
一种结合深度特征的人体运动序列追踪模型
2020-07-14 00:27蒋宇袁健
软件导刊 2020年1期
关键词:卷积神经网络
蒋宇 袁健

摘 要:目前主流的判别式目标跟踪模型大多使用灰度、颜色等手工特征,在目标快速移动或受到视频序列背景等因素干扰情况下,目标跟踪器可能在跟踪目标时学习到错误特征而导致跟踪失败。因此,提出一种结合深度特征的相关滤波跟踪算法。首先将待跟踪目标图像输入至卷积神经网络中,提取出较高层的卷积特征,然后将提取的卷积特征输入相关滤波器中得到响应,最后根据响应峰值得到追踪结果。以VOT2016中包含人体运动的视频序列为实验数据集,并分别与CN、SAMF及KPDCF模型进行对比。实验结果表明,结合深度特征的相关滤波算法具有较好的追踪性能,在不大幅降低追踪速度的情况下,提升了追踪精度和稳定性。
关键词:手工特征;相关滤波器;深度特征;目标追踪;卷积神经网络;人体运动序列
DOI: 10. 11907/rjdk.191379
开放科学(资源服务)标识码(OSID):
中圖分类号:TP303
文献标识码:A
文章编号:1672-7800(2020)001-0089-06
0 引言
在人体运动序列中,需要追踪的目标通常有着较大形变,且视频序列背景可能有较多变化,所以在单目标跟踪过程中需要选取出比较有区分度,且有着较低计算量的特征,才能更好地满足单目标追踪的实时性与高精度要求。如今,由于单目标跟踪对实时性的要求越来越高,因此相关滤波算法在该领域十分流行,但是滤波跟踪是基于先验训练模板的,一旦出现追踪目标本身形变较大,或因运动过快而发生变形的情况,相关滤波算法产生的训练模板很可能在后续的帧序列中匹配不一致,从而导致追踪目标丢失或追踪错误的情况。随着机器学习技术的迅速发展,深度卷积神经网络在视觉追踪领域的应用也越来越广。一般而言,构建的卷积神经网络层数越多,提取的高层特征将包含更多语义信息以及定位目标的结构化信息,卷积神经网络的应用效果也会越显著。例如2014年提出的G oogLeNet与2015年提出的ResNet,这些深层次网络采用大量图片数据集进行训练,被成功应用于图像处理各相关领域。但是卷积神经网络需要进行大量计算,直接使用卷积神经网络进行分类追踪,难以实现目标实时追踪。因此,本文结合卷积神经网络的抽象特征与相关滤波跟踪算法,提出一种基于深度卷积特征的相关滤波跟踪模型。实验结果表明,该模型应用于人体运动序列追踪速度较快,且有着较高精度。
目标追踪是计算机图像处理领域一个非常重要的研究方向,有着十分广泛的应用场景。早期研究基本上都在欧美等发达国家,比如早在1980年代,Horn等[1]提出将光流法用于对计算机视频中目标的追踪与识别。光流计算实际上是一种通过检测图像像素点强度随时间的变化情况,进而推断出物体移动速度及方向的方法,如2001年Sidenbladh[2]通过光流信息表征运动特征,G onzalez[3]使用KLT特征,Btadski&Davisa1[4]采用运动梯度信息对运动特征进行表述。但这些基于光流法的研究缺陷在于当个体被遮挡时,提取运动信息会变得极其困难且误差较大,追踪精度也很低。因此,传统光流计算在目标运动边界被遮挡、背景干扰强的情况下,远远达不到对于目标追踪精度和速度的要求。之后,出现了粒子滤波算法[5]与一些基于卡尔曼滤波[6]及其相关改进方法。随着计算机技术的飞速发展,针对目标追踪的研究逐渐演变为一个计算机视觉的目标识别检测问题。2010年,Bolme等[7]第一次将相关滤波应用于目标追踪领域,并构建了一个自适应的相关滤波器,称为MOSSE滤波器。