
基于元路径异构网络嵌入的姓名实体消歧方法
2020-07-14 04:57王建霞张玉璇许云峰
河北科技大学学报 2020年3期
关键词:自然语言处理
王建霞 张玉璇 许云峰


摘 要:为了解决大型学术数据库中重名作者的歧义消解问题,提出了基于元路径异构网络嵌入的姓名实体消歧模型。使用大型在线学术搜索系统DBLP上的公开数据集,首先抽取学术出版物的作者信息、标题和会议期刊名称等特征属性,再利用word2vec模型工具生成的特征属性词嵌入输入到GRU网络中进行训练,构造出一个PHNet矩阵网络进行随机游走操作,从而捕捉不同类型节点之间的关系,最后进行相似节点的划分,完成姓名消歧工作。实验结果显示,新方法的精确度为0.865,召回率为0.792,F1值为0.815。基于元路径的异构网络嵌入模型的精确度、召回率等指标都优于对比模型。因此,所提出的模型在提高大型学术数据库的消歧精准度方面具有良好的应用前景。
关键词:自然语言处理;计算机神经网络;实体消歧;网络嵌入;异构网络
中图分类号:TP311.13 文献标识码:A
doi:10.7535/hbkd.2020yx03005
Disambiguation method of name entities embedded in meta-path
heterogeneous networks
WANG Jianxia, ZHANG Yuxuan, XU Yunfeng
(School of Information Science and Engineering, Hebei University of Science and Technology, Shijiazhuang, Hebei 050018, China)
Abstract:
In order to solve the problem of disambiguation of duplicate authors in large academic databases, a name entity disambiguation model based on meta-path heterogeneous network was proposed. Based on the public data of the large online academic search system DBLP, the author information, title, name of conference journal and other characteristic attributes of academic publications were extracted first. Then the characteristic attribute words generated by the word2vec model tool were embedded into the GRU network for training, so that a PHNet matrix network for random walk operation was constructed to capture the relationship between different types of nodes and finally similar nodes were divided to complete the name disambiguation. The experimental results show that the accuracy of the method is 0.865, the recall rate is 0.792, and the F1 value is 0.815.The meta-path-based heterogeneous network embedding model is superior to the comparison model in terms of accuracy and recall rate. Therefore, the proposed model has a good application prospect in improving the accuracy of disambiguation of large academic databases.
