
基于数字图书馆公共资源管理平台的实时日志分析系统的设计与应用*
2020-07-15 06:52莫恭钿
广西民族大学学报(自然科学版) 2020年1期
莫恭钿,韦 端
(广西交通职业技术学院,广西 南宁 530023)
0 引言
当前,数字图书馆作为一种全面、高效、便捷的公共资源管理平台正在得到广泛的应用.通过使用Java与Nginx服务器的网站技术,开发出符合高职院校业务需求的数字图书馆公共资源管理平台,可以为高职院校专业建设、课程开发、师资队伍培养、教改和科研等工作提供高效率、深层次、多元化信息服务能力.但是,随着网络用户访问流量的不断增大,让数字图书馆公共资源管理平台面临着巨大的网络安全风险.
在网络日志处理流程中,主要有两类网络日志处理方式,[1]一种是日志数据离线处理,另一种是日志数据实时流处理.网络本数字图书馆公共资源管理平台,将使用实时日志数据处理.通过使用 Nginx、Flume、Kafka和Spark Streaming的组合技术进行日志分析方案设计,[2]让本系统具有实时性、功能针对性强、操作简便等特点.
1 需求分析
1.1 日志文件分析
数字图书馆公共资源管理平台所产生的web日志信息主要包含表1内容.
通过表1数据字段的信息,主要进行如下3个方面分析:
(1)网站平台流量分析.重点在于分析不同的网络用户在一段时间内使用数字图书馆公共资源管理平台的流量变化趋势情况.主要指标是总页面访问量和各网络用户的页面访问量.
(2)用户来源分析.统计分析通过各种搜索引擎工具、网站外部链接来源以及其他等方式进入本网站平台的情况.通过用户来源分析结果可以及时提醒数字图书馆公共资源管理平台相关管理人员,哪种类型的来源为其带来了更多用户访问,以及为网站溯源调查提供便利.
(3)用户所访问网页分析.统计分析每个用户访问数字图书馆公共资源管理平台页面的相关操作,分析内容包括统计分析页面对访问者吸引力程度,用户对网页有哪些潜在安全、违规操作,以便帮助平台管理员更有针对性的提高平台的安全性和可靠性.

表1 web日志主要信息Tab.1 main information of Web log
1.2 技术分析
Nginx:主要考虑数字图书馆公共资源管理平台是运行在多个linux系统的Nginx服务器上,平台运行使用所产生的日志文件就是Nginx原始日志文件,并且Nginx可以提供负载均衡等技术功能,提高了实时日志系统资源的利用率.
Flume:可以实现可靠的、分布式的实时日志采集和传输能力,便于日志数据的收集,适用于作为数字图书馆公共资源管理平台Nginx日志文件收集.
Kafka:主要用于快速并行机制加载实时的日志数据,[3]作为集群功能为后续的Spark Streaming提供数据分析.
Spark Streaming:可以实现实时流数据处理能力,并且具有强大的容错机制.可以将Kafka的实时日志流数据,根据某些时间设定和数据格式要求,通过程序处理,得到最终实时日志分析结果.
同时,本人以及所在单位的工作团队具有较高的软件开发能力以及工作经验,为本系统的顺利研究和开发提供了重要的技术保障.[4]
2 系统设计分析
2.1 系统总体设计分析
实时日志分析系统应具有对网站平台流量分析、用户来源分析以及所访问网页分析三大功能机构,如图1所示.
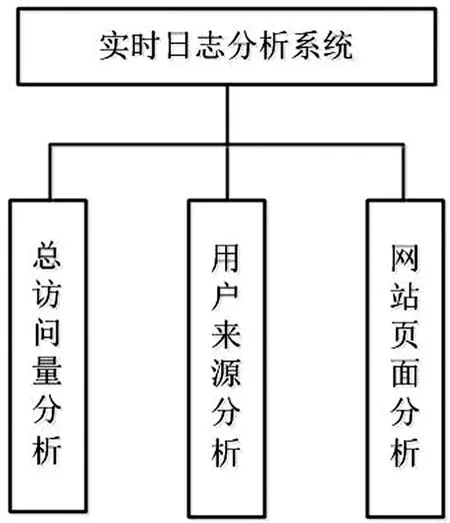
图1 系统总体结构图Fig.1 overall structure of the system
2.2 数据库表结构设计分析
数据库的功能是主要用来存放日志分析的最终结果,[5]以便于数据的保存以及为最后图形化显示提供数据来源.本系统涉及网站平台流量分析、用户来源分析以及所访问网页分析三大功能机构.因此,可以制定网站平台流量表、用户来源表以及所访问网页表三张表进行分析后数据的保存.
