
基于时间集分割的蒸汽流量预测模型
2020-06-22 13:15王梦柯何利力
软件导刊 2020年5期
王梦柯 何利力


摘 要:由于制造业生产数据具有较强时段性,相关工艺蒸汽流量预测方法精确度不高,无法有效节能降耗。针对该问题,提出基于时间集分割的蒸汽流量预测模型。基于工艺生产情况及原始数据的时段性,将日生产工艺流量时间集划分为工单稳定生产时段、工单启动后/结束前时段、非工单时段,采用逐点回归模型预测工单稳定生产时段,利用曲线补全模型预测工单启动后/结束前时段。非工单时段无生产,因此无需进行预测。综合逐点回归—曲线补全预测结果,得出日工艺用蒸汽流量。实例研究表明,相较于传统未分割时间集的单一预测模型,基于时间集分割的逐点回归—曲线补全组合预测方法精确度达94%以上。基于时间集分割的组合模型不仅预测精度高且较稳定,可为蒸汽生产与实时调度提供决策依据。
关键词:时段性;时间集划分;逐点回归;曲线补全
DOI:10. 11907/rjdk. 191885 開放科学(资源服务)标识码(OSID):
中图分类号:TP306文献标识码:A 文章编号:1672-7800(2020)005-0088-06
0 引言
一个精确的工艺用流量预测模型对于蒸汽供应设备的调度优化与企业稳定生产具有重大意义。国内外现有流量预测方法可分为3类。
(1)基于数学分析的模型。如邹伯贤等[1]将自回归滑动平均模型(Autoregressive?Moving?Average Model,ARMA模型)应用到网络流量预测中,取得了较好的预测结果,使网络过载预警成为可能;刘艳丽等[2]提出一种改进的ARIMA预测模型,通过优化模型识别与参数调整提高了交通流量预测精度。
(2)人工智能模型。如吴海姬等[3]采用BP神经网络建立主蒸汽流量预测模型,但神经网络存在易陷入局部极小点、预测精度差等缺点;王雷等[4]针对实际生产过程中主蒸汽流量预测,提出一种基于支持向量机(Support Vector Machine,SVM)的主蒸汽流量回归预测方法,然而该方法计算模型比较复杂,当数据规模较大时,耗时较长;Fu等[5]基于平均影响值和支持向量回归,提出了一种新的主蒸汽流量预测模型,该方法可有效减少模型维数,提高预测精度。
(3)组合模型。如张维平等[6]提出一种基于粗糙集理论与最小二乘支持向量回归算法相结合的主蒸汽流量预测方法,避免了常规最小二乘支持向量回归算法根据经验选取输入参数的盲目性;Gao等[7]采用小波分析与人工神经网络相结合的方法建立小波神经网络短期交通流预测模型,取得了更好的预测精度与更快的收敛速度;Mouatadid等[8]首次提出复发长短记忆网络与最大重叠离散小波变换及自举技术相结合,并应用于农业灌溉流量预测,取得了准确的预测结果。
现有方法虽然在一定程度上提高了预测性能,但大多数方法不适用于预测制造企业生产工艺蒸汽流量,因为实际生产工艺流量数据具有较强时段性,若直接采取某种方法进行预测,结果往往不够精准。因此本文提出一种逐点回归——曲线补全的组合预测方法,根据不同时段数据特性和影响因素,先对时间集进行分割,再针对不同时段采用不同的预测方法,以提高预测性能,达到企业节能降耗的目的。
1 问题与数据描述
本文研究对象为某大型企业制丝线蒸汽流量预测及供能应用。根据次日计划工单集合预测工艺用蒸汽流量,预测频度为5分钟/次。通过深入剖析工艺蒸汽历史流量数据,充分考虑产品、工艺线、时间段等因素对流量的影响,利用最佳数学方法表示蒸汽变化规律,最后基于规律对次日工艺蒸汽流量进行预测。
