
基于YOLO v3与图结构模型的群养猪只头尾辨别方法
2020-07-24 05:07沈明霞刘龙申陆明洲孙玉文
农业机械学报 2020年7期
李 泊 沈明霞 刘龙申 陆明洲 孙玉文
(南京农业大学工学院, 南京 210031)
0 引言
智能视频监控技术在生猪养殖中的应用日趋广泛,利用计算机视觉技术提高生猪行为监测水平已成为农业工程领域的研究热点之一[1-3]。要实现视频图像中群养猪只的自动行为监测,准确的猪只定位是系统必不可少的环节[4-6]。随着研究的深入,仅获得整体猪只的位置已不能完全满足精准监测的需求。例如在猪只饮水、采食、爬胯等行为的监测识别过程中,相比于整体猪只的位置,利用头部或尾部等部位信息明显更加合理[7-11]。因此,准确获取猪只的头部和尾部等关键部位信息对于提高猪只的行为监测水平具有重要意义。
近年来,对于图像中的猪只检测问题国内外有许多深入研究,旨在不断提高猪只检测的精度[12-15]。而关于猪只头尾辨别问题的研究相对较少,并且大部分情况下仅将此问题作为整个系统的一个简单操作进行处理,因此采用方法都较为基础。KASHIHA等[8]通过分析猪只轮廓各点到质心距离曲线的整体趋势来判断头部位置。NASIRAHMADI等[9]利用拟合椭圆的长轴与猪体轮廓的交点判断头尾位置,但并未分辨出头部和尾部。杨心等[16]在通过椭圆拟合及猪体身长截取出猪体两端的轮廓后,利用广义Hough聚类的方法识别轮廓属于头部或尾部。高云等[17]在此方法的基础上增加了对轮廓圆度的考虑,进一步提高了头尾判别的精度。上述方法需要建立在猪只个体分割及其轮廓提取均正确的基础上,而在光照不均、猪只严重密集等复杂情况下很难保证轮廓提取的精度。不同于上述方法,文献[10-11]利用快速区域卷积神经网络(Fast region-based convolutional neural networks, Fast R-CNN)模型直接训练猪只头部检测器,取得了较高的检测精度。但这种方法无法处理由于遮挡、强光等因素导致头部不可见的情况,并且该方法对头部与猪只整体分开进行检测,需要对头部和其所属猪只进行关联,但文中对此考虑较为简单,无法处理复杂情况。
鉴于猪只头部和尾部在判断猪只行为中的重要作用,并且二者可以基本确定猪只身体方向,本文选取猪只头部和尾部为两类关键部位,从群养猪只的监控视频中自动获取准确的猪只及其头尾位置信息,提出一种猪只检测及头尾辨别方法,以提高群养猪只自动行为识别及监测水平。
1 材料与方法
1.1 视频采集
本文的实验图像均采集于南京农业大学江浦农场生猪养殖基地。所选取的实验猪舍面积约为3.8 m×3.2 m,猪舍中央安装的铁栏杆将整个猪舍分割为两个独立的小型猪舍,每个小型猪舍中饲养4头保育期猪只。监控摄像机安装于实验猪舍中心位置的天花板处,近似位于铁栏杆的正上方,高度约2.5 m。监控摄像机以俯视的角度进行拍摄。选用镜头焦距为4 mm的海康威视DS-2CD3335-I型红外摄像机。由于受猪舍高度及摄像机镜头焦距限制,摄像机所能拍摄到的监控画面并不能完整覆盖整个猪舍,因此靠近画面上侧与左侧猪舍边缘处的猪只可能会出现整体或部分身体超出摄像机成像范围的情况。
实验期间摄像机连续采集5 d猪只活动视频。考虑到夜晚时段的猪只多处于睡眠状态,因此仅选取每日08:00—17:00间猪只较活跃时段的视频作为实验素材。摄像机工作过程中,监控视频存储于硬盘录像机中,帧率为12 f/s。视频采集完成后,以20 s间隔从视频中抽取540幅图像作为图像数据集,图像分辨率为2 048像素×1 536像素。从540幅图像中随机选取300幅图像作为训练集,其余240幅图像作为测试集。本文仅关注图像中头尾均完整可见的猪只目标。在训练集和测试集中完整猪只分别为1 956头和1 584头。在图像中用矩形框人工标注出所有完整猪只个体的身体、头部、尾部,便于后续的模型训练和测试。由于所有的实验图像数据均采集于自然环境下的群养圈舍,图像中呈现的许多特点反映了实际生产环境的特点,例如不均匀的光照、图像中央的栏杆、多变的猪只姿态,这些因素提高了猪只检测和头尾辨别的难度,因此该图像测试集可用于客观评价本文方法在实际生产应用中的性能。
1.2 研究方法
本文提出了一种在群养猪只的监控图像中检测猪只目标并辨别其头尾位置的方法。该方法借鉴了计算机视觉中研究人体检测及姿态估计问题的一种思路,即引入基于部位的模型(Part-based model)[18-19],将猪只看作由关键部位按一定空间关系组合成的目标。本文方法流程如图1所示。

