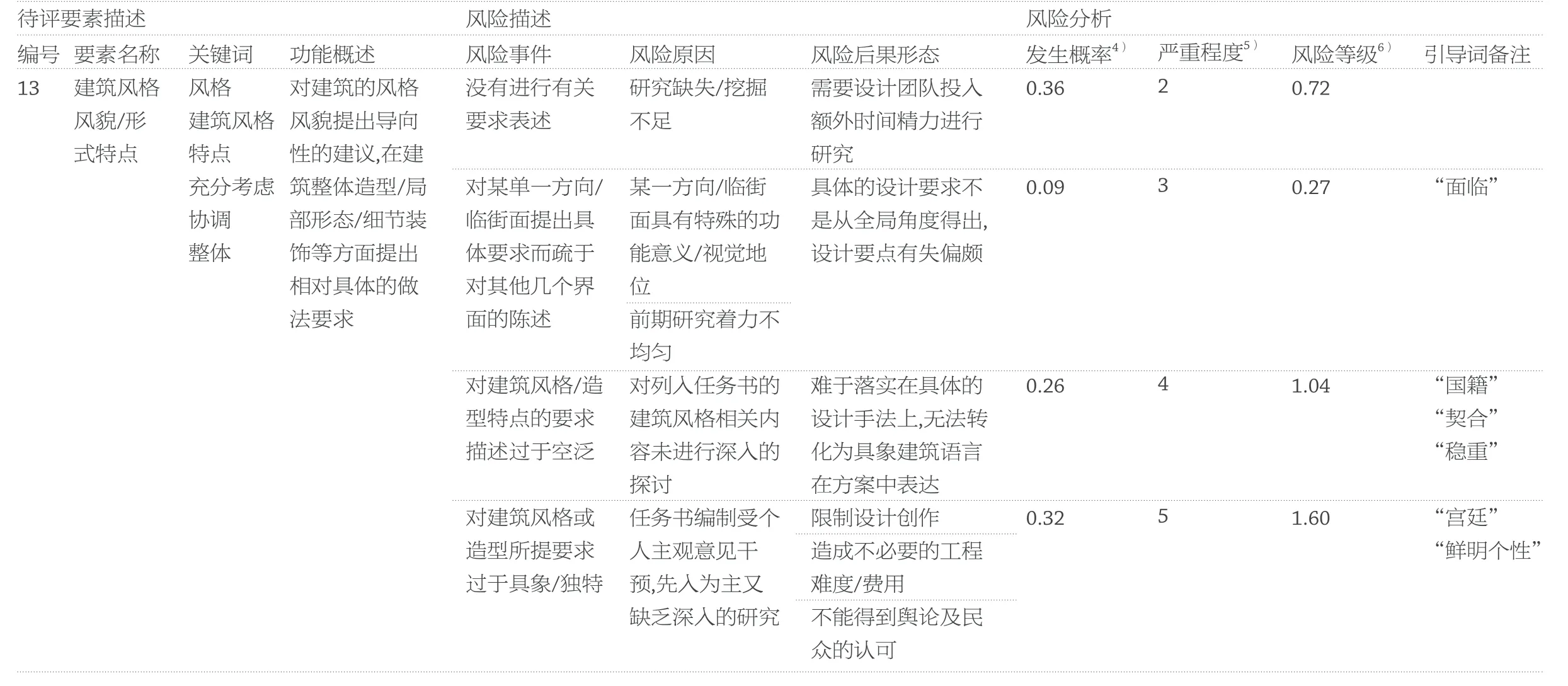
表4 任务书待评要素“建筑风格风貌与形式特点”的风险识别表(绘制:刘佳凝)
通过对这些任务书的特异词或者说风险引导词应用全文搜索技术,可以搜索得到具体的任务书特异内容,进而可以通过逻辑推理来实现判断这些特异内容是否真的是所对应任务书待评要素的风险事件,若是,则可以确定特异词及其内容所对应的待评要素是一个风险评价的指标。表4 示例了“建筑风格风貌与形式特点”这一待评要素在“面临”“国籍”“契合”“稳重”“宫廷”“鲜明个性”几个引导词下搜索归纳得到的风险识别与判定结果。
需要特别说明的是“房间数量、面积与具体设计要求”这一待评要素是一项特殊而重要的任务书评价指标,因为其风险不仅存在于文本层面,更存在于房间清单或空间列表中,也就是面积数值的大小和分配比例问题,而这部分数据并不能够通过特异词搜索来进行风险识别和判定。若要对面积表格中的数值型数据进行科学的风险评估,可以通过加和检验、向量聚类等方法来识别和评价。
应用上述风险识别与判定方法,最终确定的任务书评价指标结果为:经大量任务书样本的文本挖掘,共得到22 个待评要素,并全部识别出风险内容,可以进行风险判定,并晋级成为任务书风险评价指标;通过梳理策划评价理论,咨询相关专家及一线建筑师,对文本挖掘得到的22 个待评要素进行检查和补充,又增加12 个待评要素,其中10 个识别出风险内容,确定为任务书风险评价指标,“任务书编制人员与编制程序”和“任务书格式与内容”两个待评要素,虽然没有直接从任务书样本库中识别出风险事件,但与本研究所探讨的任务书评价理论高度相关,在再次垂询专家意见后,仍旧补充在任务书评价指标之列。
3 结语
本文针对“建筑学问题+文本类对象+风险识别方法”这个交叉领域,进行新的理论和实践探索。通过任务书文本的分解与挖掘,所得到的“关键词”“特异词”“待评要素”、以及由其引导搜索得到的内容,可以视为一种基于实践样本的“参考样例”和“错误日志”,这为任务书评价领域由于缺乏成型的历史数据,为以往只能依靠专家经验或单纯的头脑风暴进行评判的问题,提供了一种新的、更具客观性、智能性和高效性的解决思路。
