
基于加权图方法的高炉过程故障检测1
2020-06-10 08:53安汝峤杨春节潘怡君
高校化学工程学报 2020年2期
安汝峤, 杨春节, 潘怡君,2
(1. 浙江大学 控制科学与工程学院, 浙江 杭州 310027; 2. 中国科学院 沈阳自动化研究所,辽宁 沈阳 110016)
1 前 言
高炉炼铁是国家工业生产过程的重要组成部分,具有复杂性和时变性的特征[1]。因此,研究高炉生产过程的故障检测具有重要意义,许多学者对工业过程故障检测进行了大量的研究[2-4]。突变点检测作为一种工业过程故障检测的方法,近些年被广泛研究[5]。由于高炉炼铁过程发生各种各样的物理化学变化,以及复杂的生产原理,导致生产状态时刻变化,因此需要利用非参数的方法。此外,高炉炼铁是一个需要人为操作的半自动化过程,主观性较强,采集得到完全无故障的数据矩阵十分困难,需要无监督的过程监测方法[6]。
近些年来,一些无监督和非参数的突变点检测方法已经被广泛研究[7-10]。LUNG-YUT-FONG等[11]提出了一种基于Wilcoxon秩统计量的非参数突变点检测方法。ADAMS等[12]提出了一种基于Bayesian的在线突变点检测方法。CHU等[13]构建了一种非参数模型的突变点检测的框架,利用观测值之间的相似信息,应用在多种不同类型的数据中进行突变点检测。AN等[14]提出了一种基于欧式距离和时间间隔图方法的突变点检测,并实施在实际的高炉生产过程。CHEN等[15-16]提出了一种基于图的突变点检测方法,并建立了相应的统计量。与上述介绍方法相比较,基于图的方法是同时具有无监督和非参数特征的。此外,基于图的突变点检测方法,对采集到的数据特征没有过多限制,适合于高炉炼铁流程。除了本文作者的研究之外,目前尚未应用于工业过程故障检测。MUSULIN等[17-18]利用谱图分析理论进行过程监测,与上述文献不同的是,基于图方法利用的是欧式距离构造最小生成树,并建立了相应的突变点检测统计量。 基于图方法的突变点检测首先计算观测值之间的欧式距离,并根据此构造最小生成树。其次,每一个采样点作为突变点候选值依次将观测值分为两个部分,并计算连接来自两个部分的观测值的边的数目。如果连接两个不同组观测值的边数目较少,则说明存在突变点。这是因为,如果没有突变点存在,观测值之间的连接应该是无序且杂乱无章的。而突变点的存在,观测值更倾向于连接同一组内的观测值,使连接两个组的观测值的边数目较少,从而确定突变点的存在。高炉炼铁是一个复杂的工业生产过程,由于传感器的误差,数据传输干扰等原因,采集到的数据矩阵很可能包含异常值。而异常值存在干扰计算边的数目,从而导致较高的故障误报率。作者进一步考虑加权图方法,对于不同观测值利用不同权值,有效降低异常值对故障检测的影响。
2 问题描述
给定一个数据矩阵 X ∈Rn×m,每一行xi, i = 1,2,…,n是一个包含m个变量的观测值。本文研究目的是验证在上述数据矩阵X中是否存在一个突变点τ。这是一个二样本检验的问题。其中的零假设为

备择假设为

其中,τ为突变点,F0和F1为两种不同的数据分布。
本文需要考虑下述两个假设:
假设1:高炉炼铁过程采集到的观测值之间是彼此独立的。
假设2:在整个高炉生产过程中噪声的分布是不变的。
上述假设的合理性以及可实现性在作者的另一篇文章中已经叙述[14]。
3 加权图方法的突变点检测
3.1 基于图方法的突变点检测
假定存在一个数据矩阵X,在一系列时间序列xi,i = 1,2,…,n中,是否存在突变点的零假设和备择假设均与问题描述中相同。基于图方法的突变点检测首先需要获得观测值之间的连接图。目前得到连接图的方法主要有3种:最小生成树[19]、最小距离对[20]以及近邻图的方法[21]。CHEN等[15]在文献中证明,获得观测值之间连接图的方法不影响突变点检测的结果。
其次,计算连接两个来自不同组观测值的边数目作为统计量。依次设定每一个观测值作为疑似突变点,将全部观测值分为2组,在得到观测值连接图之后,计数连接来自不同组观测值的边数目。当这个边的数目较小时,意味着观测值更倾向于连接同一组内的观测值,则说明此时的疑似突变点为真正的突变点。因为此时两个组的数据分布存在差异,导致观测值连接出现规律。下面将上述突变点检测的方法用公式表示。
首先定义一个指示函数xI,如式(3)所示[22]。

