
基于预训练模型的文本分类网络TextCGA
2020-06-08 08:04杨玮祺杜晔
现代计算机 2020年12期
杨玮祺,杜晔
(北京交通大学计算机与信息技术学院,北京100044)
0 引言
文本分类是指计算机将一篇文章映射到给定的某一类别或某几个类别的过程。文本分类在生活中有着广泛的应用,根据任务领域可以分为网络舆情分析、新闻主题分类以及评论情感分析等。随着移动互联网的普及,越来越多的信息以文本的形式展现在人们的面前,对文本信息的准确分类显得愈发重要。
近年来,研究者们大多使用深度学习方法进行文本分类。与传统的文本分类方法相比,使用深度学习的文本分类方法不需要人工设计复杂的特征工程,从而可以实现端到端的学习。然而,使用深度学习方法进行NLP 领域的工作时,首先需要考虑设计语言模型,即如何去用计算机能理解的方式去表示一个词,一个句子和一篇文章。这始终是一个十分困难且无法绕过的问题。NLP 领域预训练模型的出现,在一定程度上解决了这个问题。研究者们可以利用预训练模型得到文本的初级特征表示,进行自己的NLP 任务。
此外,在文本分类过程中,如何捕捉上下文关系是研究的重点。学界普遍使用RNN 网络来捕捉这种关系,但是,对于长度较长的文本,RNN 网络中前序节点对后续节点的影响会递减,从而导致序列特征提取效果不佳,这就是RNN 网络的短期记忆问题。虽然LSTM 和GRU 结构的出现,在一定程度上缓解了这个问题,但是这两类结构在长文本分类任务上的表现仍然有提升的空间。
本文在文本分类任务中使用预训练模型,主要进行了如下工作:
(1)提出了一种适合处理文本信息的模块,CGA 模块,该模块由三个隐藏层组成,可以较好地提取文本的局部信息和序列信息。
(2)将CGA 模块并行使用,提出基于预训练模型和CGA 模块的文本分类网络,TextCGA,并通过实验验证该文本分类网络在公开数据集上有着良好的表现。
1 相关工作
1.1 迁移学习和预训练模型
迁移学习是一种很流行的深度学习技术,是将从源领域(Source Domain)学习到的东西应用到目标领域(Target Domain)上去[1]。通过将已训练好的模型、参数等迁移到新的模型中,来帮助新的模型进行训练,以达到建立精确的模型,缩短训练时间的目的。利用迁移学习,使得学习并不是从零开始,而是从之前解决各种问题时学到的模式开始,即将之前从某一任务中学到的知识迁移到同一学科空间中的另一任务中,其中的数据或任务是存在相关性的[2]。
预训练模型就是我们之前所提到的这种已经经过良好训练的模型。当前的预训练模型主要分为两大类:
(1)基于特征:如Word2Vec、Sent2Vec、Para2Vec。这类预训练模型都是用一个算法或者模型,如Word2Vec 里的Skip-Gram,在大规模语料上进行训练,将特征进行保存,并用于今后需要使用的地方。
(2)基于微调(fine-tuning):这类预训练模型也是在大规模语料上,结合特定的目标任务训练的。使用时,需要在预模型后面接上自己的网络,用下游的训练任务的数据进行微调,才能够取得比较好的效果。
