
基于TextRank的产品评论关键词抽取方法研究
2020-06-19 08:45尤苡名
软件导刊 2020年4期


摘 要:关键词抽取技术能从海量产品评论文本中挖掘出用户关注的焦点,方便后续为用户推荐合适的产品。经典关键词抽取算法TextRank在迭代计算词汇节点的重要性得分时,忽略了邻近词汇节点的影响力差异。为此,提出一种融合TFIDF与TextRank算法(简称TFTR)抽取评论中的关键词。首先,通过引入用户浏览评论后给出的评论有用性反馈,提高有效评论中出现的重要词语权重,对TFIDF算法进行改进。然后将改进后的词频逆文档频率作为词节点特征权重引入到TextRank算法中,以改进词汇节点的重要性得分分配过程。实验结果表明,相比传统的TextRank算法,TFTR算法提取出的产品评论关键词准确性在P@10标准下提高了15.70-/0,证明了该算法的有效性。
关键词:关键词抽取;TFIDF;TextRank;TFTR;评论有用性反馈
DOI: 10. 11907/rjdk.191810
开放科学(资源服务)標识码(OSID):
中图分类号:TP393
文献标识码:A
文章编号:1672-7800( 2020)004-0229-05
0 引言
在个性化推荐领域,互联网的盛行导致数据量激增,人们很难从庞大的数据中直接获取到有用信息。评论文本不仅描述了产品的真实特点,还包含了丰富的用户观点信息,反映出个人偏好。如果从评论文本中挖掘出用户偏好信息,即可将具有相似偏好特征的用户所喜爱的项目推荐给该用户。此外,商家面对过载的评论信息,亟需快速、精确地掌握用户态度,再针对性地作出应对以完善项目。因此,利用关键词提取技术准确、高效地从海量评论文本中挖掘出用户关注的焦点,具有很高的实用价值。作为NLP(自然语言处理)领域一个重要的子任务,它也是信息检索、文本分类、对话系统等热门学术研究的基础,应用范围非常广,例如图书情报[1]、生物医学文献[2]、新闻媒体[3]等。
关键词提取方法可以分为监督性和无监督性两类。前者将关键词抽取任务转化为分类问题,通过人工标注词汇,训练分类模型实现关键词的0/1分类[4]。然而,由于监督性方法面临人工标注工作量大、数据量爆增且内容实时性强等问题,无监督性方法逐渐成为学者们研究的热点,并有取代监督性方法的趋势。常用的无监督性关键词抽取算法包括以下3种:TFIDF算法[5]、LDA主题模型[6]和TextRank算法[7]。大量相关研究都是在以上3种算法基础上融合新的算法,或者将这3种算法本身进行融合。
张瑾[8]将特征词位置及词跨度权值引入到TFIDF中,并在提取新闻情报关键词实验中证明了算法的有效性;YI等[9]针对TFIDF的不足,运用类别间离散和类别内信息熵理论,引入类别判别定义,考虑特征项的类别内和类别间分布,并在复旦大学语料库实验中验证了算法的有效性;张震等[10]分别从用户和商家视角定义了有效关键词,提出基于语言模型的关键词抽取方法,通过实验证明所提模型挖掘出的关键词在推荐系统中有着很好的推荐效果;谢玮等[11]在词语位置加权TextRank基础上引入词频逆文本频率,实现关键词抽取并将其应用于论文审稿自动推荐中;刘竹辰等[12]将特征词在文档内的词距和位置分布信息融入到TextRank模型中,改进了关键词提取效果;宁建飞等[13]主要通过word2vec计算词汇间的相似度,并改进Tex-tRank算法中图节点间的权重分配,以改善关键词抽取效果;夏天[14]利用word2Vec模型将维基百科中文数据生成词向量模型,对TextRank词节点的词向量进行加权聚类,实现关键词抽取;He等[15]提取关键短语的控制词汇及其先验概率作为先验知识,然后利用监督学习算法对TFIDF、Tex-tRank和先验概率等特征进行学习,并在Inspec、Krapivin、NUS和Ke20K 4个公共数据集上验证了先验知识对关键词提取的有效性;刘啸剑等[16]提出一种结合LDA与Tex-tRank的关键词抽取模型,并在Huth200和DUC2001数据集上进行实验,结果表明了该方法的有效性;魏赟等[2]在TextRank算法基础上,引入TFIDF计算词语之间的权重得分,但该方法对权重的赋值仍存在缺陷。
本文在文献[2]的基础上引入浏览用户对评论的有用性反馈,以提高有效评论中关键词的权重,对TFIDF进行改进,然后结合TextRank算法挖掘评论中的关键词。
