
一种多源数据融合过程中的实体关联性计算方法
2020-05-15 09:22周凯,周宏
中国人民公安大学学报(自然科学版) 2020年1期
周 凯, 周 宏
(1.重庆警察学院信息安全系, 重庆 401331; 2.重庆市公安局网络安全保卫总队, 重庆 401120)
0 引言
随着信息技术的高速发展,社会数据化程度得到不断提升,数据源的多样化、数据量的巨大化以及数据集的关联化为信息的获取与分析提供了更为有利的条件,通过对多源数据进行组合或综合,利用多源数据的交叉印证与关联分析,可得到比单一数据源更精确、更全面的信息。在当前大数据时代,针对多源数据的融合已成为大数据分析处理的关键环节[1-5],尤其在公共安全领域中,基于多数据源融合的信息高效查询和分析,更有利于有价值情报的获取,为公安办案提供线索。
然而,由于数据管理系统在数据采集过程中的记录不准、人为操作等原因,错误数据、过时数据等数据不一致导致多个数据源对同一实体的联系存在冲突,因此,针对数据不确定信息的处理一直是多数据源融合所面临的主要问题之一,相关的解决方法、技术等学界已有一些研究。如:Yin等人[6]针对Web数据源相互关联的情况,提出了如何从多个数据源冲突信息中为每一个真实对象找出最准确的描述;王继奎等人[7]提出了一种非对称的数据值关联度算法,解决了主数据集成中常出现的因简写、少写、位置调换、错误书写等因素引起的多业务系统文本数据冲突问题;张志强等人[8]考虑到文本数据值之间相似性的判断,并结合数据源可信度及其依赖关系的计算,提高了从众多冲突数据中找到正确数据值的精度。在多数据源融合过程中,数据冲突的处理涉及到很多具体的方法与技术,基于不同的系统环境、数据特征等因素,针对实际的应用场景或问题,其方法和技术不尽相同。
面对在满足公安应用场景及业务需求中所遇见的多数据源融合过程中同一单值属性的实体对象关联多个对象值问题,即实体对象之间的关联产生多义性问题,本文基于应用场景的系统环境和业务数据特征,提出了一种结合时间属性权值和数据源权重的多数据源DatasourceRank算法,实现对实体对象之间真实度计算。该算法仅对实体对象相关联的数据进行计算,以数据源为基准单位,结合实体关系的时间属性以及各数据源权重,计算实体对象之间的关联度,从而发现当前的实体对象之间真实关联关系。其优点在于,可基于查询信息实时进行计算,并依据关联度高低向用户推荐检索结果,为业务分析工作提供更加精准的信息。
1 问题分析与描述
在本应用场景中,数据平台中的数据源有数百种,数据量多达两万多亿条,且每天还以数十亿条的量在不断增加。但是,数据源中的数据来源复杂,质量良莠不齐,多存在由于原始记录不准、更换号码、人为操作等原因,造成不同数据源中同一个号码可能关联不同的用户的情况,见图1。当出现这种情况时,如何高效计算该号码与每个用户的关联度,找出当前最有可能的使用人就是至关重要的问题。

图1 同一号码在不同数据源中与用户之间的关联关系
在本应用场景中,时间属性是重要的因素。比如,某个手机号码在2002~2006年系甲使用,但2007年至今该号码被甲销号后,又由运营商分配给乙使用,则该两组数据均为真实数据,但从信息对于业务工作的价值度来看,后组数据的重要程度明显要高于前者。
因此,本文主要研究的问题可描述为:给定一批数据源集合S={S1,S2,…,Sn},数据源Si(1≤i≤n)中包含一部分与所查询号码num有关联的数据集Si(num),O={S1(num),S2(num),S3(num),…}代表所查询号码num在多个数据源都存在关联数据集,通过计算数据源Si(1≤i≤n)中所查询号码num与相关联用户usr的概率Pi(num→usr),并结合数据集中实体关系的时间属性权值T(usr,num)以及数据源权重D=(D1,D2,…,Dn),得到多源数据环境下所查询号码x与不同实体对象之间的关联度,并依据其关联值得到最具时效、准确度最高的关联对象。
2 基于多数据源的实体关系关联度计算方法
