
基于图卷积神经网络的医保欺诈检测算法
2020-06-07 07:06易东义邓根强董超雄祝苗苗吕周平朱岁松
计算机应用 2020年5期
易东义,邓根强,董超雄,祝苗苗,吕周平,朱岁松
(华中科技大学协和深圳医院,广东深圳518060)
(∗通信作者电子邮箱denggenqiang@qq.com)
0 引言
近些年,随着人民生活水平不断提高,中国基本医疗保险参与人数已经达到13.5亿人,参保率超过了95%,医疗支出费用从2008年的1.45万亿增长到2015年的4.10万亿,年均增长率达16%,远远超过我国国内生产总值(Gross Domestic Product,GDP)同期增长率[1],其中很重要的一个原因就是医保欺诈、资源浪费和药物滥用(Fraud-Waste-Abuse,FWA)。根据联邦调查局估计,在美国每年欺诈占医疗保险的3%~10%(大约占190~650亿美元)[2]。随着人口老年化加剧,FWA情况愈演愈烈。根据医疗机构的报告,2012年美国FWA总费用为750亿美元[3-4]。在国内,2017年,仅四川省公布的56件医保欺诈案件中,“11.28”特大骗保案件就涉及5400余万元;2018年“沈阳骗保案”轰动一时,主要涉事人员40余人,给国家带来巨大的损失。与此同时,传统的欺诈检测依靠专家调查,这会产生大量的时间成本和人力成本。根据案件难易程度每次调查的费用在200~20 000美元[4]。此外,随着医疗保险数据的爆炸性增长,领域专家人数无法满足现有欺诈案例筛查的需要。因此,医保欺诈方面有必要投入研究,尽早地发现、预防甚至杜绝医疗保险欺诈的发生。
现有的自动医保欺诈检测方法分为两个研究方向[5-6]:无监督学习和有监督学习。基于无监督学习[7-9]的欺诈检测方法非常依赖数据的分布,其特点是寻找离群点作为欺诈点,但是这种方法非常不适合偏移的数据集,比如医疗保险数据集[10]。 Zhang 等[9]提 出 了 imLOF(improved Local Outlier Factor)局部异常检测算法,将局部异常点作为欺诈点。另一方面,监督学习方法[11-14]需要大量的标签数据才可以取得较好的预测模型,在实际医保欺诈数据中,非欺诈的数据并没有作记录,且只有较少的欺诈数据(调查昂贵、患者隐私保护)。Bauder等[11]在不平衡的数据上使用了随机森林作为分类器。Pandey等[14]提出了基于规则的计分系统、逻辑回归模型和决策树等模型,都依赖于大量的训练数据样本。
