
基于VCK-vector模型的词义消歧方法
2020-06-09 12:20戴洪涛侯开虎周洲肖灵云
软件 2020年2期
关键词:自然语言处理
戴洪涛 侯开虎 周洲 肖灵云
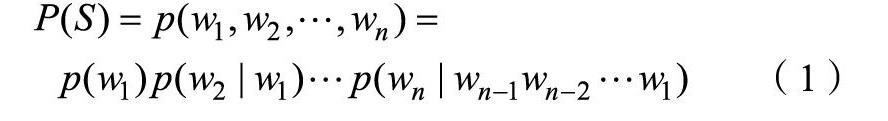

摘 要: 自然语言处理(NLP)旨在如何让计算机更好的理解人类的语言,但是在自然语言中句段、词汇本身存在多义和歧义,计算机无法将其转换为能识别的二进制编码,这是当下NLP领域内存在的最大问题。本文将Viterbi算法的词性标注模型、CBOW语言模型及K-Means聚类算法组合,构建一种基于词向量的多义词组合消歧模型(VCK-Vector)。通过词性分布对比、语义相关度任务和聚类效果分析等方法评测模型,最后通过百度AI词向量与模型输出结果进行对比。结果显示基于VCK-vector模型在实际场景运用中是可行的。
关键词: 自然语言处理;多义词消歧;VCK-vector模型
中图分类号: TP391.9 文献标识码: A DOI:10.3969/j.issn.1003-6970.2020.02.029
【Abstract】: Natural Language Processing (NLP) aims to make computers better understand human language. However in natural language,there are polysemy and ambiguity in sentence segment and vocabulary, and computers cannot convert them into recognizable binary codes. This is the biggest problem in the field of NLP.This paper combined the part of speech tagging model of Viterbi algorithm, CBOW language model and K-Means clustering algorithm to construct a polysemous word combination disambiguation model (VCK-Vector) based on word vector. The model was evaluated by comparing part-of-speech distribution, semantic correlation task and clustering effect analysis. Finally, Baidu AI word vector was compared with the output of the model. The results are showed that the paper propose polysemous word combination disambiguation model (VCK-Vector) based is feasible in scene application.
【Key words】: Natural language processing; Polysemy disambiguation; VCK-vector model
0 引言