基于多数据源的实体关系关联度计算主要涉及实体关联时间属性权值的计算、数据源权重的计算以及所查询号码与各用户关联度的计算,见图2。同时,针对本应用场景,由于各数据源之间具有业务关联性,因此,对数据源权重的计算借鉴了PageRank算法[9]中网页权重的民主表决机制,利用与该数据源有关联关系的其他数据源共同决定该数据源的权重,其能够适应数据维度的变化,通过多方投票,能够较好解决数据质量良莠不齐的问题。

图2 实体关系关联度计算流程图
2.1 实体关系的时间属性权值计算
如前所述,时间属性是权衡该类业务数据中实体之间关系价值的重要因素之一,因此,以运营商登记的用户号码注册信息为基准,结合同一用户在不同数据源中的号码记录情况,计算这些号码对于该用户的时间权重。
假设T(usr,num)为用户usr与号码num的时间关系权值,当用户usr存在多个号码注册记录信息时,用户usr与各使用号码的时间权值可表示为T(usr,num)={T(usr,num1),…,T(usr,numn)},T的取值范围在0.1~1之间,以0.1为单位逐级递增。
θ(numi,numj)为用户usr注册号码numi与注册号码numj的时间间隔。对θ(numi,numj)值进行排序、分段统计,区间所对应的θ值越大,用户与对应号码的时间权重T越低;相反,θ值越小,T越高。当θ值为0时,表示该用户的号码稳定,未发生过变化,用户与号码的实体关系权重被赋予最大权值1。
2.2 数据源权重计算
假设D=(D1,D2,…,Dn)T为n维数据源权重值向量(n为数据源总数),M为转移矩阵。
(1)
其中,mij表示数据源i到数据源j的概率,由公式(1)计算;eij表示数据源i与数据源j关联的数据条数;Hi表示数据源i与其他数据源关联的所有数据条数。
给定一个D的初始值D0,设初始时,每个数据源的数据源权重值为1/n,得到初始向量D0=[1/n1/n… 1/n]。通过多轮迭代求解:Dk=MTDk-1,最后收敛于‖Dk-Dk-1‖<ξ,即差别小于某个阈值,即迭代结果收敛。
2.3 所查询号码与各实体属性的关联度计算
由公式(2)计算所查询号码num在数据源i下与用户usr的关联概率Pi(num→usr)。
(2)
式中,G表示所查询号码num在数据源i下与用户usr关联的总次数;V表示所查询号码num在数据源i下存在的所有关联总次数。
然后,结合之前所计算得到的时间权重T(usr,num)和数据源权重Di,对Pi(num→usr)进行加权计算,得到加权值Wi(num→usr),见公式(3)。
Wi(num→usr)=Pi(num→usr)×T(usr,num)×Di
(3)
最后,依据多个数据源的信息价值,由公式(4)计算出号码num与用户usr的关联度P(num→usr)值。
(4)
基于所查询号码与用户之间关联度的计算结果进行排序,按照关联度值的排名顺序向用户推荐结果,其中,关联度值最高的关联关系即为该号码当前最有可能的使用人。
3 实验结果与分析
本文使用了1 500条公开电话号码数据作为查询数据,分别基于本文DatasourceRank算法和PageRank算法进行关联度值计算并排序,提取其结果进行分析对比验证,其结果可见表1。
本文提出的DatasourceRank关联度计算算法基于实际应用场景中的数据特性,考虑了实体关系的时间价值、不同数据源权重等多种影响因素,其准确率明显更高,同时,由于其以数据源为基准单位,仅对实体对象相关联的数据进行计算,所需要的时间开销也有所降低。
以其中一个号码“138*****883”为查询对象进行详细分析,从业务大数据平台中检索相关数据,发现该号码在4个数据源中存在多条记录数据,该号码与多个用户之间存在交叉关联性,见图3,图中椭圆形表示手机号码,方形表示数据源,而圆形表示使用过该号码的人。

图3 所分析实体对象存在的关联性
根据本文的DatasourceRank方法进行计算。首先,进行实体关系时间权重的计算,主要伪代码如下:
T←初始化所有关系的时间权值均为1
r←用户注册号码发生变化的记录
remaider←t.length%10
offset←0∥偏移量
fori←0 ton-1
forj←iton
{
