
基于SAE-GA-SVM模型的雷达新型干扰识别
2020-06-19 08:49罗彬珅刘利民刘璟麒
计算机工程 2020年6期
罗彬珅,刘利民,董 健,刘璟麒
(陆军工程大学 电子与光学工程系,石家庄 050003)
0 概述
随着军事科技的不断发展,在信息化战争中,电子战(Electronic Warfare,EW)[1]已经成为引人注目“第四维战场”,是现代化战争中一种特殊的作战方式,也是一种重要的作战手段[2]。作为电子对抗中的一个关键组成部分,雷达对抗也因电子技术的快速发展而日渐激烈。干扰与抗干扰技术相互制约和互相发展,循环往复,具备在复杂电磁环境下的生存作战能力已成为未来电子装备发展的主要方向之一,干扰识别是雷达对抗过程中重要一步。近年来,数字射频存储(Digital Radio Frequency Memory,DRFM)[3]技术发展不断成熟,使得有源欺骗干扰成为当代电子干扰的主要手段。
雷达的有源干扰识别主要有信号接收、预处理、特征提取与降维以及分类识别,最关键的步骤是特征提取和分类识别。从信号级层面,利用数字信号处理方法根据信号统计特性找出具有表征信号间差异性的特征。文献[4]针对频谱弥散(Smeared Spectrum,SMSP)干扰和切片组合(Chopping and Interleaving,C& I)干扰类型的识别问题,提出了基于双谱分析和分形维数[5]的干扰识别方法,在一定的干噪比条件下,通过支持向量机(SVM)分类器能够较为稳定地识别不同干扰类型。文献[6]针对距离拖引干扰(RGPO)、速度拖引干扰和距离-速度同步拖引干扰的识别问题,提出了基于栈式稀疏自编码器(Stacked Sparse Autoencoder,SSAE)的有源欺骗干扰识别算法。文献[7]建立了欺骗式干扰和目标回波数学模型并进行分析和仿真,构建了抗欺骗式干扰特征参数集,通过仿真和外场试验对提取的部分特征进行了验证。文献[8]针对多种新型干扰的识别问题,采用多域联合的特征提取方法进行干扰类型识别,但未考虑对高维数据进行降维处理。文献[9]针对多种类型的拖引干扰的识别,采用基于Fisher准则的特征选择方法进行降维处理,实现了较优的特征子集组合。文献[10]研究了混合主成分分析(Principal Component Analysis,PCA)与遗传算法(Genetic Algorithm,GA)的特征降维方法,利用PCA-GA-SVM检测模型进行雷达辐射源信号识别。
总体来看,雷达有源干扰识别技术还有待进一步完善。目前针对单一干扰类型的识别技术不断涌现,但是关于新型干扰、多种干扰相结合的复合干扰研究还不全面[11]。多数文献仅是单纯地针对雷达干扰类型的识别研究,而未考虑加入回波信号后的识别情形,不符合现实中的雷达对抗需求,且主要集中在选取有效的干扰信号特征。此外,多数文献不采用或直接采用传统的降维处理方法,这样通过线性映射只能学习到数据的低维结构,不能完全表征其本质特征。