本文的研究是要构建建筑设计项目任务书的一套评价体系,提取指标本身只是最初始的一步,相应的还应建立起相匹配的指标权重体系。风险识别过程中得到的发生概率、严重程度、风险等级数据,其实就可以为指标权重提供第一数值来源,但如何组合、平衡这些数据,同时贴合任务书风险评价的实践目的与意义,使之呈现为一套简明的、有效的权重体系,则需要更多的研究,作者在这方面也进行了一定的尝试和探索,限于篇幅便不在本文中详述。□
注释
1)k 取遍文档 j 中的所有词语。词频实际上是词语频数的归一化表达,避免了文档长度对词频的干扰。词频反映了词语在文档内的普遍程度。
2)分母中比定义多加了1,是考虑到词语不属于语料库的可能,为了防止除0的情况发生而加。文档频率反映了词语在文档间的普遍程度,逆向文档频率则是词语在文档集中普遍重要性的度量。
3)见表2星号标注的待评要素。
4)风险事件的发生概率按照风险特异词的并集概率求解,P(AUBUC)=P(A)+P(B)+P(C)-P(AB)-P(AC)-P(BC)+P(ABC),其中P(i)为某一单一特异词出现的概率(文档概率)。
5)风险事件的严重程度通过访谈相应任务书项目的建筑师,咨询对本评价体系有一定了解的专家小组,最终归纳得到。
6)风险等级=发生概率×严重程度
猜你喜欢
疯狂英语·新读写(2022年4期)2022-11-22
锦绣·上旬刊(2022年1期)2022-05-16
疯狂英语·读写版(2022年4期)2022-04-08
科教新报(2022年2期)2022-02-21
第二课堂(课外活动版)(2021年1期)2021-05-21
艺术品鉴(2021年2期)2021-04-26
读者·校园版(2019年21期)2019-10-18
现代计算机(2019年1期)2019-03-04
艺术评论(2018年8期)2018-12-28
现代计算机(2018年7期)2018-04-24
