
基于自相似流量水平分级预测的网络队列调度算法
2020-05-11 03:02魏德宾沈婷杨力戚耀文
通信学报 2020年4期
魏德宾,沈婷,杨力,戚耀文
(1.南京理工大学自动化学院,江苏 南京 210094;2.大连大学信息工程学院,辽宁 大连 116622;3.大连大学通信与网络重点实验室,辽宁 大连 116622)
1 引言
随着通信技术的发展,网络中业务种类和业务量都在迅速增加,良好的服务质量需要较高的链路带宽来保证。虽然人们可以通过提高硬件性能来增加网络带宽,但是仍然难以满足日益增长的用户需求和避免网络中某些路由或交换节点的拥塞。当拥塞发生时,如果没有有效的队列管理和调度方法,大量的数据分组由于不能及时转发,积压在路由器的缓冲区中。极端情况下会导致缓冲区溢出,丢失分组,网络将无法为业务提供保障。
队列调度是指路由器以数据流的相关信息为依据,按照某种规则从队列中选择待转发的分组,从而为数据流提供公平或有差别的服务。目前,队列调度算法主要有3 种,分别是简单队列调度算法、基于时间戳的调度算法和基于轮询的调度算法。
简单队列调度算法包括先来先服务调度算法、随机调度算法和基于优先级的调度算法等。先来先服务调度算法按照分组到达顺序确定分组服务顺序,实现简单,管理方便,且最大时延可由队长决定,但其不能为高优先级的分组提供服务质量(QoS,quality of service)保障,无法支持区分服务。随机调度算法是在所有等待队列中随机选择转发分组,该方法可在某种程度上满足统计意义的性能保证,但不能满足确定性的时延保证。基于优先级的调度算法虽然能为高优先级分组提供QoS 保障,但只有当高优先级队列都为空时,低优先级队列分组才会被调度,这会导致低优先级队列的“饿死”现象。
基于时间戳的调度算法通过对分组记录开始服务时间和结束服务时间进行排序,选择具有最小服务时间的分组进行调度。这类算法主要是对Parekh 等[1]提出的最理想的队列调度算法模型——通用处理器共享(GPS,generalized processor sharing)的近似模拟,如加权公平队列(WFQ,weighted fair queuing)、最坏情况加权公平队列(W2FQ,worst-cast weighted fair queuing)和开始时间公平队列(STFQ,start time fair queuing)等,具有良好的时延性能和公平性,但时间复杂度高,实现困难。
