
深度学习框架下微博文本情感细粒度研究①
2020-05-22 04:44王嘉梅王伟全
计算机系统应用 2020年5期
王 儒,王嘉梅,王伟全,符 飞
(云南民族大学 电气信息工程学院,昆明 650504)
(云南民族大学 云南省高校少数民族语言文字信息化处理工程研究中心,昆明 650504)
据第43 次《中国互联网络发展状况统计报告》[1],中国网民规模达8.29 亿,2018年网页长度19 061 579 332 918 字节数,相比2017年增长11.4%,对规模越发庞大的网络文本内容进行有效的挖掘处理,对促进网络的发展和网络环境的净化有着重要意义.随着网络的发展,形如微博、邮件、短信、弹幕、新闻评论、微信、聊天记录的短文本内容逐渐增多,网络成为人们表达观点与抒发情感的重要平台,与传统通过书信报刊形式表达观点有所不同,上述形式的短文本有以下几个特点:
1)文本内容长度一般都较短.
2)内容形式不局限于纯文本,也会结合表情图像.
3)持有观点的群体和观点的内容具有多样性.
4)表达的观点或内容具有一定的倾向性和重复性.
5)一般都缺少上下文信息.
本文以NLPCC2013 任务二微博数据集为研究对象,探究微博短文本在不同神经网络模型中的情感细粒度分类结果,论文其余部分是这样组织的,第1 节介绍了情感细粒度分析,第2 节介绍词向量及论文实验所用到的几个不同模型及结构,第3 节介绍实验所用数据、环境、参数及评价标准,第4 节对实验结果进行了分析与评价,最后对未来的工作进行了总结和展望.
1 情感细粒度分析
情感细粒度分析是情感分析的分支,从文本颗粒度层次上来说,情感分析可以分为篇章级、句子级、属性级3 个层次[2],按能否获取观点评价对象的不同可分为粗粒度情感分析(篇章级、句子级)与细粒度情感分析(属性级),篇章级和句子级的情感分析只能得到整篇文档或整条句子的情感倾向,无法确切得知观点评价对象的喜好,属性级的情感分析基于评价对象及其属性上的观点信息,可以得到观点评价对象对某一事物的具体情感.传统的情感分析方法往往是将文本划分为积极和消极的二分类,或加入中性的三分类,随着社交网络规模的扩大,简单的二分类或三分类无法囊括丰富的文本情感,如“我早上很难过,一个人郁郁寡欢的,小王可能察觉到了我的异样,跑来带我出去逛街玩了好久,有人关心的感觉真好啊!”.这句话前半部分表达了今天心情的颓丧,后半部分表达了有人关心心情因此得到缓解而愉悦的转变,这句话无法用简单的二分类或三分类进行囊括,也因此细粒度情感分析在实际应用中有很强的需求[3,4].与其他文本相比,微博文本具有篇幅较短(一般在140 字以内),噪声大,上下文的语义信息稀疏,符号化(表情、图像)和口语化(缩写)严重等特点[5,6],个性化的表达非常适合进行细粒度情感分析的研究.
张云秋等[7]利用情感词典的方法在大连理工大学情感词汇本体DUTIR[8]的7 大类情感词汇基础上增加了表示“疑”这一类情感的词汇,共52 个词,根据情感强弱不同分为4 个等级,并在自行构造的药物微博评论数据集上使用PMI 方法进行了“乐、好、怒、哀、惧、恶、惊、疑”8 种情感的细粒度分析,这些评价结果基于当前情感类别,没有给出整体的宏平均分析结果.
刘丽[9]利用条件随机场(CRF)结合语法树剪枝的方法对产品评论进行了细粒度情感分析,借助Map-Reduce 中并行化协同训练的方法对语料进行了半自动标注,并进行了可视化表示,在识别情感要素和情感评价单元两个领域均取得了89%左右的综合准确率.
李阳辉等[10]利用深度学习中降噪自编码器的方法在多个数据集上进行了实验,对文本进行了句子级的情绪二分类(消极、积极),没有更进一步对文本的情感细粒度进行分析.
张谦等[11]利用深度学习中词向量模型结合传统机器学习中TF-IDF 模型进行词汇加权对15 种微博主题文本进行了主题分类,证明了合并后的模型结果比单一的词向量加权模型和TF-IDF 模型分类结果更好.
还有许多工作[12–15]结合深度学习的知识对文本进行情感分析以后取得了很好的效果,这里不一一列举.
2 词向量与神经网络模型
2.1 文本-数值转化
自然文本输入计算机以后需要进行文本-数值的转化,传统方法是通过向量空间模型(Vector Space Model,VSM)[16]进行文本-数值之间的转换将文本转换成向量以空间上的相似度表示文本间的相似度,通过计算空间相似度来表示文本相似度计算简单方便,但存在文本稀疏、一词多义、易忽略文本上下文信息等问题难以解决.机器学习中传统的向量空间模型如TFIDF 模型、One-Hot 向量,都是通过将文本中的词频信息转化为向量衡量该词语所占的权重.
Word2Vec[17,18]自2013年提出以来迅速取代向量空间模型成为自然语言处理领域新的基础,与VSM 相比,Word2Vec 是一种分布式的神经概率语言模型[19](图1),Word2Vec 层数并不深,是一种浅而双层的神经网络,词向量的每一维都具有一定的语义和语法特征,能够捕捉更多有关上下文的信息,同VSM 一样,词向量也很难解决一词多义的问题,这是由于训练出的词向量矩阵是静态固定不变的.词向量模型有两种,CBOW 模型与Skip-gram 模型.其中CBOW 模型利用当前词上下文的若干个词语预测当前词的概率,如图1通过当前词前后2 个词预测当前词语,而Skip-gram 模型则相反,通过当前词的概率预测上下文的若干个词语.

