
用户轨迹挖掘与可视化系统的研究与设计
2020-07-22 09:54孙瑜王李冬
电脑知识与技术 2020年11期
孙瑜 王李冬
摘要:近年来,随着移动互联网应用的迅猛发展,用户可以很方便地获取个人位置信息,使用各种基于位置的服务(Locationbased Services,LBS),将自己的移动过程以轨迹的形式进行记录。如何对产生的轨迹数据进行挖掘,已成为数据挖掘领域的一个研究热点。在完成对大量的轨迹数据的存储与处理之后,用户轨迹的可视化对于用户轨迹的分析无疑能够提供一个直观的研究环境,但是单纯的可视化和轨迹交换并未充分发掘出轨迹中隐藏的知识。基于此,该文从用户轨迹数据出发,进行用户轨迹数据的挖掘分析并通过JAVA技术实现可视化。此外,该文通过计算两个用户之间的相似度为用户推荐潜在的朋友,完成个性化朋友推荐。
关键词:轨迹可视化;轨迹挖掘;基于位置的服务
中图分类号:TP391 文献标识码:A
1研究背景
随着移动互联网的发展,记录移动目标轨迹数据成为极其简单的工作,大多数地理信息服务相关的公司和组织已经积累了数量庞大GPS轨迹数据,但其大多数的数据都是简单的采集,对于获取的信息也没有进行进一步处理,这些原始数据庞大且难以被理解。在大数据时代,如何挖掘海量信息,为用户进行个性化的推荐,无论是对于学术研究还是商业应用都极具价值。
过去的几年里,国内的一些服务应用仍停留在根据用户当前的GPS定点,推荐用户周边距离较近的商铺等这些简单的基于位置服务的应用,而没有进一步深度挖掘用户之前轨迹信息来为用户提供更便利更智能的服务。目前国内的轨迹挖掘研究也处于借鉴一些国外研究资料进行理论研究的階段,而局限于国内的整体的轨迹数据信息环境。
国外的数据信息环境从规范性和共享性要优于国内,以Facebook、Twitter、Google+、MySpace等为代表的社交网络服务在全球已累计超过20亿的用户,这些网站的位置服务功能每天都会产生数以亿计的位置数据。这些位置数据包括时间、位置、速度等基础信息,反映了用户真实的移动轨迹。同样的,国外的轨迹挖掘和位置服务的研究也先于国内。过去几年内,已经形成了一批以GPS轨迹为代表的个人地理位置信息的挖掘研究,类似于识别在每个位置的用户特定活动,分析各位置之间的关系以及预测旅行者在这些位置之间的活动等。
Giannotti等人较早地提出了轨迹挖掘问题,Jeung等人利用航迹数据库建立了基于密度的数据表示方法,而Lee等人提出了一种TraClass方法,该方法能从轨迹数据中通过划分轨迹生成特征层级,并搜索了基于区域和基于轨迹的聚类方法。文献基于一个统一的框架,提出了地点位置的坐标提取、用户停留点检测和用户频繁行为模式挖掘方法。文献利用采集自LBSN的数据,建立地点和用户偏好模型,根据用户需求,在时空约束下生成旅游路线,形成旅游包推荐给用户。文献提取景点的开放时间、门票与GPS坐标等及旅游网站上对于景点的评价信息等,针对新手游客在陌生城市如何规划旅游路线的问题,研究基于景点评分机制以及用户多约束的旅游路线推荐问题。文献以谷歌地球软件为平台,通过采集公众上传的VGI照片数据,在数据预处理的基础上,运用核密度估计方法绘制城市热点空间分布图,研究市民对城市空间的偏好。文献从移动空间信息服务关键技术探讨基于路线推荐服务的研究方法,设计并编程实现了一个基于特定景区景点的满足用户时间需求的旅游路线推荐服务软件。
