
基于训练网络的目标检测方法及应用
2020-05-11 08:11任江涛李定主屠惠琳
火力与指挥控制 2020年4期
任江涛,李定主,屠惠琳
(北方自动控制技术研究所,太原 030006)
0 引言
近年来,随着大数据技术的不断发展,图像目标的识别分类已经成为非常重要的研究热点。在地物遥感图像识别领域,通过目标识别分类,可以在遥感图像中获取不同目标的位置信息以及具体目标的类型[1]。在民用方面,可以用于资源调查、环境检测以及防灾减灾等;在军用方面,可以用于军事测绘、战略侦查以及目标打击等[2-3],因此,针对遥感影像的目标识别分类具有十分重要的意义[4-6]。近几年来,随着对地观测技术的进步,遥感数据有着非常明显的大数据的特征,从而可以为目标识别分类提供大量的可用数据,在此基础上,基于深度学习的遥感目标识别分类得到了广泛的应用[7-9]。
2014 年Ross Girshick 等人提出了目标检测算法R-CNN(Region-based Convolutional Neutral Network)[10],其结合了卷积神经网络[11]和区域候选(Region Proposal)方法,在目标检测与行人检测上取得了较好的成绩,然而也存在着效率低下,花费时间长等一系列问题。随后,Ross Girshick 等人提出了Fast R-CNN,Shaoqing Ren 等人在Fast R-CNN 的基础上提出了Faster R-CNN 模型[12],将区域建议、特征提取、建议框回归等整合到同一个端对端的网络中,有效地减少了算法对计算资源的占用,大大加快了模型的速度,在目标检测领域拥有最好的检测精度,是目前应用最为广泛的模型之一。
在Faster R-CNN 模型中的特征提取阶段,VGG16 模型是目前使用较多的训练网络。在网络深度方面,VGG16 网络相比之后出现的inception 网络和深度残差网络而言层数太少,不能更好地提取高维度的特征,从而在特征提取上不占优势;在速度方面,VGG16 网络的网络参数数量过多,占用了太多的内存和算力,严重影响模型的训练速度和检测速度;在模型结构方面,VGG16 模型网络结构简单,无法解决训练中出现的梯度爆炸以及梯度消失的问题,从而严重影响模型的训练,以及最后模型的检测精度。
本文针对Faster R-CNN 模型中的VGG16 训练网络提取能力弱、检测速度慢等问题,对Faster R-CNN 模型中原有的VGG16 训练网络进行改进并进行实验,分别替换为inception、ResNet50 以及ResNet101[13]等CNN 网络模型,在遥感卫星图像飞机、车辆、水箱和操场等数据集上进行训练并进行对比实验。实验结果表明,本文中提出的新模型相比传统模型,在多种遥感目标上都具有识别精度高和识别速度快的优势。
1 Faster R-CNN 网络模型构建
Faster R-CNN 将目标检测所需的候选区域生成、特征提取、分类器分类以及回归器回归整合到一个深度神经网络框架上运行,并且全部运行在GPU 上,与Fast R-CNN 相比,Faster R-CNN 最大的优势就是提出了区域建议网络(Region Proposal Networks,RPN),用来生成高质量建议区域框。RPN的出现取代了Fast R-CNN 中的选择性搜索(Selective Search,SS)方法。
Faster R-CNN 模型整体构造如图1 所示。
Faster R-CNN 由4 个部分组成:
1)卷积神经网络,用于提取图片的特征,输入为整张图片,经过CNN 网络前向传播至最后共享的卷积层,一方面得到供RPN 网络输入的特征图,另一方面继续前向传播至特有卷积层,产生更高维特征图;

图1 Faster R-CNN 网络模型
2)RPN 网络,用于推荐候选区域;
