
基于层次注意力机制的维度情感识别方法
2020-06-18 03:41汤宇豪毛启容高利剑
计算机工程 2020年6期
汤宇豪,毛启容,高利剑
(江苏大学 计算机科学与通信工程学院,江苏 镇江 212013)
0 概述
情感是人类行为和思考的一种状态,随着人工智能技术的不断发展,人们更多地希望改变智能机器客观、冷静的特性,并进行深度开发使其具备人类一样的情感与思维,提供更人性化的服务。美国麻省理工学院PICARD教授根据情感在人类认知、决策、行动选择和语言学习等方面所起到的关键作用,于1997年提出了“情感计算”[1]的概念,其目的是通过赋予计算机识别、理解、表达和适应人的情感的能力来建立和谐人机环境,并使计算机具有更高更全面的智能。
随着情感计算需求的不断增加,需要识别的情感种类越来越多。传统的离散情感识别模型因为情感种类的局限性,在准确率和鲁棒性上达到了瓶颈。连续维度情感描述的是持续不断的情感状态,主要利用维度情感空间对情感状态进行建模和描述。这种方法采用空间中连续的数值来描述情感状态,每个情感状态对应多维空间中的一个点,每个维度对应情感的心理学属性,将描述情感阶段变化的离散情感转换为描述情感连续变化的维度情感。
本文提出一种层次注意力机制(Hierarchical Attention Mechanism,HAM)来学习音频模态中的频域信息和视频模态中的人脸位置信息,并将两者融合进行维度情感识别。该模型分为视频特征学习和层次注意力机制学习两个部分,通过频率注意力机制,计算音频不同频域对情感表达的贡献值并增强凸显情感流露部分特征的影响力,根据多模态注意力机制,分别计算两种模态对情感识别的贡献值并进行融合,以弥补单一模态信息表达不完整的缺陷。
1 相关工作
二维(arousal-valence)情感空间如图1所示,其中,横轴valence代表效价度,表示情感的积极与消极程度,纵轴arousal代表唤醒度,表示情感的激昂与低迷程度。通过设置效价度和唤醒度,可以表示出各种复杂细微的情感并加以区分,如欣喜若狂和怡然自乐描述了不同程度的愉悦之情,眉飞色舞和洋洋得意表达了两个褒贬不同的喜悦。二维情感空间因为其较简单的结构和丰富的情感表达能力,成为目前维度情感识别主要采用的维度空间。

图1 二维arousal-valence情感状态空间示意图
早期的连续维度情感识别方法主要采用手工特征结合传统机器学习算法进行识别。文献[2]采用手工方法提取人脸表情特征,结合最大似然分类、似然空间估计等概率空间分类方法以及隐马尔科夫模型(Hidden Markov Models,HMM)实现维度情感识别。文献[3]采用支持向量机(SVM)算法和k-近邻(KNN)算法对比维度情感识别效果。