该厂蒸汽由4台蒸汽流量输送大小不同的锅炉进行供应,关于制丝生产工艺蒸汽流量的采集点位有100余个,数据采集频率2次/分。工单数据集合[Wm,na][{order_id,t_s,t_e,b,d,a}],其中order_id表示工单编号且唯一,m表示第几天,na表示工单生产次序,t_s表示工单生产开始时间、t_e表示工单生产结束时间、b表示生产产品、d表示生产工艺段、a表示生产工艺线。工单数据和流量数据融合后数据集合[o_m={(order_id,t_j,v_j,b,d,a)|][j=1,2,?2880}],其中o_m表示第几天数据集,t_j表示采集时间点,v_j表示流量值。
本文从工艺蒸汽流量数据集中选取2018年1月8日至1月12日制丝A线烘丝段蒸汽流量数据进行可视化处理,绘制5日内蒸汽流量时间曲线图。
由图1可以看出,原始日蒸汽流量变化具有显著的时段性,基本分为3类时段。结合业务调研及数据探索可知,流量处于平稳波动状态的时段为工单稳定生产时刻,工单启动/结束时段为稳定生产开始前一段时间段与稳定生产结束后一段时间段,非工单时间段即非生产时间段。
2 模型与方法
2.1 基本思路
实验采用2017年6月1日到2018年12月31日蒸汽工单流量融合数据作为预测模型的训练数据集,采用2019年1月7日到1月11日数据作为预测的校验数据集,根据工厂日历通过数据处理将非工作日剔除。
根据卷烟厂实际调研情况及大量数据可视化分析可知,工单正常生产时间段是蒸汽流量曲线波动较为稳定的时间段。在工单稳定生产前的一段时间,曲线波动主要处于管道预热阶段,预热时间长度受生产产品、工艺线、工单次序影响,此外预热阶段蒸汽曲线还可能受人为操作影响;而工单稳定生产结束后的一段时间内,流量逐渐减少,最后趋于某一个值,为后续工单生产作准备。
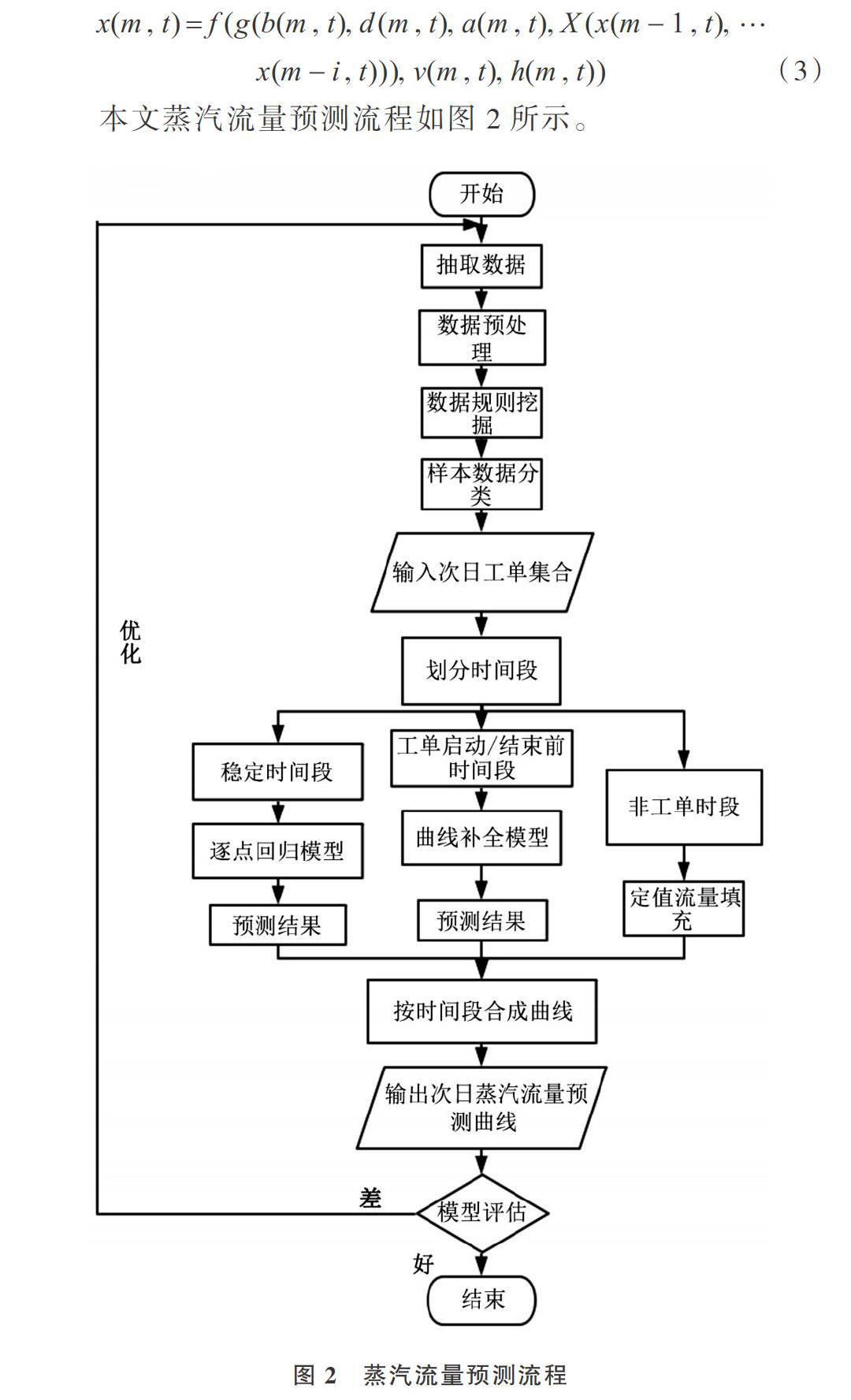
为提高预测精确度,分析基于分割后的时间集数据特点,采用相应建模方式进行预测,即工单稳定生产时段采用逐点回归模型,工单启动/结束时段采用曲线补全模型,非工单时段分为工单间非生产时段和非工单间非生产时段,其中工单间时段流量用前一个工单末尾流量值填充,非工单非生产时段流量用0填充,故无需预测。综上所述,预测天m时间点t处于的时间集不同,预测工艺蒸汽流量[x(m,t)]采用的预测方法也不同。主要包括工单稳定生产时刻蒸汽流量预测逐点回归方法与工单启动/结束蒸汽流量曲线补全方法,则蒸汽流量预测表达式为:
2.2 数据预处理
由于数据采集环节较多,实际收集的数据存在多种不连续、毛刺等问题,在建立预测模型之前需进行相应数据处理,还原数据连续性和真实性。
坏数据出现的位置和时间是未知的,具有很强的随机性。其表现形式有多种,大致可划分为3类:①单点空流量,该类坏数据主要是因为传感器出现故障,没有采集到数据或数据丢失;②单点毛刺流量,该种坏数据在整体数据中表现为急剧增大或急剧减小,与相邻流量有明显区分;③局部数据连续出现空流量,其表现为某个时间段内整体流量连续出现空值,与前后时间段内的流量曲线走势明显不同。
针对以上不同情况,采用不同处理方法处理数据。
(1)插值法。本文根据具体数据情况,采用插值法对缺失值进行补全。基本思路为:逐条检查融合集合o_i中每个工单即order_id采集的流量值,如果是空值,则获取其索引号[hi]及其前一个记录的索引号[hi-1]和值[ri-1],然后继续向后遍历并保存每个遍历值索引号,直到获取后面一个非0的值[rn]及其索引号[hn],计算两个非0数据之间的距离[hn]-[hi],用插值法将缺失的数据计算出来。
