
基于主题模型的胸部X光片诊断报告异常检测方法*
2020-05-04 06:54尤诚诚冯旭鹏刘利军黄青松
计算机工程与科学 2020年4期
尤诚诚,冯旭鹏,刘利军,黄青松,3
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650500;2.昆明理工大学信息化建设管理中心,云南 昆明 650500;3.云南省计算机技术应用重点实验室,云南 昆明 650500)
1 引言
随着医院影像报告管理系统的广泛应用,我国各级医院产生并且保存着大量的胸部X光片及其对应的诊断报告。胸部X光片是常规体检的检查项目之一,已经成为胸部检查的优先选择,它能快捷、清晰地对胸部的大体情况包括肺、心脏等器官进行观察。胸片诊断报告有着重要的应用价值,它不仅能对可能发生的疾病提前预警,还是临床医生制定治疗方案的重要参考依据。诊断报告核心的内容是影像描述和诊断结论,这两部分是辅助医生诊断和患者治疗的重要参考,也是用于诊断报告异常检测的关键信息。医生书写诊断报告具有相当大的主观性,有可能会因为经验不足或疲劳而产生影像描述内容的解读错误[1],使一些疾病被漏诊、误诊。另外诊断报告中影像所见部分描述自由,多为医疗惯例描述语言,复杂的影像描述内容也可能影响医生的鉴别诊断,得出错误的诊断结论。筛选出这些异常的诊断报告,首先可以减少疾病误诊率,为临床医生的诊断治疗提供更准确有效的参考。其次,为建立规范化的医疗检查体系和实现高效精准的医疗服务提供了基础。最后,可增强医院的管理水平,监督考察医疗工作者的技术素养。所以,对诊断报告进行异常检测方法的研究意义重大。本文以胸部X光片诊断报告为研究对象进行诊断报告异常检测的研究。
传统的异常检测方法都是为了找出不满足规则和期望的样本[2]。目前在医疗领域出现了大量的异常检测方法用于检测医疗保险记录、医疗处方等医疗数据。有监督的异常检测方法,首先通过大量高质量的人工标注数据,利用传统的分类方法找出异常数据。Kumar等[3]用SVM的方法检测医疗索赔数据的记录错误。Rawte等[4]结合监督和无监督的方法来检测医保欺诈。无监督的异常检测方法,通过计算离群点发现异常的数据样本。崔书华等[5]通过离群点检测方法对异常数据进行分析。高永昌[6]提出一种基于异构网络社区离群点检测的医生欺诈发现方法。Segaert等[7]证明了稳健回归和离群点检测是处理高维临床数据(如omics数据)的关键策略。丁可[8]提出一种基于状态转移矩阵的便携式医疗设备通信异常数据检测方法。Hawking等[9]基于k近邻方法来找出医疗欺骗数据。张焕毫[10]提出了基于最近集孤立度的方法找出骨科处方数据的孤立点异常样本。Yamanishi等[11]使用概率生成模型去检测病理数据的异常。Johnson等[12]基于多阶段方法检测健康保险索赔中的欺骗。另外,还可以用上下文检测的方法来检测2类特征的匹配关系,找出匹配不成立的异常数据。该方法在医疗中也有应用,Hu等[13]使用该方法在医疗记录中识别异常用药案例。刘少钦等[14]提出了基于扩展主题模型的方法判断诊断疾病与处方药物间的异常,其提出的扩展主题模型具有很好的参考意义,在异常处方的检测中取得了很好的效果。目前医疗领域的异常检测方法,主要针对医疗处方等疾病名称、药物名称固定的结构化数据,但是针对语言结构复杂、专业术语难以获取的影像诊断报告的研究相对较少。
传统的有监督检测、异常点检测、上下文异常检测等方法检测异常诊断报告效果不佳。由于缺乏有效的标注数据,有监督的检测方法不适用于诊断报告。诊断报告文本描述自由,一些影像描述的症状或者疾病出现较少,但不能归为异常,所以用于异常点检测会出现偏差。诊断报告数据高维稀疏,因此通过传统的映射函数进行上下文的特征匹配,效果不佳。