在图像领域,人们采用预训练的大型网络来提取图像的初级特征,利用这些特征进行自己具体的下游任务。例如在CTPN 网络中[3],首先使用VGG16 前5层结构提取图像特征,之后再使用自己的网络结构做文本检测。近两年,许多大型研究机构陆续公开了一些NLP 领域的预训练模型,如ELMo[4]和BERT[5],这些预训练模型大部分属于第二种基于微调的预训练模型,并且都是在大量语料上,结合特定的任务和训练技巧所得到的,具有很强的文本表示能力。这使得研究者可以使用这些预训练模型所提取的文本特征,进行自己下游的NLP 任务。
1.2 基于深度学习的文本分类方法
NLP 研究者使用深度学习方法在文本分类领域进行了许多的研究。2013 年,Google 开源了一种用于词向量计算的工具——Word2Vec[6],该工具可以很好地度量词与词之间的相似性。后续的研究者们也都是使用词向量工具,对文本进行表示,来进行自己的分类任务的。Tomas Mikolov 等人提出了在工业上使用广泛的FastText 网络[7]。该网络将输入的词向量序列进行线性变换,映射到中间层和输出层。同时,使用了层次Softmax 替代传统的Softmax 方法,提高了计算效率。但是FastText 方法在准确率上并没有优势,并且所采用的线性变换方法,并没有很好地可解释性。
Kim 等人提出TextCNN 网络[8]。TextCNN 使用词向量矩阵对文本进行表示,并使用CNN 捕捉文本特征。该网络使用不同大小的滤波器对文本进行特征提取,将池化后的特征进行拼接,输入Softmax 层进行分类。TextCNN 可以提取到多种层面的特征,但是并没有很好地利用词与词之间的顺序上的关系。
为了更好地利用文本上下文之间的关系,Siwei Lai等人提出使用RCNN 网络[9],可以在时间复杂度为O(n)的前提下,使用双向的RNN 捕捉单词的上下文关系,对文本进行良好的表示,提升文本分类的准确率;Chunting Zhou 等人提出C-LSTM 网络[10],使用CNN 提取词向量特征,使用LSTM 捕捉词与词之间的序列特征,达到了较好的分类结果。但是,这些使用RNN 的分类网络,在文本句子较长时,存在着短期记忆问题。
为了克服RNN 网络的这一缺点,Jader Abreu 等人提出了一种用于文本分类的层级注意力机制网络,HAN[11]。该网络抛弃了以往网络使用RNN 的做法,在句子级别以及文档级别提出了注意力机制,使得模型对于重要程度不同的内容赋予不同的权重,开创了Attention 机制在文本分类任务中应用的先河。
2 TextCGA文本分类网络
2.1 网络结构
TextCGA 网络以预训练模型为基础,在网络上中使用多个CGA 模块,每个CGA 模块都由卷积层、RNN层和Self-Attention 层构成,将所有CGA 模块的输出进行拼接,输入Softmax 层进行分类。模型结构和CGA模块结构如图1 所示。
模型处理文本数据的步骤如下:
(1)将文本切分成独立的句子,利用预训练模型将句子转换为句向量,将文本表示为句向量矩阵。
(2)将句向量矩阵输入多个CGA 模块。每个CGA模块首先使用不同卷积核的CNN 提取矩阵的局部特征信息,作为后续的输入。
(3)对于CNN 提取到的特征图,使用RNN+Self-Attention 结构强化序列特征建模,作为每个CGA 模块的输出。
(4)将所有CGA 模块的输出进行拼接,经过一层全连接层,使用Softmax 分类器输出每一个类别的概率。