3)感兴趣区域池化层(Region of Interest pooling,RoI pooling),将不同大小的输入转换为固定长度的输出;
4)分类和回归,这一层输出候选区域所属的种类,以及候选区域在图像的精确位置。
1.1 RPN 网络
RPN 网络是Faster R-CNN 组成的一部分,是目前最先进的建议框提取算法。RPN 网络的输入为一张任意大小的图片,输出为一系列矩形的目标建议选择框。特征图在RPN 网络与训练网络之间是共享的,这样可以大大缩短提取过程的时间,加快运行的速度,并节约大量的内存和计算力。
RPN 的核心机制在于使用全卷积网络(Fully Convolutional Network,FCN)产生建议区域,其本质是基于滑动窗口的无类别目标检测器。RPN 独有的锚点(anchors)机制和边框回归机制可以得到多尺度的建议区域,并通过采用anchors 来解决边界框列表长度不定的问题,即在原始图像中统一放置固定大小的参考边界框。不同于直接检测目标的位置,RPN 将图像转化为两部分解决:对每一个anchor 而言,anchor 是否包含相关的目标,以及如何调整anchor 以更好地拟合相关的目标。
Anchor 的机制是:预训练网络卷积层的最后一层特征图上的每一个像素映射回原图,并以该点所在区域的感受野中心为基准点,生成k 种不同缩放比例和宽高比的anchors,其面积大小分别为1282、2562和5122,每种面积又分成3 种长宽比,长宽比分别为:1∶1、1∶2 和2∶1。
RPN 网络中的两个卷积层/全连接层,第1 个卷积层将特征图中每个滑动窗口的位置编码成一个特征向量,然后传递到第2 个卷积层;第2 个卷积层输出两个特征向量,分别为对应的每个滑动窗口位置输出的k 个区域得分,表示该位置的anchor为物体的概率,这部分的输出特征向量长度为2×k(每个anchor 都对应有着正样本和负样本之分,即物体的概率与不是物体的概率);以及k 个回归后的区域建议(框回归),目的是输出目标所在的精确位置,一个anchor 对应4 个框回归参数,因此,框回归部分的总输出特征向量长度为4×k。最后得到区域建议的得分和回归建议框,输出到ROI 池化层。不是所有的anchor 都用来训练,随机抽取128 个正样本和128 个负样本进行训练。
1.2 网络结构
Faster R-CNN 目前提供了3 种训练网络模型,分别是ZF 模型(小型)、VGG_CNN_M_1024 模型(中型)和VGG16 模型(大型),以对应不同的训练场合,其中最常用的是VGG16 网络。但是VGG16网络训练速度缓慢,耗费大量的计算资源,而且在网络深度上只有16 层,在抽象的高层次特征提取上不占优势。本文拟采用inception 网络、ResNet50以及ResNet101 来代替VGG 网络进行特征的提取。
1.2.1 inception 网络
Inception 网络模型的结构如图2 所示,其中inception1 模块和inception2 模块的具体网络结构如图3 和图4 所示:
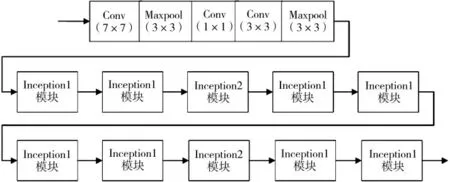
图2 inception 网络的基本结构
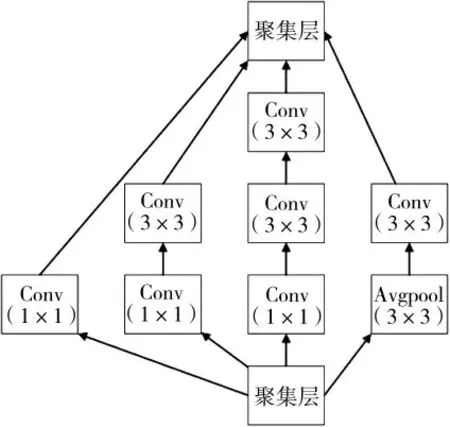
图3 inception1 模块的网络结构
Inception 网络采用了模块化inception 结构,方便增添和修改。Inception 网络在多个不同尺寸的卷积核上同时进行卷积运算后再进行聚合,并使用1×1 的卷积进行降维以减少计算成本。该实验使用的inception 网络共使用了10 个inception 模块。原始输入图像为224×224×3 和600×600×3 两种。各个卷积层的卷积核大小不同,分别为7×7,3×3以及1×1,卷积后进行ReLU 非线性激活函数。池化层采用maxpool 和avgpool,池化核大小为3×3 和7×7。最后的卷积层输出7×7×1 024 大小的特征图,RPN 和Fast R-CNN 共享这个特征图。