随着深度学习的不断发展,卷积神经网络(CNN)和长短时记忆网络(LSTM)在维度情感识别领域得到应用。文献[4]使用手工方法和深度学习方法相结合的方式,首先将维度情感分为简单和复杂两个等级,使用隐马尔科夫模型对情感进行初步识别,然后在此基础上采用双向长短时记忆网络(BLSTM)学习时间上下文信息,识别效果优于传统机器学习方法。文献[5]采用时间池化的方式将多模态特征串在一起进行特征层融合并使用LSTM进行维度情感识别。文献[6]对音频和视频模态分别使用BLSTM进行识别,再运用线性支持向量回归(SVR)对识别结果进行决策层融合。文献[7]使用3D卷积神经网络学习特征上下文信息。虽然上述方法都取得了较好的效果,但是存在如下问题:
1)未考虑到人脸区域凸显情感表达的部分并不相同,如说话人微笑时,嘴部和眼部等凸显情感的部分较人脸边缘区域(头发、耳朵等)对情感识别影响更大[8]。此外,音频不同频域之间对情感识别的效果也有差异,同等处理高频和低频的特征并不合理,如激动时,高频域的特征相比于低频域的特征更能凸显此时的情感状态。
2)不同模态对于情感状态的影响程度是不同的,如说话人沮丧时,低沉的语调相比“面无表情”更能表征当前的情感状态。
3)已有模型所取得的高精确度主要源于数据库提供的手工特征以及在训练和测试模型时投入了高额计算成本。因此,如何采用更合理的方法进行多模态连续维度情感识别,成为当前的一个挑战。
近年来,注意力模型在自然语言处理、计算机视觉、语音识别等领域得到了广泛应用。文献[9]基于注意力模型构建了根据图像生成主题的模型。文献[10]提出基于CRNN与注意力机制相结合的语音识别模型。文献[11]提出将双向长短时记忆网络和注意力模型相结合的视频描述与语义分析的模型。其实注意力模型本质上是一种资源分配模型,主要目的是从众多信息中选择出对当前任务更关键的信息,提高模型的性能。以计算机视觉中的注意力模型为例,特征学习的瓶颈在于需要对整体图像处理[12],但是人类视觉只需要将视觉焦点集中在当前感兴趣的区域上,这一特点能够有效地减少人类视觉系统的带宽。因此,通过保留编码器(CNN、LSTM等)对输入序列的中间输出结果,然后训练一个模型来对这些输入进行选择性的学习并且在模型输出时将输出序列与之进行关联。相比于采用多层网络叠加或者决策层进行多模态融合的方式提高模型准确率,注意力模型使用更加简洁的结构学习对目标有利的特征,并将结果传递到下一层网络中进一步学习,简化了模型的复杂度,提升识别效果。
2 层次注意力机制维度情感识别方法
