
汉维可比语料数据集
2020-06-22 09:59冯韬李淼曹宜超曾伟辉
中国科学数据(中英文网络版) 2020年1期
冯韬,李淼,曹宜超,曾伟辉
1.中国科学院合肥智能机械研究所,合肥 230031
2.中国科学技术大学,合肥 230026
引 言
语料库是自然语言处理工作的基础资源,具有非常大的应用价值。根据语料库包含的语种数量,可以分为单语语料库、双语语料库以及多语语料库。其中,双语语料库是最常用也是最主要的语料库资源,根据语料库中语料资源的对应关系,其包含平行语料库和可比语料库两种形式。平行语料库中的双语数据严格互译,其按照不同的对齐粒度可以分为词级、句级、段级以及篇章级。平行语料由于其良好的互译性、双语资源严格对齐等特点,已经被广泛应用于自然语言处理的许多方面。但是,平行语料库的构建是一项非常艰巨的任务,需要借助语言学专家的知识,耗时费力,周期较长。而且,从互联网上获取平行语料也是比较困难的,因为互联网中严格互译的文档资源比较稀少,无法从网络中挖掘大规模的平行语料资源。因此,目前平行语料库中的双语资源数量并不能达到实际的应用需求,尤其是在类似于维吾尔语的少数民族语言方面,该问题更加明显。
可比语料作为平行语料的补充,日益受到了人们的重视。可比语料是指内容具有一定的相似性但并不是严格互译的双语资源。两篇可比语料文档的主题相似,描述的是同一个事件,但是独立的产生于各自的语言中,文本之间并不是互译的,这些特点使得可以利用机器学习算法从大规模的互联网文本中获取可比语料。首先利用网络爬虫技术从互联网上挖掘源语言文本,其次采用主题建模算法获取文本的主题,然后从互联网上挖掘类似主题的目标语言候选文本,最后利用跨语言相似度算法获取最终的目标文本,并将其放入到可比语料库中[1]。可比语料也可以应用于自然语言处理的其他任务中,如机器翻译、跨语言信息计算、语言模型等。因此,可比语料对于自然语言处理领域具有十分重要的意义。
我国是一个统一的多民族的国家,维吾尔语信息处理对于促进民族之间的交流与合作具有十分重要的意义,汉维可比语料库的建设可以有效促进汉维机器翻译的研究。目前神经机器翻译已经取得了很好的进展,在多种语言对上的性能超过了传统的机器翻译方法。但是,神经机器翻译是“数据驱动”的方法,其性能严重依赖于平行语料的规模、质量和领域覆盖面,只有大量的数据才能充分的发挥神经网络的性能。所以,汉维平行语料资源的匮乏严重制约了汉维机器翻译的发展,但是人工构建汉维平行语料库又非常困难。因此,在汉维平行语料资源不足的情况下,从互联网上挖掘高质量的汉维可比语料具有重要的意义,可以为汉维机器翻译的研究以及维吾尔语信息处理提供语料资源和技术支撑。
1 数据采集和处理方法