因此,对于突变点 τ 的每个疑似值t,连接两个来自不同组观测值的边数目可以式(4)表示[15]。


图1 10个数据点的最小生成树图 Fig.1 Minimum spanning tree of 10 observations
利用一组数据举例介绍基于图方法的突变点检测原理。给定10个数据,每组数据包含2个变量。其中前5个观测值服从N(0,0.1*I2)分布,后5个观测值服从N((2,2)’,0.1*I2)分布,即在第5个数据处存在一个突变点。根据这10个数据,绘制最小生成树如图1所示。上述10个数据点连接顺序如表1所示。
基于图方法的突变点检测计算连接每个突变点疑似值前后两组数据点的边的数目。例如,当假设第3个数据点为突变点,从表1可以得知,连接第3个点前后两组数据的边数目为2 (数据点3连接数据点4;数据点5连接数据点2)。其他连接疑似突变点前后两组数据点的边数目如表2所示。
从表2可以得知,去除两边数据点后,当第5个数据点作为疑似突变点时,连接前后两个组边数目最小,则说明第5个数据点存在突变,和数据设定一致。
3.2 基于加权图方法的突变点检测
提出一种新的获得观测值之间连接权值的方法。首先,计算前10个测试观测值之间的欧式距离,人为剔除与其他观测值之间欧氏距离较大的观测值,如果出现异常观测值,则可以再取一个新观测值重新计算。剔除可能存在的异常观测值后,计算观测值之间欧式距离的平均值,以及作为参考的观测值平均值 (此步骤可以简单作为异常值剔除的方法,仅用于获得一组正常的观测值。本文提出的加权图方法可以简便地剔除异常值,无需一直人为观察可能出现的异常值,适用于测试观测值维数较高的情况,同时鲁棒性更好)。然后,计算待检测观测值与上述观测值平均值之间的欧式距离。如果该欧式距离大于两倍的标准欧式距离平均值,则认为可能出现异常值,权值设置为0。否则,权值设置为1。如果连续3个及以上的权值为0,则不认为是异常值,作为故障可能出现的情况,权值重新设定为1。然后,计算待检测观测值之间的欧式距离,并与上述的指示权值矩阵加权,将视为异常值的观测值与所有其他观测值之间的欧式距离设置为零,消除异常值的影响。从后续的仿真过程中,可以得出在最小生成树中,这些作为异常值的观测值均会与第1个观测值相连接,消除了异常值的影响。最后,计算连接来自两个部分观测值的边数作为统计量,实现故障检测。
基于图的突变点检测方法通过将观测值分为2组,计算连接来自两个组的观测值的边的数目实现故障检测。由于高炉具有时变性以及正常工况数据采集困难的特点,需要利用无监督以及非参数的方法进行故障检测,所以基于图的突变点检测方法是适用的[14]。考虑到3.1节中介绍的基于图方法突变点检测原理,异常值的出现能影响观测值的连接顺序,导致突变点的检测出现误差,增大故障误报率。因此,需要降低异常值对突变点检测的影响。本文利用最小生成树的方法构建观测值连接图,通过修改边的权值提高突变点检测效果。
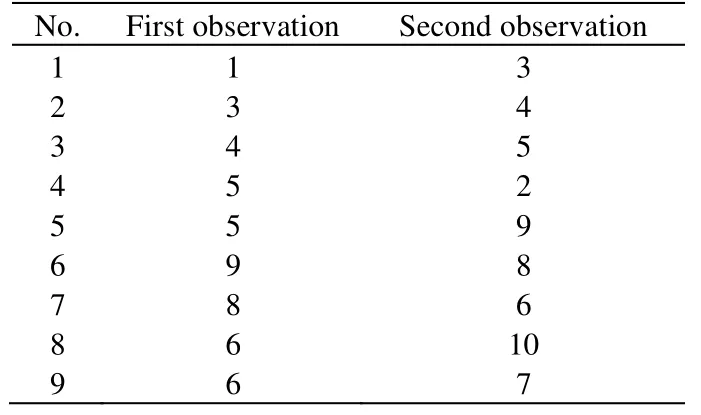
表1 10个数据点的连接顺序 Table 1 Connection order of 10 observations
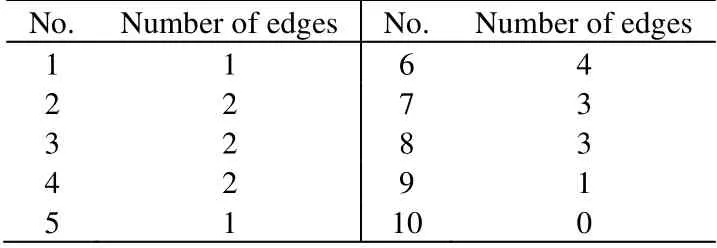
表2 连接每个突变点疑似值前后两组数据点的边的数目 Table 2 The number of edges connecting the observations derived from two group divided by a change point candidate
计算最小生成树的连接权值,首先考虑观测值xi, i = 1,2,…,n之间的欧式距离,如式(5)所示。