if r(i).id = r(j).id
t=r(j).time-r(i).time
} ∥计算号码发生变化的时间间隔
sort(t) ∥从小到大进行排序
fork←1 to 10
{
If (remaider>0)
{
for (t.length/10)*(k-1)+offset to
(t.length/10)*k-1 offset
T=1-0.1*(k-1)
}else
{
for (t.length/10)*(k-1) to (t.length/10)*k-1
T=1-0.1*(k-1)
}
offset ++
}∥基于分段对其关系赋予不同时间权重值,以0.1为基本单位,从1到0.1逐级递减
然后计算转移矩阵M,利用循环迭代计算数据源权重值,主要伪代码如下:
D←1.0/num ∥初始化各数据源权值
for i←0 to num
for j←0 to num
{
if i=j
tmpTrans[i][j] ←0
esle
tmpTrans[i][j] ←arrCount.get(i)
} ∥计算关联记录数
for i←0 to num
{
sum←0
for i←0 to num
sum += tmpTrans[j][i]
for j←0 to num
arrTrans = tmpTrans[j][i]/sum
} ∥构建转移矩阵
do { ∥迭代计算各数据源权值
S=D;
D=arrTrans.multiply(S)
}
While(D与S结果不相近) ∥如果小数点后8位不相同,则继续迭代
return D; ∥如果前后迭代结果很接近,则返回D
当Dk≈Dk-1时,则表示第k轮迭代过后,Dk和Dk-1非常接近,即D最终收敛,此时计算终止,最终的D就是各数据源的权重值。本实验中,经过18轮迭代达到收敛。最后,由公式(2)、(3)和(4)计算获得计算结果,见表2。

表2 基于DatasourceRank算法的分析结果
表3是基于PageRank算法所获得的排序结果。
将表2与表3对比可以看到,排序结果发生了变化,下面针对这些变化进行分析:表3中排在第1的关联用户a在表2中排在了第2,表3的结果仅依据各用户实体与所检索号码的关联记录频次进行计算和排序,号码“138*****883”与用户a的关联记录数最多,所以得到的关联度值最高,被排在了第1,但从使用时间属性上看,用户b使用此号码的最后时间明显要比用户a晚,从本应用的业务价值来说,用户b的价值比用户a的价值更重要。
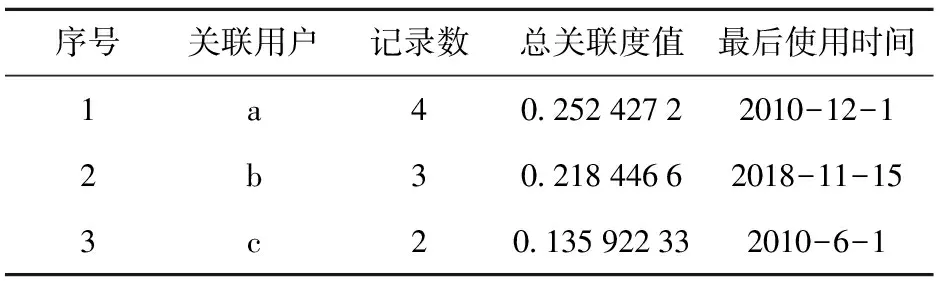
表3 基于PageRank算法的分析结果
使用本文算法进行关联度计算排序后,在表2中可见用户b与号码“138*****883”的时间关系和数据源业务权重值相对更重要,进而基于加权计算后,得到的总关联度值最高,故用户b排在了结果的第一位,其结果更符合用户的实际业务分析需求。
4 结语
本文针对目前存在的多数据源融合过程中,同一单值属性的实体对象关联多个对象值的问题进行分析,基于数据管理的业务需求及公安应用场景,提出了一种结合实体关系时间属性权值和数据源权重的计算算法,通过加权计算的方式计算实体关系的关联度值,使用户在搜索时能迅速准确地找到当前与搜索内容最相关的使用人。实证分析的结果表明该算法模型的有效性,对面向多数据源业务数据的情报分析工作提供了新的技术方法,未来若通过更大规模的数据验证后,可应用到真实的业务数据关联发掘检索系统中。
猜你喜欢
体育科技文献通报(2022年4期)2022-10-21
成都信息工程大学学报(2022年3期)2022-07-21
选煤技术(2022年2期)2022-06-06
邮电设计技术(2021年2期)2021-03-13
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
小型微型计算机系统(2019年3期)2019-03-13
计算机与数字工程(2018年5期)2018-05-29
计算机测量与控制(2018年3期)2018-03-27
计算机与生活(2018年3期)2018-03-12