基于轮询的调度算法是指调度器轮询地对每个队列中的分组进行调度,一次调度发送一个分组,不考虑业务的优先级和处理能力,使不同队列平等地使用带宽。该算法实现简单、复杂度低,适合高速分组网络,但不能解决业务不同优先级的需求和变长分组带来的不公平性。因此,研究人员提出了一系列改进算法,如加权轮询(WRR,weighted round robin)、差额轮询(DRR,deficit round robin)、差额加权轮询(DWRR,deficit weighted round robin)[2]等。文献[3]依据各队列的平均分组到达率,调整各队列的调度权值,提出了 PFWRR(proportion fairness WRR)算法。文献[4]提出了逐次最小权值轮询(SMRR,successive minimal-weight round robin)调度算法,它能保证在每个轮次中为每个活动数据流提供与本轮次中的最小权值相当的服务机会。文献[5]综合考虑网络中分组长度及队列权重,提出了一种改进型WRR(EWRR,enhanced WRR)算法。文献[6]针对传统WRR 算法权值分配和调度次序固定不变无法适应网络负载加重带来的时延增大问题,提出了可变差额加权轮询(VDWRR,variable deficit WRR)调度算法。文献[7]针对DWRR 在考虑分组截止时间时,对即将过期的分组简单转发或直接丢弃,而不是防止违反最后期限的问题,提出了一种破产差额加权轮询(I-DWRR,insolvency-deficit WRR)调度算法。文献[8]针对传统WDRR 带宽利用不充分的问题,提出了一种负差额加权轮询(N-DWRR,negative-deficit WRR)算法。文献[9]针对大型数据中心数千个虚拟机之间实现负载平衡的问题,提出了一种基于神经网络的动态负载平衡算法。
上述的调度方法虽然各有优势,但它们缺乏对网络流量特性的考虑。已有的研究表明,局域网、广域网、万维网等不同通信网络的实际网络流量都具有自相似性[10-12]。网络业务流自相似性的发现和研究推翻了之前网络流量短相关的基础假设。由于自相似性网络流量的突发性更强,持续时间更长,需要更大的网络资源和带宽,容易导致网络路由或交换节点发生拥塞,这使网络流量的统计特征提取、排队性能分析和缓冲区设置等均有所变化,同时也给网络交换节点的队列管理和调度带来挑战。