诊断报告中的诊断结论是根据影像描述得到的,影像描述中的症状实体与诊断中的结论实体存在特有的语义信息和对应关系。诊断报告中存在大量的专业术语,如果不进行实体的抽取,直接以字符或者词语特征进行训练,输入特征就会失去原有的语义信息和对应关系。如:影像描述中的“双侧膈肌光滑,双肋膈角锐利”对应结论中的“膈无异常”,分成字符或词语就失去了原有的语义信息和对应关系。通过计算这2类实体之间的对应关系,就可以判断该诊断报告影像描述与诊断结论是否匹配,即可以检测该诊断报告是否异常。本文方法的主要改进有:(1)针对胸片诊断报告的特点,利用加入后缀特征的双向LSTM-CRF(Long Short-Term Memory Neural Network-Conditional Random Fields)模型,对描述症状实体和诊断结论实体进行提取,提高了实体提取的效果。(2)利用领域知识和模板,对胸片诊断报告进行特征的扩展和补充,一定程度上缓解了特征稀疏的问题。(3)将胸片诊断报告的异常检测,转换为影像症状实体特征与诊断结论实体特征判断能否匹配的问题,利用LDA主题模型[15]来进行异常检测,取得了很好的识别效果。
2 基于主题模型的诊断报告异常检测方法
2.1 整体框架
基于主题模型的诊断报告异常检测方法整体框架如图1所示,胸片诊断报告的异常检测主要分为实体特征提取和实体特征匹配2部分。首先,利用双向LSTM-CRF模型结合诊断报告文本数据自身的字符级特点(后缀特征),对诊断报告影像描述与诊断结论中的实体进行准确提取,解决诊断报告中未登录词过多和专业术语提取困难的问题。然后,依据诊断报告自身数据的特点及领域专家知识对诊断报告中的各类特征进行扩展和补充,缓解数据的高维稀疏问题。最后利用LDA模型对诊断报告中症状实体与结论实体进行特征匹配,确定区分正常诊断报告与异常诊断报告的阈值,对诊断报告进行异常检测。

Figure 1 Overall framework of the proposed method图1 本文方法总体框架
2.2 基于双向LSTM-CRF的诊断报告实体抽取
对胸部X光片诊断报告中的症状实体和疾病实体进行实体抽取时,具有以下挑战:数据量巨大、未登录词过多、没有相应的术语词典、症状实体较长。诊断报告中的专业术语本身还具有很多的明显字符级特征,如表1所示。本文根据诊断报告自身特征提出了基于LSTM-CRF模型进行诊断报告的实体抽取。
模型中双向LSTM[16]神经网络层可以整合上下文信息,得到序列中字符标签的分布矩阵。CRF[17]广泛用于序列标注的问题,模型中CRF层根据双向LSTM层输出的标签概率分布,预测出最优的序列组合。
本文以字符基本特征结合诊断报告特有的实体后缀特征,生成表示其类型的字嵌入向量,输入双向LSTM-CRF序列标注模型,对序列标签进行预测,最后完成对诊断报告实体的抽取。以字嵌入向量作为模型的输入,解决了未登录词过多的问题,减少分词带来的负面影响,并且结合症状实体和疾病实体的字符级特征,对诊断报告中较长实体进行识别,取得了很好的效果。

Table 1 Classification of character-level features表1 字符级特征分类
2.3 基于主题模型的诊断报告异常检测
2.3.1 主题模型
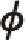