2.3 工具类设计分析
工具类的功能作用主要包含了实体类的封装,便于可视化界面的数据呈现.以及对数据库的操作、数据格式的转换、实时日志文件的数据清洗.
2.4 实时日志分析对比离线日志分析
离线日志分析,对日志信息的监控、告警、实时分析能力较弱.较为流行的离线日志分析系统采用Flume、HDFS和Spark SQL相结合的技术方案.离线日志分析系统侧重于在离线阶段完成数据分析过程,因此得到的数据分析结果相对来说是较为滞后的,无法将分析结果及时反映,而实时日志分析则填补了这一部分的空白.通过采用Nginx、Flume、Kafka、Spark Streaming的组合技术建立实时日志分析系统,可以利用Nginx的高并发、低内存消耗、配置简单,flume可以提供分布式、高效率的网站日志信息收集功能,kafka可以实现持久化存储,Spark streaming具有实时处理日志数据,并且Nginx、Flume、Kafka、Spark Streaming的组合技术是目前较为技术成熟、数据收集较为可靠也是最为常用的实时日志数据分析处理的解决方案.通过实时日志分析,能够展示用户较为真实的需求结果.
3 软件程序设计与应用
核心程序流程主要分为部署Nginx服务器、使用Flume实时读取Nginx日志、通过Kafka集群接收Flume实时数据、在Spark Streaming接收Kafka数据等五大大步骤,具体如图2所示.
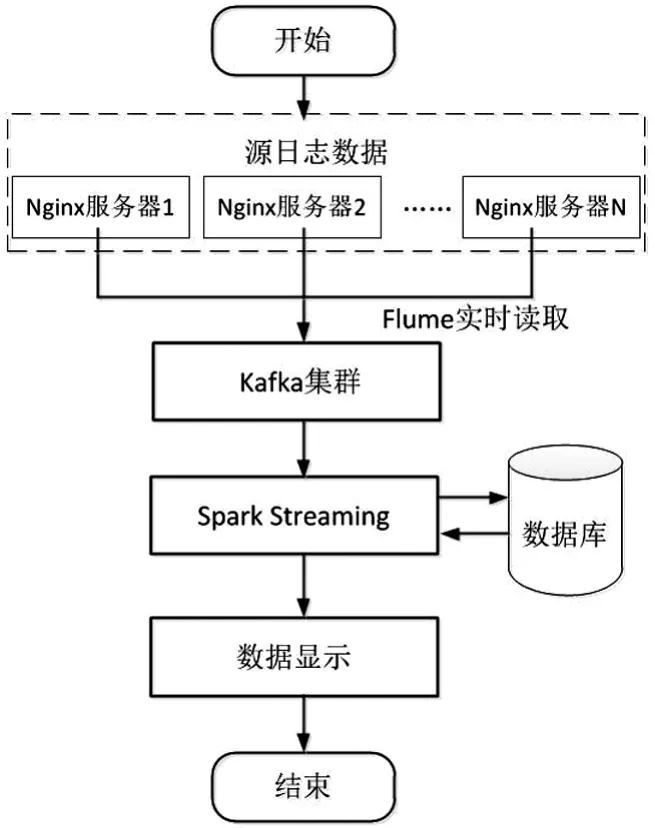
图2 实时日志分析流程Fig.2 Real time log analysis process
3.1 部署Nginx服务器
在多个linux系统中通过流量均衡负载技术部署多台Nginx服务器,数字图书馆公共资源管理平台挂载在Nginx服务器上,平台所产生的原始日志文件在Nginx服务器产生.通过多个Nginx服务器接收数字图书馆公共资源管理平台日志文件,有效加强了平台运行的数据处理能力、提高了网络的灵活性和安全性.
