
浅谈集成树算法在保险赔偿领域的应用
2020-05-09 09:47刘婷婷
青年与社会 2020年3期
刘婷婷


摘 要:如果某人今天买了一份保险,万一明天或者后天就发生了风险,那么保险公司赔给他的钱是他今天所花的钱的倍数,这是衡量一张保单保障意义的有力数据。机器学习方法在如今的许多领域都发挥着重要作用,在目前众多广泛应用于各种学习任务的机器学习算法中,集成树算法属于其中的佼佼者。文章对集成树算法中的XGBoost算法研究分析,通过在保险理赔预测的应用展示了其算法功能的优越性能。
关键词:XGBoost;保险理赔;预测;机器学习
据统计,在2015年度Kaggle数据挑战赛中,29个冠军案例中有17个采用XGBoost方法,其中有8个解决方案仅使用XGBoost算法,其它的解决方案采用XGBoost与神经网络联合的方法。这些竞赛涵盖了多个领域:商店销售预测,高能物理事件分类,网页文本分类,顾客行为预测,运动检测,广告点击率预测,恶意软件分类,产品分类,危害风险预测。当然,不可忽视数据分析和特征工程在这些解决方案中发挥了重要作用,但XGBoost是参赛者青睐的选择,这一事实表明了其算法的超强性能。
一、XGBoost模型的建立
(一)XGBoost树的定义
XGBoost算法原理于2004年由陈天奇提出,是在GBDT(梯度提升决策树)的基础上对Boosting算法的改进,解决GBDT算法模型难以并行计算的问题,实现对模型过拟合问题的有效控制。
GBDT是一种迭代的决策树算法,为便于求解目标函数,GBDT常用回归树生长过程中,错误分类产生的残差平方作为损失函数,即通过拟合残差平方构造损失函数。随着树的生成,损失函数不断下降;回归树生长过程每个分裂节点划分时枚举所有特征值,选择使得错误分类最少、损失函数下降最快的特征值作为划分点;每一棵回归树学习的是之前所有树的结论和残差,拟合得到一个当前的残差回归树;最后,累加所有树的结果作为最终结果。
GBDT 回归树求取目标函数最优解只对平方损失函数方便求得,对于其他的损失函数变得很复杂。以最小平方损失确定分裂节点的选取,仅考虑了回归树各叶节点预测精度,在追求高精度的同时易造成模型复杂度提升,造成回归树的生长出现过拟合。
XGBoost算法模型对GBDT上述两个不足进行改进。XGBoost算法增加了对树模型复杂度的衡量,在回归树生成过程分裂节点的选取考虑了损失和模型复杂度两个因素,在权衡模型低损失高复杂和模型低复杂高损失后,求取最优解,防止一味追求降低损失函数产生过拟合现象,且速度快,准确性高,是有效的集成学习算法。
(二)XGBoost目标函数
XGBoost 整体目标函数为:
其中,是损失函数(通常是凸函数),用于刻画预测值和真实值之间的差异;为模型的正则化项,用于降低模型的复杂度和过拟合问题,模型目标是最小化目标函数。
二、实证分析
(一)数据来源与描述
文章的数据来源于Allstate公司给出的数据,当你被严重的车祸摧毁时,你的注意力集中在最重要的事情上:家人,朋友和其他亲人。与您的保险代理人一起处理是您希望花费时间或精力的最后一个地方。这就是Allstate不断寻求新的方法来改善他们保护的1600多万户家庭的理赔服务的原因。该数据集公有188318条数据,有132个特征。特征中有15个连续特征,116个离散特征。其中id是int64,loss是float64,通过处理分析,数据中没有缺失值。
(二)数据预处理
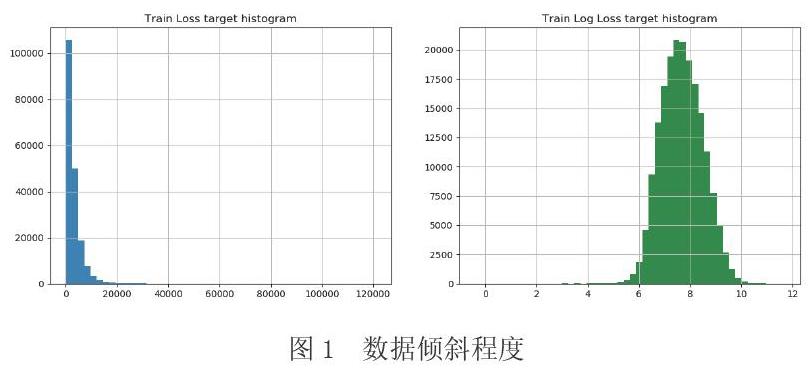