(2) 阈值法。通过对原始数据的可视化分析,可知毛刺数据均为单点毛刺且其值与前后点绝对差值均大于0.3t/h。故采用设置阈值法确定毛刺数据出现的位置,然后用插值法进行替换。
2.3 基于工作状态的时间集划分
通过实际业务调研及影响因子相关研究可知,时间点划分受产品、工艺线、工单次序、工艺段影响。结合蒸汽数据特点,故提出基于特征点对训练数据集中工艺日用蒸汽流量时间序列进行时间集分割,通过对大量训练数据集中流量曲线特征点进行分类、分析,可标准化预测工单稳定时段、工单启动/结束时段、非工单时段范围[9]。特征点指日蒸汽时间序列中对其形态及整体趋势变化影响较大的数据点。原始数据时间序列采集频率2次/分,故日蒸汽时间序列[Y{yt1,yt2,?yti|i=1,2,?2 880}]的特征点获取原则如下:
(1)根据生产计划表剔除非工单时间段,假设取生产启动时间为[t1],生产结束时间为[tm],故生产时间序列起始点和终止点为n=1或n=m。
具体流程包括:首先,由训练数据集中工单蒸汽流量数据分析,可知特征点条件变量[R1]为1.2、[R2]为0.05;然后,遍历训练数据集,按照同工艺段、工艺线、产品、工单次序进行分类形成新的类别数据集[Fwm,na];第三,分别遍历每一个[Fwm,na](其中[wm,na]表示m这天第na个工单)中的[wm,na],并根据设定特征点条件对其[ΔT1]和[ΔT2]进行统计并获取特征点出现时对应的时间点,由统计结果分析可知同一个数据集[Fwm,na]中[ΔT1]和[ΔT2]的值基本稳定,故可通过统计结果标准化同工艺段、工艺线、产品、工单次序的工单启动后时间段[ΔT1]与工单结束前时间段[ΔT2];最终把原訓练数据集按同产品、工艺段、工艺线、工单次序划分为稳定生产时间段训练数据集[Pwm,na(m,na=1,2?)]、工单启动后训练数据集[Swm,na(m,na=1,2?)]、工单结束前训练数据集[Ewm,na(m,na=1,2?)]。以制丝A线烘丝段生产利群(新版)数据集[Fwm,1]部分统计结果为例进行统计说明,如表1所示。
2.4 基于稳定生产时段的逐点回归
逐点回归基本思路为:首先,依据已划分的时间点可获取每个预测工单用于逐点回归预测的时间段I,并保存其预测点数量d,其中I可表示为[I(t0,t1,?td)];再者,从统计[Pwm,na]表中可以获取每个训练工单的稳定生产时间段J,根据每个预测工单预测点数量将其对应的训练数据[Pwm,na]中所有训练工单的稳定生产时间段J进行相同数量点d的的时间片切割,并获得对应的蒸汽流量值。至此每个预测工单与其对应的训练数据集中的工单有一致的相对时间点;最后,通过对历史点位数据分析采用适当的预测方法,逐点建立回归模型进行预测。本文分别采用均值拟合与时间序列的方法逐点建立工艺用蒸汽流量的预测模型。
时间点切割思路为:因为每个工单开始稳定生产时间和结束稳定生产时间及生产时长存在差异,所以需对工单进行相对时间切割,让每个工单的点均基于工单稳定开始时间的相对点位,以此消除时间漂移问题。
2.4.1 均值拟合模型
分别对预测时间段I中每一个点位对应的历史流量数据进行可视化分析。以2019年1月7日第一个工单预测时间段I中第一个相对时间点位[t0]对应的训练数据集中相对时间点[t0]的流量值为例,进行可视化分析,时间点[t0]蒸汽流量密度—直方如图3所示。
2.4.2 时间序列模型