通过文献检索发现,针对上述问题,国内外的研究(如文献[13-15])都是基于网络流量自相似性对主动队列管理算法的影响展开的,缺少基于网络流量自相似性的队列调度算法研究。为此,本文综合考虑网络流量自相似性对网络性能的影响和不同数据业务的传输需求,在传统差额加权轮询调度算法的基础上,根据自相似流量水平分级预测结果,动态分配权值和更新服务量子,并根据业务优先级和队列等待时间对队列进行排序,完成调度,从而达到减小队列时延、降低分组丢失率的目的。
2 DWRR 队列调度算法
队列管理与调度算法基本原理如图1 所示。队列管理机制一般位于队列输入端,依靠网络节点主动感知缓冲区的占用率来管理缓存,在网络发生拥塞时通过分组丢失管理队列长度。队列调度机制则在队列的输出端,按规则决定下一次要发送的分组,管理各流之间的带宽分配。

图1 队列管理与调度算法基本原理
DWRR 算法为每一个队列分配的权值是基于字节数的,其中主要参数定义如下。
1)权值。分配给各队列的输出端口带宽的比例。
2)差值计数器DC。在某一服务周期内,每个队列在每次进行调度服务时允许队列传输的字节数。
3)服务量子q。用字节数表示,正比于其队列权值。调度器对某队列调度服务结束后,在下一次轮询到此队列时,将此队列差值计数器的值增加服务量子,为此队列调度服务做准备。
DWRR 算法针对网络分组大小可变的情况,调度器依次服务当前非空队列,基本调度过程如图2所示,其中阴影部分为已经调度出去的分组。如果此队列首部等待发送分组长度小于或等于DC 值,则发送此分组,在差值计数器中减掉相应的字节数,并反复发送分组,直到此队列首部等待发送分组长度大于DC 值,调度器将移向下一队列,此时剩下的DC值累积到下次轮询。如果此队列为空,DC 值仍有剩余,设置DC 值为0,调度器移向下一队列。
3 基于流量分级预测的P-DWRR 算法
鉴于现有队列调度算法没有考虑网络流量的自相似特性,导致数据分组时延和时延抖动增大、分组丢失率增高的问题,本文提出 P-DWRR(prediction DWRR)算法,即在原DWRR 算法的基础上采用基于流量自相似特性的流量分级预测与队列优先级的权值设定:每隔一定的时间间隔Δt,根据流量当前的水平等级预测下一个时间间隔的流量水平等级,进而依据流量水平等级动态地调整每个队列的权值和服务量子,再根据业务优先级和队列等待时间调整调度顺序。