本文对频谱弥散干扰、切片干扰、灵巧噪声干扰、噪声调幅-距离欺骗加性复合干扰与噪声调频-距离欺骗加性复合干扰共5种干扰类型,加入回波信号进行识别检测。通过建立目标回波与干扰信号的数学模型,结合分形理论与信息熵的思想,在时域、频域、小波域、双谱域上采用基于多域联合的方法提取信号特征,并通过堆叠自编码器(Stacked Autoencoder,SAE)对多维特征实现非线性的降维处理。采用遗传算法对支持向量机进行参数优化和调整,构建基于SAE-GA-SVM的雷达有源干扰信号的检测模型。
1 信号建模
根据雷达是否受到干扰以及受到干扰的类型,雷达信号的检测模型为:
(1)
其中,H0表示未受干扰,H1~H5表示检测到干扰信号,w(t)表示接收到的信号,Sr(t)表示雷达回波信号,n(t)表示高斯白噪声,JSMSP(t)表示频谱弥散干扰,JC& I(t)表示切片组合干扰,JSN(t)表示灵巧噪声干扰,JAM-RD(t)表示噪声调幅-距离欺骗干扰,JFM-RD(t)表示噪声调频-距离欺骗干扰。
2 堆叠自编码网络模型
2.1 自编码器
自编码器(Autoencoder,AE)是由HINTON[12]于2006年提出的一种用于学习高效编码的人工神经网络,主要包括编码部分和解码部分[13]。
1)编码阶段
首先将输入进行经过标准化处理,可以提高运算精度,加快求解速度。设标准化后的特征输入向量为x=(x1,x2,…,xn),xi∈[0,1],经过式(2)加权后的到隐藏层的值为h=(h1,h2,…,hm)。
h=f(Wx+b)
(2)

2)解码阶段
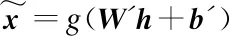
(3)
(4)
式(4)称为均方误差(Mean Squared Error,MSE),通常会在代价函数中增加一个权重衰减项,目的是解决AE中的过拟合问题,最后得到的表达式如下:
(5)
其中,λ为权重衰减项的比重,nl为AE的层数,sl为每层神经元的个数。确定自编码器目标函数后,通过梯度下降算法进行参数θ={W,b}修正:
(6)
(7)
其中,α为学习率。通过迭代运算不断更新权值矩阵W和偏置矩阵b,完成网络训练。
2.2 堆叠自编码器
堆叠自编码器包含多个隐藏层,能够学到更复杂的高维数据。通过逐层训练的方式,将前一层的输出作为下一层的输入。深度自编码器的每两层网络称为一个限制玻尔兹曼机(Restricted Boltzmann Machine,RBM)[14]。主要包含预训练过程、展开过程、微调过程3个步骤。
1)预训练过程
设置网络结构N1-N2-N3-N2-N1,其中,Ni代表每层数据的维度。利用梯度下降算法根据输入数据训练每层的RBM,最后得到每层的权值矩阵W。