时间序列分析是从一段时间上的一组属性值数据中发现模式并预测未来值的过程。ARMA模型(自回归滑动平均模型)是最常见用于拟合平稳序列的模型,本文某一时刻点对应的历史蒸汽流量数据是一组平稳的时间序列,故可用ARMA模型逐点进行建模预测[11]。ARMA模型主要有3种基本形式:自回归模型(AR)、移动平均模型(MA)与混合模型(ARMA)[12]。
对于任一零均值平稳时间序列[{x(m,t)}],若[x(m,t)]的取值不仅与其前p步的各个取值[x(m-1,t)],…,[x(m-p,t)]有关,还与前m步的随机干扰[ε(m-1,t)],…,[ε(m-q,t)](p,q=1,2,…)有关,则可用p阶自回归—p阶滑动平均混合时序模型描述该系统,记为ARMA(p,q),即参数p、q的ARMA模型预测方程[13]为:
利用平均绝对误差度量模型预测误差,通过计算得到平均绝对误差为0.014 59。综上,通过对两种用于工单稳定时段的模型误差对比分析,可知时间序列模型拟合效果优于均值拟合模型,故优先采用时间序列模型对工单稳定时间段进行逐点预测。
2.5 基于不稳定生产时段的曲线补全
工单启动后/结束前时间段由于易受外界人为因素影响,致使生产工艺蒸汽流量时间序列形态较为复杂,故通过一种基于DTW相似度的AP聚类算法获取预测时间段影响,用典型曲线补全该时间段流量曲线[15-17]。
由划分时间点阶段可获得融合后的启动后训练数据集[Swm,na(m,na=1,2,?)]和结束前训练数据集[Ewm,na(m,][na=1,2?)]。曲线补全基本思想包括:首先,依据预测工单信息获取对应的训练数据集;然后,通过计算得到训练样本两两之间的DTW矩阵,将该距离矩阵负值作为相似度矩阵并输入到AP聚类,得到聚类结果;最后从样本数量最多的类别中选择时间点与预测曲线时间点基本吻合的曲线作为典型曲线进行补全[18-19]。
2.6 基于生产计划的滚动预测
滚动预测机制的主要思想是保持数据长度不变,滚动地补充新数据,剔除旧数据,建立这样的序列更能反映预测方法有效性[20]。为得到预测日工艺用流量曲线,当滚动输入预测日工单信息时,需对相应的分割数据集进行不同新数据添加和旧数据剔除。
稳定时间段滚动预测:若当前预测点从[x(m,t)]变为[x(m+1,t)],训练样本序列则由原来的[X(x(m-1,t),][x(m-2,t),?x(m-i+1),x(m-i,t))]变成[X(x(m,t),][x(m-1,t),?x(m-i+2),x(m-i+1,t))],相比原来序列增加了[x(m,t)],去掉了[x(m-i+1,t)],进行逐点回归得到预测值。由此体现出训练样本集[Pwm,na(m,na=1,2,?)]、预测样本与预测结果的动态变化,从而实现稳定时间集流量滚动预测。
工单启动/结束时间段:向相应数据集中添加新数据集,同时将聚类结果中样本数量最少的类别中某个时间序列剔除,从而提高聚类速度,更快获取对应的典型曲线。
3 结果分析
基于式(3)对上述各分割时间集预测结果进行拼接,最终获取预测日完整工艺用流量预测曲线,预测结果如图4、图5所示。
4 结语
本文针对日工艺用蒸汽流量预测问题,提出了一种基于时间集分割的逐点回归—曲线补全的组合预测方法,先利用特征点对时间集进行分割,再根据各时段影响因素采用不同方法进行预测,降低了数据时段性对预测结果的影响。采用基于时间集分割的预测方法可较精准地预测企业工艺用蒸汽流量,为企业蒸汽智能供应策略优化提供一定理论依据。
参考文献:
[1] 邹伯贤, 刘强. 基于ARMA模型的网络流量预测[J]. 计算机研究与发展, 2002, 39(12): 1645-1652.