Keywords:natural language processing; computer neural network; entity disambiguation; network embedding heterogeneous network
現今,人们检索学术论文主要依赖学术搜索引擎,如Google Scholar、百度学术、DBLP(DataBase systems and logic programming)等。这些大型学术数据库共同面临的一个具有挑战性的问题是作者姓名的歧义消解,即通过作者的姓名来准确识别现实世界中的人。这一问题的解决对于DBLP这样的大型数据库图书馆尤为重要。DBLP是Schloss Dagstuhl-Leibniz信息学中心和特里尔大学的联合服务机构。Schloss Dagstuhl是一家“gemeinnutzige GmbH”,是被德国法律所允许的一个非盈利慈善组织,是为了增进世界计算机科学界的学术信息交融而成立的。Schloss Dagstuhl主要进行数字方法和论文书目元数据处理等研究。DBLP在处理计算机科学数据的同时,还提供计算机学术论文所涉及到的论文作者的相关属性。除了公共领域所提供的论文数据外,DBLP不会向任意第三方公开论文的私密数据,并且DBLP用户的行为也不会被系统跟踪,与此同时,DBLP不会使用用户的任何数据进行广告宣传。总之,DBLP就是一个仅仅提供计算机学术界科学会议和期刊论文出版记录的大型学术数据库。
本文针对DBLP数据库的重名作者消歧问题进行以下研究。
2.1 论文信息预处理
本文使用的DBLP数据信息包括论文的标题、作者、出版物名称、年份和id编号等信息。由于数据信息中存在噪音数据,所以首先需要进行预处理。预处理过程依次对论文信息进行去噪处理,包括去掉特殊字符串,去掉标点符号及特殊符号,去掉多余空格和换行符,去掉停用词等,然后提取需要的信息归纳到一起。
以歧义人名Bo Liu(见图1)为例,该人名下的出版物论文为124篇,根据论文标题的内容可知,Bo Liu名下有研究神经网络的论文,也有研究基于图挖掘算法等研究方向的论文,再依据organization可粗略看出,有从属于清华大学、北京科技大学和暨南大学等的Bo Liu,甚至很多Bo Liu并未显示其所属研究机构。这样有歧义的人名,本试验一共使用了109个,其中出版物数量最多的是Wen Gao数据集,其包含484条出版记录。
在预处理工作中,将109个XML格式的生数据集处理为5个TXT文件,分别为paper_author.txt,paper_author1.txt,paper_conf.txt,paper_title.txt和paper_word.txt。图2为paper_title.txt部分文本内容,其中包含内容为出版物论文id以及论文标题,其中论文标题经过处理,将其统一使用小写字母表示,并且去掉了标题中的多种符号。对于论文标题的处理有助于后续生成paper_word.txt文档,该文档保留的内容如图3所示,即是论文id以及去掉预设的诸多停止词(例如,at,based,in等)。每一词都另起一行,与论文id成行。另外3个文档内容不再赘述,都是与出版物论文id的结合。
2.2 训练基于GRU的编码器学习深层语义表示
该部分进行的是基于GRU的深度表示学习,应用gensim库中的word2vec模型生成出版物标题的词嵌入,训练单词向量时维数=100。嵌入向量的维数定义batch大小为128,嵌入大小为64,学习率为0.001。
GRU即Gated Recurrent Unit,是LSTM网络的一种的变体。试验发现使用GRU可以使训练成果得到提升。
更新门和重置门是GRU模型中仅有的2个门,具体结构如图4所示。
图4中的更新门用zt表示,重置门用rt表示。其中用于控制之前时刻的状态信息被带入到当前状态中的程度是更新门的任务,这个值越大,代表前一时刻带入的状态信息越多。重置门的作用是调控之前状态有多少信息被写入到当前的候选集t,重置门的值越小,代表之前状态写入的信息越少。
根据图4的GRU模型图,网络的前向传播公式如式(1)—式(3)所示。
rt=σ(Wr·[ht-1,xt]),(1)
zt=σ(Wz·[ht-1,xt]),(2)
t=tanh(W·[rt*ht-1,xt]) 。 (3)
先利用重置门控rt来获得“重置”之后的数据ht-1·rt,再与输入xt进行拼接,之后再经过一个tanh激活函数来处理数据,将其放缩到-1~1的范围内。此时的包含了输入数据xt。式(3)对t的操作与LSTM的选择记忆阶段类似,可以理解为记忆了当前时刻的状态。