2)展开过程
根据预训练的结果,将预训练后的RBM连接起来并对称展开得到堆叠自编码器,将每层的训练的权值W作为堆叠自编码的网络的初始值,解码器每层的权值为对应编码器层数权值的转置。
3)微调过程
基于重构的误差函数最小化原则,利用反向传播(Back Propagation,BP)算法,通过最小化交叉熵函数[15],对初始值W与偏差进行权值微调,交叉熵值越小说明由约简后的属性重构原指标数据的误差越小,最终得到最优网络结构参数,数据由N1维有效降维到N3维。
(8)
3 GA-SVM算法的雷达有源干扰分类
3.1 支持向量机
支持向量机(SVM)是文献[16]提出的一种基于统计学习理论的分类方法,其基本思想是在空间中寻求最优分类面w′x+b=0,使线性样本(xi,yi)正确分离且间隔最大,从而转换为对一个凸二次规划问题的求解。通常样本往往是非线性且不可分的,需引入惩罚因子C与松弛因子ξi,得到式(9):
(9)
使用Lagrange函数及对偶问题,得到最优超平面为:
(10)
进一步引入核函数,使得非线性、不可分的样本最终能够成功分离。径向基核函数(Radial Basis Function,RBF)相比于线性核能够处理分类标注和属性的非线性关系,相比于多项式核有更少的参数,同时具有简单实用、普适性好的优点[17]。本文选取RBF来建立SVM模型,最终得到优化模型如下:
(11)
3.2 遗传算法参数优化
遗传算法是由HOLLAND等人[18]于1975年提出的一种基于生物遗传和进化机制的自适应全局优化搜索方法。该方法具有搜索过程简单、不易陷入局部最优解、寻优效率高等优点。利用遗传算法对SVM参数(惩罚因子C和核函数参数g)进行优化,首先进行参数编码,然后以平均识别率为适应度函数,通过选择、交叉和变异3个基本运算寻找最优值,最后得到优化后的参数模型。基于SAE-GA-SVM的雷达有源干扰的识别流程如图1所示。
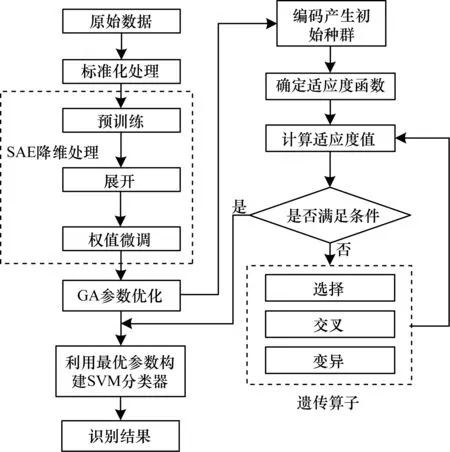
图1 基于SAE-GA-SVM的雷达有源干扰识别流程
4 仿真结果与分析
4.1 仿真实验设置
仿真实验中计算机配置为CPU i3-3227,内存为2 GB,在Windows 7 操作系统下使用MATLAB 2015b进行编码,SVM分类器算法设计采用LIBSVM库[19]。
4.1.1 干扰信号参数设置
设置雷达回波信号调制类型为LFM,电压幅值为1 V,真实目标距离为20 km,假目标距离为25 km,频率带宽为10 MHz,中心频率为1 MHz,脉宽为5 μs,脉冲时间间隔为50 μs,采样频率为33 MHz。SMSP干扰分为5段;C& I干扰分为5段,每段2个时隙;灵巧干扰中的卷积噪声功率为-15 dBw;噪声调幅-距离复合干扰噪声功率为23 dB,中心频率为6 MHz;噪声调频-距离复合干扰噪声功率为15 dBw,调频指数为0.6,中心频率为6 MHz。