[2] 刘艳丽,赵卓峰,丁维龙,等. 基于高速收费大数据的短时交通流量预测方法[J]. 计算机与数字工程,2019,47(5):1164-1169+1188.
[3] 吴海姬,王雷,司风琪,等. 基于BP神经网络的主蒸汽流量计算模型[J]. 汽轮机技术,2007(4):269-271+304.
[4] 王雷,张瑞青,肖增弘,等. 基于SVM的主蒸汽流量回归估计[J]. 华东电力,2008,36(12):89-92.
[5] FU Z G, MIN F F, YUAN J. Regression forecast of main steam flow based on mean impact value and support vector regression[C]. 2012 Asia-Pacific Power and Energy Engineering Conference,2012: 1-5.
[6] 张维平,赵文蕾,李国强,等. 基于粗糙集与最小二乘支持向量回归的汽轮机主蒸汽流量预测[J]. 计量学报,2015,36(1):43-47.
[7] GAO J W, LENG Z W, QIN Y,et al. Short-term traffic flow forecasting model based on wavelet neural network[C]. 2013 25th Chinese Control and Decision Conference (CCDC), 2013:5081-5084.
[8] MOUTADID S, ADAMOWSKI J F, TIWARI M K,et al. Coupling the maximum overlap discrete wavelet transform and long short-term memory networks for irrigation flow forecasting[J]. Agricultural Water Management, 2019, 219(219):72-85.
[9] 杨艳林,叶枫,吕鑫,等. 一种基于DTW聚类的水文时间序列相似性挖掘方法[J]. 计算机科学,2016,43(2):245-249.
[10] 崔智泉. 浅谈高斯分布的原理和应用[J]. 中国校外教育,2018(16):63-64.
[11] 李静,黄玲花. 《时间序列分析》课程教学改革探索[J]. 广西师范学院学报(自然科学版), 2017,34(4):147-150.
[12] 黄荣庚,龙静,潘志刚,等. 基于ARMA模型的地铁站环控系统能耗预测[J]. 制冷学报,2019,40(1):88-93.
[13] 谢华为. 基于ARMA平稳时间序列的道路交通事故预测[J]. 宁德师范学院学报(自然科学版),2018,30(3):268-272.
[14] 苏维均,杨飞,崔世杰,等. 造纸企业工艺过程能源消耗预测仿真[J]. 计算机仿真,2016,33(8):438-442+447.
[15] 乔美英,刘宇翔,陶慧. 一种基于信息熵和DTW的多维时间序列相似性度量算法[J]. 中山大学学报(自然科学版),2019,58(2):1-8.
[16] GAO Y Y,JIANG B,ZHU Z W,et al. A fault diagnosis method based on DTW[C]. 2006 Chinese Control Conference,2006:1281-1284.
[17] 郭秀娟,陈莹. AP聚类算法的分析与应用[J]. 吉林建筑大学学报,2013,30(4):58-61.
[18] YIN H, YANG S Q, SHAO D M et al. A novel parallel scheme for fast similarity search in large time series[J]. in?China Communications, 2015,12(2):129-140.
[19] 朱紅,丁世飞,许新征. 基于改进属性约简的细粒度并行AP聚类算法[J]. 计算机研究与发展,2012,49(12):2638-2644.
[20] KUSAKCI A O, AYVAZ B. Electrical energy consumption forecasting for Turkey using grey forecasting technics with rolling mechanism[C]. ?2015 2nd International Conference on Knowledge-Based Engineering and Innovation, 2015:8-13.
(责任编辑:江 艳)