其次,利用点乘加权的方法调节边之间的权值,如式(6)所示。

其中

bij= 0时人为设定为inf,起到避免观测值与本身连接,以及将异常值分开的作用。
计算一组正常工况观测值之间的欧式距离,并求平均,记为ave;计算这些正常工况观测值的平均值,记为xstd。计算每一个测试观测值xi与平均观测值xstd之间的欧式距离ti,

当不超过连续3个观测值得到的ti大于2倍的平均值ave时,视为异常值出现,此时将权值记为0;其他情况均记为1。
通过引入加权值 λ,将异常值与正常工况和异常值与故障工况观测值之间的欧式距离人为修改为无穷大,避免异常值参与统计量计算,有效地降低了异常值对故障检测的影响,提高故障检测率。
4 基于加权图方法的高炉过程故障检测
给定一个高炉过程测试数据矩阵 X ∈Rn×m,包含n个采样观测值,每个采样观测值包含m个变量。以及一组正常工况观测值 Y ∈Rl×m,包含l个采样观测值,每个采样观测值包含m个变量(从测试数据矩阵中获得,可以通过观察变量的散点图结合高炉操作工人的手册以及观察观测值之间的欧式距离获得)。τ 是一个突变点,则基于加权图方法的高炉过程故障检测步骤如下。其流程图如图2所示。
步骤1:计算欧氏距离
计算高炉过程采集到的需故障检测的观测值之间的欧式距离,存储在矩阵A中[23]。
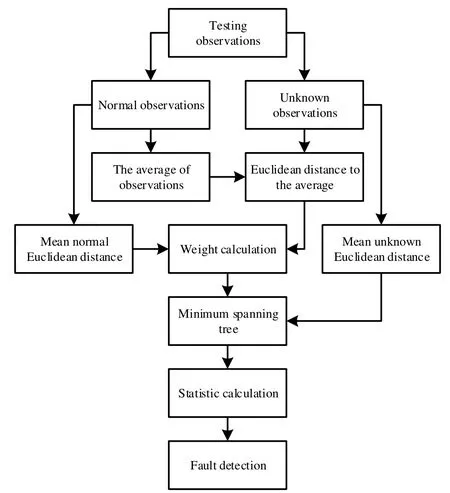
图2 基于加权图方法的高炉过程故障检测流程图 Fig.2 Flow sheet of fault detection based on the weight graph method in a blast furnace process
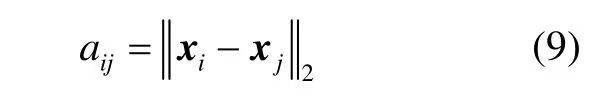
步骤2:计算参考欧式距离以及观测值
计算正常工况观测值之间的欧式距离,并求平均值;计算正常工况观测值的均值。
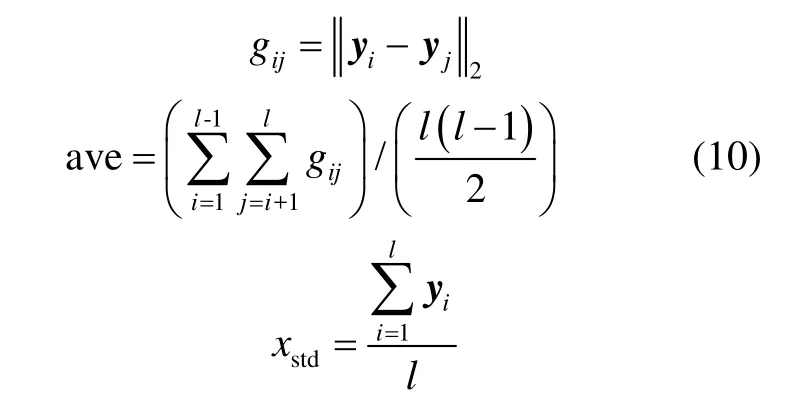
步骤3:计算权值参数
计算测试观测值xi, i = 1,2,…,n与均值xstd之间的欧式距离。