与传统的LDA模型类似,改进后的LDA模型参数求解依然使用吉布斯采样[18]方法,对同一个实例分为2个部分进行采样,两者有着相同的求解过程。以A类特征为例,计算实例d中A类特征w属于主题t的概率如式(1)所示:
(1)
标记为主题t的所有A类特征中,特征w的比重如式(2)所示:
(2)
实例d标记为主题t的特征在所有特征中的比重如式(3)所示:
(3)

将诊断报告分为影像描述(A)和诊断结论(B)单独出发进行推断,得到2个诊断报告的实例主题分布。用MA表示A类特征实例的数目,MB表示B类特征实例的数目,K表示主题数目。
影像描述类实体特征x在该模型上的实例主题分布,推断公式如式(4)所示:
(4)
诊断结论类实体特征x在该模型上的实例主题分布,推断公式如式(5)所示:
(5)
诊断报告中的影像描述、诊断结论2类实体特征由共同的参数θ得到,因此改进主题模型抽取到的2类特征语义相似,并且2类主题分布可以进行关联分析,最后得到影像描述和诊断结论之间的对应关系。通过计算比较影像描述实体和诊断结论实体得到的实例主题分布是否匹配,就可以检测异常诊断报告。
2.3.2 特征扩展补充
胸部X光片诊断报告影像描述中的内容较长,实体特征丰富,利用LDA模型可以很好地进行主题提取。但是,一些诊断结论中的实体特征较少且稀疏,进行主题提取面临挑战。针对诊断报告的特点,通过以下方式缓解上述问题。诊断报告样本实例如表2所示。
(1)特征扩展:诊断报告中存在较多并列描述,将这些并列实体分开描述如“双肺纹理增强,紊乱”改为“双肺纹理增强”和“双肺纹理紊乱”。“心脏大小形态无异常”改为“心脏大小无异常”和“心脏形态无异常”。通过特征扩展可以大大丰富特征信息。
(2)特征补充:诊断结论主要突出表征的是影像描述中的异常,主要给出异常结论,很多正常的影像描述没有给出相应的结论。这是造成诊断结论简短的一个主要原因。对于胸部X光片,医院和在线医疗网站都有对应的参考模板,诊断报告中的结论都有着与之相对应的规范描述。本文依据这些模板对诊断报告中的正常结论进行补充,大大缓解了诊断结论特征稀疏、主题提取困难的问题。
(3)将诊断的性质即阴性、阳性加入结论部分,并与影像描述中的症状实体进行匹配。

Table 2 Samples of diagnostic reports表2 诊断报告样本实例
2.3.3 阈值计算
通过计算诊断报告中影像描述和诊断结论对应的主题分布的相似度,按照相似度排序,进而检测本文方法在进行异常检测时的效果。本文利用不同的相似度计算方法计算主题分布相似度,θA表示影像描述的主题分布,θB表示诊断结论的主题分布。
用欧几里得距离(EUC)计算空间中2个点之间的距离,如式(6)所示。
EUC(θA,θB)=|θA-θB|
(6)
用余弦公式(COS)根据2个向量的夹角来确定相似度,如式(7)所示:
(7)
皮尔逊相关性(PS):由于θA和θB各个维度上分量之和为1,可以用相关性计算相似度,如式(8)所示:
(8)
其中,μ表示主题向量各个维度的均值,σ表示方差。
因为缺乏高质量标注的异常数据,所以不能依据相似度确定检测异常诊断报告的阈值。本文利用诊断报告实体相对较少的优势,对评价策略做出改进来确定检测异常诊断报告的阈值。首先得到诊断报告中每个影像描述实体概率最大的2个主题并进行标记,然后得到每个诊断结论实体概率最大的主题,最后将诊断实体依次与每个描述实体标记的主题做匹配。如果能找到对应的主题,则证明该诊断结论有来自影像描述的依据,视为正常结论,否则视为异常结论。本文根据诊断结论与影像描述中不匹配实体的数量确定检测异常诊断报告的阈值。
3 实验
3.1 实验数据及预处理