图1 Text-CGA网络与CGA模块
2.2 文本表示
模型的输入为一篇文章。在输入层之后,我们将预训练模型作为第一层,用于对文本进行特征表示。对于每一个输入,我们取预训练模型倒数第二层(具有m 个节点的隐层)的输出,作为该词或句子的表示。我们通过预处理将文章划分成句子,对每一个句子进行向量化,从而将一篇具有n 个句子的文章表示为n*m的句向量矩阵。文档的表示过程如图2 所示。
2.3 CGA模块
CGA 模块包括卷积层、RNN 层以及Self-Attention层三个部分。卷积层能够捕捉局部特征,Bi-GRU 层用来捕捉序列特征,Self-Attention 层可以解决序列过长时的短期记忆问题。每一个CGA 模块,我们为卷积层设置不同的卷积核大小,旨在从不同的感受野捕捉矩阵的局部特征。
(1)卷积层
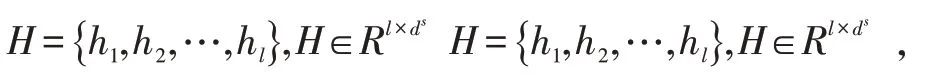

其中,i 的范围为从1 到(l-k+1),j 的范围为从1到(d^w-d+1),代表点乘操作,b ∈R 为偏置项,f 为非线性激活函数。对于整个矩阵H,可以得到feature map O:

这里,O ∈R(l-k+1)×(dw-d+1)。
(2)RNN 层
在一篇文章中,句子与句子之间存在顺序和逻辑上的关系,为了捕捉这种关系,我们使用RNN 机制来捕捉句向量之间的序列关系。GRU(Gated Recurrent Unit)是RNN 网络的一种,结构简单,参数较少,效果也很好。一个GRU 单元的结构如图3 所示。

图3 GRU单元

⊕表示将两个向量进行连接的操作,*表示矩阵乘法,σ与tanh 表示所用到的两种激活函数,Wr、Wz和Wh͂和为反向传播过程中需要学习的权重。为了更好地提取时序特征,我们使用双向的GRU 结构,Bi-GRU,如图4 所示。
GRU 主要包括两个的门结构,图中,zt表示更新门,rt表示重置门。更新门控制前一时刻的状态信息被带入到当前状态中的程度,重置门控制前一状态有多少信息被写入当前的候选集上。对于前向传播过程,有:

图4 双向GRU
其中,ti表示i 时间步的输入,和表示正向和反向GRU 单元的输出,hi表示当前步的最终输出。使用Bi-GRU 结构,既可以提取正向序列特征,也可以提取反向序列特征。对于和,我们将二者拼接在一起即可得到hi,即:

(3)Self-Attention 层
我们引入Self-Attention 机制的目的,主要在于解决当句子很多时,RNN 网络不能很好地进行序列建模的问题。Self-Attention 机制不同于传统的Attention 机制,旨在挖掘输入序列中各个节点之间的关系。Self-Attention 的主要思想是加权求和,但是这里的权重是神经网络在学习的过程中确定的。在本文中,即使在RNN 网络中,某个重要节点对后续节点的影响一直在递减,但是在Self-Attention 层中仍然还会因为较大的权重,而对最后的输出产生影响。
对于输入X,Self-Attention 机制首先产生3 个向量Q,K,V:

WQ,Wk,Wv为初始化的权重。隐藏层的输出hi可以表示为:

其中,S 被称为打分函数。通常使用缩放点积作为打分函数,因此输出向量序列可以写为:

其中,dk为Q 或K 的维度,用以防止结果过大,使得Softmax 输出都接近1。Self-Attention 层的输出,即为CGA 模块的输出。
2.4 输出层
对于每个CGA 模块的输出向量Ci,我们对其进行拼接,得到向量C:

之后,我们对C 进行drop out 操作来防止过拟合,随后与全连接层相连,激活函数采用Softmax,进行分类。对于标签ŷ的预测过程则有:
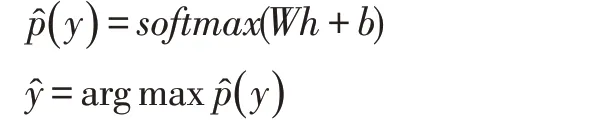
其中,h 为上一隐藏层的输出,W 和b 为全连接层的权重和偏置。
3 实验
3.1 数据集
我们选择了以下的中文新闻数据集进行实验以测试网络分类效果。
THUCNews:由清华大学NLP 实验室推出的数据集[12],整理了2005-2011 年间的新浪新闻,共包含74万篇新闻文档,14 个类别。在我们的实验中,我们选取了10 个类别的新闻,每个类别中包含有24000 篇文档,总计24 万篇文档,并按照18:1:1 的比例划分训练集、验证集及测试集。
Fudan set:由复旦大学计算机信息与技术系国际数据库中心自然语言处理小组整理,共计包含20 个类别的中文文档,我们从中挑选12500 篇文档作为训练集,2500 篇作为验证集,2500 篇作为测试集。
Sogou set:由搜狗实验室整理,数据来自2012 年6月-7 月期间的18 个类别的搜狐新闻。我们从中挑选10 个类别的新闻对其进行分类,训练集包含62500 篇文章,验证集包含2500 篇文章,测试集包含2000 篇文章。