中文同一个句子、词汇在不同场景运用会表达出不同的含义,使计算机准确分辨不同的语义是一件很困难的事情。让计算机消除词汇中的歧义,理解人类语言是自然语言处理领域的核心任务。针对计算机如何在处理中文多义词消除歧义的问题,国外的研究起步较早,1986年Hinton等人就提出了One-hot表示法的雛形,虽然运用了神经网络来获取信息,但是还未上升到自然语言处理的高度,仅仅是把符号映射在N维空间中[1]。随后,Benigo等人通过神经网络建立了概率语言模型,然而此模型在训练前指定的上下文范围十分有限,并缺乏对时序信息进行建模,不符合自然语言处理文本信息的要求[2]。另外,Mnih A.和Hin G提出了于语言知识无关的构建词类二叉树的方法[3]。Zheng X等人基于先前的研究结果,将神经网络框架应用到了中文领域[4]。Mikolov等人首次提出了CBOW模型与Skip-gram两个模型[5]。Lin Qiu使用POS标注的方法区分一词多词性的词向量[6]。最近,Seifollahi, Saeed和Shajari, Mehdi提出了利用词义消歧来分析新闻标题具体含义[7]。中文相较于英文的词汇消歧方法稍有不同,主要分为两个方向。其一,基于概率统计学将算法和模型组合于消歧任务中,王旭阳等人通过对词语预处理、词语构建及相似度排序等三个步骤,将中文网页数据进行映射[8-13]。李国佳等人通过K-Means聚类的方法标记类别,并训练相关的语料集,可得到多义词每个词义的词向量[14]。其二,构建多义词词典以其为标准用来消歧,基于Lesk算法[15]产生了相关的改进算法,王永生以词义词典WordNet为对照,通过对多义词的词义打分,采用得分最高的词义作为最终的词义[16]。除了上述研究成果外,李小涛等人基于多义词词典的词义分解和同义扩展来进行消歧[17]。卞月峰通过多义词典进行词义标注并将其用作训练集,该方法在消歧目标上具有较高准确率[18-23]。综上所述,国内许多学者对多义词消歧的两个方向均有研究,基于概率统计学的词义消歧方法,灵活性好,消歧效率高,但是消歧任务为语料库体量和类别所制约,其准确性较低。基于语义词典的方法准确率较高,但构建词典需耗费大量的工作,效率难以提高,并且消歧方法单一,改进难度大。两个方向各有利弊,但是核心问题及亟需改善的地方在于:(1)如何将中文多义词的特征进行提取;(2)如何对大型中文语料库中的多义词进行消歧。基于以上分析,本文将基于概率统计学的词义消歧方法,构建多义词组合消歧模型对语料库中的多义词词义消歧,通过该模型确定中文多义词的具体词义。本文从以下几个方面展开研究:(1)中文词语如何以向量化方式表征;(2)将Viterbi算法的词性标注模型与N-gram词性标注模型标注的结果对比,分析实验;(3)构建基于VCK-vector的组合消歧模型;(4)将本文的组合模型与其它模型的结果对比,验证模型的可行性。
1 NLP相关理论方法
1.1 N-gram模型
在自然语言处理中N-gram模型是一个十分常见的理论方法,其实质是基于条件概率公式的贝叶斯判别模型,假设有一句由n个词语组成的句子S=(w1,w2,…,wn),假设每个词wi都依赖于从第一个词w1到wi之前的词wi-1,那么可得整个句子S的概率为:
1.2 CBOW语言模型
连续词袋模型(continuous bag of words,简称CBOW)为了解决词语向量化的问题,CBOW模型使用二分类的方法多次判断目标词。其本质就是将多个隐藏层减少到了一个隐藏层。若关键词W上下文中有[a, b, c, d, e, f, g, h]8个分类,那么就先将其进行二分类,先判断W是属于[a, b, c, d]还是[e, f, g, h]。首先如果判断出W属于[e, f, g, h],那么就再进一步判断是W属于[e, f]还是[g, h],这样进行多次二分类,直到最终将W分配到某个分类中去。如果按二分类的方法来定位词语,就可以把计算单个词语的时间复杂度从o(h*N)降为o(h*logN),从而达到大幅度减少计算量和降低时间复杂度的目标。