基于层次注意力机制(HAM)的多模态维度情感识别模型结构如图2所示,该模型主要分为视频模态特征学习和层次注意力机制两个阶段。在模型训练阶段,将训练视频输入到HAM模型中学习情感显著特征,将训练音频输入到频率注意力机制学习显著频域信息,然后利用多模态注意力机制将人脸特征和音频特征融合。在模型测试阶段,将测试视频输入到训练充分的HAM中,先提取人脸情感显著特征,再进行最终情感预测。本节首先对所提出的基于层次注意力机制维度情感识别模型进行概述,然后详细描述各个阶段的学习过程。
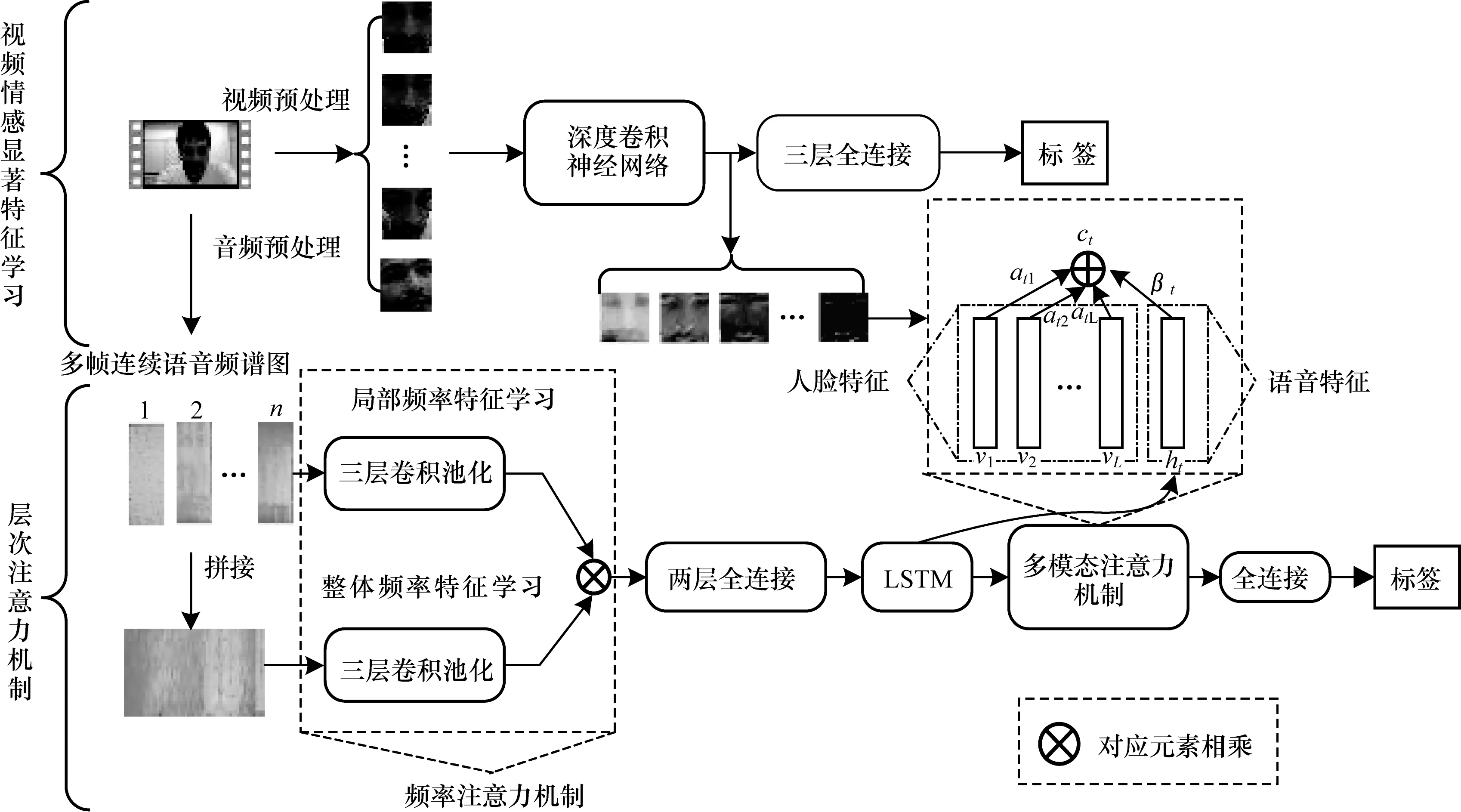
图2 基于层次注意力机制的多模态维度情感识别模型结构
2.1 视频情感显著特征学习
首先通过视频预处理,将视频按照每0.04 s为一帧进行截取,采用数据库官方提供的人脸坐标对每帧图像中的人脸进行截取,再将所有人脸图片归一化到相同尺寸。然后采用深度卷积神经网络,包括VGG、ResNet和Inception对人脸图片序列进行特征学习。将深度卷积神经网络中的全连接层结构,改为三层全连接层,第1层包含1 024个节点,第2层包含512个节点,第3层包含64个节点。其中第1层、第2层全连接采用relu作为激活函数,第3层全连接采用sigmoid作为激活函数,主要目的是学习人脸特征中的高层特征,将特征中影响力较大的维度压缩到接近1,影响力较小的维度压缩到0.5,降低低层特征中的不稳定性。
相比传统方法中选取最后一层全连接层作为特征[13],本文采用最后一次卷积模块所得到的特征图作为人脸特征。全连接层是将池化后的特征拉直并进行压缩的过程,图像的位置信息和通道信息都被打乱,使用注意力模型学习到的特征贡献值只是形式化的参数,缺乏理论实际意义。而特征图则完整地保留了人脸的纹理和层次信息,如图2人脸特征所示,注意力模型更容易根据标签学习到人脸中的情感显著特征。特征图可以更直观地可视化出来,随着网络深度的增加,特征图会越来越稀疏,实验过程中相比于观察最后的识别准确率的变化,情感状态迁移给特征图带来的变化更明显。
2.2 层次注意力机制
本节首先通过音频预处理,按照每0.04 s为一帧提取音频频谱图。因为单帧语音频谱图展现的信息量较少,且缺乏上下文联系[14],所以以当前帧为基准,设置一个长度为n的滑动窗口,将前n-1帧音频频谱图与当前帧频谱图进行拼接,作为当前帧的特征输入。然后滑动窗口以步长为1继续向后滑动采样。假设当前帧数少于n帧,比如第一帧,那么复制n-1次第一帧进行补齐。由于前后帧与帧之间的变化较小,并且一般n取值小于10,因此不会对实验产生波动性影响。
2.2.1 频率注意力机制