图1 神经网络语言模型
图1中(wt−n−2,···,wt−n+2)可看做按时间序列排序的词语集,通过神经网络结合上下文信息(context)计算语言模型中的参数来预测当前词,依据窗口大小为2 的上下文预测当前词,最后由Softmax 层输出预测的当前词.原理和2-gram 语言模型相似.
2.2 CNN 和TextCNN 模型
CNN (Convolutional Neural Network)也称卷积神经网络,1962年生物学家Hubel 和Wiesel[20]发现猫的视觉神经细胞中存在着一种被称为感受野的细胞结构,这种细胞结构能作用于视觉输入空间,对视觉形成的图像局部特征的提取能力很强,1980年,Fukushima[21]根据上述结构提出了神经感知机,被认为是卷积神经网络的雏形,到1998年LeCun[22]提出LeNet-5,宣告了现代的卷积神经网络结构正式出现.卷积神经网络由输入层、卷积层、池化层、全连接层、输出层等5 部分构成,典型的卷积神经网络LeNet-5 结构如图2.
CNN 的卷积原理可用图3表示.

图2 LeNet-5[22]
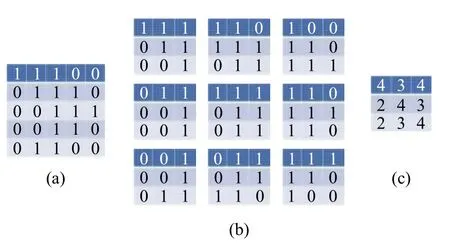
图3 卷积核滑动原理
假定输入是一个5×5 的矩阵图3(a),通过3×3窗口大小的卷积核滑动分别提取特征图如图3(b),图3(c)为卷积后得到的特征图.此时得到的矩阵很好计算,但如果是一幅长宽为256 位的图片或一条长度为200 的句子此时得到的特征图仍然十分臃肿,需要通过池化层进一步降维,常用的池化方法有最大值池化和平均池化两种.Nal Kalchbrenner 等[23]提出了k-Pooling 方法,将所有特征值得分在Top-K的值及这些特征值原始词语的先后顺序保留,这种方法对一条前半句与后半句表达情感相反或有所区别的句子效果很好.以上简单的介绍了CNN 工作原理,更多内容也可阅读文献[24,25].