1.3 Viterbi算法
Viterbi算法是自然语言处理中常用的分词和词性标注方法,其实质是利用动态规划的思想去寻找复杂网状路径中最大概率最短路径的方法。马尔科夫链的求解引入了Viterbi算法利用动态规划的思路来求解最大概率最短路径,使复杂度降为O(N*D),有效减少了计算量。其算法思想如图3所示。
1.4 K-Means聚类
K-Means聚类的原理是在分类未开始之前在所有样本中随机选取K个样本作为初始的聚类中心,然后计算每个样本与聚类中心的距离,将每个样本按照距离分给其离的最近的聚类中心,然后每个类簇的聚类中心又会根据类簇内的样本重新计算,直到所有样本都被分配完成。重复以上过程,直到满足终止条件,聚类完成。本文用K-Means聚类处理的词向量是n维空间向量,因此设K个初始聚类中心向量为:{O1,O2,…Ok},空间中各个点的向量为xi, i=1,2,3,…,n。则各个点xi到各个聚类中心的距离为![]() ,将xi归为最小d所对应的类别λi中,此时更新聚类簇
,将xi归为最小d所对应的类别λi中,此时更新聚类簇![]() 。然后对于每个聚类簇C,重新计算其聚类中心Oj,计算公式如2-32所示。直到所有的聚类中心都不在变化,输出聚类结果C={C1,C2,…,Ck}。
。然后对于每个聚类簇C,重新计算其聚类中心Oj,计算公式如2-32所示。直到所有的聚类中心都不在变化,输出聚类结果C={C1,C2,…,Ck}。
2 VCK-vector模型的构建
中文自然语言处理相较于英语更加复杂,英语可从时态中提取相关特征信息,但中文却没有这些特点。因此需要新的方法将中文多义词的特征表示出来。
2.1 模型的构建流程
首先针对具有不同词性的中文多义词,消歧模型根据词性的不同,将其在语料库中标注出来,再由语言模型训练语料库,具有不同词性的多义词就可以根据其词性将其分为两个词向量,并且其上下文也是不一样的。之后针对只有一个词性但是含义不同的多义词则需要确定其具体的含义完成消歧任务,消歧模型通过聚类的方法将只有一个词性的多义词结合其上下文来分析其具体含义。因此需要构建的消歧模型是一种结合词性标注模型、语言模型和聚类算法的组合消歧模型。根据消歧模型的消歧原理,构建消歧模型可以分为三个部分,第一个部分用于将语料库中的不同词性多义词根据词性对其进行区分;第二个部分用于将区分过后的多义词进行向量化来提取出中文多义词的特征;第三个部分通过对向量化后的多义词及其相关上下文进行聚类的方式完成对只有一个词性但具有不同含义的多义词消歧任务。图4为构建模型的流程图。
相较于其他基于统计概率的消歧方法所构建的多义词消歧模型,该消歧模型是从多义词的词性出发,将多义词人为地分为了两种类别,然后分别采用词性标注模型与聚类算法解决两种类别的多义词消歧问题,这是其它单纯使用词向量来进行多义词消歧的模型所缺乏的,也是该模型的“再创新”之处。
2.2 上下文特征提取
在中文里某個句子或某个段落中的词的含义是根据周围的若干个词或句子所组成的语境来决定的。多义词消歧任务的第一步,应该是提取歧义词的上下文特征,即从目标词w的句子周围收集n-1个词,这些词也被称为语境词。通过提取分析这些词所含有的信息,将其抽象为统一的特征表达,从而通过这些特征来对多义词进行消歧。上下文的范围在自然语言处理中也被叫做“窗口”的大小。范围的选取应该根据特征提取模型的特点而定,不是固定不变的。吴云芳等人[24]把《现代汉语语法词典》中的语法特征进行了提取并应用到消歧模型中,使得同形词的平均消歧正确率达到了90%以上。Mihalcea[25]等人将语义依赖关系特征提取出来转化为语义连接图,并使用了随机游走策略对多义词进行了消歧。卢志茂[26]等人又将语句依存关系与贝叶斯模型进行结合,有效解决了原贝叶斯分类模型中特征较弱的上下文对消歧任务造成的噪声影响。