本文研究对象为胸部X光片,是最普遍的一种影像检查,作为入院或门诊的常规检查进行疾病筛选。对大量诊断报告进行分析并与有关专家进行讨论了解到,影像描述中出现的医疗症状实体与诊断中的结论实体有着明显的对应关系,这些医疗实体大多是专有医疗用语和医疗共识用语。实验数据来自某三级甲等医院,为了保证诊断报告的普遍性,选取的诊断报告考虑到了患者性别、年龄以及检查的时间。
胸片诊断报告的实体抽取,首先需要进行序列标注。本文在有关专家的耐心指导和监督下,对胸片诊断报告进行标注。由于诊断报告中的未登录词较多,以现有的分词工具进行分词后输入模型会产生很大的负面影响。本文以字符特征按照BIO标准进行标注,实体起始字标签为“B”,实体非起始字为“I”,非实体字为“O”。
诊断报告数据中缺乏标注数据,因此本文使用人工扰动的方式模拟出异常的诊断报告数据。本文将一部分的诊断报告数据中的确定疾病的诊断结论,全部换为正常的结论。如“肺气肿”,改为“肺部无异常”。通过所提的方法检测出这些人工扰动。数据集共有5 000份正常诊断报告和标注人工扰动的200份异常诊断报告。
3.2 评价标准及部分参数设置
本文对不同实验效果的评价,采用准确率P、召回率R、以及两者的综合考量F-measure值(F)。公式如下所示:

Table 3 Training corpus annotation表3 训练语料标注
(9)
(10)
(11)
其中,TP为准确识别出的标注实体;FP为错误识别出的非标注实体;FN为未识别出的标注实体。对于异常检测:TP为准确识别出的异常报告;FP为错误识别出的非异常报告;FN为未识别出的异常报告。
本文在实体抽取部分使用双向LSTM模型,隐藏层单元数量为64,句子长度不超过100。为防止过拟合,输入层和隐藏层进行dropout,值设为0.6。在主题模型部分,设置的先验超参数α=5.55,β=0.01。由于诊断报告属于短文本,实体特征数量较少,本文以10为步长逐渐增加进行主题数对比实验。
3.3 实验设计及分析
实验1 在本文提出的异常检测方法中,实体提取的效果对异常检测影响巨大。实验1验证在双向LSTM-CRF中加入诊断报告字符级特征的实体识别方法的效果。将传统的CRF模型、双向LSTM模型、双向LSTM-CRF模型与本文方法做对比,结果如表4所示,交叉验证实验表明,本文方法在进行诊断报告的实体抽取时取得了更好的效果。
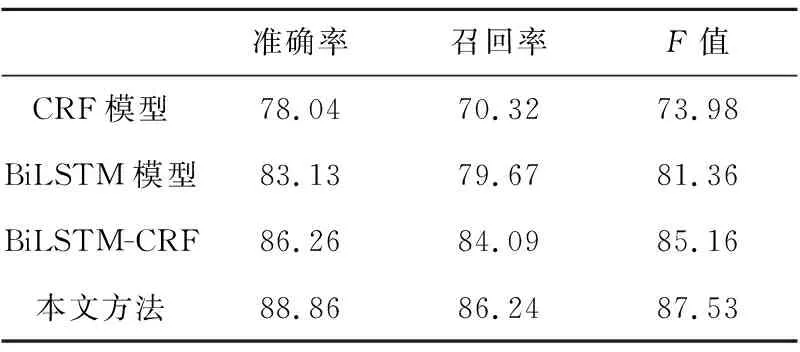
Table 4 Entity extraction results of diagnostic report表4 诊断报告实体抽取结果 %
由表4可知,本文方法在进行诊断报告的实体提取时取得了最高的准确率和召回率。本文方法充分考虑了诊断报告的特殊性,结合字符级特征,针对诊断报告中较长专业术语的提取表现出优越的性能。
实验2 将所有5 000份正常的诊断报告分成10份,采用10-fold交叉验证的方式对数据集进行划分,测试集采用其中500份正常的诊断报告和标注的200份异常诊断报告。实验分别采用了词语特征、实体特征和实体特征扩展3种输入方式,验证不同输入方式进行诊断报告异常检测的效果。同时验证不同主题数K和相似度计算方法对异常检测实验效果的影响。首先将不同类型的特征在K=10,15,20下训练模型;然后进行测试实验,根据相似度由低到高进行排序,抽取相似度较低的200份诊断报告;最后通过其中标注出的异常诊断报告的数量进行对比实验。交叉验证实验结果如表5所示。
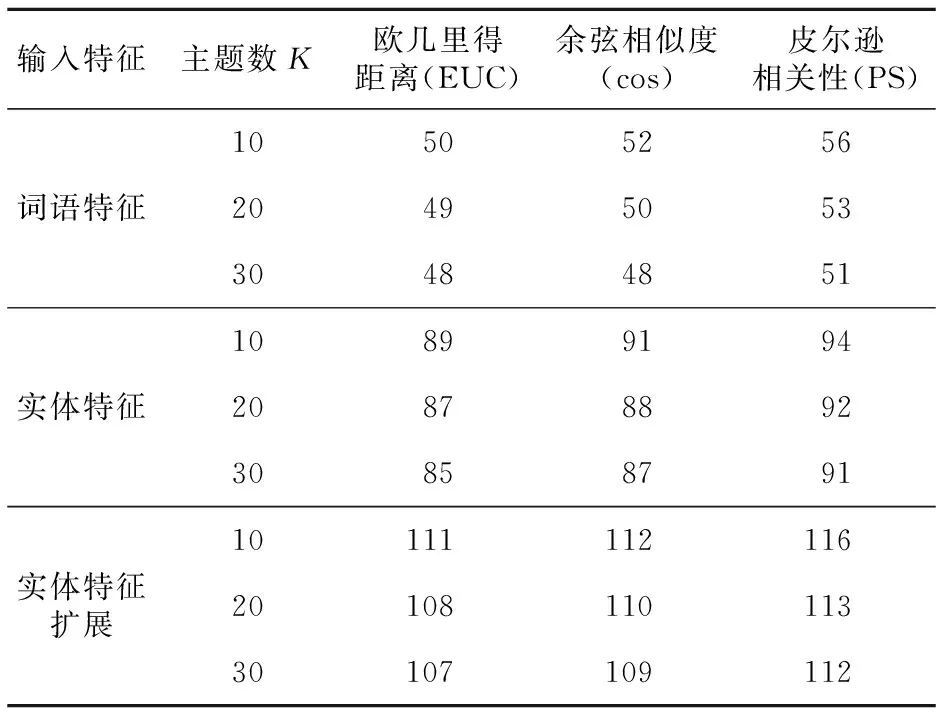
Table 5 Experiment results with different input features and number of topics表5 不同输入特征和主题数实验结果