MOSSE滤波器对视频第一帧中的追踪目标建模,然后对视频序列的每一帧,利用提取到的目标特征检测帧图像,以最小输出平方误差作为新的目标位置,并且不断调整建模目标。MOSSE滤波器可通过快速傅立叶变换使大量计算转换到频域,从而加快追踪速度;Henriques等[8]随后提出一种基于核函数映射的相关滤波器,该滤波器将待追踪目标的外观通过核函数映射至特征空间,然后通过最小二乘作分类,从而提升了追踪精度。但是该核相关滤波器只提取了目标灰度特征,也存在着追踪丢失的可能性。
随着人工智能技术的不断发展,卷积神经网络开始被应用于图像处理领域,并在计算机视觉方面取得了很好的效果,在目标追踪领域更是有着突破性进展。如Wang等[9]首次将卷积神经网络运用于目标追踪领域,利用预训练的神经网络挖掘目标深度特征,然后通过在追踪时不断调整神经网络实现对目标的追踪。神经网络解决了追踪时训练样本规模较小的问题,但在追踪速度上低于基于相关滤波器的追踪算法。然而,将神经网络应用于目标追踪领域,并在追踪时不断调整网络的思想为后续深度学习在目标追踪方面的应用打下了基础。
2015年左右,深度学习在目标追踪领域得到了大量应用。如Nam等[10]提出一种多域网络,该模型基于预训练的卷积神经网络(CNN),使用大量视频预先跟踪CNN,并跟踪视频实况获得通用目标表示。神经网络由共享层与域特定层的多个分支组成,其中域对应于各个训练序列,并且每个分支负责二进制分类以识别每个域中的目标。然后,迭代地针对每个域训练网络,以获得共享层中的通用目标表示。当在新序列中跟踪目标时,将预训练CNN中的共享层与新的二进制分类层(在线更新)组合构建新网络;M artin等[11-12]提出将SRDCF用于目标追踪领域,使用循环矩阵解决了计算损失函数时的边界效应问题,通过引入惩罚因子提高追踪精度,但速度相比传统相关滤波模型大幅降低,之后又提出一种改进的D-SRDCF模型,通过结合手工特征与CN特征,进一步提高了精度,但是速度又进一步降低。这些研究大都将目光聚焦在经过大数据集预训练后的卷积神经网络,但神经网络存在计算耗时较长的问题,因而目标追踪速度无法得到保证。
国内也在很早前就开始了目标跟踪相关领域研究,早在1986年,我国就有部分学者对计算机视觉追踪技术进行研究,并取得了一定成果,如徐博文等[13]提出的结合关键点跟踪的尺度自适应相关滤波模型,候建华等[14]提出的基于在线学习判别性外观模型的多目标跟踪模型等。
综上所述,基于相关滤波的目标追踪通常在实时性方面表现出明显的优越性,而基于深度学习的模型通常在准确性方面有着较好表现。本文根据目标追踪领域发展趋势,结合相关滤波算法与深度学习理论,基于预训练卷积神经网络提出一种结合深度特征的相关滤波追踪算法模型,并将其应用于人体运动序列追踪中。
1 相关滤波目标跟踪模型
相关性是指两个信号之间的关系,有互相关与自相关两种,相关滤波便是建立在此基础之上。对于给定的两个离散信号Sigl和Sig2,其相关性可以描述为式(1)。
其中的*表示信号的共轭,其中m和n表示位移变量。相关性即相似程度,如果信号之间的相似程度高,则其相关性也高。所以在基于相关滤波的目标追踪中,主要是提取追踪目标在候选区域的特征,并将其与计算生成的滤波器作相关操作,得到相关滤波响应峰图(空域置信图)。响应峰图中峰值坐标就是追踪目标在图像中的位置坐标,下面将详细推导该过程。令一个数字图像f和一个滤波器h进行相关操作后,得到输出g,如式(2)所示。