如果pi> 2 * ave,则qi> 0。如果qi以及相邻的qi+1, qi+2不超过连续3个为0,则ri= 0;反之,ri= 1。最后两个观测值的权值参数,根据倒数第3个观测值的权值参数确定。
步骤4:计算图中边的权值
根据步骤3中得到的权值参数,计算得到加权值λ。如果ri= 0,则λ(i,:) = λ(:,i) = 0,反之为1。通过点乘的方式计算最小生成树的权值。

人为将bij= 0设置为无穷大inf,防止观测值连接自己以及剔除异常值的目的。
步骤5:绘制图
根据步骤4中得到的加权值,利用最小生成树方法绘制图。根据权值的大小连接观测值,连接不能出现首尾相连的情况。
步骤6:计算边的数目
根据式(4)计算连接来自两个不同组的观测值的边的数目,其中疑似突变点将观测值分为两个部分。
步骤7:统计量计算
由于边的数目RG(t)和疑似突变点t的位置是有关的,因此为了降低疑似突变点t的位置影响,将边的数目RG(t)标准化。由于较小的RG(t)意味着突变点的存在,因此,为了方便观察,在标准化RG(t)同时,利用取反的方式方便观察故障检测结果[15]。

其中
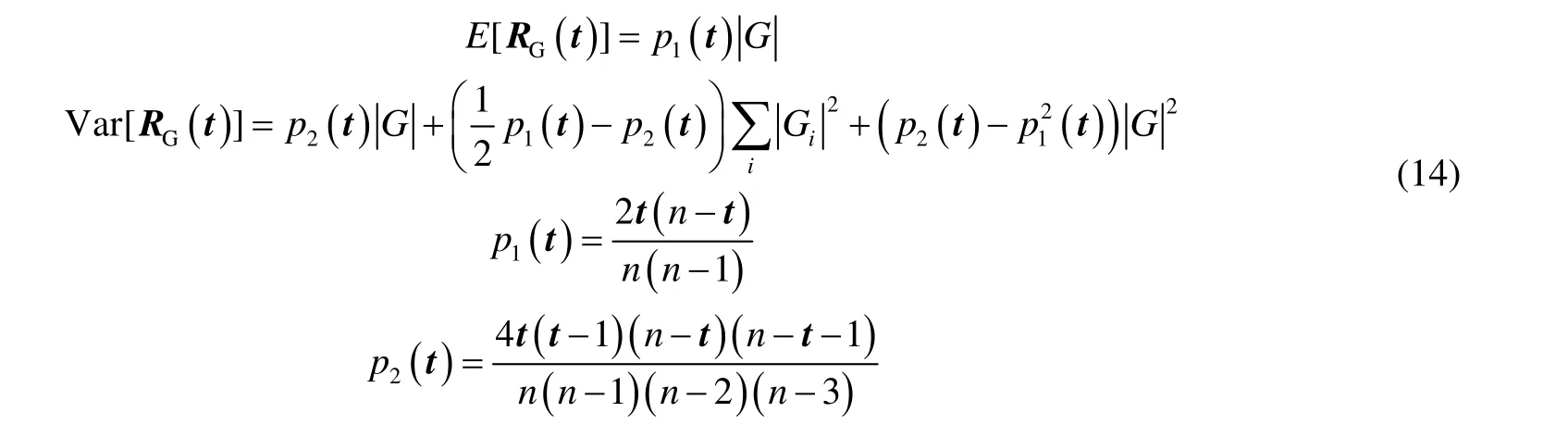
步骤8:高炉过程故障检测
如果ZG(t)中,某一个值大于其他值,则说明有突变点存在。从采样得到的测试观测值中可以分析得到,高炉炼铁过程有故障的存在。
5 研究实例
上述章节中,介绍了基于加权图方法的故障检测原理及步骤。在本章节中,首先利用数值仿真,验证了所提出的加权图方法的突变点检测效果。然后,利用实际的高炉生产数据,验证加权图方法的异常值剔除及故障检测效果。