为了解决数据稀少、数据不平衡和数据标注昂贵的问题,本文从以下3个方面研究:1)增加关系信息。虽然获取到欺诈的数据样本稀少,但是病人和医生之间的诊疗记录都有很好的保存。直观地讲,如果模型建立得适当,用病人和医生之间的关系应该可以提高欺诈检测的性能。2)贝叶斯方法。小数据通常都是在贝叶斯框架下建模,它可以使用先验分布的合理假设,将小数据中包含的信息传播给后验概率。3)提高数据质量。由于成本的限制,医疗欺诈调查的数量通常是有限制的,因此提高欺诈标识的质量就显得尤为重要。
本文的主要贡献如下:
1)提出了一种新的基于关系的变分自编码模型,可以使用病人和医生的关系结构来改善小数据集中的医疗欺诈自动检测,即使数据集只包含一类欺诈标签也可以训练。
2)提出了一种新的主动学习策略,该策略结合了基于图卷积和变分自编码的单分类医保欺诈检测模型(One-Class medical insurance fraud detection model based on Graph convolution and Variational Auto-Encoder,OCGVAE),在保持预测性能的同时,减少了领域专家进行医疗欺诈调查的次数。
3)在一个真实的医疗欺诈数据集上对所提算法进行了测试,实验结果表明,本文方法优于目前最先进的方法。
1 医保欺诈检测系统框架
1.1 病人-医生关系网建模
查询病人的就诊访问记录,构建病人-医生网络,该网络可以表示为一个无向图G ≜(V,ℰ,W),其中|V|=n是医生与病人节点数目,ℰ是节点之间的连接关系,对于任何一个节点v∈V与其他节点的关系ei∈ℰ,其权重值为wi∈W。所有节点的特征向量组合成一个特征矩阵X,节点之间的权重信息可以使用邻接矩阵A存储,为了方便阅读,将本文中的符号收集如表1,接下来将描述如何将病人-医生关系图集成到一个深层神经网络来执行有效的推理。