g=f〇h
(2)
式(2)表明,得到的滤波响应值受到h(濾波器模板)的影响,因此目标追踪问题就变为寻找滤波器模板的问题。式(2)中的〇表示卷积操作,卷积操作计算量较大,因此相关滤波跟踪算法中通常将卷积操作通过快速傅立叶变换转换到频域中进行,从而减少计算量,提高追踪效率。若将快速傅立叶变换表示为F,则式(2)可以表示为式(3)。
F(g)=F(f〇h)=F(h)。F(h)*(3)
G =F。H*
(4) 式(4)为式(3)的简化表达,由此,相关滤波的目标追琮问题可以表示为对滤波器H*的求解,如式(5)所示。
H*=G/F/
(5) 若追踪的目标在追踪过程中发生形变或遮挡变化,此时就需要H*适应场景变化。因此,相关滤波算法通常都会选择最近的n个样本更新H*,并在追踪过程中不断求解并更新H*,如式(6)所示。
其中i表示第i个输入样例。将滤波器H*与追踪目标特征集合进行相关计算,可以得到滤波响应峰图,取峰图中的峰值作为追踪目标位置。因此,追踪目标特征提取是相关滤波算法中很重要的组成部分,特征提取质量将直接关系到追踪效果。相关滤波追踪模型如图1所示。
2 结合深度特征的相关滤波目标跟踪算法
2.1 预训练卷积神经网络
目前有一些开源的已经过预训练的图像分类网络,本部分算法模型将基于这些预训练网络提取深度特征,并将从这些网络中提取的深度特征应用于相关滤波器,用于对目标进行追踪。VGG[15]卷积神经网络(简称为VCGNet)是Visual Geometry Group实验室基于大规模分类数据库Ima-geNet[16]训练出来的卷积神经网络模型。ImageNet是一个图片数据库,所有图片已通过人工手动标注好类别,共有22 000个类别,是目前世界上最大的图像识别数据库。经过该数据库训练出的VGGNet网络模型对除此之外的其它数据集具有很强的泛化能力。另外,VGCNet网络模型还具有较强的迁移能力。
VCCNet模型结构十分简洁,在目标追踪领域大部分采用16或19层网络结构(分别称为VGC16和VCG19)。本文选择19层网络结构作为实验的卷积神经网络,包括16个卷积层与3个全连接层。前几层采用3x3结构的卷积核作卷积操作,每个卷积层后面均有一个激活层。后几层为池化层,池化层的卷积核为2x2。网络最后有3个全连接层和一个soft- max层。
2.2 深度特征结合相关滤波器
上文讨论了使用相关滤波解决目标追踪问题,并将目标追踪问题转换成求解滤波器H*的问题。然而,在实际计算中,计算机都是针对图像中每个像素点进行操作的,所以式(6)可以具体表示为式(7)。
其中u、v是单个像素元素对应矩阵H中的下标。要想使差平方和最小,此时只需对每个元素求得的偏导值为0即可,如式(8)所示。
在视频序列开始时,通过手工对视频第一帧中已标注好的目标位置进行特征提取,计算初始化相关滤波器模板。在具体实现时,对视频序列的第一帧图像进行随机放射变换,产生n个训练样本,将样本进行高斯函数输出得到响应峰图,响应峰图中的峰值则是追踪目标的中心位置,便可求得该相关滤波器模板。为了提高该相关滤波器的鲁棒性,使其能够应对复杂场景,如光照急剧变化或相似背景干扰等,对相关滤波器模板采用如下更新机制,如式(11)-(13)所示。
其中的Ai、Bi是由当前视频帧计算得出的,而Ai-1、Bi-1,是由上一视频帧计算得出的,η表示该相关滤波模板学习率。因此,之前视频帧与当前视频帧都会对滤波器模板训练产生影响,但是当前帧的影响更大。