本文先实现对数据轨迹的处理与优化,之后再是完成基于地点位置的判定,实现数据点与地点直接的分析;最后,是在以上研究基础之上对用户轨迹的性质进行分析,确定用户的习惯与爱好,并且通过计算得到两个用户之间的相似度,为用户推荐潜在的朋友,完成个性化朋友推荐。
2系统设计与实现
2.1用户轨迹可视化与挖掘系统概述
随着移动互联网时代的到来,目标移动轨迹的数据获取相对较简单。就轨迹数据而言,经度Longitude,纬度Latitude,时间戳Time都是其应具有的基本属性,本文所提出的系统也是基于这个3个属性。同时对于经纬度,不难发现这个单位的定位相对较大。用户轨迹的两个地点的经纬度之差理论上相对较小,这并不方便数据的处理与分析,所以我们对经纬度数据Longitude和Latitude进行了相关的处理与优化得到了X与Y。为了数据进行更好的存储与管理,我们将轨迹数据用SQL2008数据库进行存储。
在系统的功能设计上,本文提出的系统实现了:
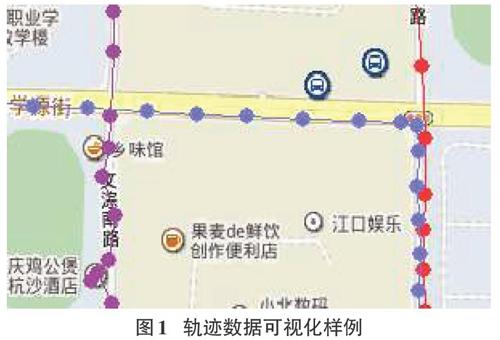
1)程序能够从数据库里读取轨迹数据,将其可视化地显示出来,不同用户的轨迹数据应当能够使用不同的颜色进行区分,如图1。
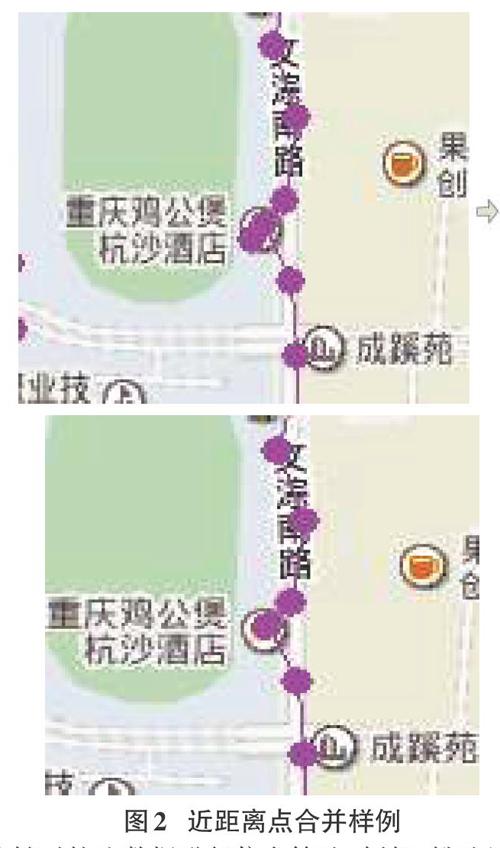
2)同时能够对轨迹数据进行一定程度的优化,例如:用户在一家小餐厅吃饭,他在餐厅内点餐和进餐之间是有目标位置的移动,表现于几个贴近或是部分重叠的点。如图2,将这些多个点合并为一个点能够既能保留数据的信息含义,抓住了用户行为的重点,同时也减轻了数据量。
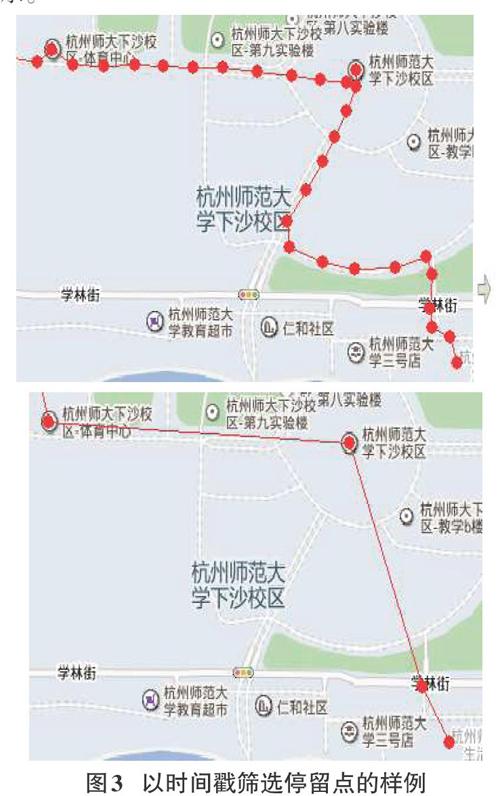
3)能够对轨迹数据进行信息筛选,例如:挑选用户停留长的点,过滤掉时间间隔短的点来直接查看轨迹的重点信息,如图3所示。
4)能够从数据库里获取地点区域点的信息,来判断轨迹中的点是否进入了一些区域,即能够分析用户A的轨迹1去了图书馆和操场,用户B的轨迹3去了水果店等。同时区域的图形应能够适应多种情况,包括一些特殊的凹多边形,即一座学校的平面区域是一个复杂的图形,不能简单地当作一个圆形或矩形进行处理。以此来判定用户的轨迹经过以及停留了哪些地点,用户停留了多长时间。
5)对用户轨迹的性质进行分析,确定用户的习惯与爱好,并且可以通过计算得到两个用户之间的习惯兴趣相似度,来为用户推荐潜在的朋友,完成个性化朋友推荐。以上都还是用户与地点的计算,兴趣相似度的计算应该涉及用户与兴趣类型的计算,比如用户甲常去A图书馆,用户乙常去B图书馆,系统不应认为A图书馆不等同B图书馆就判定用户甲和用户乙之间没有相似性,应清楚地分析到A图书馆和B图书馆的地点存在着相同的类型关联,这会对甲和乙的相似度计算产生影响。