如图2所示,将提取好的单帧频谱图序列和整体频谱图分别输入到两个并行的三层卷积池化模块中学习局部频率信息和整体频率信息。局部频率信息模块的输出激活函数为sigmoid,把单帧频谱图特征值映射0~1之间,实际上这里的局部频率学习过程就是注意力矩阵的学习过程,主要学习的是不同频率之间特征的差异对整体频率信息带来的影响。将输出的局部频率特征进行拼接,与整体频率特征进行对应元素相乘,根据情感标签反向传播,来对整体频率特征中的各个维度进行选择性加强或者削弱。相比于只采用单帧音频频谱图作为输入,加入多帧频谱图可以使模型在特征学习阶段学习时间上下文信息,同时学习到帧与帧之间在频率上的差异,而不仅仅依赖于LSTM在后期进行时序构建。此外,传统的注意力模型往往需要在原有网络基础上增加一个分支来提取注意力权重,并进行单独训练,本文中的频率注意力机制在前向传播的过程中利用频率之间的差异性学习注意力矩阵,使得模型训练更加简单。
2.2.2 多模态注意力机制
将经过频率注意力机制处理过的音频特征经过全连接层输入到LSTM中学习时间上下文信息。假设t时刻音频特征为xt,前一时刻LSTM隐藏层输出为ht-1,LSTM门控函数为f(),那么t时刻的隐藏层输出定义为:
ht=f(ht-1,xt)
(1)
假设t时刻人脸特征为V,以vgg19为例,提取的特征是第5次卷积模块的输出,特征大小为196×512,因此V的特征维数为196,每个特征深度为512,那么每维特征的注意力权重计算过程如下:
(2)

(3)
将LSTM中的音频上下文信息和人脸特征融合,计算过程如下:
(4)
其中,λt为t时刻音频特征的权重,1-λt为t时刻视频特征的权重。
2.2.3 模态比例优化函数
在实验过程中发现,当说话人在说话时,镜头中并没有出现人脸,此时只有环境背景,如电脑仪器、桌子等,多模态注意力模型无法准确判断视频中是否存在人脸,只会根据特征中各维度大小依靠情感标签来反向传播分配相应的注意力权重,因此有可能在没出现人脸时依然给人脸特征分配了较大的贡献值。同理,镜头中出现了人脸,但是说话人并没有说话,而有可能是远处的录制视频人员发出的声音,但是仍然有可能给音频特征分配了较大的注意力权重,这样对情感识别造成了误导。在深度学习梯度下降过程中,会在原损失函数中增加L2正则化[15]函数来防止过拟合,其原理主要是通过增加辅助函数来限制原损失函数中无关参数的影响力,引导总损失函数反向求导的方向。因此,受L2正则化启发,本文采用增加辅助标签和辅助损失函数的方式在反向传播的过程中引导总损失函数梯度下降的方向,在出现极端情况(有人脸无声音,有声音无人脸)时,限制多模态融合比例的取值范围。