3.2 使用Flume实时读取Nginx日志
在每个Nginx节点安装Flume软件,通过Flume软件将本服务器的数字图书馆公共资源管理平台日志文件进行实时采集,并将实时日志数据发送到Kaf Ka进行统一集中处理.每个Nginx节点主要流程为:安装Flume软件→定义agent各组件→配置source组件→配置sink组件→配置channel组件→配置source channel sink之间的连接关系→启动agent去采集Nginx服务器的日志文件.
3.3 通过Kafka集群接收Flume实时数据
通过flume Kafka软件,实现手动设定flume的sink命令,指定实时日志数据的传送目的地之后,将平台实时日志数据从channel数据传输通道中提取出,再通过kafka的相关功能将实时日志信息写进并保存.即使日志消息有没有被消耗,Kafka也会自动存档所有的实时日志信息,确保实时日志信息的安全、可靠.
3.4 在Spark Streaming接收Kafka数据
Kafka集群中传来的实时日志数据信息被spark streaming转换为Dstream格式之后再接收和使用.本实时日志分析系统将通过直接读取的功能接收实时日志数据,首先,在Spark Streaming程序中通过驱动程序启动作业,然后使用执行器通过偏移范围的方式读取Kafka集群中的日志文件数据.[5]读取完一轮数据之后,再通过查询Kafka中的最新偏移范围,再执行日志数据的读取,依次循环直到查询不到最新的偏移范围为止.具体流程如图3所示.
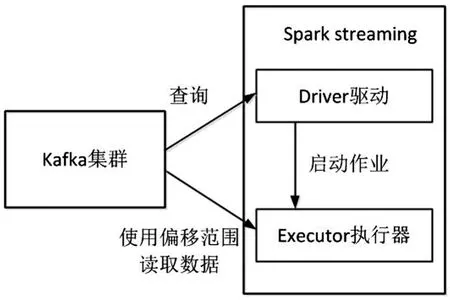
图3 直接读取方式接收数据Fig.3 Receiving data by direct reading
3.5 使用Spark Streaming进行日志分析
(1)日志解析程序设计:为了消除未解析的日志数据带来的影响,对日志解析程序设计要实现两个操作.一是对日志数据进行数据清理;二是解析得到本系统功能所需的日志数据元组.伪代码如下:
//清理日志数据
//logPattern定义日志格式的正则表达式
def filter Log(s:String)={
logPattern.findFirstIn(s)match{
case Some(logPattern(_*))=>true
case_=>false
}
}
//解析日志数据
def parseLog(s:String)={
val m=logPattern.find AllIn(s)
if(m.hasNext){
//如下方式提取需要的日志数据字段,包括客户的IP地址、用户来源、用户浏览页面信息
val clientIP=m.group(1).toString
}}
(2)主体程序设计:通过利用Spark Streaming编写程序实时分析日志数据,实现网站平台流量分析、用户来源分析、网站页面分析功能要求,最终将日志分析结果写入数据库进行保存,同时也可以直观地展示日志分析结果.具体编写程序流程如图4所示.
