
基于k-means算法实现商品的聚类研究
2020-06-22 13:23张一帆胡佳浩李依桥
数字技术与应用 2020年4期
张一帆 胡佳浩 李依桥
摘要:商品的数量非常大,需要按照一定的标准分为k类,如何把众多数据对象,分为合适k类商品,成为数据分析中的一个研究问题。本文主要阐述了该模型的具体实现过程,主要包括数据采集、数据归一化处理、构造算法模型、评估算法模型。通过采用实例数据集进行模型的训练和测试,实验结果表明:该模型能较准确的进行商品对象的分类,测试误差较小。
关键词:机器学习;k-means算法;Python
中图分类号:TP311.13 文献标识码:A 文章编号:1007-9416(2020)04-0000-00
0引言
如今网站的快速发展,人们的生活和工作都离不开网络。人们的生活节奏也在逐渐加快,工作越来越忙了。网购网站吸纳了众多的群众的参与,积累了大量的用户资源。而且我国广大的女性群体为网购网站提供了良好的用户基础[1]。一个好的网购网站可以带运输等多种产业的发展,但是目前的网购网站对用户的数据处理有时候不够准确,商品分类标准不够准确。通过对网站数据进行分析,采用k-means算法较好的完成商品配对,为网站用户提供较好的服务。
1 K-means算法
K均值(K-Means)算法是无监督的聚类方法,实现起来比较简单,聚类效果也比较好,因此应用很广泛。K-Means算法针对不同应用场景,有不同方面的改进。我们从最传统的K-Means算法讲起,然后在此基础上介绍初始化质心优化K-Means++算法,距离计算优化Elkan K-Means算法和大样本情况下Mini Batch K-Means算法[2]。
我们给定一个数据集D,以及要划分的簇数k,就能通过该算法将数据集划分为k个簇。一般来说,每个数据项只能属于其中一个簇。具体方法可以这样描述:
(1)假设数据集在一个m维的欧式空间中,我们初始时,可隨机选择k个数据项作为这kk个簇的形心Ci,i∈{1,2,…k},每个簇心代表的其实是一个簇,也就是一组数据项构成的集合。然后对所有的n个数据项,计算这些数据项与Ci的距离(一般情况下,在欧式空间中,数据项之间的距离用欧式距离表示)。比如对于数据项Dj,j∈{1,…n},它与其中的一个簇心Ci最近,则将Dj归类为簇Ci[3]。
(2)通过上面这一步,我们就初步将DD划分为k个类了。现在重新计算这k个类的形心。方法是计算类中所有数据项的各个维度的均值。这样,构成一个新的形心,并且更新这个类的形心。每个类都这样计算一次,更新形心。
(3)对上一步计算得到的新的形心,重复进行第(1),(2)步的工作,直到各个类的形心不再变化为止[4]。
2分类实现
本次使用的样本数据一共有300行,对它们进行数据分类。分类过程具体实现分为四个步骤,分别是采样数据、样本数据可视化、数据分类,显示分类视图。
2.1获取数据
我们获取300个样本数据,同时做成表格,代码如下:
import pandas as pda
import numpy as npy
import matplotlib.pylab as pyl
import pymysql
conn=pymysql.connect(host="127.0.0.1",user="root",passwd="root",db="tb")
sql="select price,comment from goods limit 300"
dataf=pda.read_sql(sql,conn)
x=dataf.iloc[:,:].as_matrix()
2.2模型分类
我们让300个样本数据划分为不同的类别,该部分的核心代码如下所示:
from sklearn.cluster import KMeans
kms=KMeans(n_clusters=2)
y=kms.fit_predict(x)
print(y)
for i in range(0,len(y)):
if(y[i]==0): pyl.plot(dataf.iloc[i:i+1,0:1].as_matrix(),dataf.iloc[i:i+1,1:2].as_matrix(),"*r")
elif(y[i]==1): pyl.plot(dataf.iloc[i:i+1,0:1].as_matrix(),dataf.iloc[i:i+1,1:2].as_matrix(),"sy")
elif(y[i]==2): pyl.plot(dataf.iloc[i:i+1,0:1].as_matrix(),dataf.iloc[i:i+1,1:2].as_matrix(),"*k")
pyl.show()
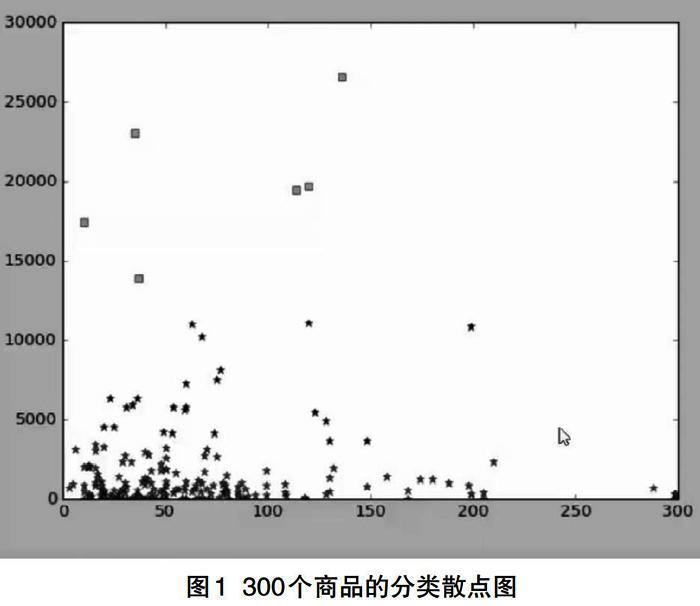
2.3分类结果
对于我们的测试数据的分类结果,我们首先标每类数据,黄色方块代表第一类,黑色五角代表第二类,红色五角代表第三类。为了更直观的的理解样本数据,数据采用Matplotlib库进行绘图分析,如图1所示。
3结语
本文通过采用k-means算法对商品数据进行分析,采用Python数据可视化库中的函数和Matplotlib库完成对数据的分类。通过测试结果,分类结果达到了相对的平均,基本能够满足我们的要求。
參考文献
[1]魏建东.K-means初始化算法研究[D].南京:南京理工大学,2015.
[2]宋建林.K-means聚类算法的改进研究[D].合肥:安徽大学,2016.
[3]李卫平.对k-means聚类算法的改进研究[J].中国西部科技,2010(24):49-50.
[4]刘越.K-means聚类算法的改进[D].桂林:广西师范大学,2016.
收稿日期:2020-03-15
基金项目:2019年省级大学生创新创业训练计划项目:ID3算法在网络购物满意度预测研究中的应用(S201910722012)。
作者简介:张一帆,男,陕西渭南人,本科,研究方向:软件工程。
Research on Commodity Clustering Based on Kmeans Algorithm
ZHANG Yi-fan, HU Jia-hao, LI Yi-qiao
(Computer College of Xianyang Normal University, Xianyang Shaanxi 712000)
Abstract:The quantity of commodities is very large, which needs to be divided into k categories according to certain standards. How to divide a large number of data objects into appropriate K categories of commodities has become a research problem in data analysis. This paper mainly describes the specific implementation process of the model, including data collection, data normalization, algorithm model construction, evaluation algorithm model. Through the training and testing of the model with the case data set, the experimental results show that the model can classify the commodity objects accurately, and the test error is small.
Keywords: machine learning;k-means algorithm;Python
猜你喜欢
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