针对音频模态,短时能量衡量了语音在某个时刻声音能量的强弱,由于远处录制人员和说话人距离较远,能量强度差异很大,因而通过设置能量阈值,低于阈值以下的能量强度设为0,以此来规避掉远处录制人员声音的干扰。因此,提取音频短时能量并归一化到[0,1]作为音频辅助标签。针对视频模态,利用opencv中非常成熟的人脸检测库对人脸图片进行检测,检测到人脸则辅助标签置为1,没检测到则置为0。构造的辅助损失函数如下:
(5)
其中,m为短时能量,是属于0~1之间的实数,n为集合{0,1},表示是否检测到人脸。L1在t时刻对λ的梯度为:
(6)
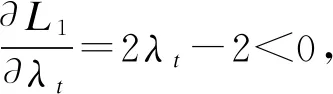
(7)

图3 模态比例优化函数梯度示意图
3 实验结果与分析
3.1 数据库
为验证模型的识别效果,本文选用了AVEC2016(International Audio/Visual Emotion Challenge and Workshop)挑战赛提供的数据库进行实验。AVEC2016数据库是RECOLA(Remote Collaboration and Affective Interaction)数据库的一个子集。数据库提供自然型的数据,是对参与视频会议的人进行录制得到的。数据库提供了训练集、验证集和测试集一共27个长度时间为5 min的视频,由6个法国研究人员在arousal和valence两个情感维度上进行了标注,每隔40 ms进行一次标注,标注范围为-1~1。每个视频长达7 500 frame,最终每帧标签为6名研究人员标注结果取平均值。数据库官方强调了数据库构建的工作量并鼓励使用数据库的研究人员可以采用更合理的方法去提取特征。
3.2 实验设置
在视频特征学习阶段,本文采用R平方系数[16]作为特征学习的评估指标,其通过计算数据的变化来表征回归任务中预测值和标签值的拟合程度。R平方系数越大,代表拟合程度越高,特征提取效果越好。R平方系数函数如下:
(8)
其中,Y_actual是情感真实标签序列,Y_predict是情感预测值序列,Y_mean是情感真实标签序列的平均值。
在层次注意力机制训练与测试阶段,本文采用数据库官方提供的一致性相关系数(Concordance Correlation Coefficient,CCC)作为情感识别的评估指标,计算公式如下:
(9)
其中,μx和μy分别是情感预测值序列和情感真实标签序列的平均值,σx和σy分别是情感预测值序列和情感真实标签序列的标准差,ρ是2个序列之间的皮尔逊相关系数[17],计算公式如下:
(10)