TextCNN[26]是CNN 的一个变种,由Kim Y 在2014年提出,是卷积神经网络在自然语言处理领域的首次应用,在当时取得了state-of-the-art 的效果,结构如图4.TextCNN 工作原理与CNN 相差不大,通过卷积核滑动提取文本中的特征,但图像是二维数据(长、宽),文本是一维数据,需要通过构造不同的Filter(卷积核)的窗口大小形成维度上的差异完成文本上的二维表示,常用的卷积核窗口大小为3、4、5,这与Ngram 语言模型在某些方面不谋而合,N-gram 语言模型通过计算当前词前后N个词语的概率得到当前词语与上下文之间的关系.Zhang Y[27]测试了不同参数设置如词向量、激活函数、Feature Map 大小、Pooling 的方法等对Text-CNN 模型分类效果的影响及最佳参数.
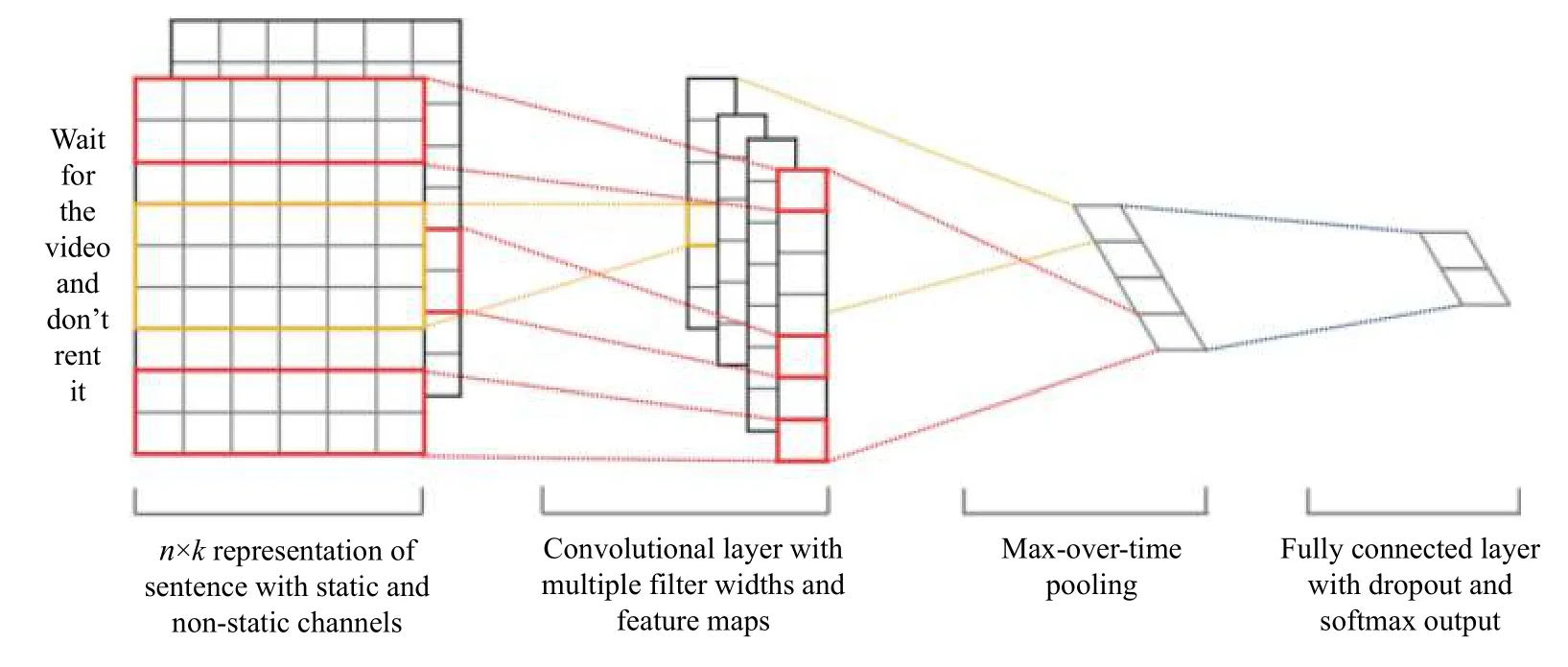
图4 TextCNN[26]
Text-CNN 在中文文本分类(词级别)中工作原理如图5.

图5 Text-CNN 中文词级别分类原理
从图5可以看出TextCNN 模型要先经过中文分词,再按卷积神经网络的原理对文本转化的数值进行处理,卷积神经网络相比循环神经网络更多关注局部的信息,因而中文处理领域影响较大的停用词处理对卷积神经网络而言就非必须,分词时可根据需要决定是否去除停用词.
2.3 LSTM 和GRU 模型
RNN 也称循环神经网络(Recurrent Neural Network)或递归神经网络(Recursive Neural Network),本文中RNN 指循环神经网络,循环神经网络既有前馈通路,又有反馈通路,可以将上一时刻的信息传入下一时刻,使模型捕捉到序列数据中有关上下文的信息,故而常用于处理如语音、文字、视频图像等形式的时间序列数据.典型的RNN 如图6.