图1展示了患者的药品购买记录和医疗欺诈样本的病人-医生网络。如图1所示,欺诈样本连接起来形成一个集群。事实上,现有的图形分析方法[15-17]已经表明,关系信息对于检测医疗欺诈是有用的,但是,这些方法是无监督的,而且是为特定的医疗系统设计的,例如假设可以从医生、病人和药店获得详细的关系信息[16]。相比之下,本文使用一组小型的一类欺诈标签对病人-医生网络进行建模,以实现准确的医疗欺诈检测。

图1 病人-医生关系网Fig.1 Patient-doctor relational network

表1 符号表Tab.1 Label table
1.2 医保欺诈检测框架
本文的欺诈检测框架如图2所示,提出了基于图卷积和变分自编码的单分类欺诈检测框架(OCGVAE)。
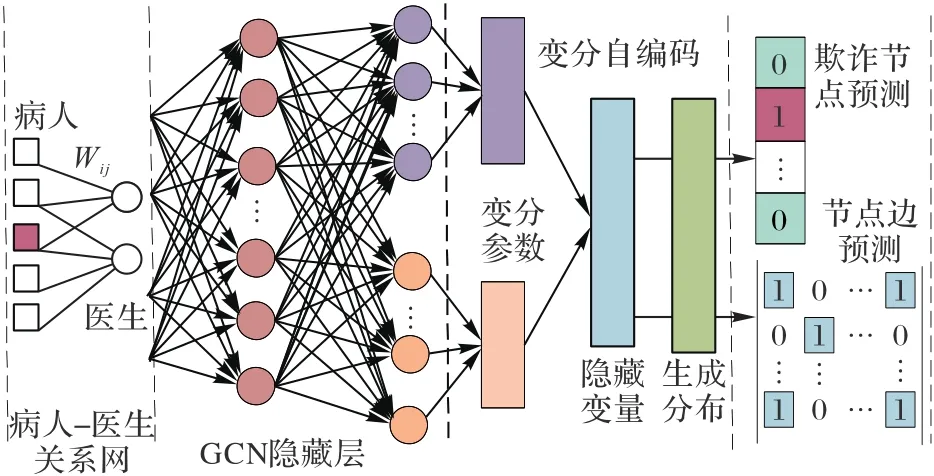
图2 医保欺诈检测框架Fig.2 Architectureof medical insurancefraud detection
OCGVAE主要由3个模块组成,每个模块都有重要的作用并且相互关联。框架的第1个模块是图卷积神经网络(Graph Convolutional neural Network,GCN),它是连接数据特征和病人-医生关系网络的关键枢纽。它包含输入层和两个隐藏层,第二个隐藏层有两个并行结构,它们共享第一层参数。第2个模块是变分自动编码器(Variational Auto-Encoder,VAE),其输入是GCN的输出,一个输出是平均向量,另一个是标准偏差向量,它们构成了隐藏变量的分布。最后的模块是关于框架的输出,在本文提出的架构中,节点的标签和节点之间的链接可以被预测。
1.3 图卷积神经网络
在机器学习领域,卷积神经网络(Convolutional Neural Network,CNN)模型取得了令人瞩目的成绩,但是,CNN不适合医保欺诈的场景,因为传统的CNN模型只适用在欧几里得空间上,而病人-医生关系网络是一个图结构的数据。为了解决这个问题,本文使用了图卷积方案(GCN),它可以在图谱领域处理图结构数据[18-19]。

定义一个图卷积操作*G,给定一个参数为θ∈Rn的过滤器Fθ≜diag(θ)和一个输入信号x∈Rn,卷积操作可以定义为:其中:U∈Rn×n是拉普拉斯矩阵L特征向量组成的矩阵,即其中I n是单位矩阵,A和D是图G的邻接矩阵和度矩阵,Λ是一个对角矩阵,其对角线上的值是矩阵L的特征值。