同时本系统对习惯兴趣程度进行分析计算,就比如用户甲10条轨迹中有8条轨迹都经过了图书馆,每次的停留时间都超过了60分钟,而用户乙10条轨迹中只有1条轨迹经过了图书馆,且停留时间仅为20分钟,那么用户甲和用户乙在对“爱去图书馆”的程度上应该是有完全不同的定义。
2.2系统详细设计方案与思路
2.2.1数据库设计
以上为本文所提出的系统的数据库设计,同时我们将数据库相关的方法统一写在了DataBaseAbout.java文件中,方便管理与调用。
2.2.2可视化处理
本系统使用了JAVA中的CUI来进行可视化设计,主要思想是一个控制窗口加上一个显示窗口来完成系统的操作与显示。数据的存储思路则是先以num0数据表示每条线路点的个数,u[]数组表示每条轨迹线路所属的用户,count表示有多少条轨迹线路,再用二维数组x[]、y[][]、t[]表示每条线路的每个数据点的x、y、t属性。
系统用public void paint(Graphics g)来实现图形的绘画,即通过g.setColor方法完成色彩设置,g.fillOval方法画圆,g.draw-Line方法连线。同时,为了更加直观地显示,本系统添加了一个相应的地图作为显示背景,即使用InputStream stream=newFileInputStream(”bg.bmp”); uuage image=ImagelO.read(stream);注bg.bmp放在同项目文件夹中,否则请使用绝对地址。
2.2.3近距离点合并与停留时间筛选
近距离点合并的大致设计为在控制窗口点击按钮之后,输入距离间隔阈值d,并传递其他相应参数调用Join.java中的f方法。在f方法中,将对每条线路的每个数据点进行与相邻数据点的比较,若两个数据点之间距离小于距离间隔阈值d,则两点合并,时间戳取较早的数据点的时间。
停留时间筛选的大致原理同近距离点合并相同。
2.2.4数据点与地点的判定
用戶的某条轨迹是否进入某个地点区域,则应判断该轨迹的每个数据点是否在这块区域的多边形图形内。本系统将点与多边形的判断写在了PolygonCalculation.java中的function方法中,在通过循环传递不同的参数调用该方法,完成判断。大致原理为:
判断某点与多边形位置关系,需要区分两类多边形:1)凸多边形;2)凹多边形。
为了区分两类多边形,需要计算给定点与多边形各顶点连接形成边各个夹角的锐角和,若锐角和小于2*Math.PI弧度,则该多变形为凸多边形,否则为凹多边形。(由于圆周率强制取float后的精度误差,故弧度和total判断时补足误差0.000001,以减小误差,(total +0.000001)< (float)《n-2)*Math.PI》。
根据给定点与两类多边形位置关系,其性质不同:1)凸多边形:点到多边形各个定点形成的邻边的夹角之和为360度,则点在凸多边形内;小于360度则在凸多边形外。2)凹多边形:若给定点为(a,b),做射线x=a(y>b),计算与多边形交点个数,若交点个数为奇数个则在凹多边形内,否则在凹多边形外。(注:点在多边形边线上情况不做讨论。)