图6 RNN 结构图
RNN 公式,如式(1)及式(2):

式中,xt为输入当前时间步的输入信息,yt为当前时间步信息经隐藏层ht后得到的输出信息,同时也是下一时间步的输入信息,st是隐藏层的值,U是输入层到隐藏层的权重矩阵,V是隐藏层到输出层的权重矩阵,W则是隐藏层上一次的值作为这一次的输入的权重.RNN 训练时的梯度变化由于模型的时序性存在不能简单的通过BP(反向传播)算法进行,需加入基于时间的计算过程,也就是BPTT 算法.
RNN 可以捕捉文本的上下文信息,但当模型时间步过长时,过去时间步的历史信息不停累积容易使模型出现梯度爆炸或消失的情况,LSTM[28]和GRU[29]均是在此基础上进行的改进.RNN 有很多变种结构,Jozefowizc R 等[30]测试过一万多种RNN 及其变种结构的效果.
LSTM (Long and Short Term Memory)的主要结构由输入门it(input gate)、遗忘门ft(forget gate)、输出门ot(output gate)、以及细胞态(memory cell)组成,为了避免出现梯度爆炸或消失的情况,LSTM 通过遗忘门先选择性的遗忘掉上一时间步的部分历史信息,再通过细胞态对当前时间步的模型状态进行更新.典型的LSTM 如图7.
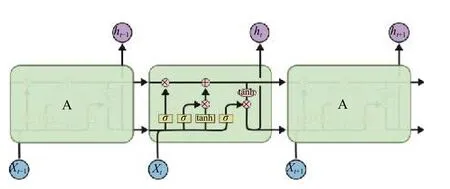
图7 LSTM 结构图[27]
LSTM 公式如式(3)~式(8):

式中,W和b分别表示相应状态下的权重系数矩阵和偏置项,σ 和t anh表示Sigmoid 和双曲正切激活函数,LSTM 在训练时先按式(3)~式(8)计算当前时间步各个状态值,再通过BPTT 算法反向计算网络的整体误差,通过误差对模型梯度进行优化并更新网络的权重.
GRU (Gated Recurrent Unit)在LSTM 的基础上进一步简化了模型结构,将LSTM 的输入门it、遗忘门ft、输出门ot更改为更新门zt(update gate)与重置门rt(reset gate),并将细胞态与隐层状态ht进行了合并为.GRU 结构如图8.
GRU 公式如式(9)~式(12):

式中,W表示相应状态下的权重矩阵,ht表示隐藏层状态信息,σ 和t anh表示Sigmoid 和双曲正切激活函数,比较GRU 与LSTM 的结构会发现,GRU 的输入输出结构与LSTM 相似,区别在于GRU 根据式(12)使用zt即可完成对输入信息的遗忘与选择,使用参数更少,结构更加简单.

图8 GRU 结构图[28]
2.4 双向结构
在类时间序列数据的处理中,只有前馈输入还不够,还需要有反馈通路以利用上一时间步的信息,双向(Bi-directional)结构很好的解决了这个问题.缺点是相比单层结构,双向结构需要更多的计算资源,程序运行时间也更长.
双向结构如图9所示.

图9 双向结构
2.5 CLSTM 和CNN-LSTM 模型
LSTM 神经网络可以捕捉序列中有关上下文的信息,CNN 神经网络可以获取全文的局部特征,Ghosh S[31]结合两个模型提出了结合上下文信息的混合神经网络模型CLSTM(也称时空网络)在接续语句预测上相比当时其他模型提高了20%,Zhou CT[32]等将这一模型应用到文本分类、情感分析问题上也取得了不错的效果.孙晓等[33]将LSTM 与CNN 的输出结果进行直接拼接,在讽刺语识别数据集上进行了测试,效果比词袋模型或单一RNN、CNN 模型要好.本文在CNN 和RNN 的组合模型与拼接模型的基础上进行了改进,加入了双向结构以利用上下文信息.
C_BiLSTM 用双向LSTM 连接CNN 中的卷积层与池化层,通过CNN 卷积层提取序列数据中心的重要特征,BiLSTM 层对提取后的特征进行处理得到序列数据中有关上下文的信息,模型如图10.