3.1 自相似过程
设X={Xi:i=1,2,…}表示一个广义平稳离散随机过程,其中,Xi表示第i个时间间隔到达网络节点的数据分组数。X具有恒定均值μ和有限方差σ2,且其自相关函数为r(k)。
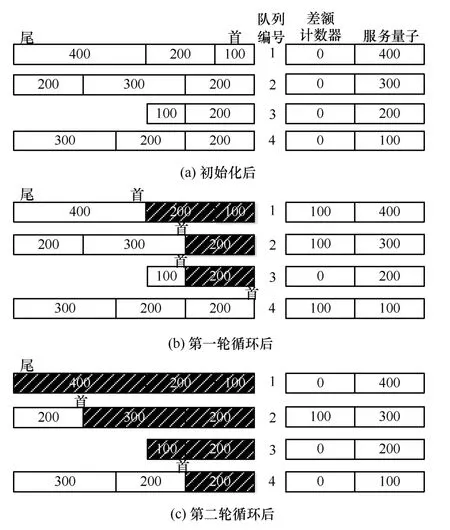
图2 DWRR 算法的调度过程
随机过程X的m阶聚集过程,i=1,2,…}的定义为
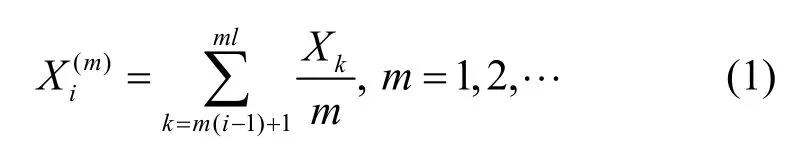
对每个m,X(m)都定义了一个广义平稳随机过程,其方差和自相关函数分别为V(m)和r(m)(k)。
如果随机过程X的自相关函数满足r(k)=,则称X为严格二阶自相似过程,且具有 Hurst 参数,0<β<1。如果随机过程X的自相关函数满足r(k)~ck-β,k→∞,其中c为正常数,则称X为长相关过程。如果随机过程X的m阶聚集过程X(m)的自相关函数满足,k∈Z+,则称X为渐近二阶自相似过程。
当H∈(0.5,1)时,随机过程具有自相似性,并且H值越大,自相似程度越高。文献[16]指出,当足够多的、服从重尾分布的ON/OFF 过程叠加在一起时,叠加后的过程具有自相似性,其 Hurst 参数为,其中α为重尾分布的形状参数。
3.2 流量水平分级
设{X(t),t∈T}是一个广义平稳随机过程,x(t)是随机过程的一个样本函数。
取2 个参数T1,T2> 0,在t时刻,可以使

其中,a表示在最近的过去[t-T1,t)上观察到的总流量,b表示在最近的未来[t,t+T2)上观察到的总流量,V1和V2表示最近的过去和最近的未来的复合随机变量。
假设随机过程{X(t),t∈T}具有有限的均值和方差,分别为,为了描述流量水平的“高”和“低”,本文将Vk的变化范围分为以下6 个级别

定义2 个新的随机变量L1和L2,其中L1为T1时间段上的流量等级,L2为T2时间段上的流量等级,则有
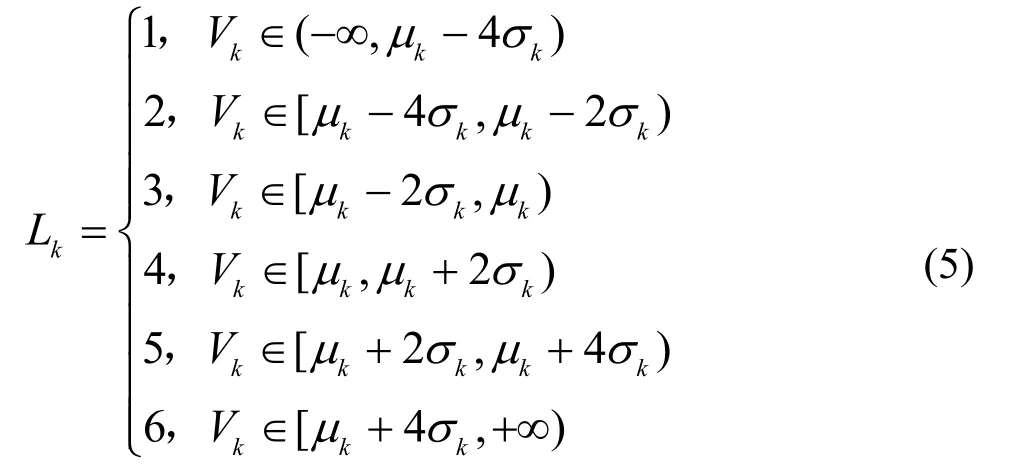
其中,k=1,2,Lk是Vk的函数,即Lk=Lk(Vk)。因此,如果Lk≈ 1,那么流量水平相对于平均值是“低”;如果Lk≈ 6,那么流量水平相对于平均值是“高”。