表1 数据集及划分情况
3.2 比较模型
以下为本次实验所使用的对比模型:
Average Embedding(AE):对于一片文章,将所有词向量取算数平均值,直接使用全连接网络进行分类。该方法优点是速度较快,在工业界使用较为广泛。
TextCNN:由Kim 等人提出,使用3 种不同卷积核,进行三次卷积操作并将结果进行拼接,使用Softmax 层进行分类。该网络仅使用CNN 做特征提取,缺失文本的序列特征。
C-LSTM:由Zhou 等人提出,该模型融合了CNN特征提取的能力,也采用了LSTM 提取序列特征的能力。由于使用了RNN 结构,该网络在文本较长时可能会出现分类不准确的问题。
Attention-based C-GRU(Att C-GRU):由杨东等人提出[13],该模型将GRU 与Attention 机制结合,验证了Attention 机制可以优化语义特征表示。但是此结构并没有采用模块化的设计,初步的特征提取存在局限性。
4 实验结果与分析
模型中存在着多个超参数,其中最重要的参数为CGA 模块的数量。为了测试CGA 模块的数量对模型分类准确率的影响,我们改变模型中CGA 模块的数量,在THUCNews、Sogou 以及Fudan 数据集上进行实验,结果如表2 所示。

表2 CGA 模块数量对准确率的影响
实验结果表明,并非CGA 模块越多分类效果越好。在CGA 模块数量为6 和7 时,已经出现了准确率的极值。当CGA 模块数量继续增加时,并不会给准确率带来提升。由于CGA 模块之间是并行的关系,因此网络的训练时间并不会有显著增加。我们将CGA 模块的数量设定为7 个。
我们在这三个数据集上继续进行实验,测试模型的分类准确率。实验结果如表3 所示,我们使用准确率来评估模型。

表3 实验结果
从整体上来看,我们的模型在所有数据集上的表现,都超过了对照的方法,这证明了本文提出的模型在文本分类任务中是有效的。但是在Sogou 和Fudan 文本分类任务中,模型表现较对比模型虽有较大提升,但是并没有达到如THUCNews 任务中的准确率。结合数据分析后,我们发现,Sogou 和Fudan 数据集中的新闻数据,平均文本长度在25 句左右,而THUCNews 数据集的文本长度在50 句左右。当句子数量相对较少时,Self-Attention 机制和双向GRU 机制无法较好发挥自身的学习能力。因此本文的模型更适合于长文本分类,而不适合弹幕、评价等短文本分类任务。
5 结语
本文提出了一种基于预训练模型的文本分类模型,并在3 个数据集上进行了评估,验证了本文模型在文本分类任务上的有效性。通过与经典的分类模型进行实验比较,本文模型可以很好地发挥预训练模型的文本表示能力,并且在捕捉文章上下文关系时,使用CGA 模块避免了传统RNN 网络的短期记忆问题。同时,并行使用的CGA 模块可以在不增加训练时间的条件下,有效地提升网络的分类结果。
在未来的工作中,我们将继续探究如何更好地对文章上下文关系进行捕捉,以实现更准确的文本分类效果。
猜你喜欢
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
新高考·高一数学(2022年3期)2022-04-28
时代英语·高二(2021年4期)2021-07-29
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
高中生学习·高三版(2016年9期)2016-05-14
中学生数理化·高一版(2016年6期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