结合信息熵与分形理论的思想,采用基于时域、频域、小波域、双谱域的多维特征提取方法,提取特征T={t1,t2,…,t47}共47维,具体如表1所示。

表1 多域联合提取的特征类别
4.1.2 数据预处理
本文首先对数据采用标准化处理,使得各属性特征处于同一数量级,有利于加快计算速度,得到更准确的分类识别效果。根据式(12)将采样数据线性映射到[0,1]范围[22]。
(12)
4.2 仿真实验
4.2.1 基于多维特征提取的雷达干扰类型识别
针对以上提出的6种雷达信号,分别提取如表1所示的47维特征T={t1,t2,…,t47}。设置干噪比(JNR)的范围为-12 dB,-10 dB,…,6 dB,干噪比间隔为2 dB。通过蒙特卡洛仿真每个干噪比下产生600个训练样本,取其中的200个样本用于测试,并通过基于RBF的SVM分类器,重复进行仿真实验100次,取其均值作为仿真实验结果,识别结果如表2所示。由表2可以看出,各类干扰信号的识别率随JNR增大而呈现上升趋势。其中,复合噪声类干扰的识别率较高,能够接近100%的准确率。当JNR小于-8 dB时,切片重构干扰和目标回波信号的识别率明显下降,主要是因为高斯白噪声功率过大,从而导致切片重构干扰信号和目标回波间的特征参数差异性变小,影响了对这两种信号类型的识别。当JNR大于-6 dB时,各类干扰有90%以上的识别率。
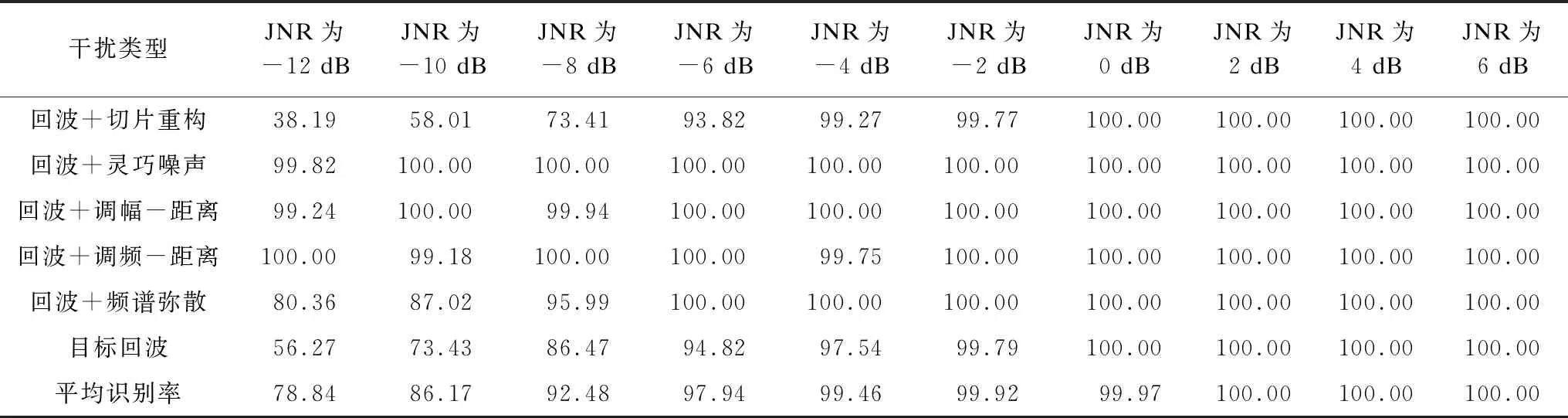
表2 各类干扰信号的识别率
4.2.2 第1隐藏层节点数对SAE的影响
为提高对各干扰的识别率以及有效降低特征维度,本文针对SAE的特征降维效果做了相关的仿真及结果分析,SAE的参数结构对分类识别效果有重要的影响。根据提取的47维特征向量,设定2层RBM进行数据降维处理。输入层的节点数为47,而第1隐藏层节点数选取非常关键,是对原始数据的首次约简,决定了输入层特征的抽取能力。一方面,节点数增多能够加强网络的学习能力;另一方面,节点数的增多会影响网络的泛化能力,出现过拟合的问题,并且也会大幅增加计算量。根据4.2.1节的仿真实验结果,在设置JNR=-10 dB的条件下,通过蒙特卡洛仿真实验对6种信号类型产生600个训练样本,随机抽取200个作为测试集,重复进行100次仿真实验,取其均值作为仿真实验结果,SAE-SVM模型参数设置具体如表3所示。

表3 SAE-SVM 参数设置