1 改进关键词抽取方法
1.1 传统TFIDF与TextRank
TFIDF(词频逆文本频率)是计算特征权重最常用的方法[17],用来评估指定词汇在整个文本或语料库中的重要程度。TF表示特征词汇在整个文档中出现的频率,文档中出现频率越高的词语重要性越强。对于某文本i中的词语j,TF计算方式如式(1)所示。
1.3 基于改进TFIDF的TextRank算法
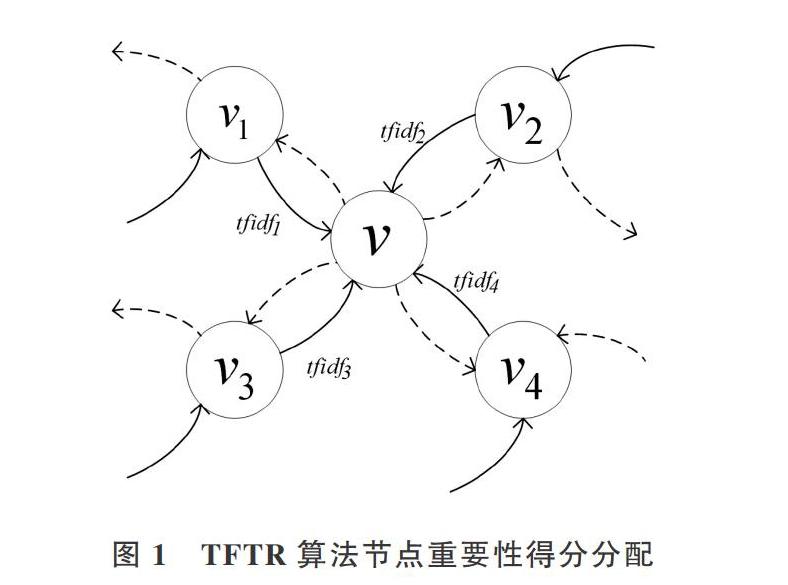
传统TextRank给每个节点赋予的初始权重都是一样的。对于指定节点,在迭代计算邻近节点重要性得分过程中,源节点将自身得分均分给邻近节点,而未考虑节点之间的重要性差异,显然是不符合实际情况的。因此,将改进TFIDF算法引入到TextRank中,将其作为词节点之间的特征权重,调整词节点间的影响力。
如图1所示,{v1,v2,v3,v4}5个词构成一个图,根据改进TFIDF算法计算出4个相邻词节点的词汇特征权重依次为tfidj1、tfidf2、tfidf3和tfidf4。因此,对于指定词节点v,指向该节点的权重分别为相邻节点的词特征权重,从而有效区分不同重要性词节点对节点v的影响。
(4)融合评论的helpful反馈,根据式(6)计算候选关键词的tfidf权重。
(5)构建候选关键词图G=(V,E,其中V为节点集,由步骤(3)生成的候选关键词组成,若词汇在长度为L(原文本中的距离)的窗口中共现,则两个词汇节点之间通过边相连。
(6)将所有候选关键词节点重要性得分初始化为1,根据式(8)迭代计算新一轮节点重要性得分。如果节点误差率小于0.000 l,或达到指定的迭代次数,则算法停止迭代。
(7)根据节点的重要性得分从大到小排序,选取前S个单词作为关键词。
(8)将步骤(7)得到的关键词在原始文本中一一寻找标记。如果关键词位置相邻,则将这两个相邻词汇合并作为多词关键词。
2 实验
实验在Windows 10系统下进行,硬件配置为Intel( R)Core(TM)i7 CPU,内存大小为8CB,硬盘大小为500GB,所用编程语言为Python语言。
2.1实验数据
本文选择亚马逊数据集的Kindle Store子集[19]研究关键词抽取算法,该数据集是与电子书相关的数据集。原始数据集中包含评论者ID、产品ID、评论者名字、评分、评论文本、评论概述summary、评论有用性反馈、发表评论的Unix时间和评论时间戳共9个字段。Kindle Store原始数据集中不同电子书的受欢迎程度存在巨大差异,许多冷门电子书的评论数据数量过少,不利于进行评论短文本挖掘。为了验证本文所提算法对电子书评论关键词抽取的效果,特将用户评论数超过100的电子书采样出来,同时保留产品ID、评论文本和评论有用性反馈3个字段。该数据集采样前后具体情况如表1所示。
将不同电子书的评论信息存储到*.csv文件中,以产品ID作为文件名。文件每一行是评论有用性反馈及某一用户对电子书的评论。利用Python的nltk自然语言处理包对每个文件中的用户评论文本进行文本预处理。首先进行分词与词性标注,然后去除评论文本中的停用词,保留名词、动词和形容词,接着进行词干还原。经过文本预处理之后,评论文本挖掘才进入下一步骤——关键词抽取。
2.2 对比算法及评估指标
(1)评估指标。所用亚马逊数据集的Kindle Store子集不存在人工标注的关键词,对于算法自动抽取出的关键词,根据一定规则人工判别是否为有用关键词。人工判别规则具体分为两条:①是否与书籍的情节、人物、作者等组成元素相关,能否反映电子书特点;②是否有利于对其他用户进行推荐。
为了验证算法对关键词的抽取效果,采用信息检索领域常用的P@k指标作为算法性能评估指标。P@k[20]是将算法自动抽取前k个关键词与人工标注结果比较得到的查准率,如式(9)所示。
P@k=N(k)/k
(9)
其中,分子N(k)表示抽取出k个关键词中人工判别为有用的关键词数目。
(2)对比算法。将改进算法与3种经典算法TFIDF[5]、TextRank[7]和TFIDF+TextRank[2]进行比较。其中,TFIDF无参数设置,后两种算法中d=0.85,词共现窗口size=5。
2.3 实验结果与分析
实验一:词共现窗口对改进TextRank算法的影响。