汉语和维吾尔语文本数据是利用网络爬虫技术从互联网上获取的,然后对其进行数据预处理、特征提取、相似度计算等步骤,最终决定是否将其放入到汉维可比语料库中。汉维可比语料挖掘系统框架结构如图1所示。
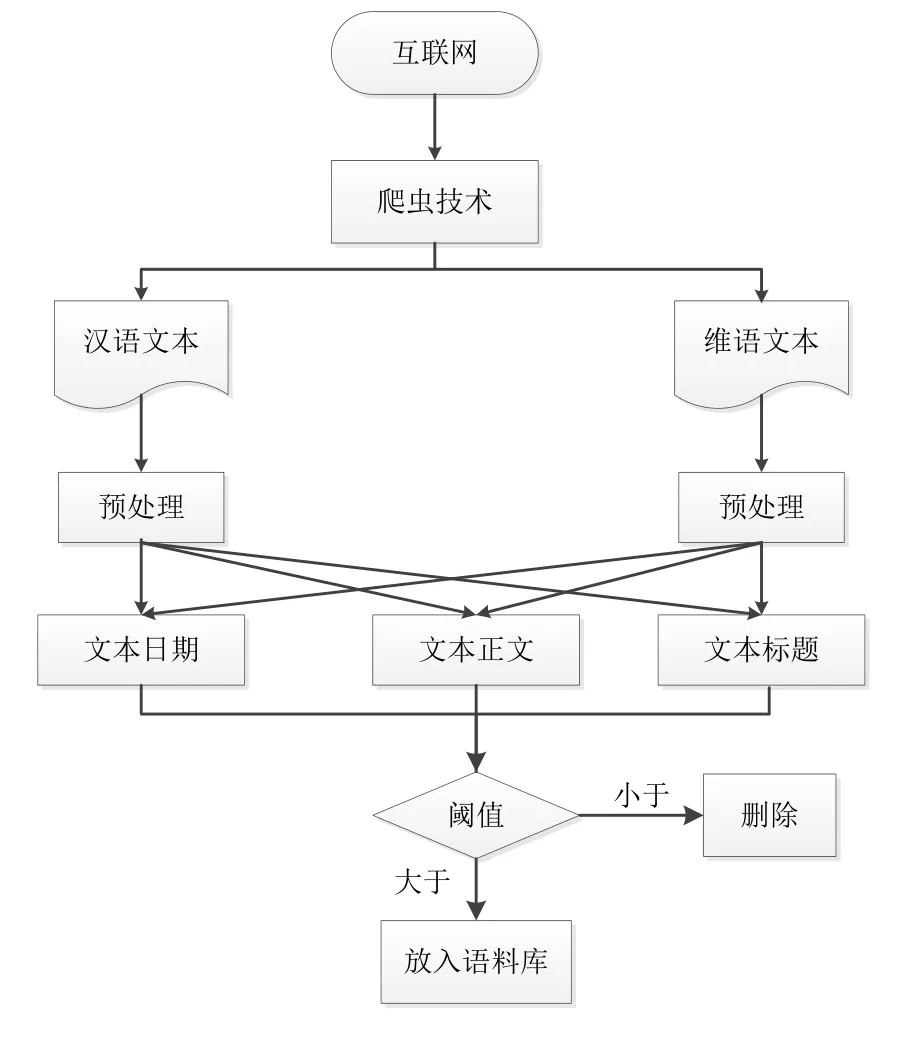
图1 汉维可比语料系统示意图
该系统利用最大连续文本密度和的方法对汉语和维吾尔语的网页内容进行抽取。根据现有的网页正文抽取方法,本方法提出了一个融合结构和语言特征的统计模型,将网页文档转化为正、负交替的文本密度序列。为避免丢失短小正文行,采用高斯平滑技术,通过邻近行内容的连续性,增加短文本行的文本密度[2-3]。最后,结合最大间隔距离,利用动态规划的方法计算最大连续文本密度和来抽取网页正文内容,这样可以有效避免将网页评论等篇幅较长的噪声误判为正文内容的情况发生。
在获取汉语和维吾尔语网页文本之后,对其进行相似度计算[4]。在汉维可比语料挖掘系统中,采用融合多特征的汉维网页文本相似度计算方法。该方法首先抽取预处理后的网页文本的发布时间、标题和正文信息等特征,这里的预处理主要是先去噪,然后翻译维吾尔语标题和关键字,再使用中国科学院的ICTCLSA(Institute of Computing Technology,Chinese Lexical Analysis System)系统进行分词、过滤停用词等处理[5-6]。然后根据上述特征计算双语文档发布日期的差异、正文长度关系、正文阿拉伯数字相似度、标题重合程度以及正文重合程度5种启发信息,并将它们作为特征来判断汉语文本和维吾尔语文本的相似程度。在该方法中利用正则表达式匹配文本的标题和发布日期并且抽取文本的正文内容,然后利用正则表达式提取正文中的阿拉伯数字。选择双语文档发布日期作为相似度计算的特征是因为不同语言文本对同一事件的描述一般是在事件发生后的一段时间内,两篇可比语料文档的发布日期应该是相近的[7-8]。
对于网页文本内容,选择正文长度关系、正文阿拉伯数字、标题重合度以及正文重合程度作为相似度计算的特征。选择正文长度关系是由于两篇可比语料文本对同一事件的描述应基本一致,内容长度比应该在某个值附近分布,可将长度关系转换为长度关系度;选择正文阿拉伯数字相似度是因为可比语料的不同语言文档是对同一事件的描述,那么出现在正文中的量词等阿拉伯数字应基本一致,可以利用欧式距离计算汉维文本中的阿拉伯数字的相似度;选择标题重合程度是因为新闻标题是对内容的概要,可比语料的源语言标题经翻译后应与目标语言标题基本一致,即有较多相同的词汇;选择正文重合程度是因为两篇可比语料文档的主题是一致的,源语言新闻正文经翻译后的文本应与目标语言新闻正文相似,即两篇新闻文档的主旨是相同的。为了提高模型的效率,减少其计算时间,本文取300个字符作为处理的阈值,即文本长度超过300个字符的数据不参与正文重合度的计算。最后通过神经网络训练得到各启发信息的权重并将5种启发信息进行加权融合,从而得到两篇汉维新闻文档的相似度得分。