在更新记忆阶段,使用了式(2)得到的更新门控zt进行遗忘和记忆2个操作。更新表达式见式(4)。
ht=(1-zt)*ht-1+zt*t。(4)
式中:zt(门控信号)的区域是0~1,若记忆下的数据越多,则门控信号越逼近1,遗忘的数据越多则越逼近0;(1-zt)*ht-1是对原本隐藏状态进行的选择性遗忘;(1-zt)作为遗忘门,用来遗忘ht-1中一些不紧要的内容;zt*t是对包含当前节点信息的t进行选择性“记忆”。
yt=σ(Wo·ht)。 (5)
需要说明的是,[]用来代表有2个向量相连,*是Hadamard Product,代表操作矩阵中对应的元素相乘,此时要求2个相乘矩阵是同型的,+表示矩阵加法操作的进行,σ为sigmoid函数,利用sigmoid函数能够将数据处理为0~1范围内的数值,从而来充当门控信号。激活函数tanh能够帮助调节流经网络的值,而且tanh函数的输出值一直在区间(-1,1)内。
在输出层中,计算loss使用的是softmax的交叉熵(labels和logits)+平均值。
2.3 構造一个PHNet并生成随机游走
使用基于元路径的随机游走操作来捕捉不同节点间的关系,即通过论文标题、论文作者、论文发表期刊,构建PHNet(异构网络)矩阵。本文所构建的异构网络中的节点类型只有论文一种,关系类型为3种(合著作者、共同标题、共同发表期刊)。在一个PHNet中,2个论文节点之间可以通过多个无向关系进行连接,由这些无向关系连接的节点序列可以看作是从论文到论文的表述。受网络嵌入DeepWalk和Metapath2Vec方法的启发,利用随机游走策略和跳跃图模型学习网络节点表示。本文提出了一种元路径和关系权值引导的随机游走策略,用于加权异构网络上的采样路径。
元路径通过异构关系捕获节点间的相关性,在异构网络嵌入中得到了广泛的应用。本文在采样路径上考虑了PHNet中关系的权值,从直观上看,两个节点之间的关系值越大,它们之间的相似性就越大。在每一步游走中,当游走到一个邻居时,连接当前节点到邻居节点的关系值越高,就越有可能对该邻居进行采样。具体来说,本文依次选择PHNet中的一个论文节点作为路径的第一个节点,生成一个长度为100的元路径,然后选择最后一个节点作为另一条元路径的第一个节点。每个随机递归采样网络中的节点,都会生成一条由论文节点引导的长路径,直到满足固定长度,最后生成的结果输入到WMRW.txt文档中,如图5所示。
2.4 基于元路径异构网络嵌入
当前进行网络研究应用较多的是同构网络。若要把基于同构信息网络的方法用在异构信息网络中,需要将异构网络映射为同构网络,或者忽略节点间的连接信息,只是上述这2种方法都将会产生信息丢失的情况。因此,直接在异构信息网络上进行数据挖掘的方法是非常必要的。由于在异构信息网络中节点的连接是通过不同的语义意义,从而提出最好充分利用异构信息网络的网络模式期盼。网络模式即是了解信息网络的元结构,能够对网络的检索和数据挖掘进行指导,对于分析和理解网络中对象和关系的语义意义大有帮助。简单而言,就是一种基于元路径的方法。元路径就是在网络模式上加以定义的路径,代表了在2个对象类型之间的关系,同时能够定义实体之间新的或现存的关系。
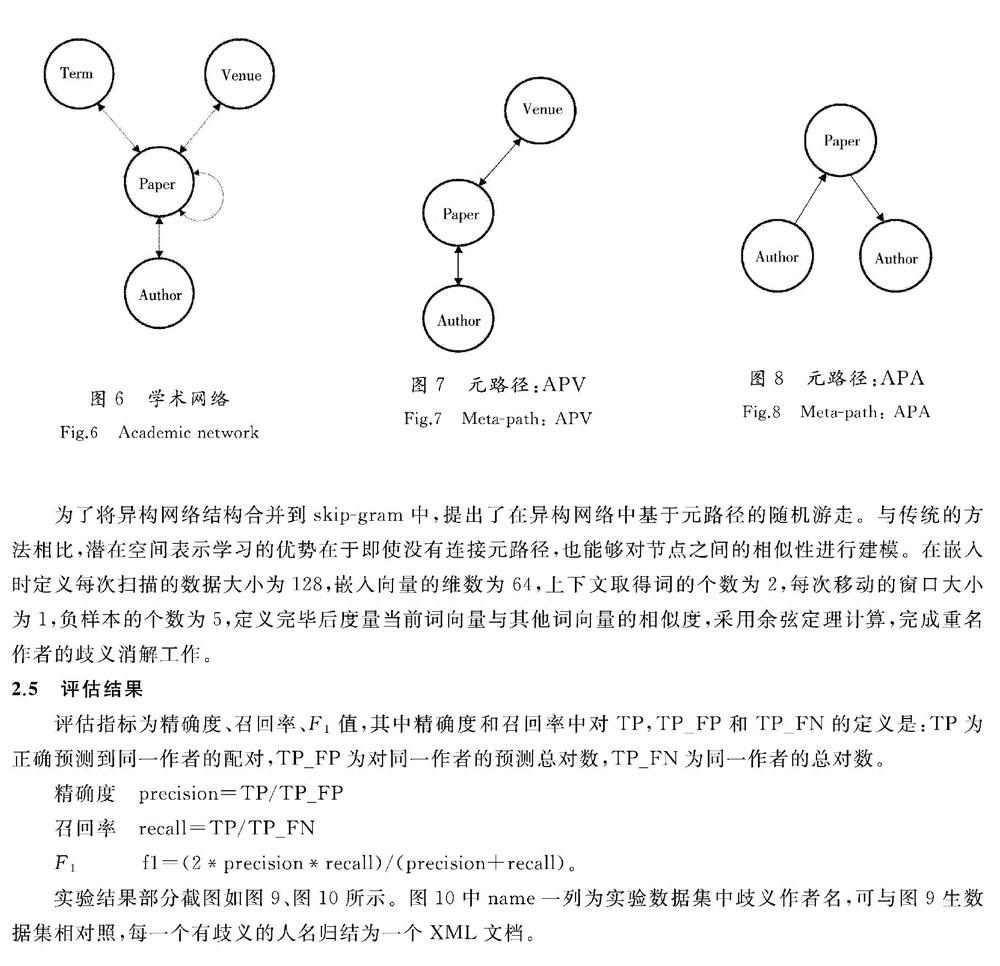
现实世界中普遍存在着异构信息网络,本文选用的DBLP数据集是非常经典的异构网络,包含了4类实体:Paper,Venue,Author,Term。对于每篇论文,它都有一组4类实体的连接。此网络也包含了一些论文的信息,即论文之间有论文引用的论文集合。图6—图8为学术网络与元路径示意图。
为了将异构网络结构合并到skip-gram中,提出了在异构网络中基于元路径的随机游走。与传统的方法相比,潜在空间表示学习的优势在于即使没有连接元路径,也能够对节点之间的相似性进行建模。在嵌入时定义每次扫描的数据大小为128,嵌入向量的维数为64,上下文取得词的个数为2,每次移动的窗口大小为1,负样本的个数为5,定义完毕后度量当前词向量与其他词向量的相似度,采用余弦定理计算,完成重名作者的歧义消解工作。
2.5 评估结果
评估指标为精确度、召回率、F1值,其中精确度和召回率中对TP,TP_FP和TP_FN的定义是:TP为正确预测到同一作者的配对,TP_FP为对同一作者的预测总对数,TP_FN为同一作者的总对数。