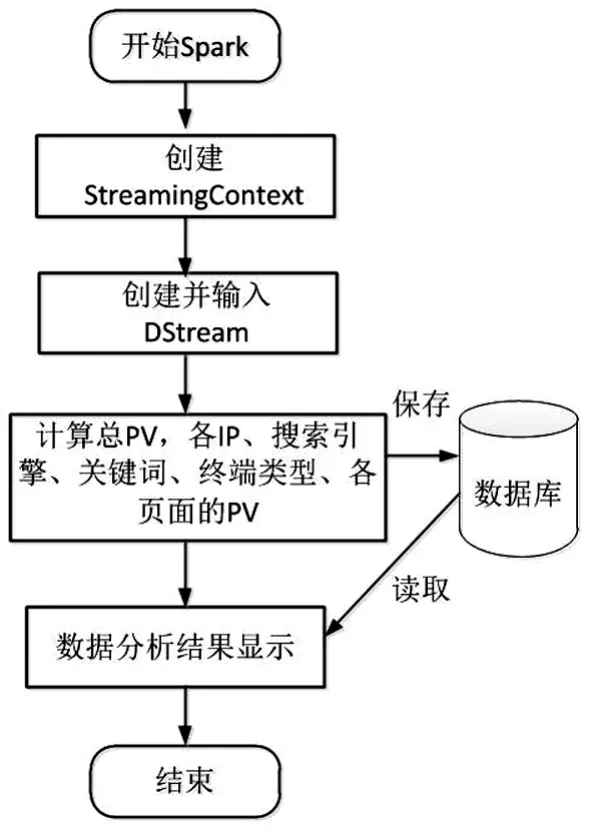
图4 Spark Streaming编写程序流程Fig.4 Spark streaming programming process
4 测试结果分析
软件测试就是在测试阶段设计出一系列的设计方案来验证系统是否存在错漏,[4]本实时日志分析系统通过了性能测试和功能测试.
4.1 性能测试
通过使用TTCPW等多个测试工具,对实时日志分析系统进行性能测试.可知系统的网络吞吐量、页面响应时间、并发数、系统性能都达标.性能测试结果如表2所示.

表2 系统性能测试Tab.2 system performance test
4.2 功能测试
在数字图书馆公共资源平台正常运行情况下,对本实时日志分析系统进行功能测试.例如,测试统计分析本平台的用户访问流量在24 h当中的占比,经过分析测试结果如图5所示.可知一天当中15时是整个平台访问的流量高峰期,其次是16时和20时.其余的功能也能够显示出分析结果.功能呈现结果达到了预期的要求.
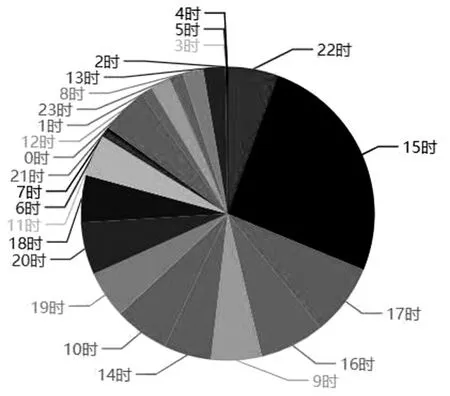
图5 系统功能测试Fig.5 system function test
平台经过了性能测试和功能模块测试之后,又进行了压力测试以及试运行测试.[4]经过测试能够实现对平台的总访问量、用户来源以及网站页面等功能进行实时数据分析,并能够以可视化的方式正常显示分析结果,系统的平均反应时间能够达到日志数据采集的要求,且在长时间的运行后,依然能够正常分析处理日志数据.
5 结语
经过测试,基于数字图书馆公共资源平台的实时日志分析系统各项功能都达到预期设计目标,具有数据实时分析、功能针对性强、结果可视化直观等特点,完全符合数字图书馆公共资源管理平台的要求.对数字图书馆公共资源管理平台的使用,能够及时统计平台的数据访问量、对平台的用户来源进行分析以及对每个用户访问平台的页面进行分析,可以提高平台的安全性以及及时、有针对性地更新用户访问量高的板块内容,同时也为其他类型的网站日志分析提供借鉴的意义.
猜你喜欢
华人时刊(2021年13期)2021-11-27
现代企业(2021年2期)2021-07-20
心声歌刊(2020年4期)2020-09-07
铁道通信信号(2019年9期)2019-11-25
网络安全和信息化(2019年8期)2019-08-28
思维与智慧·上半月(2018年9期)2018-09-22
小学生(看图说画)(2017年6期)2017-11-06
中国工程咨询(2017年9期)2017-01-31
知识产权(2016年8期)2016-12-01
网络空间安全(2016年3期)2016-06-15