图10 C_BiLSTM 模型示意图
CNN-BiLSTM 模型将CNN、BiLSTM 两个神经网络模型的输出结果经Keras 的Concatenate 层进行简单拼接,最后经Softmax 进行分类,模型如图11.

图11 CNN-BiLSTM 模型示意图
3 实验准备工作
3.1 实验数据
本文所用数据为NLPCC2013 任务二微博数据集,数据已经标注.如图12,共8 类情感标签none,sadness,like,anger,happiness,disgust,fear,surprise 其中各类情感标签数目分别为6753,1144,2120,640,1476,1394,139,334 共14 000 条,包含4000 条训练集与10 000 条测试集,在实验过程中我们将两个数据集合并成一个数据集,借助Python 的机器学习包SKlearn 中的数据处理函数Train_Test_Split 按训练集与测试集8:2 的比例进行重新划分.
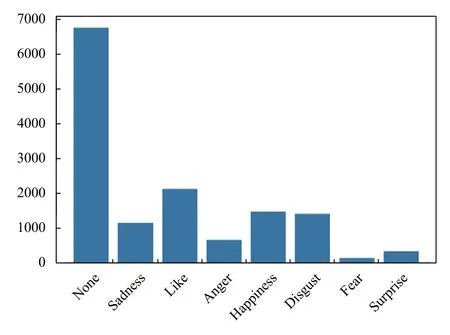
图12 微博情感标签分布图
3.2 实验环境
本文实验环境配置见表1.

表1 实验环境配置
3.3 词向量
词向量是深度学习用于自然语言处理的关键一环,论文采用了两种词向量的训练方式,一种是通过Keras 中Embedding 层的动态训练生成的词向量,一种是预训练词向量模型.
关于预训练词向量,原始数据中包含5 万条原始微博语料,但这部分语料规模较小,训练出的词向量规模也较小,本文选用了北京师范大学中文信息处理研究所与中国人民大学 DBIIR 实验室合作的工作[34],这份工作的内容包括一百多种中文领域的词向量,选择其中的微博词向量531 MB (557 675 674 字节,300维)作为本文所用预训练词向量.从这份词向量中随机抽取了部分词语,如图13,可以看到不同词语间的语义相关性.
3.4 神经网络参数
神经网络模型中参数对模型最终的结果意义极大,表2为论文所用模型参数,分别为输入长度、层数、词向量维度、神经元个数、卷积核、dropout、optimizer、epoch,为了便于比较论文部分模型设置了相同的参数.表2中dropout 一行括号内参数为循环时上一时间步到当前时间步循环dropout 的比率,在统计层数时,去掉了模型的输入层与输出层.
图13 微博词向量可视化

表2 神经网络参数
3.5 实验评价指标
在进行实验结果分析之前,需要明确判别模型性能的标准,本文采用两种评价指标进行评价.一种是机器学习中常用的准确率,F1 值,一种是混淆矩阵,准确率和F1 值可以得到整个模型的整体分类效果,但不能得到某一情感类别文本的细粒度分类效果,混淆矩阵可以比较文本预测类别与文本真实类别的差异看出某一模型具体的细粒度分类效果.
准确率的定义是以关注的类为正类,其他类为负类,分类器在测试数据集上的预测或正确或不正确,4 种情况出现的总数分别记作:
TP:将正类预测为正类数.
FN:将正类预测为负类数.
FP:将负类预测为正类数.
TN:将负类预测为负类数
准确率的定义为:

F1 值的定义为:

混淆矩阵的定义是矩阵的每一列代表文本的预测情感标签,每一列的总数表示预测为该类别情感标签的文本的数目.每一行代表数据的真实归属情感标签,每一行的数据总数表示该类别情感标签的文本实际的数目.每一列中的数值表示此实际情感标签文本被预测为该类情感标签的数目.
4 实验分析
由于dropout 机制的存在,每次训练结果会出现一定的偏差,本文比较了8 种模型在10 次训练中整体准确率效果最好的一次结果,还比较了加入词向量优化后的模型训练10 次训练中整体准确率最好的一次结果,如表3,取小数点后4 位.
通过表3可以看出,在最好结果的对比上,CNN模型比RNN 模型整体准确率更好,加入双向结构以后LSTM、GRU 整体准确率变低,CNN-BiLSTM 模型的拼接模型整体准确率比使用双向结构的RNN 模型更好,C_BiLSTM 模型整体准确率最低,整体准确率最佳的LSTM 模型53.71%与最低的BiGRU 模型整体准确率50.36%相差3.35%.同加入词向量以后的准确率作比较发现CNN 和LSTM 模型整体准确率分别下降4.89%、0.85%,其余6 个模型的最佳整体准确率保持不变或有所提高,加入词向量以后最佳整体准确率也由LSTM 模型的53.71%提高到CNN-BiLSTM 模型的55.07%,说明加入词向量对提升整体准确率有一定效果,值得注意的是加入词向量以后除TextCNN 模型与C_BiLSTM 模型,其余模型的F1 值均有所下降,说明模型准确率有提高但分类性能有所下降,词向量覆盖掉了原始文本的部分语义,本文通过将混淆矩阵进一步分析模型的细粒度分类效果.