针对词义消歧的问题,本文采用CBOW模型,从输入层到隐藏层是将目标词w周围的n-1个词作为输入并进行求和平均,不需要将窗口范围设置过大,只需要w左边的两个词与右边的两个词就已足够,所以设置窗口大小为5。如果窗口范围设置过大,会导致隐藏层得到的求和平均向量所包含的输入过多,导致丢失掉其中一部分信息。而CBOW模型一开始是将所有输入的词向量与模型参数随机初始化,因此在CBOW模型中上下文的特征(即词向量)是通过训练过程提取出来的。
2.3 基于词性标注的上下文特征改进
本文将语料库交给语言模型进行词向量训练从而得出词语特征之前对语料库进行词性标注,希望可以通过对语料库进行词性标注的手段来改善消歧效果。因为本文采用的语料库是维基百科中文语料库,其数据量为千兆级,包含30余万篇文章,所以不可能采用传统人工标注的方式对其进行词性标注。本文引用了两种中文词性标注模型对语料库进行词性标注:分别为基于N-gram词性标注模型及基于Viterbi算法的词性标注模型。
通过改进,实现了两个目标,第一点将不同词性具有不同语义的多义词w区分了出来,使其从原来语言模型的输入w改善成为了w/tag的形式,增加了多义词的区分度,其中tag表示为多义词标注的词性。第二点将原本无监督的训练方式改善成为了半监督的训练方式,使得多义词词向量特征更加明显。不仅改善了多义词的消歧效果,并且为进一步优化模型做好了基础工作。
2.4 词向量训练及其处理
关于CBOW语言模型及Skip-gram语言模型的实现的操作步骤:(1)模型的输出层函数为Hierarchical Softmax,统计所有词的词频,准备构建霍夫曼树。(2)根据语料库的词频构建霍夫曼树。(3)CBOW语言模型,将目标词w的上下文词向量求和平均作为输入变量,按照目标词w在第二步中生成的霍夫曼编码,对其路径上的每个中间节点进行分类并且按照分类结果训练隐藏层向量和目标词w的词向量。(4)完成霍夫曼树、霍夫曼编码及输入变量以后,从霍夫曼树的根节点开始,根据节点的向量和模型参数对每个节点进行Logistic分类,如果分类错误,则要对该节点的向量进行修正,并记录误差量。
Skip-gram语言模型的实现与CBOW语言模型的原理是相同的,不同点在于Skip-gram模型并不是对单个的输入词向量进行迭代更新,而是对2c个输出词的词向量进行迭代更新。
2.5 VCK- vector模型
本文对维基百科中文语料库进行了词性标注,提取了上下文特征并且得到了多义词的词向量。将多义词的不同词性转化为了不同向量,完成了对多义词不同词性的消歧目标。对于同词性的多义词无法消除的歧义。由此引入K-Means聚类法,将之前多义词词向量及与其相关度较高的词向量提取出来,进行K-Means聚类,得到多义词所在类别的聚类中心,并使用该中心的向量代替多义词的词向量,得到多义词在上下文中最终的词向量。以上是本文基于统计学的方法完成多义词消歧技术的过程和原理。在之前的研究中,本文结合了词性标注模型、将词语转化为词向量的语言模型以及统计学中的聚类方法,共同形成了本文基于词向量的多义词组合消歧模型(Viterbi-CBOW-K-means of Vector)模型,本文将其简写为VCK-vector模型。
3 VCK-vector模型的实现
3.1 语料库预处理