1.4 高效的图卷积神经网络
虽然GCN适合用于医患网络模型,但计算复杂度仍然是一个问题。式(1)需要的时间复杂度是O(n2),其中n是节点个数。二次时间复杂度说明了在人数较多时,GCN不能有效地工作。为了解决这个问题,文献[18-19]提出了两个近似计算,将时间复杂度降到线性关系。
1)切比雪夫多项式近似[18]。

其中:S(•)是激活函数,H(l)和W(l)是第l层的激活矩阵和参数,H(0)=X。
1.5 基于变分的自动编码关系模型
OCGVAE的理论模型为:

其中X和A是对应病人-医生关系网的特征矩阵和邻接矩阵。为了利用好病人-医生关系网信息,将潜在变量z的变分参数定 义 为 GCN 模 型 :其 中μ≜GCNμ(X,A;Wμ)和lbσ≜GCNσ(X,A,Wσ)。
生成模型的定义:
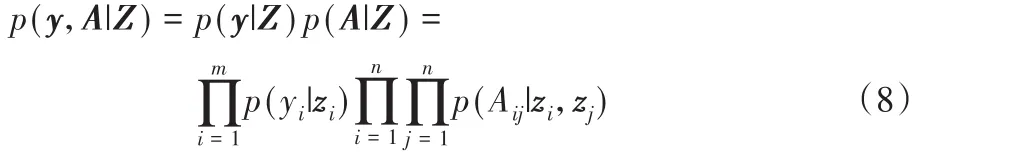
以上两个式子定义为:p(Aij=1|z i,z j)≜S(z iTz j),p(yi=1|z i)≜S(W l z i+b),其中W l是逻辑回归因子,b是偏置项,只有极少数的m≪n是标记为欺诈的节点。
上述的参数Wμ、Wσ、W l都可以使用变分下界函数优化:
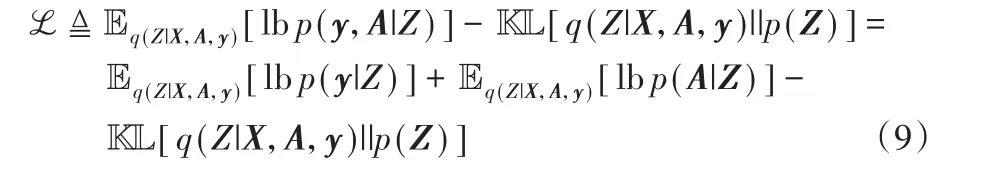
2 医保欺诈调查
主动学习策略[20-22]已经成功地应用于数据标注,特别是在标记数据点非常昂贵和/或费时的情况下,这种技术允许用最少的标签实现模型的预测准确性。本文提出的OCGVAE可以借助主动学习,更好地进行欺诈调查,其关键思想是调查最不确定的案件,以便OCGVAE进行分类:

其中:yv是节点v的标签,ℍ[]•是分布的熵,节点v的熵值由以下计算得到:

后验分布p(yv|A,X,y)由以下推出:
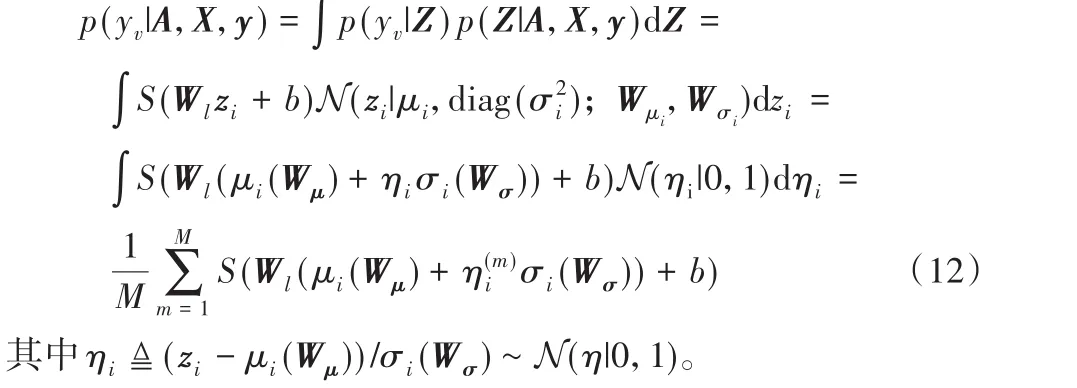
通过式(12)计算熵值选择出最不确定的节点给专家做案件调查。
3 实验和结果
3.1 数据集