5.1 数值仿真
本节中,利用40个采样观测值验证所提出的方法的有效性。其中前20个观测值服从N(0,0.1*I2)分布,后20个观测值服从N((2,2)’,0.1*I2)分布。为了验证算法剔除异常值的效果,在全部40个采样观测值中,人为引入10% 的异常值,并且服从N((5,5)’,0.1*I2)分布。为了简便,正常工况数据直接生成。基于图和加权图方法的数值仿真突变点检测结果如图3和4所示,横坐标是采样观测点,纵坐标为相应的检测统计量。为了清楚地对比两种方法的突变点检测效果,检测出突变点时刻以及数值较大的3个统计量的方差如表3所示。比较数值较大的3个统计量的方差是为了验证所提出算法能较精确地检测出突变点,在突变点出现的采样时刻对应于较大的统计量,其他时刻的统计量较小,减少误报的出现。
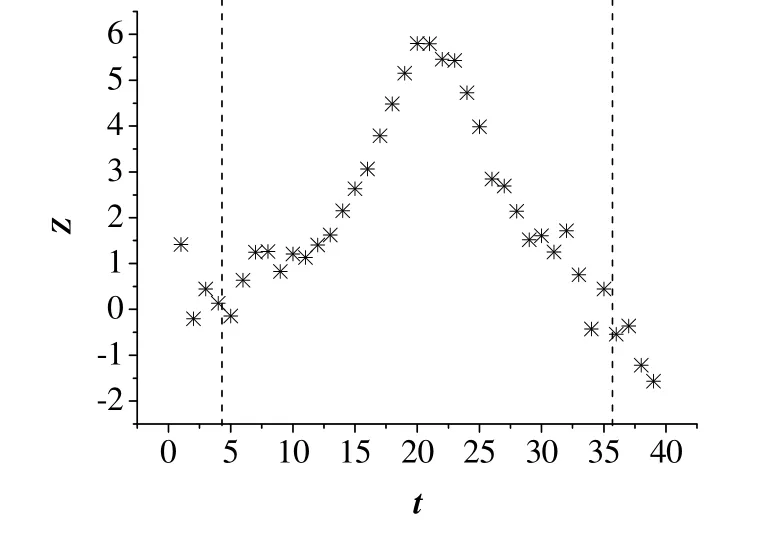
图3 基于图方法的突变点检测数值仿真结果 Fig.3 Change point detection result based on the graph method for a numerical example
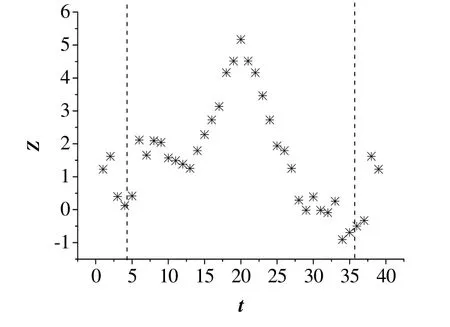
图4 基于加权图方法的突变点检测数值仿真结果 Fig.4 Change point detection result based on the weight graph method for a numerical example