精确度 precision=TP/TP_FP
召回率 recall=TP/TP_FN
F1 f1=(2*precision*recall)/(precision+recall)。
实验结果部分截图如图9、图10所示。图10中name一列为实验数据集中歧义作者名,可与图9生数据集相对照,每一个有歧义的人名归结为一个XML文档。
3 实验结果分析
本文使用DBLP数据集进行实验,有歧义的人名为101个,论文出版物有7 585篇,其中包含的節点特征有作者id,作者名以及出版物的详细信息。详细信息包含:论文标题、出版年份、作者(论文所有的作者)、出版期刊、出版物id、作者所属单位。因较多人的所属单位信息为空白,所以该特征属性在本次消歧任务中不作为侧重点。本次实验整理数据侧重于利用论文标题、作者集合、出版物期刊名称、出版年份和id编号等特征属性进行消歧操作。
为了验证本文所提出方法的消歧性能,将其与另外4种方法进行比较,这4种方法包括:DeepWalk,LINE,Node2Vec和PTE,都是目前最先进的顶点嵌入方法。为了公平起见,所有这些方法都使用相同的数据来实现姓名消歧。
DeepWalk:DeepWalk是近期所提出的一种网络嵌入方法。在给定论文合作关系的情况下用来捕获与关联文档集合中的一对人员之间的协作,并采用均匀随机游走的方法来获取其邻域的上下文信息进行文档嵌入。
LINE:LINE不再采用随机游走的方法,它在图上定义一阶相似度和二阶相似度,对节点的信息进行了补充,从而得到更丰富的节点嵌入。
Node2Vec:和DeepWalk近似,Node2Vec为实现文档嵌入设计了一个有偏差的随机游走过程。
PTE:预测性文本嵌入框架的目标是捕获词-词、词-文档和词标签之间的关系。可是,该种方式不能捕捉文档间的连接信息。
表1显示了本论文所提出的方法与对比方法在处理多个不同人名姓名歧义消除方面的性能(表1用于DBLP数据集)。在表1中,列1为需要消歧的作者姓名,第3列—第6列为各种方法的F1值。F1值表示各种方法给定姓名数据集下的消歧性能。最后一列显示了本文所提出的方法相较于对比方法的改进水平。
表1表明,本文方法相较于对比方法的总体改进比较大。PTE的表现很差,因为它没有将相关的结构信息整合到实验中。DeepWalk的方法忽略了边缘权值,这一点恰恰在异构学术网络中是非常重要的。这几种基于嵌入的对比方法都不能利用多个网络信息来处理消歧任务,本论文的模型利用了这一点,提出了基于元路径异构网络嵌入实现姓名消歧的方法,这可能是该方法优于现有的基于网络嵌入方法的一个重要原因。
4 结 语
笔者提出了一个有效解决作者姓名消歧问题的框架。该框架对DBLP数据集中有待消解歧义的作者姓名的数据集进行了预处理操作,利用word2vec模型进行嵌入,再输入到GRU网络中进行训练,根据节点间的关系构造了PHNET网络,最后基于元路径异构网络嵌入实现姓名消歧。该方法所提出的表示学习方案比其他现有的网络嵌入方法能更有效地将属于同名作者的文档进行消歧处理。实验结果验证了该方法的可行性和有效性。
本研究虽实现了预期目标,但是在组合不同类型的特征属性(如利用文本信息的语义信息和离散特征)来学习有待消歧作者论文的有效表示方面仍有进步空间。在未来的工作中,将尝试把此方法应用于分布式计算系统,进一步提高大型学术数据库的消歧速度和效果。
参考文献/References:
[1] DENG H, KING I, LYU M R. Formal models for expert finding on DBLP bibliography data[C]//Eighth IEEE International Conference on Data Mining. [S.l.]: [s.n.], 2008: 163-172.
[2] HUANG Zhixing, YAN Yan, QIU Yuhui, et al. Exploring emergent semantic communities from DBLP bibliography database[C]//International Conference on Advances in Social Network Analysis and Mining. [S.l.]: [s.n.], 2009: 219-224.