由表5可知,(1)以实体特征扩展后数据作为输入,保持了诊断报告的语义特征和对应关系,同时一定程度上缓解了诊断报告实体特征稀疏的问题,取得了较好的实验效果。(2)在主题数K=10时,不同输入特征在各组排序数据中都取得了较好的效果。(3)利用皮尔逊相关性作为相似度计算的方法,实验效果较好。因此,后续的对比实验均以实体特征扩展作为输入,主题数K选择10,相似度计算采用皮尔逊相关性。
实验3 为了验证本文方法的性能,将本文方法与传统的异常检测的方法做比较。将上下文检测方法、异常点检测方法与本文方法进行了对比实验。实验根据相似度排序抽取出的50,100,150,200份诊断报告,根据异常诊断报告的数量,对比不同方法的性能。本文方法:计算实验数据中所有实例主题分布相似度,并根据所有诊断报告实例相似度由低到高进行排序。上下文检测方法:根据诊断报告数据偏离映射函数的程度进行排序。异常点检测:根据与实验数据集合的距离,将远离集合的诊断报告数据进行排序。本实验采用10-fold交叉验证的方式,实验结果如图2所示。
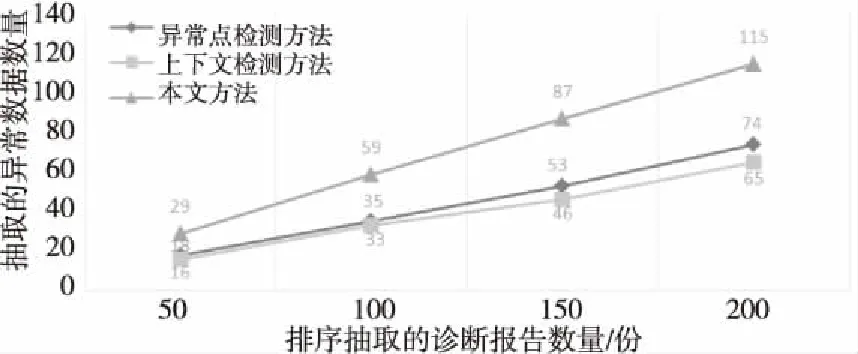
Figure 2 Experimental results comparison of different methods图2 不同方法实验结果对比
由图2可知,本文方法进行诊断报告的异常检测,在不同的抽取数量中的检测准确率提高显著,检测效果明显优于传统的异常点检测、上下文检测方法。因此,本文方法更适合缺乏高质量标注,数据特征稀疏的胸部X光片诊断报告。
实验4 由于根据实例主题分布的相似度无法准确确定检测异常诊断报告的阈值,所以本文将每一个诊断结论与影像描述中症状进行关系匹配,根据不匹配的数量来确定检测异常诊断报告的阈值。实验结果如表6所示。

Table 6 Experimental results on different thresholds表6 不同阈值的实验结果
由表6可知,当阈值设定为2以上的时候,虽然准确率有着很高的水平,但是召回率却急剧下降。当阈值设定在2以下时,虽然召回率有所提高,但是准确率出现了明显的下降。最终将检测诊断报告的阈值设置为2,取得了较好的实验效果。
4 结束语
本文提出了一种基于主题模型的胸部X光片诊断报告异常检测方法,适用于缺乏有效标注,数据高维稀疏,未登录词较多的胸部X片诊断报告异常检测。首先,利用双向LSTM-CRF模型结合该诊断报告文本数据自身的字符级特点(后缀特征),对诊断报告影像描述与诊断结论中的实体进行准确提取。然后,依据诊断报告自身数据的特点及领域专家知识对诊断报告中的各类特征进行有效扩展和补充。最后,利用LDA模型对诊断报告中症状实体与结论实体进行特征匹配,对诊断报告进行异常检测。本文方法对胸部X光片诊断报告进行异常检测取得了很好的效果,但是对于其他诊断结论较短、实体较少或者缺乏领域知识进行特征扩展的、高维稀疏的诊断报告异常检测的准确率仍有待提升。后续将围绕存在以上问题的诊断报告开展进一步的研究工作。
猜你喜欢
中等数学(2022年7期)2022-10-24
中学生数理化·高一版(2021年1期)2021-03-19
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
南风窗(2016年26期)2016-12-24
小猕猴智力画刊(2016年5期)2016-05-14
南风窗(2015年22期)2015-09-10
南风窗(2015年7期)2015-04-03