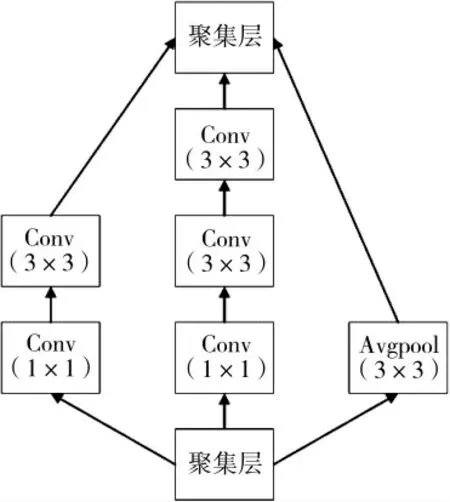
图4 inception2 模块的网络结构
1.2.2 深度残差网络
随着网络的深度变化,出现了训练集准确率下降和错误率上升的现象,即网络的退化现象。错误率升高的原因是网络越深,梯度消失的现象就越明显,在后向传播的过程中,无法有效地把梯度更新到前面的网络层,靠前的网络层参数无法更新,导致训练和测试效果变差。深度残差网络正是针对这种问题而出现的。
深度残差网络的基本单元如图5 所示。
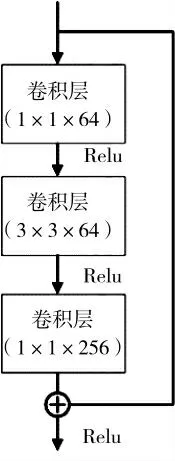
图5 深度残差网络的基本单元结构
深度残差网络共有5 种深度不同的网络结构,根据深度分别命名为ResNet18、ResNet34、ResNet50、ResNet101 以及ResNet152,其中ResNet50 和ResNet 101 得到了广泛的应用。本文选择ResNet50 和ResNet101 深度残差网络模型作为Faster R-CNN 的训练网络。
ResNet50 的网络模型结构如下页图6 所示。
该实验中的ResNet50 网络共使用了16 个残差单元,共50 层。每个单元有3 个卷积核,其大小分别为1×1,3×3 以及1×1,如图5 所示,卷积后进行ReLU 非线性激活函数。
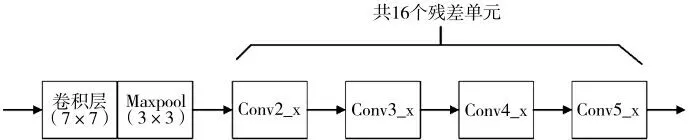
图6 ResNet50 的网络模型结构
ResNet101 网络的结构和ResNet50 网络一致,ResNet101 中残差单元共有33 个。最后的卷积层输出7×7×1 024 大小的特征图,同时输入到RPN 和Fast R-CNN 中。
2 实验分析
2.1 数据准备
实验采用的数据均来自西北工业大学的Yi Yang 等人的UCMerced_LandUse[14]数据集,以及武汉大学的Jingwen Hu 的AID[15]数据集,图像大小分别为256×256 和600×600。拟选取飞机、汽车、水箱以及操场等4 种类别进行实验。因数据样本太少,为防止出现特征不明显的情况,需要进行数据扩充的操作,采用几种常见的数据扩充方式进行操作:随机修剪、旋转变换、色彩抖动、噪声扰动等。经过数据扩充,得到共计7 891 张图片,按照4∶1 的比例将数据分为train set 和eval set 进行训练。
原始图像文件均为JPEG 格式,参照VOC2007数据格式,对原始图像进行处理和标注。原始图像的目标坐标信息为xml 格式的文件,使用工具labelImg对图像标注,然后在同一个文件夹下生成同名的xml格式的位置文件。共获得飞机目标6 451 个、汽车目标3 645 个、水箱目标5 366 个、操场目标1 492 个。
2.2 实验过程及结果
实验在windows10 操作系统,anaconda3 环境下进行,配置了NVIDIA GeForce GTX 1060 的显卡,显存为6 GB。选择在TensorFlow深度学习框架下进行实验。图片以及图片位置信息的xml 文件输入到Faster R-CNN 中。分别使用inception 网络、ResNet50 网 络 和 ResNet101 网 络 作 为 Faster R-CNN 的训练网络。迭代次数设置为60 000 次,学习率采取阶梯下降策略,初始值为0.002,40 000 步之后下降为0.000 2。