[3] FRANCESCHET M. Collaboration in computer science: A network science approach[J]. Journal of the American Society for Information Science and Technology, 2011, 62(10): 1992-2012.
[4] KIM J, KIM H, DIESNER J. The impact of name ambiguity on properties of coauthorship networks[J]. Journal of Information Science Theory and Practice, 2014, 2(2): 6-15.
[5] CAVERO J M, VELA B, CACERES P. Computer science research: More production, less productivity[J]. Scientometrics, 2014, 98(3): 2103-2111.
[6] SHI Quan, XU Bo, XU Xiaomin, et al. Diversity of social ties in scientific collaboration networks[J]. Physica A: Statistical Mechanics and Its Applications, 2011, 390(23/24): 4627-4635.
[7] REITZ F, HOFFMANN O. Learning from the past: An analysis of person name corrections in the DBLP collection and social network properties of affected entities[J]. Social Network Analysis and Mining, 2013,6: 427-453.
[8] 余傳明,林奥琛,钟韵辞,等.基于网络表示学习的科研合作推荐研究[J]. 情报学报,2019,38(5):500-511.
YU Chuanming, LIN Aochen, ZHONG Yunci, et al. Research of author name disambiguation based on network embedding[J]. Journal of the China Society for Scientific and Technical Information, 2019, 38(5): 500-511.
[9] GARFIELD E. British quest for uniqueness versus American egocentrism[J]. Nature, 1969, 223(5207): 763-763.
[10]LEY M. DBLP: Some lessons learned[J]. Proceedings of the VLDB Endowment, 2009, 2(2): 1493-1500.
[11]KIM J. Evaluating author name disambiguation for digital libraries: A case of DBLP[J]. Scientometrics, 2018, 116(3): 1867-1886.
[12]HAZIMEH H, YOUNESS I, MAKKI J, et al. Leveraging co-authorship and biographical information for author ambiguity resolution in DBLP[C]/Advanced Information Networking and Applications (AINA). [S.l.]: [s.n.], 2016: 1080-1084.
[13]HAN H, GILES L, ZHA H, et al. Two supervised learning approaches for name disambiguation in author citations[C]//Proceedings of the 2004 Joint ACM/IEEE Conference on Digital Libraries. [S.l.]: [s.n.], 2004: 296-305.