TFTR作为非监督性的关键词抽取算法,词共现窗口大小作为唯一参数,影响着算法抽取关键词效果。当词共现窗口取size={3,5,7},任意取100本电子书,利用TFTR算法对每本Kindle电子书的所有评论抽取候选关键词,然后在重要性得分排名前10的词汇中人工判断并标注有用关键词,最后计算不同电子书抽取关键词的查准率情况并取平均值。TFTR算法计算得到的P@10如表2所示。
根据表2可知,当窗口的size=5时,算法的P@10指标最大。换言之,算法得到重要性得分排名前10关键词中被人工标注为有用关键词的数目最多。所以为了使TFTR达到较为满意的抽取效果,取size=5。
实验二:不同算法关键词抽取结果比较。
首先利用4种算法对624本Kindle电子书的所有评论抽取候选关键词,然后在重要性得分排名前5/10/15/20的词汇中人工判断并标注有用关键词,最后计算不同电子书抽取关键词的查准率情况,并对其求算数平均作为算法抽取关键词的P@k指标,具体结果如表3所示。需要注意的是,TextRank、TFIDF+TextRank以及TFTR的词共现窗口大小固定为5。
为了更清晰地对比算法间的差异,将表3中的数据绘成直方统计图,如图2所示。
分析图2可得出以下结论:
(1)TFIDF算法在抽取电子书评论关键词时效果最差,这是因为该算法仅考虑了词频和逆文档频率特征计算词汇的重要性得分。
(2)TextRank算法相比于TFIDF算法,查准率略有提高,可能是因为算法通过词汇共现窗口构建词汇联系图,本质上利用了词汇短语间的语义信息。
( 3)TFIDF+TextRank算法相比于前两种单一算法,算法抽取查准率明显提高,说明对TextRank算法引入TFIDF特征能弥补相关不足。
(4)TFTR算法的P@k指标是4种算法中最高的。相比于TFIDF算法、TextRank算法和TFIDF+TextRank算法,TFTR算法提取出的产品评论关键词在P@10标准下的准确性分别提高了19.4%、15.7%和2.3%。
(5)随着k值的增加,4种算法的P@k指标都有一定程度降低,说明随着候选关键词排序的靠后,算法抽取出的关键词中引入了更多噪声数据。为此,未来需要融入更多文档内部或外部信息以改善算法性能。
为了更清晰地观察各个算法自动抽取关键词的效果,现随机挑选出一本电子书,对其全部评论进行挖掘。算法自动抽取出的前20个候选关键词结果如表4所示。
通过分析表4中从TFIDF算法抽取得到的结果,可以大致推断出该电子书内容是与科幻相關的,同时也包含了浪漫、打斗元素。然而与其它3种算法相比,由于抽取出的词汇是一元词汇,一些信息会变得模糊。例如对于plot(情节),从TFIDF算法抽取出的结果中并不能明确知道情节如何,而TextRank算法抽取出的候选关键词可以是二元词汇。从结果中可以发现,有些评论者想表达的是“fictionplot”,也即科幻情节。TFIDF+TextRank算法和TFTR算法沿袭了TextRank算法的优点,即从评论中抽取出双词词汇,从而使候选关键词中包含更多评论信息。此外,相比于其它3种算法,TFTR算法抽取结果中人工标注为有用关键词的数目更多。同时,TFTR算法提取出的候选关键词更加准确、可靠,能更好地抓住不同评论者关注的焦点。
3 结语
产品评论关键词抽取对产品推荐具有重要作用,关键词抽取质量对后续产品推荐有着直接影响。然而,产品评论因其具有文本短小、词汇少及词汇质量参差不齐等特征,增大了关键词提取难度。本文将评论的helpful反馈引入TFIDF中,以提高重要关键词特征权重,并结合Tex-tRank算法,挖掘出评论文本中的产品关键特征。实验结果表明,相比于TFIDF算法、TextRank算法和TFID F+Tex-tRank算法,本文提出的TFTR算法挖掘出的产品特征关键词在P@10标准下的准确性分别提高了19.4%、15.7qe和2.3%。同时,提取出的候选关键词更能抓住不同评论者关注的焦点,从而有利于将产品关键词用于后续产品推荐。然而,TFTR算法自动抽取出的关键词中仍含有噪声词汇,人工识别剔除工作量大,未来可考虑选取可靠的“种子”词汇,利用训练模型对自动抽取出的关键词作进一步分类。
参考文献:
[1] 邱小花,李国俊,肖明.基于Sci-2的国外图书馆学情报学研究主题演变分析——以共词分析为例[J].情报杂志,2013,32(12):110-118.