3.3 流量水平条件转移概率估计
取长度为ns 的聚合流量序列Xt,将其分为块,每个连续非重叠块的长度为T1+T2,并且对于第j=1,2,…,N个非重叠块,计算长度为T1,T2上的总流量,分别记为V1,V2。令 ℓ,ℓ′=1,2,…,6分别为T1,T2上的流量等级,hℓ为满足L1(V1)=ℓ(即T1上的流量等级为ℓ)的总块数,hℓ′为当L1(V1)=ℓ时,满足L2(V2)=ℓ ′(即T1的流量等级为ℓ 条件下,T2的流量等级为ℓ ′)的总块数,则流量水平条件转移概率计算式为。
3.4 P-DWRR 算法设计
P-DWRR 算法基本步骤介绍如下。
Step1根据n个队列优先级初始化队列的权值w0i(i=1,2,…,n),若最小权值不为1,则需将其设为1,其他权值同比例缩放,最后归一化为。
Step2计算过去Δt时间段内队列i的流量水平的具体等级ℓ,根据条件转移概率计算式Pr{L2=ℓ′|L1=ℓ},预测下一时间段队列i的流量等级为。
Step3根据的值将队列降序排列,其中ti为队列i的等待时间,依次从高到低进行调度,以平衡队列优先级、数据突发程度和队间公平性。
Setp4判断队列i是否为空,若为空,则设DC[i]=0,队列i=i+1;若不为空,转到Step5。
Step5根据计算出的流量等级改变权值,计算更新后的wi=w0i+Δwi,并将结果写入队列的权值表中,其中Δwi的计算过程介绍如下。
由式(5)可知,当流量等级小于3 时,该Δt时间段内流量水平远低于其均值,可减少其预先分配的带宽,即;当流量等级处于3~4 时,该Δt时间段内流量水平在均值上下浮动,令Δwi=0,即流量等级处于3~4 时,不调整其预先分配的带宽;当流量等级大于4 时,该Δt时间段内流量水平高于其均值,且随着流量等级的增大,数据突发程度增高,可将其预先分配的带宽增大,其中maxiΔwi表示队列i权值增量的最大阈值。
总的来说,权值增量Δwi的计算式为
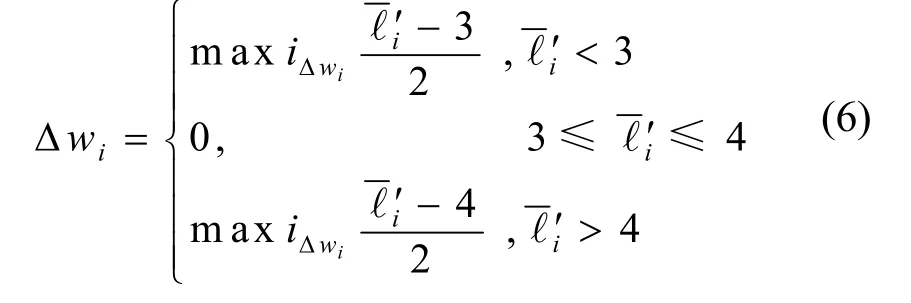
Step6从队列的权值表读取队列i的新权值wi,归一化为。
Step7根据队列i的权值,分配队列i一次可增加的服务量子,其中C为服务速率。