相关滤波算法将用于本章提出的模型在线学习部分中,下面说明如何使用滤波器进行追踪。基本思路为:由初始给定的追踪目标外观,学习生成一个判别相关滤波器(简称DCF),在追踪目标的待检测图片中,DCF会对其中的追踪目标输出相关响应峰值,由此实现对追踪目标在待检测图片中的定位。相关滤波运算可以在频域通过快速傅立叶变换实现,因此相关滤波有着较高的实时性。
首先,在视频序列的初始帧中指定追踪目标位置信息,然后根据指定的追踪目标图像提取追踪目标特征集合,训练得出DCF,在视频序列的后续每帧图像中,从前一帧由相关滤波输出的追踪目标位置中提取追踪目标图像特征,实现相关滤波的更新。以第t帧为例:①此时已知t-l帧时追踪目标的位置信息D,在第t帧中提取出位置D的图像;②对得到的图像进行特征提取,作相关滤波运算,得到相关滤波响应峰图(空域置信图);③响应峰图中的峰值位置即是第t帧中追踪目标的位置;④将得到的第t帧追踪目标位置作为第t帧的输出,再依据位置信息更新相关滤波器。
下面构建基于深度特征的相关滤波实时追踪模型(Deep Feature DCF,以下简称DFDCF)。模型主要流程如下:
首先,确定序列首帧中手工标注好的追踪目标区域,将该区域图像输入VCG19网络(已预训练好的卷积神经网络)中,提取出卷积层中第16层特征,根据式(10)计算出相应滤波模板;然后,对序列中的每一帧后续图像,采用式(11)提出的更新规则更新滤波模板,由上一视频帧的输出结果(第一帧输出结果即为手工标注结果)确定当前帧的位置提取信息,将当前帧提取的图像再次输入至VCG19网络中。由于高层卷积特征有着追踪目标的语义信息,所以选取( conv16)卷积层特征作为当前特征,与新滤波模板作用得出滤波响应;最终,将响应峰值作为当前追踪结果。模型流程如图2所示。
3 实验与分析
3.1 数据集与实验环境
VOT( Visual Object Tracking)[17]是一个针对单目标跟踪的测试数据集,从2013年发展至今,已成为单目标跟踪领域主流的3大平台之一。作为一个测试数据集,VOT有着十分丰富的测试数据,本文只选取其中的人体运动视频序列作为实验数据,包括singerl、singer2、godfather等共24个视频序列。
本实验中利用已训练好的VCC19提取目标区域特征,具体采用19层网络中的第16层卷积特征,其中式(12)与式(13)中的学习率η值为0.02。从追踪的实验数据集VOT2017中筛选出人体运动序列数据集,其中的初始帧目标位置已知。
3.2 评估指标
为了验证本文跟踪算法的性能,结合VOT以及传统追踪指标,使用如下评价指标作为本文算法模型评价指标:
(1)每秒传输帧数(Frames Per Second,FPS)。定义为跟踪视频总耗时T与视频总帧数F的商值,如式(14)所示。
FPS=T/F
(14)
(2)精确度(Accuracy)[18]。用来评价追踪算法追踪目标的准确度,数值越大,准确度越高。其借用了IoU( Inter-section-over-Union,交并比)定义,某人体运动序列第t帧的准确率定义如式(15)所示。
3.3 结果对比分析
本文实验采用文献[13]中提出的结合关键点的跟踪算法(简称KPDCF)、CN[19]、SAMF[20]进行实验结果对比。实验图集如图3所示。
由图3可以看出,不同算法模型在视频序列每一帧的追踪结果都不相同,但是VOT数据集中标注的真实目标位置只有一个,因此不同算法的准确率也不同。当然,不同模型的跟踪速度也不同,图4展示了KPDCF、CN、SAMF與本文提出模型在速度上的对比实验结果。