维基百科的中文语料库为Xml格式,需将其转换为utf-8编码的.txt文本才能对其进行后续处理。其具体操作为调用python中的logging、os、sys等第三方库,对Xml文件的读取和.txt文件的写入操作。由于语料库中存在着大量的繁体中文,需使用opencc程序对其进行文体转换。语料库中仍然存在着许多标点符号以及“的”、“地”、“得”这样的字,在自然语言处理中称为停用词,需将这些标点符号及停用词去除。本实验采用复旦大学整理公布的停用词表作为标准对语料库进行清洗。
3.2 分词及词性标注
本文所用的维基百科的中文语料库体量很大,所以使用稳定性能较好的jieba分词工具。在词性标注上,本文分别使用N-gram模型与基于Viterbi算法构建的词性标注器对维基百科中文语料库进行了词性标注并对标注结果进行了对比。
3.3 词向量的训练
词性标注任务完成后,得到语言模型训练词向量所需要的输入,即经过词性标注的维基百科中文语料库。然后使用CBOW模型、Skip-gram模型分别训练未经过词性标注和进行过词性标注的维基百科中文语料库,得到两种语料库的词向量模型。训练结果如表1、2所示。
3.4 K-Means聚类
本文选择与多义词相关度最高的10個词语作为聚类对象,将K值定为3。通过K-Means聚类后,得到与多义词同类别的若干个词语,并且得到该类别的聚类中心。聚类完成后,对得到几个指标来进行多义词的消歧,用以判断上下文相关词语与多义词之间的相关程度。
4 模型对比验证
本文实验环境为:CPU:4核,Inter(R) Core(TM) i5-7500 @ 3.40 GHz;
RAM & ROM:8 GB & 150 G;
操作系统:64位Windows7;
开发语言:Python3.6;
IDE:Pycharm及第三方库;
实验对象:维基百科中文语料库(1.60 GB)。
4.1 词性标注模型
本文采取简单对比两种词性标注模型标注完成后的语料各个词性分布的合理性进行评估,并选择词性分布更加合理的模型进行下一步实验。结果如表3、表4所示。
由上表可知基于Viterbi算法的标注模型采用的训练语料库是python中的jieba词库,其词语丰富程度和词性丰富程度都优于sinica_treebank词库,得到的词性标注结果分布更加平均合理。因此,本文采用基于Viterbi算法的词性标注集进行后续实验。
4.2 CBOW与Skip-gram语言模型
本文采用语义相关性来对两种语言模型进行评价。如表5、6所示为两个语言模型分别以“关心”作为研究对象,分析研究对象之间的关系。由表可知CBOW语言模型的区分度较好,Skip-gram语言模型区分度较差。并且从实验过程来看,CBOW语言模型进行词向量训练,耗时9个小时,用Skip-gram语言模型进行词向量训练时,耗时36个小时。
4.3 语料库标注前后词向量对比
本文语料库标注模型采用基于Viterbi算法的词性标注模型,词向量的训练模型为CBOW语言模型,其中以“关心”为研究对象的相关度如表7、8所示。
由上表可知,经过词性标注的语料库其词向量的表现更好。证明本文对研究对象进行词性标注的工作是可行的,通过对语料库进行科学的词性标注,不仅可以消除不同词性的多义词歧义,并且可以使后续工作得到的词向量具有更高的质量。
4.4 K-Means聚类改进后的词向量
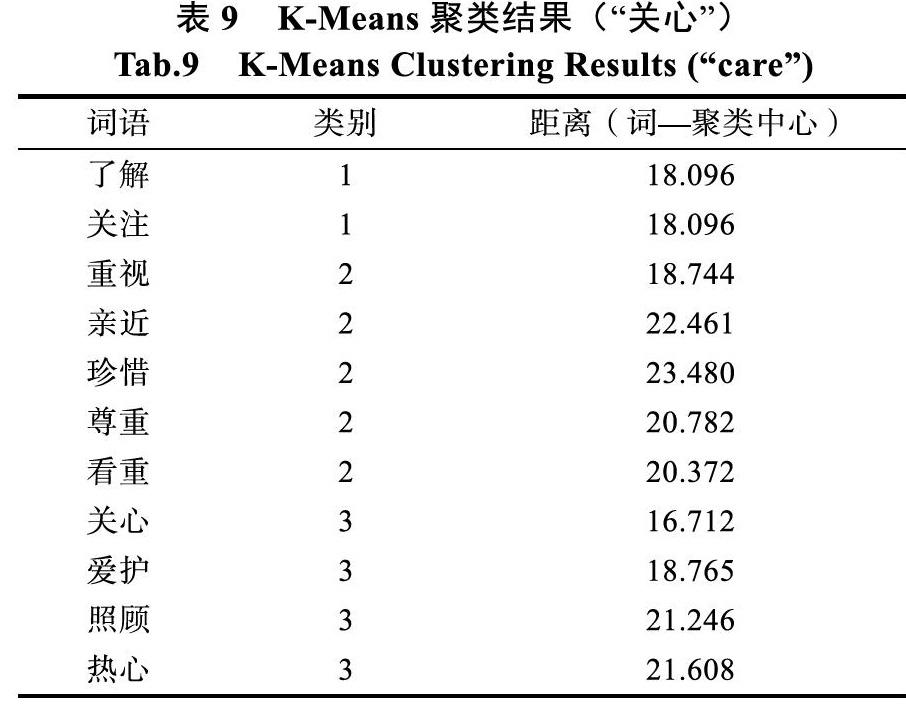
K-Means聚类前后词向量的对比的标准为聚类中心的相关度,因为向量维度为400维,无法在本章中列出所有的维度,所以在此只列出所有聚类词语的类别以及与其对应聚类中心的距离,如表9所示。
经过K-Means聚类之后,“了解”、“关注”、“重视”等7个词被分到了第1类和第2类中,其他词语与“关心”一同被划分为第3类。通过聚类后的结果,可以确定多义词“关心”的词义是与“爱护”和“照顾”最相关的,也就是说在上下文中,这里的“关心”更加倾向于表示对某人爱护和照顾有加的意思。