Step8判断当前调度队列中的首部分组的字节数和差值计数器值的关系。
如果差值计数器的值大于队列首部分组的字节数,则调度器允许从输出端口将该首部分组发送出去,并且差值计数器的值减去队列首部分组的字节数P_size。调度器在发送完该分组后,继续检测当前队列新的队列首部分组的字节数与差值计数器值的大小情况。如果该队列首部分组的字节数仍然小于差值计数器的值,继续发送该队列首部分组,并将差值计数器的值减去首部分组的字节数,重复该过程,直到当前队列为空,或者当前队列首部分组的字节数大于差值计数器值。如果队列为空,则转到Step4。
如果差值计数器的值小于当前队列首部分组的字节数,将拒绝对该队列进行调度服务,差值计数器将该次未使用的额度保留,并在下一次轮询到该队列时加入差值计数器中使用,然后转到Step4。
Step9如果所有队列中都没有等待调度转发的数据分组存在,则调度算法结束。
P-DWRR 算法中,计算均值和方差的时间复杂度均为O(n),队列调度算法的时间复杂度为O(n2)。P-DWRR 算法流程如图3 所示。
4 仿真校验
4.1 流量等级预测结果
为了得到自相似流量,本文利用100 个独立Pareto 分布的ON/OFF 源叠加模型来模拟网络自相似流,Pareto 分布的累积分布函数为
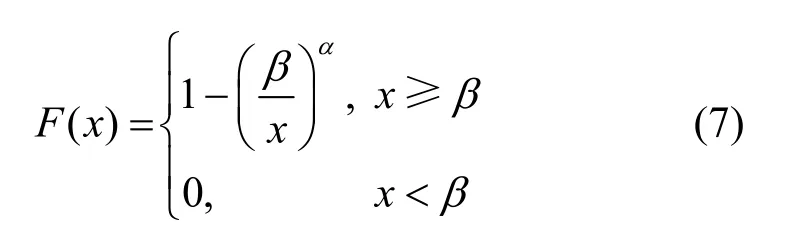
其中,α值分别取1.2、1.4 和1.6,由可得其对应的Hurst 参数值分别为0.9、0.8 和0.7,数据分组大小为128 B,ON 持续时间均值为50 ms,OFF 持续时间均值为10 ms,仿真时间长度为10 000 s,取T1=T2=5 s,通过3.2 节流量水平分级的条件转移概率计算方法,可得表1~表3。
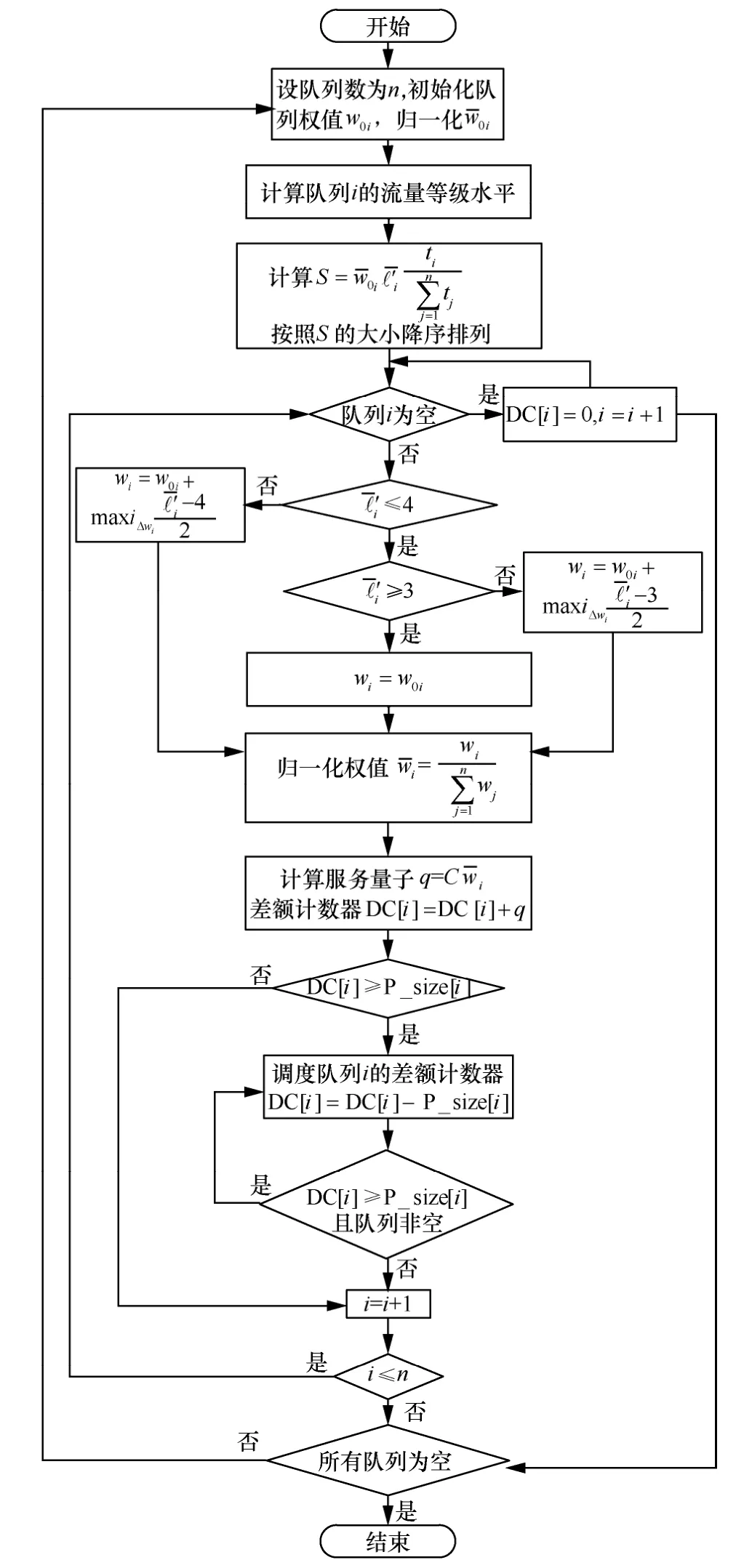
图3 P-DWRR 算法流程

表1α=1.2时流量水平条件转移概率
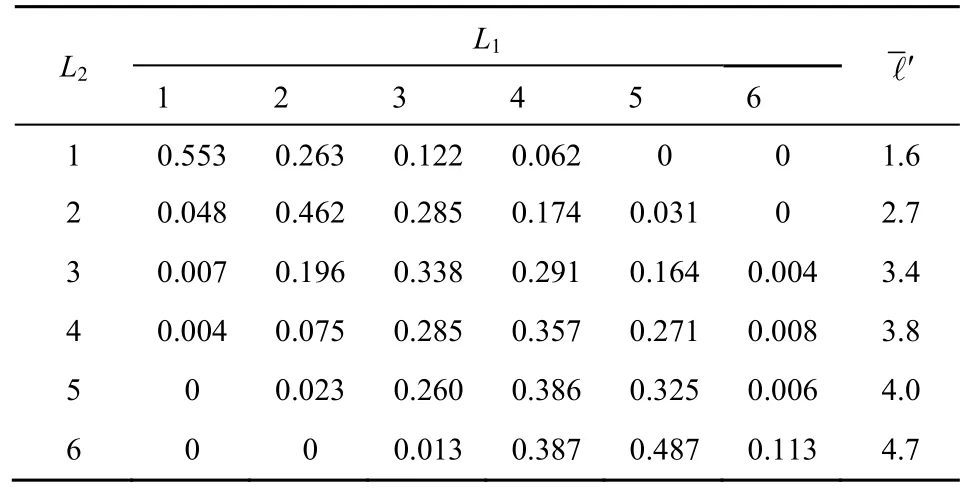
表2 α=1.4时流量水平条件转移概率
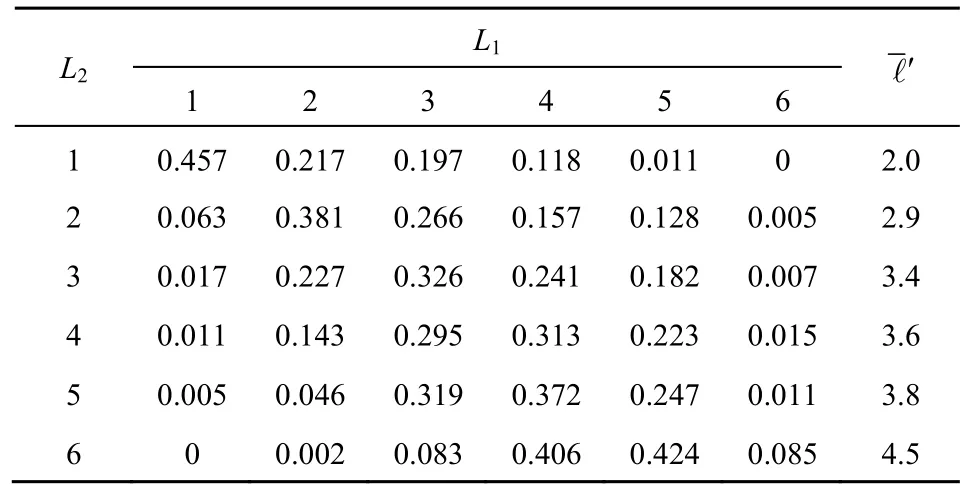
表3 α=1.6时流量水平条件转移概率
4.2 性能指标选取
1)分组丢失率