[14]GILES C L, ZHA H, HAN H. Name disambiguation in author citations using a K-way spectral clustering method[C]//Proceedings of the 5th ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL'05). [S.l.]:[s.n.], 2005: 334-343.
[15]MALIN B. Unsupervised name disambiguation via social network similarity[C]//Workshop on Link Analysis, Counterterrorism, and Security[S.l.]: [s.n.], 2005:93-102.
[16]ZHANG Baichuan, AL-HASAN M. Name disambiguation in anonymized graphs using network embedding[C]//Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. [S.l.]:[s.n.], 2017: 1239-1248.
[17]PERZZI B, AL-RFOU R, SKIENA S. Deepwalk: Online learning of social representations[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. [S.l.]:[s.n.], 2014: 701-710.
[18]TANG Jian, QU Meng, WANG Mingzhe, et al. Line: Large-scale information network embedding[C]//Proceedings of the 24th International Conference on World Wide Web. [S.l.]: International World Wide Web Conferences Steering Committee, 2015: 1067-1077.
[19]TANG Jian, QU Meng, MEI Qiaozhu. PTE: Predictive text embedding through large-scale heterogeneous text networks[C]//Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. [S.l.]:[s.n.], 2015: 1165-1174.
[20]GROVER A, LESKOVEC J. Node2vec: Scalable feature learning for networks[J]. Knowledge Discovery and Data Mining, 2016: 855-864.
[21]PHAM T H, PHAM X K, NGUYEN T A, et al. NNVLP: A neural network-based Vietnamese language processing toolkit[C]//International Joint Conference on Natural Language Processing. [S.l.]:[s.n.], 2017: 37-40.
[22]WU Fangzhao, LIU Junxin, WU Chuhan, et al. Neural Chinese named entity recognition via CNN-LSTM-CRF and joint training with word segmentation[J]. The World Wide Web Conference, 2019: 3342-3348.
[23]甄然,于佳興,赵国花,等.基于卷积神经网络的无人机识别方法仿真研究[J]. 河北科技大学学报, 2019, 40(5): 397-403.
ZHEN Ran, YU Jiaxing, ZHAO Guohua, et al. Simulation research on UAV recognition method based on convolutional neural network[J]. Journal of Hebei University of Science and Technology, 2019, 40(5): 397-403.
[24]纪志强,魏明,吴启蒙,等.基于递归神经网络的TVS电磁脉冲响应建模[J]. 河北科技大学学报, 2015, 36(2): 157-162.
JI Zhiqiang, WEI Ming, WU Qimeng, et al. EMP response modeling of TVS based on the recurrent neural network[J]. Journal of Hebei University of Science and Technology, 2015,36(2): 157-162.
收稿日期:2020-03-25;修回日期:2020-05-25;责任编辑:冯 民
基金项目:中国留学基金委地方合作项目(201808130283);中国教育部人工智能协同育人项目(201801003011);河北科技大学校立课题(82/1182108);河北科技大学雾霾与空气污染防治科研项目(82/1182169);河北省科技支撑计划项目(17210104D, 18210109D);河北省高等学校科学技术研究项目(ZD2015099);河北省高层次人才资助项目(A2016002015)
第一作者简介:王建霞(1970—),女,河北临城人,教授,硕士,主要从事网络与数据库、图像处理方面的研究。
通讯作者:许云峰副教授。E-mail:hbkd_xyf@hebust.edu.cn
王建霞,张玉璇,许云峰.
基于元路径异构网络嵌入的姓名实体消歧方法
[J].河北科技大学学报,2020,41(3):233-241.
WANG Jianxia, ZHANG Yuxuan, XU Yunfeng.
Disambiguation method of name entities embedded in meta-path heterogeneous networks
[J].Journal of Hebei University of Science and Technology,2020,41(3):233-241.
猜你喜欢
计算技术与自动化(2017年3期)2017-10-26
魅力中国(2017年24期)2017-09-15
中国市场(2016年39期)2017-05-26
电子技术与软件工程(2016年24期)2017-02-23
计算机应用(2016年12期)2017-01-13
电脑知识与技术(2016年10期)2016-06-16
求知导刊(2016年10期)2016-05-01
电脑知识与技术(2016年5期)2016-04-14
科技视界(2016年5期)2016-02-22