表3 2种方法在数值仿真中突变点检测效果对比 Table 3 Comparison of two methods for change point detection in a numerical simulation
从图3和4中可以得出,基于两种方法均可以准确地检测出突变点,但是基于加权图方法的突变点检测效果较好,且可清楚地得出突变点的出现位置。表3中可以看出,基于图方法的前3个较大统计量数值差别较小,在突变点检测判定中,可能出现误判。而基于加权图方法的突变点检测,利用观测值之间欧式距离,改变了最小生成树中权值计算方式,能够有效降低异常值的影响,使观测值之间的连接具有更好的加鲁棒,减少波动的出现。因此,基于加权图方法的突变点检测具有降低异常值影响的作用,并且可准确地检测到数值仿真过程中存在的突变点,可以进一步实施在实际高炉过程生产数据中。
5.2 高炉过程
高炉炼铁是一个复杂的生产过程,近些年来许多研究学者对高炉炼铁的生产原理[24-25]以及故障检测做了大量研究[26-28]。然而,在高炉炼铁生产过程中,传感器出现故障、网络数据传输出错、少量原料的投入等都能导致异常值的出现,而常见故障检测方法对异常值较敏感,如k-nearest neighbor (kNN)等[29-30]。而异常值的出现能直接影响最小生成树中观测值之间的连接顺序,从而导致较高的故障误报率。本节利用加权图方法降低异常值的影响,提高高炉过程故障检测的效果。
本章节利用某钢铁厂高炉数据验证所提出算法的有效性。采集到的高炉数据矩阵包含18个变量,高炉炼铁过程主要包含6种故障,低料线、炉温过凉、炉温过热、管道形成、悬料以及塌料,具体介绍可以参考文献[6]。本节利用低料线、炉温过凉以及塌料3种故障验证所提出算法的有效性。10个正常工况数据作为校验数据。测试数据包含40个采样观测值,前20个正常工况数据,后20个为相应的故障工况数据。仿真结果如图5~图10所示,横坐标是采样观测点,纵坐标为相应的检测统计量。具体的故障检测时间以及前3个较大统计量的方差如表4所示(故障在第21个采样时刻出现)。

图5 基于图方法对高炉低料线故障检测仿真结果 Fig.5 Fault detection result based on the graph method for low stock line in a blast furnace process

图6 基于加权图方法对高炉低料线故障检测仿真结果 Fig.6 Fault detection result based on the weight graph method for low stock line in a blast furnace process
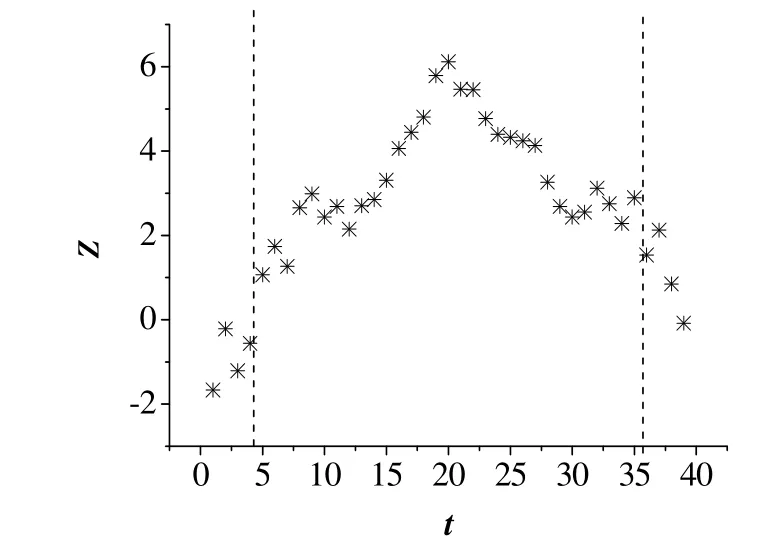
图7 基于图方法对高炉塌料故障检测仿真结果 Fig.7 Fault detection result based on the graph method for slip in a blast furnace process
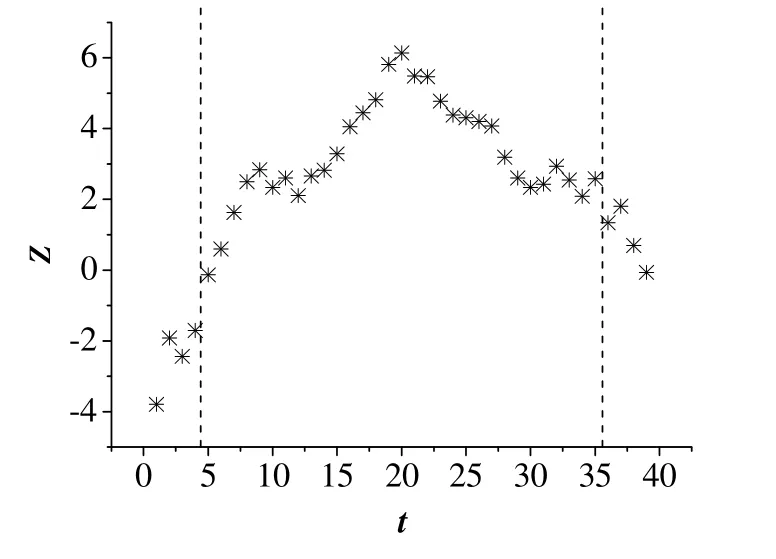
图8 基于加权图方法对高炉塌料故障检测仿真结果 Fig.8 Fault detection result based on the weight graph method for slip in a blast furnace process