分组丢失率是指测试中丢失数据分组占所发送数据分组的比例,与数据分组长度和发送频率相关。在队列调度算法中,要求在缓冲区大小固定的情况下,尽可能降低分组丢失率。
2)时延
时延是指数据从网络的一端传送到另一端所需的时间,一般由发送时延、传播时延、排队时延和处理时延组成。在队列调度算法中,以排队时延作为衡量指标。
4.3 仿真结果及分析
仿真实验采用Matlab 仿真软件进行,实验使用的仿真拓扑结构如图4 所示。
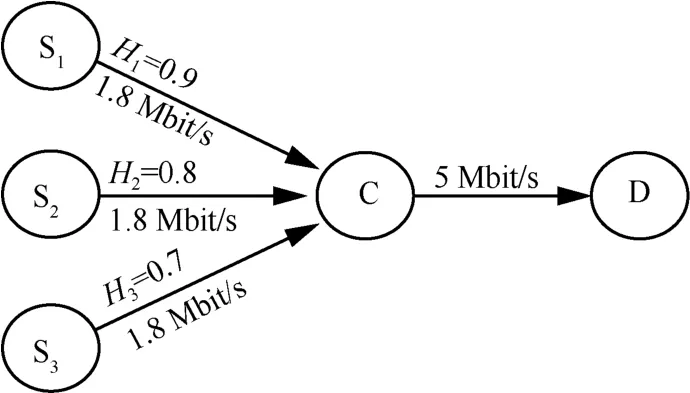
图4 仿真拓扑结构
图4 中,S1、S2和S3为3 个源节点,分别采用100 个独立Pareto 分布的ON/OFF 源叠加模型来模拟网络自相似流,具体参数与4.1 节的设置相同。其中Pareto 分布的α值分别取1.2、1.4 和1.6,对应的队列分别为队列1、队列2 和队列3,Hurst 参数值分别为0.9、0.8、0.7,3 个队列的优先级按由高到低的顺序排列,初始权值设置为3:2:1。C 为中间节点,D 为目的节点,中间节点服务速率为5 Mbit/s,源节点向中间节点的发送速率均为1.8 Mbit/s,maxiΔwi=1。
1)调度算法分组丢失率
当DWRR 算法[2]、VDWRR 算法[6]和P-DWRR算法在缓冲区长度从5 个分组变化到100 个分组时,分组丢失率曲线如图5 所示。
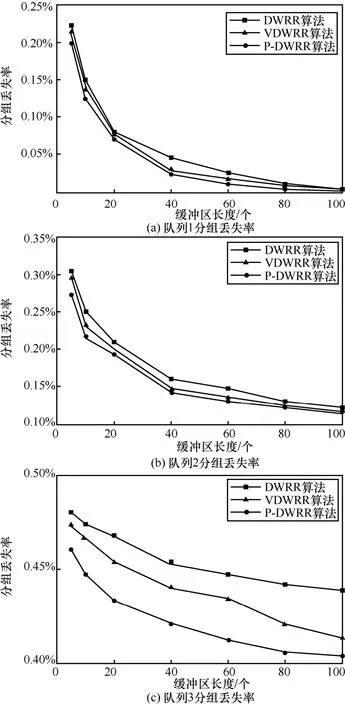
图5 3 个队列的分组丢失率曲线
在队列分组丢失率方面,随着缓冲区长度的增加,3 种算法的分组丢失率都呈现出减小趋势。其中在同一个缓冲区长度下分组丢失率的不同主要受队列权值设定的影响,而在同一个队列的不同调度算法的分组丢失率比较中,P-DWRR 算法的分组丢失率是最低的。以队列3 为例,在不同的缓冲区长度下,P-DWRR 算法相对于DWRR算法,平均分组丢失率降低了约7.1%;相对于VDWRR 算法,平均分组丢失率降低了约4.4%。这是由于本文的P-DWRR 算法根据优先级和队列的流量水平预测结果动态地调整权值和调度顺序,把调度过程划分为多个调度周期,在一个调度周期内根据事先预测的队列流量突发程度,设置一个合适的权值比例进行调度,减少队列由于流量突发导致从缓存中溢出的数据分组数量。
2)调度算法排队时延