为测试第1隐藏层的节点数如何影响分类效果以及改变第1隐藏层的节点数。在微调过程中,SAE利用回馈网络来微调网络的权重,从而使降维后的数据能够更加精准。本文采用47-60-10的结构模型,改变第1隐藏层的节点数。对于不同的SAE结构,微调过程的重构均方误差(Mean-Square Error,MSE)、信号的平均识别率以及平均训练时间如表4所示。从表4可以看出,随着迭代次数的增加,均方误差通过交叉熵函数的不断调整而变小。迭代次数在20以内,均方误差降低的效果最为明显,最后在80次之后趋于稳定。设置的7种SAE结构在迭代次数为100时的MSE值为0.05左右,实现了较好的拟合效果。从信号识别率来看,先是随节点数增加而升高,然后趋于降低,其中在节点数为60处有最高的正确识别率。从模型的训练时间来看,与第1隐藏层的节点数成正比,但从总体上看各个结构模型的训练时间差异不大。通过综合考虑,最后选择第1隐藏层的节点数为60。
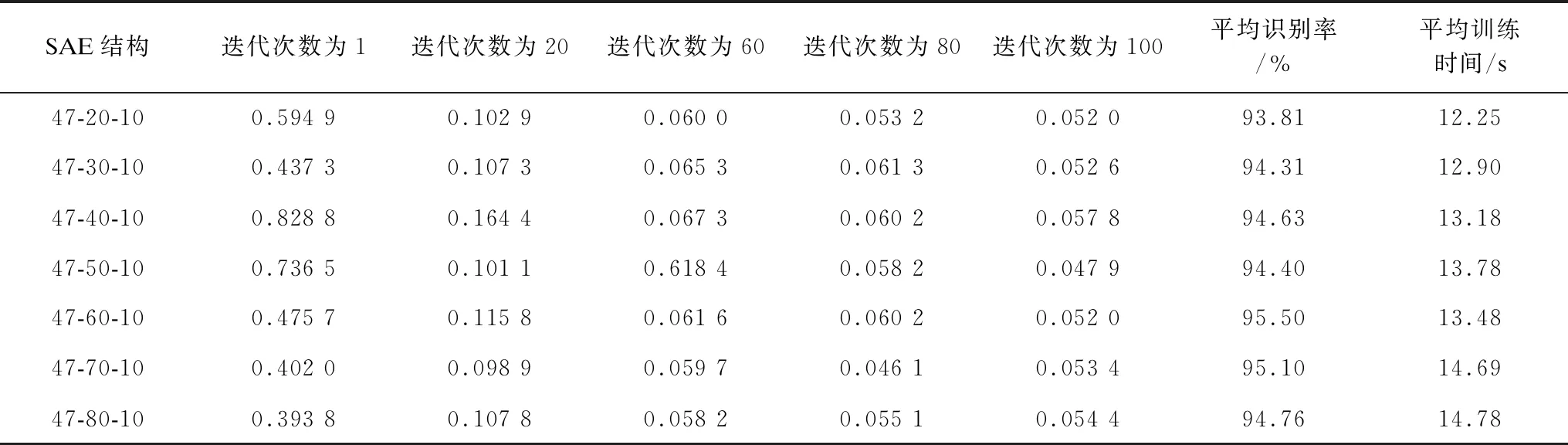
表4 第1隐藏层节点数对SAE性能的影响
4.2.3 输出层节点数对SAE的影响
自编码网络的目的是实现数据的有效降维,在保证识别精度的前提下数据的维度越低,自编码网络降维的效果越好。本文研究重点是选择合适的输出层节点数,测试输出层的节点数对SAE性能的影响,本文采用47-60-10的结构模型改变输出层的节点数,得到不同SAE结构的平均识别率和平均训练时间,如表5所示。从表5可以看出,一方面随着输出层节点数的增加,SAE模型的平均识别率先增加再趋于降低。当输出层节点数为10时,平均识别率最大值为95.50%。另一方面,表5中10种SAE结构的平均训练时间大致相同。综合考虑节点数与平均训练时间、平均识别率的关系,选取节点数为10的输出层结构,最终构建的SAE网络结构为47-60-10。
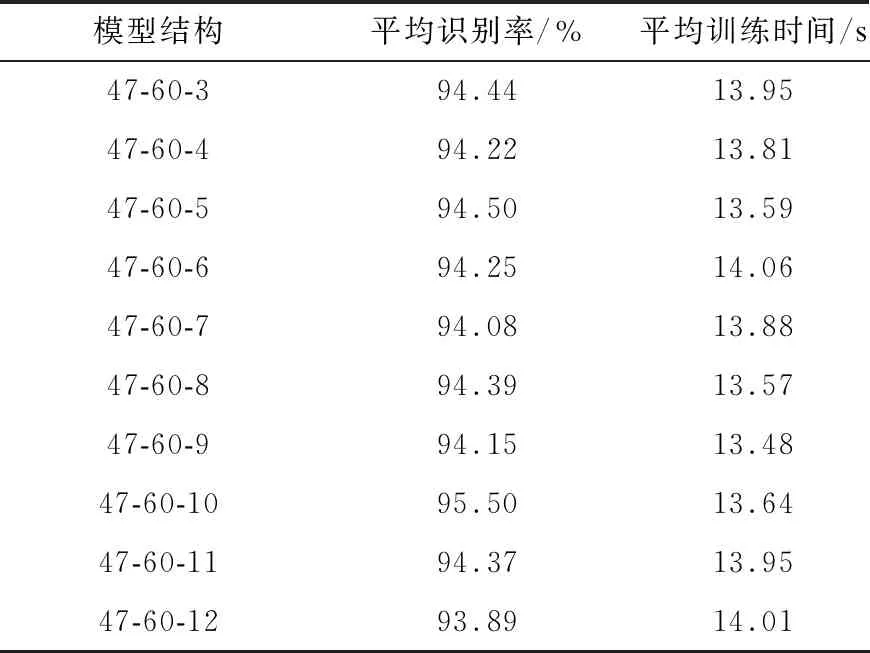
表5 输出层节点数对SAE性能的影响
4.2.4 GA-SVM雷达有源干扰信号分类模型构建
根据4.2.1节的仿真实验设置,SVM选用普适度较好的RBF核函数。为提高SVM的分类效果,本文采用GA算法对其进行参数寻优。利用LIBSVM中的gaSVMcgForClass函数来实现优化SVM参数(惩罚因子C和核函数参数g)。GA的相关设置如下:最大进化代数为200,种群数量为20,惩罚因子C的取值范围为[0,10],核函数参数g的取值范围为[0,10],交叉验证次数V=5,交叉概率为0.8。寻优过程的适应度曲线如图2所示。

图2 GA-SVM 算法参数优化过程曲线
从图2可以看出,随着迭代次数的增加,GA优化SVM模型的参数逐渐达到一个最佳适应度值,最后稳定在96.25%,此时的惩罚参数C与核函数参数g的组合达到SVM的性能最优,即最佳惩罚参数C=2.389,最佳核函数参数g=1.536。
4.2.5 与其他算法的性能对比
堆叠自编码器是一种无监督的神经网络模型,对高维采样数据既能线性变换,又能表征非线性变