图9 基于图方法对高炉炉温过凉故障检测仿真结果 Fig.9 Fault detection result based on the graph method for cooling in a blast furnace process

图10 基于加权图方法对高炉炉温过凉故障检测仿真结果 Fig.10 Fault detection result based on the weight graph method for cooling in a blast furnace process
从图5~10以及表4中可以看出,基于图方法不能有效地检测出高炉过程存在的低料线故障,以及炉温过凉故障也不能及时检测出来。而基于加权图方法对于3种故障,均能够在第一时间准确地检测出故障。此外,基于加权图方法得到的前3个数值较大的统计量方差较大,说明突变点可以明确地被检测,降低了误报率。因此,通过引入权值的方式,计算观测值之间欧式距离,判断数据矩阵中可能存在的异常值,降低了异常值对构造最小生成树的影响,提高了故障检测的效果。而在实际的高炉炼铁生产过程中,及时检出故障是十分重要的,能够降低财产损失,提高操作人员的安全,具有十分重要的意义。

表4 两种方法的高炉故障检测效果对比 Table 4 Comparison of two methods for fault detection
6 结 论
针对高炉过程采集观测值包含异常值的问题,提出了一种加权图的故障检测方法。基于加权图方法利用观测值之间的欧式距离,计算得到新的加权值,有效降低了异常值对构造最小生成树的影响,提高了故障检测结果。从数值仿真和实际高炉生产数据的仿真结果说明本文提出的基于加权图方法可以准确及时地检测出采样观测值中存在的突变点。同时,基于图方法是无监督以及非参数的,适用于复杂的工业生产过程。因此,本文将基于图方法创新性地应用到高炉过程实际工业生产中,具有十分重要的意义。但本文所提出的是一个离线故障检测的方法,在未来的研究中,可以通过考虑聚类方法的思想,实现在线故障检测。
符号说明:
aij— 欧氏距离
ave — 正常工况观测值欧式距离平均值
G — 最小生成树得到的图以及边的集合
RG(t) — 边的数目
t — 可能突变点
xstd— 正常工况观测值的平均值
Gi — 子图,包含所有连接观测值xi的边
Ix— 指示函数
ZG(t) — 算法统计量
τ — 突变点
inf — 无穷大
猜你喜欢
山东冶金(2022年2期)2022-08-08
成都信息工程大学学报(2022年3期)2022-07-21
昆钢科技(2021年3期)2021-08-23
昆钢科技(2021年3期)2021-08-23
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
石材(2020年2期)2020-03-16
数学物理学报(2019年6期)2020-01-13
当代工人(2019年18期)2019-11-11
少年漫画(艺术创想)(2019年6期)2019-10-12
中华建设(2019年8期)2019-09-25