DWRR 算法、VDWRR 算法和P-DWRR 算法的排队时延曲线如图6 所示。为了更好地观察时延的变化情况,设定此处的缓冲区长度为100 个分组,仿真时间为1 000 s。
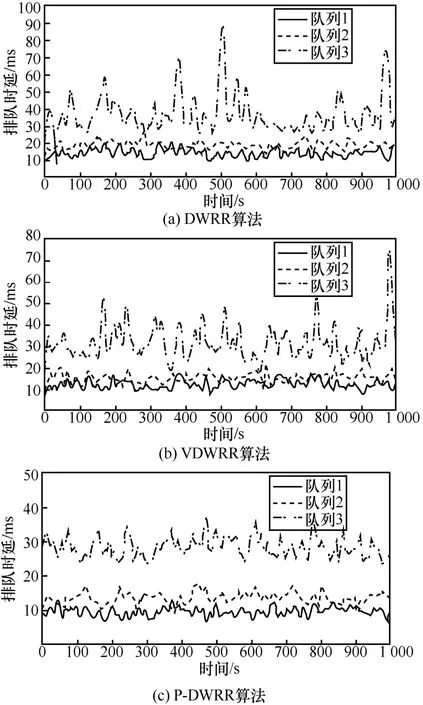
图6 3 种算法的排队时延曲线
3 种算法平均排队时延的比较如表4 所示。从表4 中可以看出,本文的P-DWRR 算法的平均排队时延是最低的。

表4 3 种算法平均排队时延的比较
以队列1 为例,P-DWRR 算法比DWRR 算法的排队时延降低了27%左右,比VDWRR 算法的排队时延降低了22%左右。这主要是因为不同Hurst参数下的流量突发程度不同,其流量水平在不断变化,相对于权值和调度顺序都不变的DWRR 算法、调度顺序动态调整的VDWRR 算法而言,本文的P-DWRR 算法权值的动态设置利用了预测的网络流量水平等级,更能贴合队列中实际的流量水平,同时因其调度顺序考虑了业务优先级和排队等待时间,使其排队时延更低。
3 种算法排队时延标准差的比较如表5 所示。从表5 可以看出,P-DWRR 算法的队列时延变化更平稳。

表5 3 种算法排队时延标准差的比较
5 结束语
本文通过分析网络流量自相似特性对队列调度算法影响以及不同业务的QoS 需求,设计了队列调度算法P-DWRR。队列调度算法在业务优先级决定队列初始权值的基础上,根据每个队列在一定时间间隔内流量等级的不同进行调整,实现权值的动态分配,并对队列的服务顺序进行调整。实验结果表明,P-DWRR 算法具有较好的时延和分组丢失性能,可满足网络不同业务类型的数据在不同自相似程度下的QoS 要求。
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22
舰船科学技术(2022年10期)2022-06-17
科学导报·学术(2020年26期)2020-10-21
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
微型电脑应用(2019年8期)2019-08-22
计算机与数字工程(2019年2期)2019-02-28
军营文化天地(2018年2期)2018-12-15
中国教育信息化·基础教育(2018年3期)2018-04-12
北京航空航天大学学报(2017年7期)2017-11-24