换。设定JNR的范围为-12 dB,-10 dB,…,0 dB,在干噪比间隔为2 dB的条件下,本文设置了47-SAE-10-GA-SVM、47-Fisher-SFS-20-SVM、47-PCA-10-SVM、47-PCA-47-GA-SVM、47-KPCA-10-SVM、47-SVM 6种不同的分类模型,对比各模型在不同JNR条件下的平均识别性能、平均训练时间与平均识别时间,具体测试的数据结果如表6所示。根据表6的仿真实验结果可以得出如下结论:
1)冗余的特征信息不但不能够帮助提高对雷达有源干扰信号的平均识别率,反而会大幅增加检测模型计算的时间和复杂度,影响检测模型对干扰信号类型的识别判断。
2)基于特征降维的5种检测模型(47-SAE-10-GA-SVM、47-Fisher-SFS-20-SVM、47-PCA-10-SVM、47-PCA-10-GA-SVM、47-KPCA-10-SVM)都能够在保证平均识别率的前提下有效地进行特征降维,不同程度地去除了冗余信息,降低了运算的复杂度。其中,SAE-GA-SVM的分类算法凭借自编码网络的高效性能,取得了最优的识别率。
3)结合目前现代战场复杂电磁环境的特点,对雷达有源干扰信号识别的关键是进行快速、准确地识别。相较于传统的干扰检测模型,基于SAE-GA-SVM模型对有源干扰的“平均识别时间”用时是最短的。虽然相较于传统的检测模型,其存在训练时间较长的问题,但训练时间是基于战前的准备时间,不是关键因素。综上所述,对于雷达新型有源干扰的识别,基于SAE-GA-SVM的模型是一种可行高效的干扰信号检测模型。
5 结束语
本文针对雷达新型干扰的识别问题,提出一种基于SAE-GA-SVM的干扰检测模型。结合分形理论与信息熵的思想,采用多域联合的方法提取信号时域、频域、小波域、双谱域特征,分别运用6种分类模型进行性能对比,SAE依据神经网络结构对高维数据进行非线性的数据降维与重构,实现最低的特征维度。仿真结果表明,相较于传统的分类模型,SAE-GA-SVM具有较高的识别准确率。由于本文未考虑多种雷达干扰信号同时进入雷达接收机的情况以及没有对采样的数据进行去噪预处理,影响了模型的识别准确率,下一步将对此进行研究。
猜你喜欢
车主之友(2022年4期)2022-08-27
计算技术与自动化(2022年2期)2022-07-04
海军航空大学学报(2021年1期)2021-09-01
通信电源技术(2020年22期)2020-03-27
海峡姐妹(2019年12期)2020-01-14
通信电源技术(2018年3期)2018-06-26
火控雷达技术(2016年3期)2016-02-06
火控雷达技术(2016年1期)2016-02-06
广西文学(2015年9期)2015-10-24