本文利用机器学习技术构建了汉维可比语料挖掘系统,并取得了较好的实验结果,主要包含以下几个方面的研究工作:
(1)在网页正文提取方面,提出了一种基于最大连续文本密度和的网页正文文本抽取方法。将网页内容转换为正负交替的密度序列,并将密度序列和最大的那部分文本看作是网页正文文本。
(2)提出了一种融合多特征的跨语言网页正文文本相似度计算方法。在该方法中将网页的标题、发布日期以及正文文本作为相似度计算的特征信息,并且利用神经网络算法为特征信息赋予相应的权值,特征信息加权求和的值就是两个网页文本的相似度。
(3)汉维可比语料系统挖掘到的语料经过处理之后,将其上传到相应的网站,供用户下载使用。因此,可比语料的数据是公开共享的。
2 数据样本描述
本数据集的一个样本共包含两个文件:第一个是txt格式的汉语语料文本,第二个是txt格式的维吾尔语语料文本,汉语文本和维吾尔语文本是一一对应的,图2、图3分别表示汉语语言文本和其相对应的维吾尔语语言文本。
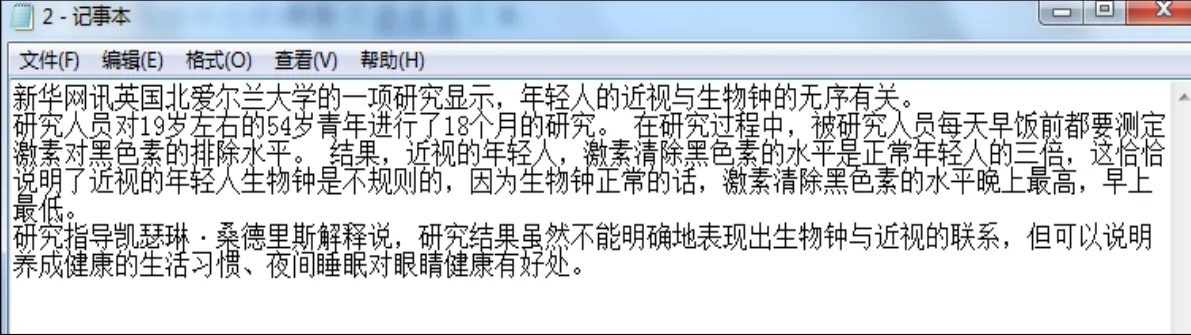
图2 汉语语言文本

图3 维吾尔语语言文本
整个数据集由5000个样本数据构成,即数据集包含5000个汉语语言文本和5000个维吾尔语语言文本。图4和图5分别表示汉语文本的数据结构和维吾尔语文本的数据结构。汉语的文件名是ch,维吾尔语的文件名是uy,每一个文件夹中包含多个文本数据,它们是一一对应的关系。如图4中的1_cn.txt与图5中的1_uy.txt是一组可比语料对。
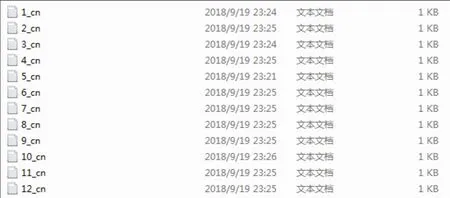
图4 汉语文本的数据结构
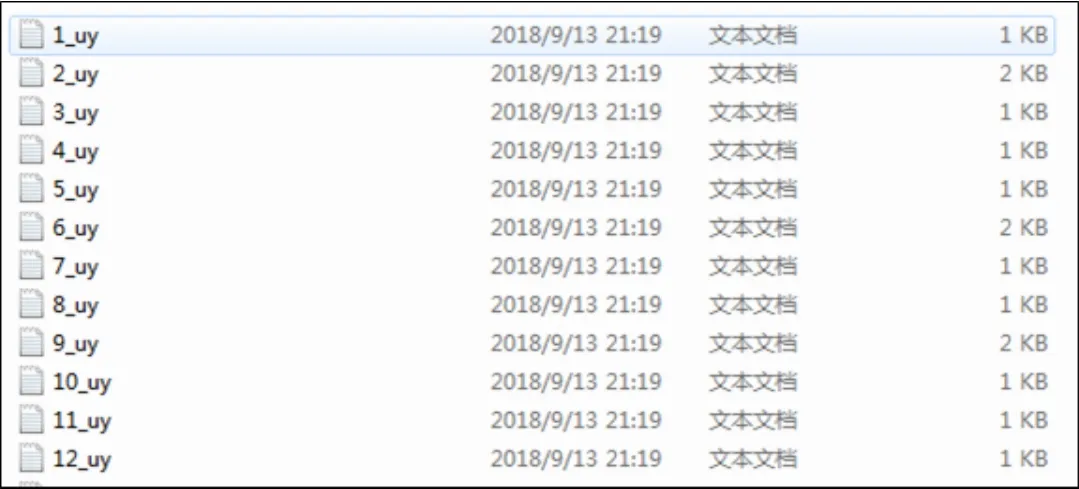
图5 维吾尔语语言文本数据结构
3 数据质量和评估
为了保证可比语料数据的质量,将汉维可比语料加入到数据库后,审核人员会对这些数据进行进一步筛选和审查。并且为了更好地服务审核人员,我们开发了远程Web网页系统供审核人员使用,在网页中显示汉维可比语料供专家审查。因此,维吾尔语语言专家们可以通过远程登录网页的方式对汉维可比语料进行审核,对于审核结果不达标的可比语料,将它们从汉维可比语料库中删除。
在获取汉维可比语料的过程中,我们使用了正则匹配算法对维吾尔语和汉语语料文本进行去噪处理。针对网页文本杂乱无序、不规范等特点,我们把网页中的一些冗余标签,如“