4.5 VCK-vector模型与百度AI词向量的对比
为了比较模型最后得出结果的优劣,以VCK-vector模型与百度AI得到的词向量之间的距离关系进行比较。如表10与11所示。
由表可知,虽然百度AI的词向量维度相对VCK-vector模型,“关心”更加远离了其他相关词语,VCK-vector模型更加稠密的词向量可以减少计算量并且其所包含的信息更加准确。
5 结束语
词义消歧任务是自然语言处理过程和应用中的重点和难点问题,本文提出了一种VCK-vector消歧模型,利用对多义词进行词性標注、进行词向量转换以及K-Means聚类的方法,并结合现有的多种词性标注算法、词向量训练模型以及聚类算法对多义词的消歧进行了深入的研究。本文得出以下几点结论:
(1)在词性标注任务上,本文对两种不同的词性标注模型,即N-gram词性标注模型及基于Viterbi算法的词性标注模型进行了对比,并分析了输出结果,基于Viterbi算法的词性标注模型表现效果更好;
(2)本文对CBOW模型及Skip-gram模型进行了对比分析,并采用评判任务对两种模型输出的词向量进行了对比,分析了两种语言模型各自的特点、算法过程和最后得到的输出结果,证明CBOW模型更适合作为本文的语言模型。
(3)词性标注的语料库相较于未经词性标注的语料库之间得出的词向量效果更佳;
(4)本文针对初步得到的词向量进行了K- Means聚类,并与未进行K-Means聚类的词向量进行比较,实验结果证明本文对词向量进行K- Means聚类可以有效的消解多义词存在的词义;
(5)通过与百度AI的词向量进行比较,VCK- vector模型更加稠密的词向量可以减少计算量并且其所包含的信息更加准确。
综上所述,本文通过实验证明了本文所提出的多义词组合消歧模型(VCK-vector)模型是有效可行的。中文语义消歧的方法随着研究的深入将不断改善,但如何正确且高效率的完成消歧任务仍是其研究重点。本文提出的组合消歧模型达到了消除多义词歧义的效果,但局限性很大,首先不论词性标注还是训练词向量,都应对比更多的算法模型,提出更加完善的组合模型,其次本文采用了K-Means聚类对多义词消歧,针对词向量的处理,还可以结合主题模型(LDA)、LSI及TF-IDF、最大熵及机器学习等模型算法深化研究,提高词向量质量,最后本文的语料库单一,在处理具体的消歧任务时,应结合本文的组合模型实施办法来采用相应的语料库作为训练对象,以提高实际运用中的准确性。
参考文献
Hinton G E, Rumelhart D E, Williams R J. Learning internal representation-s by back-propagating errors[J]. Parallel Distributed Processing: Exploration-s in the Microstructure of Cognition, 1985, 1.
Bengio Y, Ducharme R, Vincent P, et al. A neural probabilistic language m-odel[M]. Innovations in Machine Learning. 2006.
Mnih A, Hinton G. Three new graphical models for statistical language mo-delling[C]. International Conference on Machine Learning. Corvallis, Orego-n, USA, June 20-24, 2007.