在整个实验中,采用均方根误差(Root Mean Square Error,RMSE)作为损失函数,其定义如下:
(11)
其中,xi代表第i帧的情感预测值,yi代表第i帧的情感真实标签。
在视频特征学习阶段,选取12组视频作为训练集,6组视频作为测试集。对于人脸特征学习,分别采用Vgg19、ResNet34、ResNet50、InceptionV3 4种经典深度CNN进行对比实验。由于以上4种深度CNN对图片大小要求基本都是224×224或者299×299,因此批量训练数量设置为150。在频率注意力机制模型中,使用三层卷积三层池化的卷积神经网络结构作为音频上下文特征学习模型,每帧音频频谱图大小为24×120,输入窗口为5帧音频信息,因此输入频谱图大小为120×120。第1层卷积核大小为2×2,卷积核数量为8。第2层卷积核大小为3×3,卷积核数量为16。第3层卷积核大小为3×3,卷积核数量为32。为了保证整体频率学习与频率局部学习特征图输出大小一致,卷积过程中采用全0填充,保持两者尺寸一致。池化尺寸全部设置尺寸为2×2的最大池化,步长为1。
在验证HAM模型识别效果阶段,设置了3组对比实验:1)仅使用单帧音频频谱信息作为模型输入,在不使用频率注意力机制的前提下与视频特征在特征层融合,对比完整的HAM模型,比较CCC相关度系数;2)在使用频率注意力机制的情况下,与视频特征在特征层融合而没有在模态间使用注意力机制,对比完整的HAM模型,比较CCC相关度系数;3)在使用频率注意力机制和多模态注意力机制的情况下,对使用和未使用模态比例调整函数的实验效果进行对比。
实验操作系统为ubuntu18.04,开发语言为python3.6.2,深度学习框架为tensorflow1.8、keras2.1和theano1.0.0,CPU为英特尔至强E5-2630V4 10核20线程,内存为三星ddr4 2400 16 GB×8(128 GHz),GPU为英伟达特斯拉P100×2 16 GB显存,加速版本为CUDA 9.0。在前期多次实验对比的情况下,为了保证训练充分,将epoch次数设置为1 000。梯度下降优化算法从SGD、Adam和RMSProp三者中选择。初始学习率设置为0.000 5。为了更直观地对比训练和测试结果之间的差异,每训练一个epoch并在相应数据集上测试一次。
3.3 性能比较
3.3.1 人脸情感显著特征学习效果对比