表3 不同模型准确率及F 值(%)
图14中,图14(a)表示模型未加入预训练词向量模型的混淆矩阵,图14(b)表示加入预训练词向量模型的混淆矩阵.由混淆矩阵的表现可以看出,在不加入词向量的情况下,对happiness,like,none,sadness 等情感类别文本预测效果较好.Anger,disgust 等情感类别文本预测效果一般.Fear 和surprise 情感标签文本预测效果极差,甚至出现类别缺失的情况,为此查阅了原始的微博文本,发现部分句子标签为fear 的微博文本很难表征强烈的fear 情感,如“和总部来的领导们在珠江新城吃饭,完后她们想去沙面逛逛,我正好开了车所以当然由我送去.然后,我就开始不停问同事沙面怎么走,然后同事说先往2 沙岛方向走,然后我开始问2 沙岛怎么走,再然后很巧的我的GPS 就死机了一直搜不到卫星信号[衰]你们说,领导会不会觉得我是故意的?![泪]”.“去微博广场看了十几页,全这句话:我喜欢周韵汤唯全智贤.嘛意思啊? 2 亿微博用户不会全体中毒吧?真可怕!!这样宣传比买CCTV 的8 点广告好值啊!!!”.相比强烈的fear 情感,这两句话更像是在吐槽个人的想法并抒发个人的情绪,第二句中“好值啊”和前半部分表达的情感有区别,句子的整体情感也因此产生变化,也一定程度影响模型预测的结果.

图14 混淆矩阵
结合混淆矩阵的结果,加入词向量以后模型的整体准确率有所提高,但具体到某一情感类别,特别是情感标签数较少的类别,模型的预测结果不甚理想,出现了在预测时情感类别缺失的状况,这种情况以数据量较小的情感标签为主.与未加入词向量时的结果相比,情感类别缺失更多,说明词向量覆盖了部分情感词汇的文本信息,不能很好的表征微博文本的细粒度情感,可以尝试构建更大规模的基于微博文本的词向量,同时,中文自然语言处理流程中停用词的去除,也对口语化、符号化、图形化严重的微博文本产生了一些影响,可以尝试构建基于微博文本的情感词汇库或微博分词系统.
与欧阳纯萍等[35]基于多策略融合的细粒度情感分析方法相比,基于神经网络模型的方法最佳整体准确率高了大约25%,需要注意的是欧阳纯萍等的工作所用数据集剔除了情感标签为None 的文本.与传统的基于机器学习方法的文本细粒度情感分类的效果相比,基于神经网络模型的微博文本细粒度分类仍大有可为.
5 总结与展望
论文结合深度学习方法对微博文本进行了细粒度情感分析,但对文本情感的探究较少,试验了深度学习中几种模型在情感细分类中的效果,下一步除了构造新的模型,还应当结合一定的情感知识;分词时简单地用结巴分词进行了分词,而微博文本新词、缩略词、表情符号较多,这种分词不甚准确,影响文本情感的表征,也在一定程度上影响了情感细分类结果,下一步可以考虑构建微博的情感词典;同时,不同情感标签的数目差距较大,情感标签数目最多的None 与最少的fear 比例近乎50:1,对分类结果也有极大的影响;模型对文本的上下文信息利用较少,可考虑使用Elmo、Bert 等基于上下文信息的预训练语言模型,或加入Attention 机制进行优化.与微博文本领域主题分类的相关工作相比,微博文本的情感细粒度分类任务仍任重而道远.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
健康体检与管理(2021年10期)2021-01-03