由图4可以看出,最为简单的CN模型跟踪速度最快,达到了90fps多,但这是在牺牲追踪精度的情况下达到的,本文提出的DFDCF模型跟踪速度排名第二。KPDCF由于考虑了多尺度自适应问题,提高了算法的时间复杂度,因此速度较慢,而SAMF模型在跟踪速度方面表现最差。
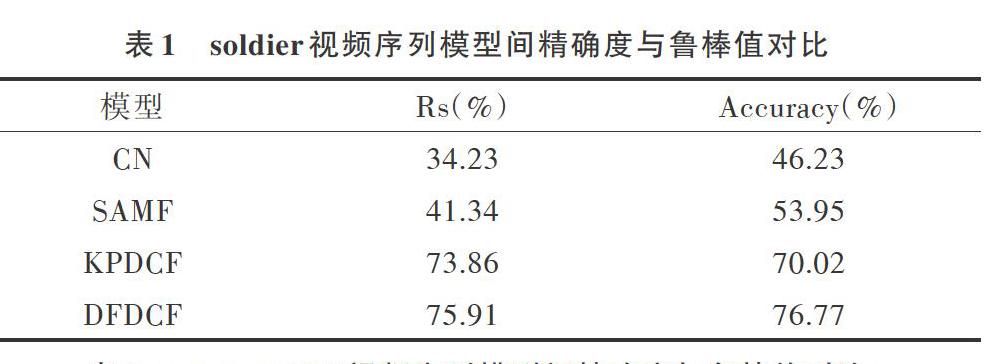
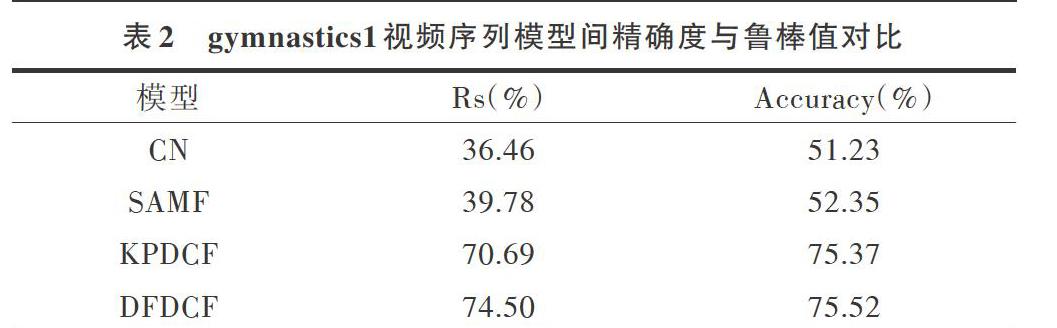
图5展示了在singerl视频序列下4个模型的精确度与鲁棒值对比,在singerl视频序列中,光线变化较为强烈,背景干扰性强。可以看到,在20次实验中,本文提出的DFD-CF不论是平均准确度还是平均Rs值,在4个算法中都是最高的,虽然与KPDCF的性能差距不大,但在以上的FPS结果对比中,DFDCF相比KPDCF领先了约20fps。CN模型虽然在FPS对比中大幅领先,但其追踪精度和鲁棒值都远达不到要求。事实上,在针对其它人体运动视频序列的实验结果中,DFDCF的平均精度与鲁棒值都有着较好表现,具体数据如表1一表3所示。
4 结语
本文研究了人体运动序列的目标追踪问题,首先介绍了传统基于相关滤波的目标追踪算法,指出其手工特征选择部分在追踪目标形变较大或受到外界环境因素干扰情况下,可能导致追踪目标失败,然后提出一种结合深度特征的相关滤波追踪模型,使用预训练的卷积神经网络获取目标特征,并将得到的深度卷积特征用作相关滤波器的特征提取部分,相关滤波器则作为运动序列的在线目标追踪部分。实验结果表明,本文提出的基于深度特征的相关滤波追踪模型在人体运动序列追踪领域有着良好性能,在与其它模型对比时,在每秒传输帧数、准确率和鲁棒值方面都表现较好。然而,现有目标追踪算法在追踪速度与追踪准确率方面很难做到两者兼顾,后续研究将聚焦如何在不大幅降低追踪准确率的情况下,进一步提高追踪速度。
参考文献
[1]HORN B K P, SCHUNCK B G. Determining optical flow[J]. ArtificialIntelligence, 1981 , 17( 1-3) : 185-204.
[2]BOBICK A F, DAVIS J W. The recognition of human movement usingtemporal templates [J]. Pattern Analysis & Machine IntelligenceIEEE Transactions on , 2001 .23( 3) : 257-267.
[3]COMANICIU D. RAMESH V, MEER P. Kernel-based object track-ing [J]. Pattern Analysis & Machine Intelligence, 2003, 25 (5) :564-575.
[4] ZHAO T, NEVATIA R. Tracking multiple humans in crowded envi-ronment [ C ]. Proceedings of the 2004 IEEE Computer Society Confer-ence on Computer Vision and Pattern Recognition, 2004.
猜你喜欢
科技创新与应用(2017年5期)2017-03-16
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