在人脸特征学习阶段,分别在arousal和valence 2个维度上采用4种深度卷积神经网络进行对比实验。特征学习结果分别如图4和图5所示,在arousal维度上,InceptionV3和ResNet50在训练充分的情况下,R平方系数都非常接近0.73,两者损失几乎没有差异,但是InceptionV3相比ResNet50网络参数多达24 734 048个,单次epoch训练时间54 s,而ResNet50单次epoch训练时间为37 s,因此在arousal维度上采用ResNet50学习人脸特征。在valence维度上,ResNet34的R平方系数达到了0.62,损失也非常接近最低的VGG19,而且网络结构相比于其他几种也更简单,单次epoch训练时间31 s,因此在valence维度上采用ResNet34学习人脸特征。
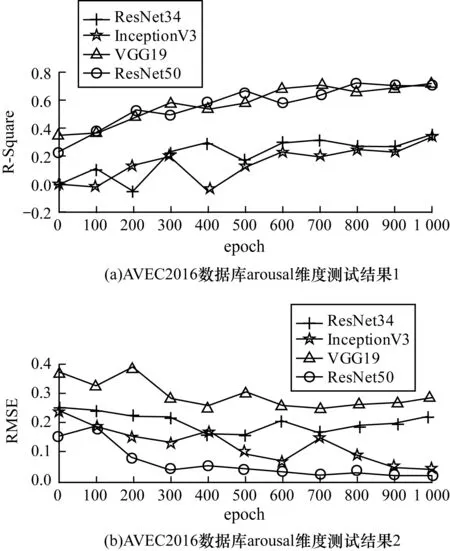
图4 arousal维度视频情感显著特征学习结果

图5 valence维度视频情感显著特征学习结果
3.3.2 层次注意力机制可视化
为更直观地展现层次注意力机制的识别效果,在测试模型阶段保存频率注意力机制和多模态注意力机制所计算出的注意力权重,叠加到原始人脸图片和频谱图上,生成热力成像图,并展示多模态注意力机制人脸特征权重分布图,如图6所示。
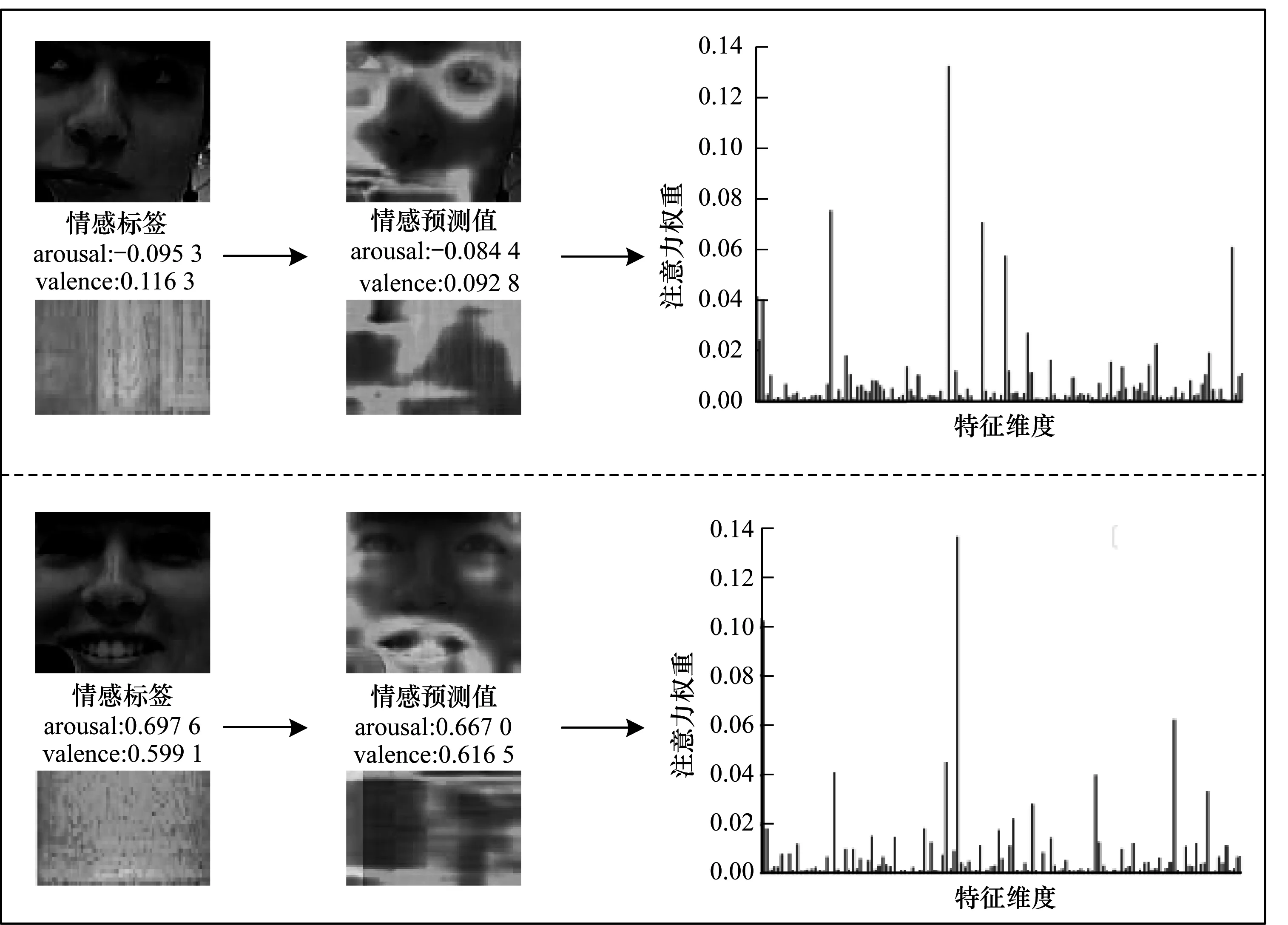
图6 层次注意力机制可视化结果
从图6可以看出,加入了层次注意力机制之后,人脸凸显情感表达的部位比如眼睛和嘴巴都被赋予了更大的权重,而边缘区域比如头发、耳朵等噪音的影响被削弱,语音信号中与当前情感流露更相关的频率得到了加强,如图6所示说话人微笑时,高频域音频特征更加显著。通过注意力权重分布图可以看出,突出情感表达的特征往往集中在少数部分的几个特征中,这样有选择地加强这部分特征的影响力,减少了模型对其他无关特征或者影响力较小特征的关注,在面对维度更多的特征时,模型只需关注对当前识别贡献较多的特征。
3.3.3 层次注意力机制效果对比
在层次注意力机制学习阶段,分别对比了不使用层次注意力机制、仅使用层次注意力机制中的频率注意力机制而不使用多模态注意力机制、使用层次注意力机制和使用模态比例优化的层次注意力机制4种方法进行对比。实验中保存了4种方法在测试集上的最佳结果,并随机选取测试视频逐帧展开绘制预测曲线。在不使用层次注意力机制的情况下,预测曲线非常抖动,与标签曲线差异较大。使用了频率注意力机制的预测曲线,整体走向偏向标签曲线的发展趋势,相对稳定。使用了层次注意力机制的预测曲线,相比只采用频率注意力机制,预测曲线和标签拟合程度有了大幅提升,更加稳定。而加入了模态比例优化函数的预测曲线,在原有的结果上进一步优化,相对情感标签的拟合程度更高。