本文所使用的医保欺诈数据来自于深圳市某医院2015年患者就诊数据,包含了120万的访问记录,40万就诊患者,1242名医生。由于有限的计算资源,从中选择了一个较合理的数据子集,筛选的条件如下,20<年龄<70,总支付>800,总数量>16,最高价格>35,频次>1,自费<300,最低价格>15。
经过筛选后,用于实验的数据集有34192名患者和1 095名医生,包含138个欺诈患者的912次就诊信息,其数据特征如表2所示。
利用患者就诊记录(表2)建立节点特征矩阵X,将性别、年龄、保险类型、就诊次数、年费、年购药量等不变量直接复制到特征矩阵中。计算2015年期间个人就诊记录的属性平均值,包括最高单价、最低单价、天数、数量、自费和总金额。上述特性仅用于指定每个病人节点,而医生节点中的对应节点则保留为一些虚拟值。医保欺诈发生时,起着关键作用是病人的特征,而不是医生。
为了建立病人和医生之间的关系结构,本文使用一个简单的启发式算法对病人-医生图G中的边进行加权。定义边ei∈ℰ是节点(u,v)的连接关系,定义wi∈W是边ei的权重。如果u、v是同类型的,wi=0,否则,wi是病人访问医生的次数。
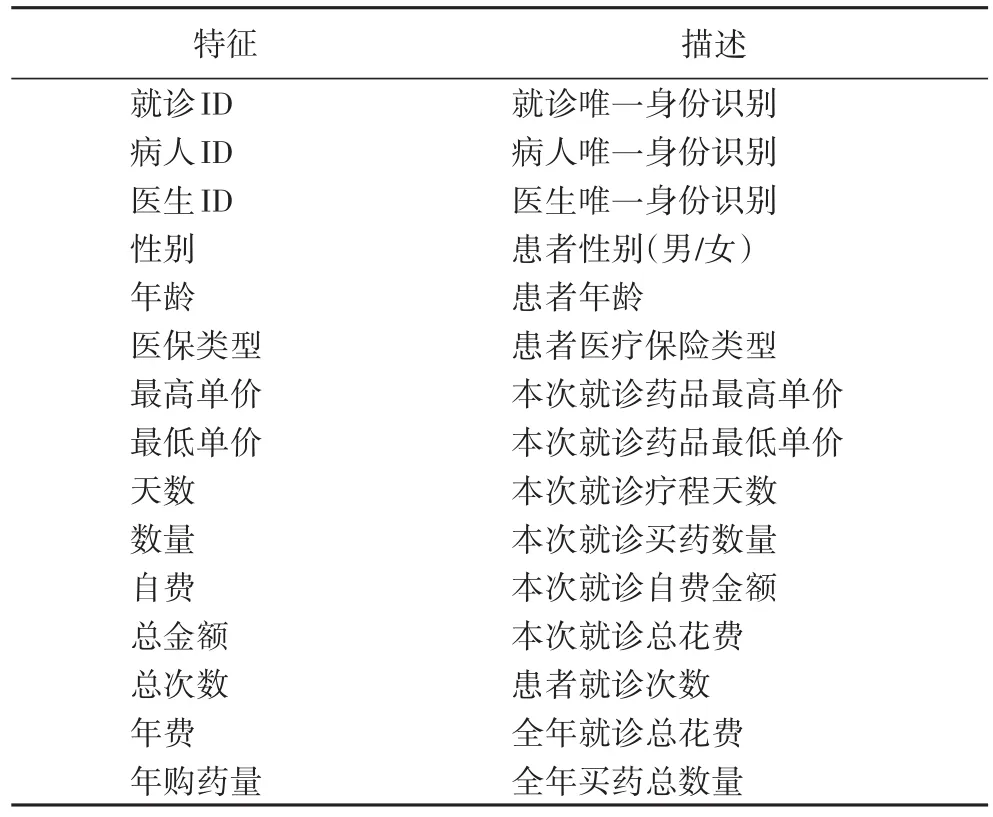
表2 病人就诊记录描述Tab.2 Description of patient visit records
3.2 实验设计
在GCN结构中,第一层和第二层分别有32个和16个隐藏单元,为防止过拟合,设置dropout为0.5,学习率为0.01,隐藏变量z i的维度是16。实验采取了4折交叉验证,结果平均超过100次随机实验,该模型采用精确度、查全率、准确率和F1分数等多个指标进行性能评价。
3.3 OCGVAE实验结果
表3显示了在真实世界的医疗数据集上医疗保险欺诈检测的结果。实验比较了两类算法在有无病人-医生关系网情况下的性能。在所有性能指标中,本文提出的模型能够获得最优的性能指标,这说明病人-医生关系网在欺诈检测当中有着很重要的作用。总的来说,在病人-医生网络中工作的方法比其他方法表现更好,这表明医患网络可以提供额外的有用信息,提高欺诈检测的性能。OCGVAE的性能明显优于Semi-GCN(在三个指标上比Semi-GCN高15%~20%),原因是变分的AutoEncoder框架可以解决由于一个小的单类标记数据集引起的过拟合问题。