通过观察离散值分布的情况,可以看出,大部分的分类特征(72/116)是二值的,绝大多数特征(88/116)有四个值,其中有一个具有326个值的特征,考虑是记录的天数。对于赔偿值loss,损失值中有几个显著的峰值表示严重事故。这样的数据分布,会使得这个功能非常扭曲会导致回归表现不佳。
数据越倾斜越不利于建模,越均匀越利于建模。将类别数据的类别用数字替换,對数据进行对数变换可以改变数据的倾斜程度。如图1所示,左侧是没有进行处理的loss值的直方图,右侧是np.log后的loss值的直方图,右侧图像分布更均匀,转换之后赔偿值趋于正态分布,因此选择右侧图像对应的loss作为目标值,见图1。
(三)回归建模
XGboost是Gradient Boosting 算法的改进版本,XGBoost对损失函数生成二阶泰勒展开,并在损失函数之外对正则项求得最优解,充分利用多核CPU 的并行计算优势,提高了精度和速度。算法步骤可表示如下:
从上述步骤可知,XGBoost 在优化目标函数的同时做了预剪枝,从而可以得到最优参数,使预测结果更准确。
(四)评价标准
对于保险行业理赔的预测分析,本次研究更加关注预测的损失值和真实赔偿损失值之间的误差大小,通过观察误差可以判断出模型的好坏,因此选用平均绝对误差,能更好地反映出预测值误差的实际情况。
(五)实验结果与结论分析
首先,训练一个基本的xgboost模型,然后进行参数调节通过交叉验证来观察结果的变化,使用平均绝对误差来衡量mean_absolute_error(np.exp(y),np.exp(yhat))。
Xgboost自定义了一个数据矩阵类DMatrix,会在训练开始时进行一遍预处理,从而提高之后每次迭代的效率。在设定50棵树的情况下,得到了一个基准结果:MAE=1218.9,并且没有发生过拟合。
在建立了100棵树的情况下,得到了新的记录MAE=1171.77,比第一次的要好,考虑到60棵树之后又一点点过拟合,查看了60棵树之后的预测情况,没有太大的影响。
树的深度和节点的权重这些参数对xgboost性能影响最大,因此,在调整参数的时候应该首先选择他们。max_depth指的是树的最大深度,增加这个值会使模型更加复杂,也容易出现过拟合,深度3-10是合理的。min_child_weight是正则化参数,如果树分区中的实例权重小于定义的总和,则停止树构建过程。
三、结语
建立合理有效而又科学的保险赔偿预测模型,能为保险等服务机构提供更加可靠而科学的决策支持,减少不必要的损失,意义非常重大。文章在对比多个集成算法模型基础上,建立基于目前最流行及性能较好的XGBoost集成算法的理赔预测模型,并在Allstate开源数据集上,对XGBoost算法进行比较与对比研究。实证结果表明,在机器学习等领域具有显著优势的XGBoost算法对预测模型的建立性能很优越。
参考文献
[1] Chen T, He T, Benesty M, et al. Xgboost: extreme gradient boosting[J].R package version 0.4-2,2015:1-4.
[2] 连克强.基于 Boosting 的集成树算法研究与分析[D].北京:中国地质大学 (北京),2018.
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
疯狂英语·初中天地(2018年6期)2018-11-24
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