优化过的层次注意力机制在arousal和valence两个维度上的训练测试过程分别如图7和图8所示。在arousal维度上,当训练epoch达到800次时,此时训练集CCC已经超过0.9,测试集也达到了0.75左右,模型训练已充分,随着训练的继续,模型开始过拟合,测试效果下降。在valence维度上,训练和测试过程都较为抖动,训练epoch达到700次时,模型基本训练充分,但是测试结果并不稳定。无论是在arousal还是在valence维度上,RMSE损失都有一定的波动。因此,在模型训练充分后,取测试阶段的50个epoch结果的平均值作为最终识别结果,最终在arousal维度上CCC为0.732,在valence维度上CCC为0.679。
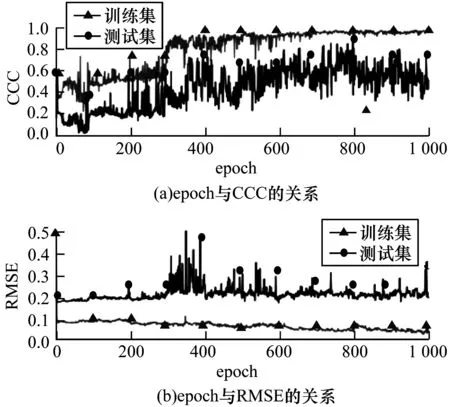
图7 arousal维度优化层次注意力机制训练测试过程

图8 valence维度优化层次注意力机制训练测试过程
具体对比实验结果如表1所示,相比于当前维度情感识别中的其他方法,层次注意力机制虽然在损失上逊色于最优结果,但是CCC相关度系数更能反映情感预测值和情感标签值的拟合程度。从表1可以看出,使用了频率注意力机制在CCC上已经超越了大多方法的结果,在此基础上构建的层次注意力机制的CCC表现最佳。最后对损失进行优化,CCC在2个维度上分别达到了0.732和0.679,说明经过优化的HAM模型可以更有效地提取音频和视频中的情感显著特征进行融合。

表1 层次注意力机制与其他方法的维度情感识别结果对比
4 结束语
基于连续维度情感识别,本文提出基于层次注意力机制的维度情感识别方法。利用大量实验环境下的数据进行人脸情感显著特征和层次注意力机制两个部分的学习。实验结果表明,与目前的主流方法相比,本文方法使用注意力机制对所学习的特征利用上下文信息进行有选择的加强,简化了特征预处理的过程,降低了情感无关因素的干扰,在连续视频与音频模态上的维度情感识别任务中取得了良好的效果。由于采用深度卷积神经网络学习人脸特征,且没有和层次注意力机制融合成一个模型,导致模型损失优化困难与特征学习不彻底,因此下一步将采用更合理的网络结构学习人脸特征,将特征学习和模型预测融为一体,并引入音频手工特征丰富音频信息与人脸特征融合,进一步提高模型识别准确率。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
动漫星空(2018年9期)2018-10-26
传媒评论(2017年3期)2017-06-13
电子制作(2017年9期)2017-04-17
第二课堂(课外活动版)(2016年2期)2016-10-21
人间(2015年8期)2016-01-09