Zheng X, Chen H, Xu T. Deep Learning for Chinese Word Segmentation a-nd POS Tagging[C]. Settle, Washington, USA, EMNLP. 2013: 647-657
Mikolov T, Chen K, Corrado G, et al. Efficient Estimation of Word Repres-entations in Vector Space[J]. Computer Science, 2013.
Lin Q, Yong C, Nie Z, et al. Learning word representation considering pro-ximity and ambiguity[C]. Twenty-eighth Aaai Conference on Artificial Intel-ligence. Boulder, Colorado 2014.
Seifollahi S, Shajari M. Word sense disambiguation application in sentime-nt analysis of news headlines: an applied approach to FOREX market pre-diction[J]. Journal of Intelligent Information Systems, 2019: 1-27.
王旭陽, 姜喜秋.基于上下文信息的中文命名实体消歧方法研究[J].计算机应用研究, 2018, 35(4): 1072-1075.
杨晓峰, 李堂秋, 洪青阳. 基于实例的汉语句法结构分析歧义消解[J]. 中文信息学报, 2001, 15(3).
杨雪. 基于维基百科的命名实体消歧的研究与实现[D]. 北京, 北京邮电大学, 2014.
史天艺, 李明禄. 基于维基百科的自动词义消歧方法[J]. 计算机工程, 2009, 35(18): 62-66.
宁博, 张菲菲. 基于异构知识库的命名实体消歧[J]. 西安邮电大学学报, 2014(4): 70-76.
汪沛, 线岩团, 郭剑毅, et al. 一种结合词向量和图模型的特定领域实体消歧方法[J]. 智能系统学报编辑部, 2016, 11(3): 366-374.
李国佳, 赵莹地, 郭鸿奇. 一种基于多义词向量表示的词义消歧方法[J]. 智能计算机与应用, 2018, v.8(04): 57-61.
Lesk M. Automatic sense disambiguation using machine readable dictionari-es:how to tell a pine cone from an ice cream cone[C]. Acm Sigdoc Con-ference. Banasthali University, Rajasthan, India, 1986.
王永生. 基于改进的Lesk算法的词义排歧算法[J]. 微型机与应用, 2013(24): 69-71.
李小涛, 游树娟, 陈维. 一种基于词义向量模型的词语语义相似度算法[J/OL]. 自动化学报: 1-16 [2019-04-01]. https://doi.org/10.16383/j.aas.c180312.
卞月峰. 面向全文标注的中文词义消歧研究与实现[D]. 南京, 南京师范大学, 2015.
孙磊. 基于Web知识的无监督英文目录标签消歧[J]. 计算机应用与软件, 2010, 27(9): 224-227+282.
刘琦. 一种基于WordNet上下文的词义消歧算法[D]. 吉林,吉林大学.
邓龙. 基于语义的中文词义消歧技术研究[D]. 哈尔滨, 哈尔滨理工大学.
张春祥, 徐志峰, 高雪瑶. 一种半监督的汉语词义消歧方法[J/OL]. 西南交通大学学报: 1-6 [2019-04-01]. http://kns. cnki.net/kcms/detail/51.1277.U.20180306.1913.006.html.
高宁宁. 基于混合特征和规则的词义消歧研究[D]. 吉林,吉林大学.
吴云芳, 金澎, 郭涛. 基于词典属性特征的粗粒度词义消歧[J]. 中文信息学报, 2007, 21(2): 1-8.
Mihalcea, Rada. Graph-based ranking algorithms for sentence extraction, a-pplied to text summarization[J]. Unt Scholarly Works, 2004, 170-173: 20.
卢志茂, 刘挺, 张刚, 等. 基于依存分析改进贝叶斯模型的词义消歧[J]. 高技术通讯, 2003, 13(5): 1-7.
猜你喜欢
计算技术与自动化(2017年3期)2017-10-26
魅力中国(2017年24期)2017-09-15
计算机应用(2016年12期)2017-01-13
求知导刊(2016年10期)2016-05-01