[2]魏贇,孙先朋.融合统计学和TextRank的生物医学文献关键短语抽取[J].计算机应用与软件,2017,34(6):27-30.
[3]胡学钢,李星华,谢飞,等.基于词汇链的中文新闻网页关键词抽取方法[J].模式识别与人工智能,2010,23(1):45-51.
[4]赵京胜,朱巧明,周国栋,等.自动关键词抽取研究综述[J].软件学报,2017, 28(9):2431-2449.
[5]SPARCK J K.A statistical interpretation of term specificity and its ap-plication in retrieval [J]. Journal of Documentation, 1972, 28(1):11-21.
[6]BLEI D M, NG A Y, JORDAN M I.Latent dirichlet allocation [J].Journal of Machine Learning Research. 2003,3:993-1022.
[7]MIHALCEA R, TARAU P. Textrank: bringing order into text[C]. Pro-ceedings of the 2004 Conference on Empirical Methods in Natural Lan-guage Processing. Association for Computational Linguistics, 2004:404-411.
[8] 张瑾.基于改进TF-IDF算法的情报关键词提取方法[J].情报杂志,2014, 33(4):153-155.
[9]YI J K, YANC G,WanJ. Category discrimination based feature selec-tion algorithm in Chinese text classification[J].Journal of InformationScience and Engineering, 2016, 32(5):1145-1159.
[10] 张震,曾金.面向用户评论的关键词抽取研究——以美团为例[J].数据分析与知识发现,2019,3(3):36-44.
[11]谢玮,沈一,马永征.基于图计算的论文审稿自动推荐系统[Jl.计算机应用研究,2016,33(3):798-801.
[12] 刘竹辰,陈浩,于艳华,等.词位置分布加权TextRank的关键词提取[J].数据分析与知识发现,2018,2(9):74-79.
[13] 宁建飞,刘降珍.融合Word2vec与TextRank的关键词抽取研究[J].现代图书情报技术,2016(6):20-27.
[14] 夏天詞向量聚类加权TextRank的关键词抽取[J].数据分析与知识发现,2017(2):28-34.
[15]HE G X. FANC J W. CUI H R, et al. Keyphrase extraction based onprior knowledge[C].JCDL, 2018: 341-342.
[16] 刘啸剑,谢飞,吴信东.基于图和LDA主题模型的关键词抽取算法[J].情报学报,2016,35(6):664-672.
[17]SOUCY P,MINEAU G W. Beyond TFIDF weighting for text categori-zation in the vector space model[ C]. IJCAI. 2005,5:1130-1135.
[18] 周锦章,崔晓晖.基于词向量与TextRank的关键词提取方法[J].计算机应用研究,2019,36(4):1051-1054.
[19]HE R, MCAULEY J. Ups and downs: modeling the visual evolutionof fashion trends with one-class collaborative filtering[C].Proceed-ings of the 25th International Conference on World Wide Web. Inter-national World Wide Weh Conferences Steering Committee, 2016:507-517.
[20] DAVIS J,GOADRICH M. The relationship between Precision-Re-call and ROC curves[C].Proceedings of the 23rd International Con-ference on Machine Learning. ACM, 2006: 233-240.
(责任编辑:黄健)
作者简介:尤苡名(1993-),女,浙江理工大学信息学院硕士研究生,研究方向为数据挖掘、中文信息处理。
猜你喜欢
中华胰腺病杂志(2021年1期)2021-02-26
山东医药(2020年34期)2020-12-09
当代陕西(2020年17期)2020-10-28
中华胰腺病杂志(2019年4期)2019-08-29
人大建设(2018年5期)2018-08-16
电信科学(2017年6期)2017-07-01
学与玩(2017年5期)2017-02-16
中国教育信息化(2015年10期)2015-08-23
儿童故事画报·发现号趣味百科(2015年5期)2015-07-22
出版与印刷(2015年4期)2015-01-03