训练得到的模型在WHU-RS19[16]数据集上进行测试,该数据集是来自武汉大学的遥感数据集,包含机场、桥梁等共计19 种遥感目标,图片大小为600×600。共选取326 张图片在训练得到的不同模型上进行测试。测试得到的检测效果如图7 所示,图中分别为飞机、车辆、水箱以及操场的目标识别结果效果图,图中文字为该目标的类别名,数字为该类别的置信度。在3 种不同训练网络下,针对不同遥感目标的识别精度的对比结果如表1 所示。

图7 目标识别结果效果图
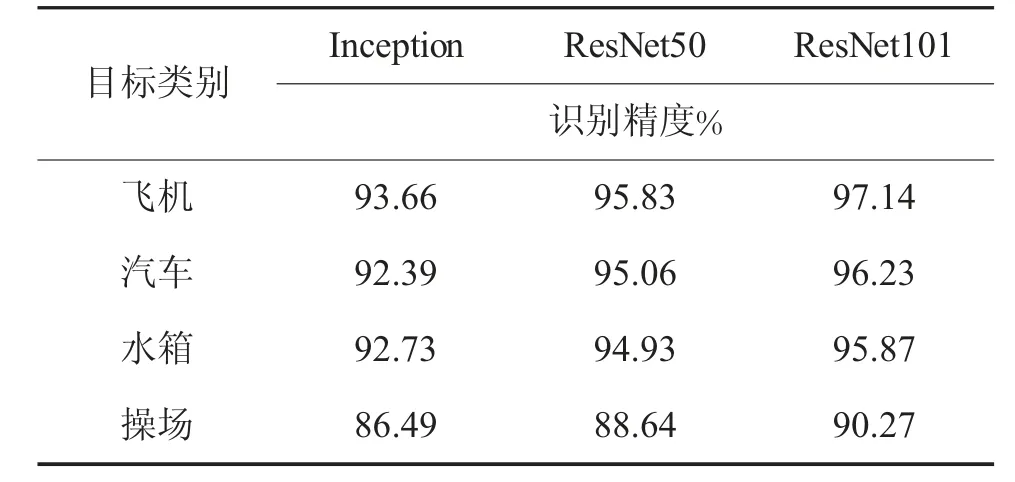
表1 几种模型识别精度对比
通过比较表1 可以看出,不同训练网络对于目标识别精度的影响。与inception 网络相比,深度残差网络层数更深,而且深度残差网络的残差单元可以很好地解决深层次网络的退化问题和梯度消失、梯度爆炸的问题,因此,在4 类目标上具有最高的识别精度。
本文给出了基于VGG16、inception 网络、ResNet 50 和ResNet101 的Faster R-CNN 模型在飞机遥感数据集上的实验结果,不同训练网络下的识别精度对比如表2 所示,不同训练网络下的平均识别速度对比如表3 所示。

表2 VGG16 与3 种训练网络的精度对比识别精度%

表3 VGG16 与3 种训练网络的速度对比识别速度/s
在识别精度上,使用VGG16 网络的Faster R-CNN 模型在飞机数据集的识别精度为92.87%,在4 种模型对比中处于劣势,而使用层数最深ResNet101 网络的Faster R-CNN 模型拥有最高的识别精度,达到了97.14%。
在识别速度上,使用inception 网络作为训练网络的Faster R-CNN 模型拥有最快的识别速度0.13 s,相比VGG16,inception 网络使用了特有的inception 模块结构,大幅度降低了参数数量,因而在速度上有很大的提升;相比VGG16,ResNet50 和ResNet101 在参数数量上有所减少,而且使用的shortcut 方法大幅度提升了计算效率,所以在识别速度上也有提升;相比inception 网络,ResNet50 和ResNet101 的结构更加复杂,具有更多的参数数量,因而在速度上不及inception 网络。
3 结论
本文在TensorFlow 深度学习框架下,搭建了基于inception 网络、ResNet50 网络和ResNet101 网络作为训练网络的Faster R-CNN 模型,通过对高分辨率遥感图像中的4 种特定目标进行识别,研究了不同训练网络对于识别结果的影响。实验结果表明,相 比VGG16 网 络,inception 网 络、ResNet50 和ResNet101 在高分辨率的遥感图像数据集上均展示出了更好的识别精度和识别速度。在识别精度上,inception 网络不及ResNet50 和ResNet101;在识别速度上,inception 网络优于ResNet50 和ResNet101。今后将针对更加复杂的遥感目标以及小样本数据上的目标识别开展进一步的研究工作。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
机械工业标准化与质量(2022年8期)2022-10-09
农业工程学报(2022年12期)2022-09-09
成都信息工程大学学报(2022年2期)2022-06-14
心理学报(2022年4期)2022-04-12
北京大学学报(自然科学版)(2022年1期)2022-02-21
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
北京航空航天大学学报(2020年10期)2020-11-14