为了解释所提出的OCGVAE所引起的改进,图3将二维空间中的数据可视化,构建了一个由138个欺诈节点和300个随机选择的未标记节点组成的小数据集。图3(a)仅使用节点特征,用无监督的降维方法T-SNE[37]可视化节点;图3(b)通过在OCGVAE模型中将潜变量z i的维数设置为2来可视化数据。
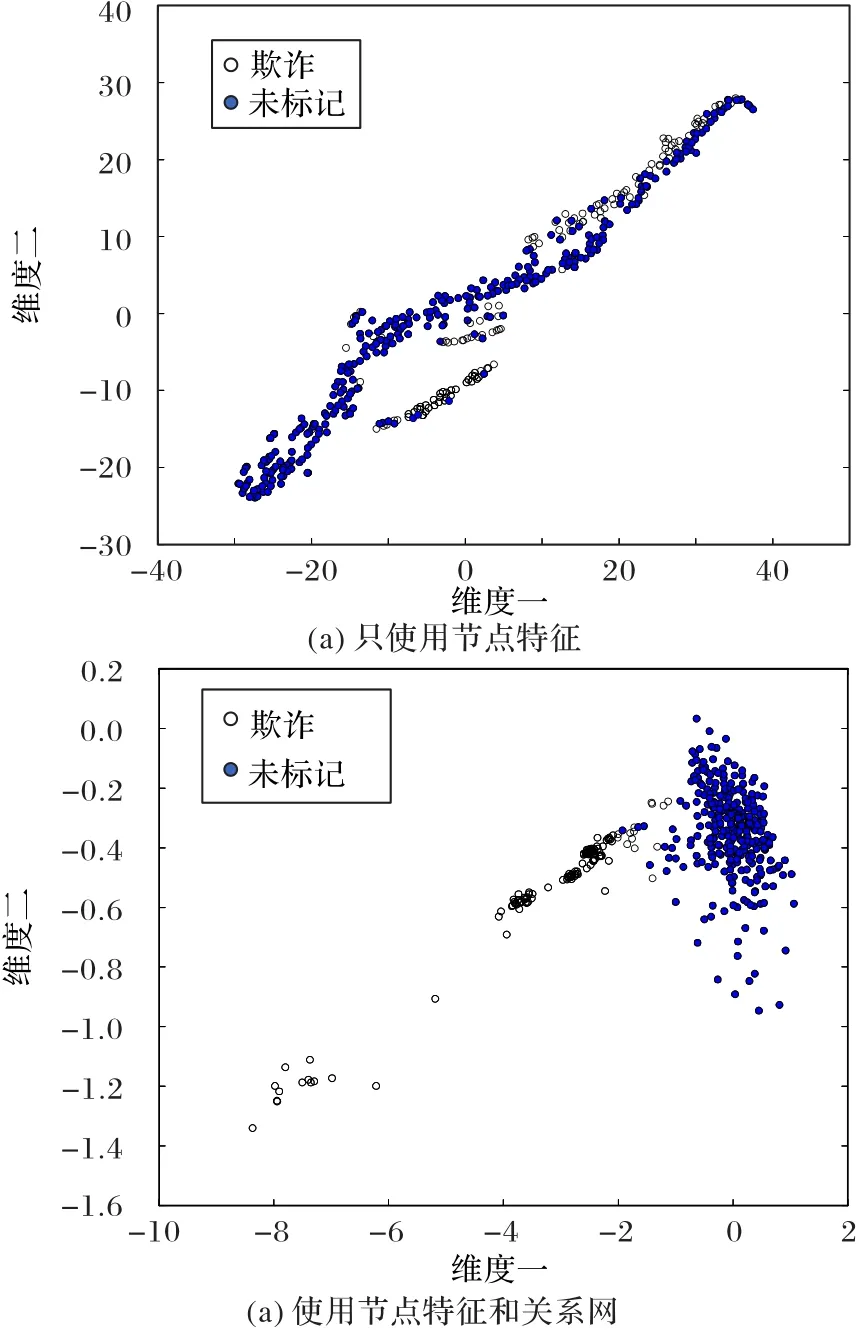
图3 使用T-SNE和OCGVAE的医疗保险数据的可视化Fig.3 Visualization of medical insurance fraud dataset based on T-SNE and OCGVAE
可以看到,图3(a)数据点是混合的,难以分离欺诈数据和未标记的点;图3(b)表明两种数据点在潜在空间z中可以更好地分离,因此,使用OCGVAE模型可以更容易地学习分类边界。

表3 使用关系网与不使用关系网各算法在真实数据上检测性能的比较Tab.3 Detection performancecomparison of different algorithmson real datawith or without relational network
3.4 主动学习实验结果
为了显示主动欺诈调查的成本效益,本文比较了以下三种策略的性能。
最大熵(MaxEnt)策略 它使用预测熵来度量未标记点的不确定性;然后,选择MaxEnt前k个未标记数据点进行欺诈调查。
最大概率(MaxProb)策略 与MaxEnt不同,直接在欺诈预测中选择概率最高的前k个数据点。
随机(Random)策略 在未标记的样本中随机选取k个数据点做调查。
如图4所示,在不同的学习率和分类阈值设置下(学习率和分类阈值作为超参数,可以由经验设置),MaxEnt策略在所有4个性能指标中都优于其他两个策略(由于篇幅限制,只画出了F1值和准确率)。随机策略表现最差,这意味着常规的自动检测欺诈的做法非常低效。当设置适当的学习率和分类阈值(例如,学习率a为 0.01,阈值t为 0.8)时,MaxEnt和MaxProb可以获得相近的性能。在所有设置中,MaxEnt策略比MaxProb策略执行得更稳定。因此,在现实场景中部署主动欺诈调查时,MaxEnt策略是一个更好的选择。
在图5中,显示了随着欺诈标签数据增多的性能变化趋势。结果表明,使用两个分类阈值:0.5和0.8,MaxEnt方法均可以较快地收敛(由于篇幅限制,只画出了F1值曲线)。

图4 OCGVAE中主动学习策略在不同学习率和分类阈值下的性能比较Fig.4 Performancecomparison of active learningstrategiesin OCGVAEwith different learningratesand classification thresholds
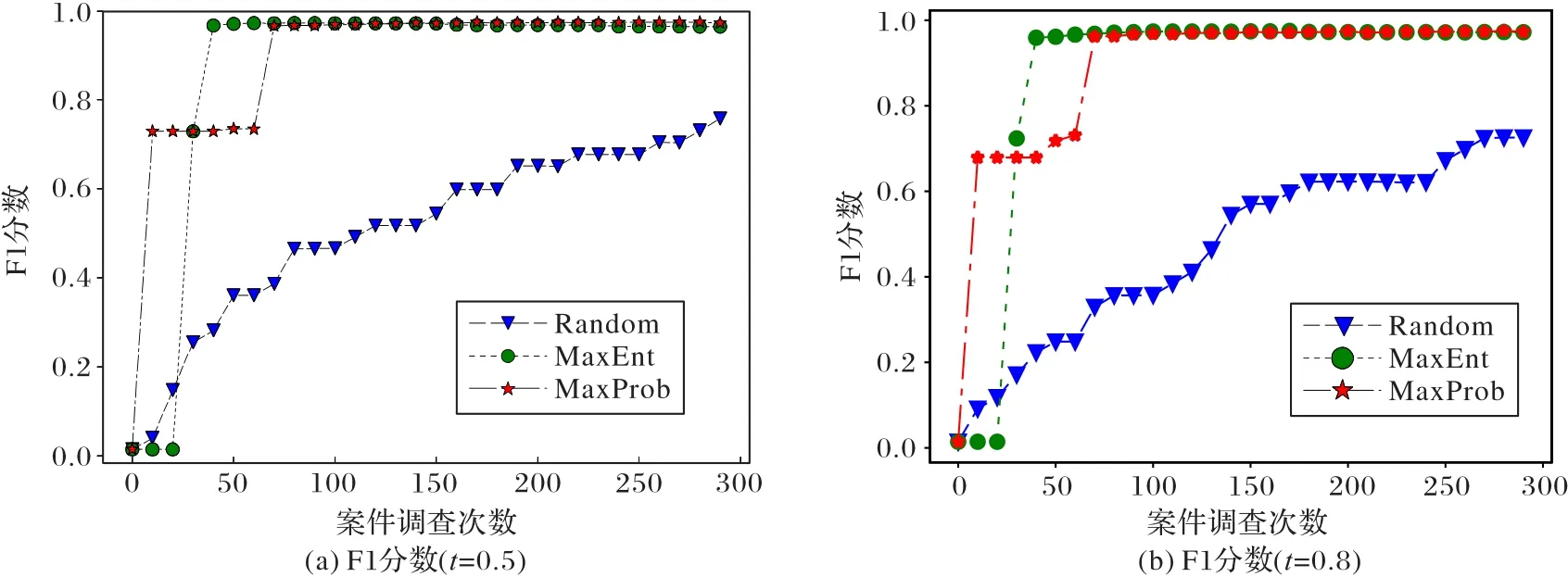
图5 不同分类阈值t下OCGVAE中主动学习策略的收敛曲线Fig.5 Convergence curves of active learning strategies in OCGVAE with different classification thresholds t
4 结语
本文着重于研究一个自动医疗欺诈检测框架。该框架的主要特点是:1)能自动侦测进行医疗诈骗活动的可疑病人;2)能协助领域专家进行具有成本效益的医疗诈骗调查。这依赖于本文提出的一种新颖的基于变分自动编码器的关系模型,它可以同时利用病人-医生网络和一类欺诈标签,来改善欺诈检测和欺诈调查任务。与一类对抗神经网络(OCAN)、一类高斯过程(OCGP)、一类近邻(OCNN)、一类支持向量机(OCSVM)和半监督图卷积神经网络(Semi-GCN)算法相比,准确率分别高出16.1%、70.2%、31.7%、36.5%和27.6%。但是,随着患者人群的增大,该框架对计算机的计算资源的要求也会剧增。在未来的工作中,将考虑如何解决这个问题。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
汽车维修与保养(2019年7期)2020-01-06
现代世界警察(2019年3期)2019-09-10
银行家(2012年11期)2012-01-17
全国新书目(2004年7期)2004-07-09