图1 本文方法流程图Fig.1 Flow chart of proposed method
首先,在输入图像中检测猪只整体、猪只头部、猪只尾部3种目标位置,作为进一步分析的基础。综合考虑检测精度及运行速度,选择基于深度神经网络的目标检测模型YOLO v3(You only look once v3)[20]作为目标检测器,检测结果在图像中用矩形框表示。接下来,逐个提取猪只整体的检测矩形框判断其内部的部位情况。统计矩形框中心处于整体猪只矩形框内部的头部和尾部数目,分别用Nhead和Ntail表示。根据Nhead和Ntail的取值,分为以下3种情况:
(1)Nhead≥1且Ntail≥1,即猪只整体矩形框内部检测到头尾两种部位,但可能出现多种头尾组合方法。这种情况下,利用预先建立好的图结构模型(Pictorial structure models)[21]对每种可能的头尾组合计算其组合得分,最后选取得分最高且超过阈值tscore的头尾组合作为当前猪只的头尾位置。
(2)Nhead≥1、Ntail=0或Nhead=0、Ntail≥1,即猪只整体矩形框内部仅检测到头部或尾部一种部位。这种情况下需要根据当前图像的特征推理出缺失部位的位置。获得推理的部位位置后,接下来的处理方式与情况(1)相同。
(3)Nhead=0且Ntail=0,即猪只整体矩形框内未检测到任何部位。此时根据文献[16]中基于广义Hough聚类的方法作为一种弥补措施,辨别出头部和尾部的位置。同时,当前两种情况下无得分超过阈值的部位组合时,也利用该方法确定头尾的位置。
通过上述3种处理方式,可以对检测到的每头猪只目标辨别出其头部和尾部的位置。
1.3 基于YOLO v3的猪只整体及头尾检测
YOLO[22]是基于卷积神经网络的通用目标检测模型,该模型的特点是在进行检测时使用回归思路预测所检测目标的矩形框,因此与其他需要先进行选择性搜索提取大量候选区域的检测方法相比,能够大大提高计算效率。YOLO v3是YOLO系列模型的最新版本,借鉴了残差网络形成更深的网络层次,还融合特征金字塔网络改善了目标检测的性能,尤其适于小目标的检测。因此,从检测精度和效率两方面综合考虑,本文选用YOLO v3模型检测猪只整体和头尾部位。
一般深度学习模型需要大量训练样本,而本文为了适应有限的训练样本,在模型训练时使用迁移学习的策略,引入在VOC数据集上预训练好的模型。在预训练模型的基础上,使用本文训练集中的标注数据进行模型参数微调,最终获得训练好的检测模型。该模型具有从输入图像中检测猪只整体及其头部、尾部3类目标的矩形框坐标及置信度的功能。
图2为测试集中猪只整体及部位检测结果示例。图中猪只整体检测结果用红色矩形框标示,头部和尾部检测结果分别用蓝色和绿色矩形框标示。为了方便叙述,对图像中的猪只标记了序号。由于YOLO v3模型的检测精度较高,图像中的大部分猪只及其部位都能被准确检测到。但在某些特殊情况,如遮挡、快速运动模糊等因素的影响下,仍然会存在一些部位漏检的情况。如图2中2号猪只的尾部由于被1号猪只遮挡而未能检测到。另外,即使头尾能够被准确检测,但如何实现头尾与猪只整体间的正确关联也是一个重要的问题。如3~6号猪只的检测矩形框内除了含有相应序号猪只的部位外,还包含了其他猪只的部位。因此,还需要对部位检测结果进行进一步分析,才能够最终确定猪只头尾位置及其正确关联的整体猪只。

图2 猪只整体及部位检测结果示例Fig.2 Example of detection results for pig and their parts based on YOLO v3
1.4 基于图结构模型的猪只部位组合
若从俯视角度观察猪只,会发现其头部和尾部具有一定的几何约束关系。这种约束可以作为一种先验知识,用于衡量头部和尾部的组合方式属于同一头猪的可信度。本文引入图结构模型来实现部位组合的功能。图结构模型是用一组部位和它们之间的联系来描述整体目标内部位组合关系的模型,广泛用于人脸、人体等可用不同部位的组合来描述的对象[23-24]。图结构模型中的部位代表了整体目标的局部视觉特征,部位的选取通常符合目标的语义分割方式,如将人体划分为头部、躯干、四肢等部位。而部位间用类似弹簧的模型描述部位间的形变特性,将部位的空间组合特征定义为一种形变配置(Deformable configuration)。这样,图结构模型就可以灵活表示各种形变配置情况下的整体目标。
本文所构建的猪只图结构模型如图3所示。整个模型的结构可看作一个简单的无向图,由3种类型的结点组成:整体猪只结点Vp、头部结点Vh、尾部结点Vt。每个结点的配置信息由其图像坐标决定。在已知3种结点的图像坐标后,可按图3的方式构造同样结构的无向图,并定义得分函数ψ(Vp,Vh,Vt)计算当前图结构与预先建立的图结构模型的匹配程度。匹配得分为头尾部位的局部外观特征得分与部位之间几何约束得分的加权叠加。

图3 猪只图结构模型示意图Fig.3 Pictorial structure model for pigs
(1)
φa(Vh,Vt)=(c(Vh)+c(Vt))/2
(2)
φg(Vp,Vh,Vt)=whpN(dhp_norm;μhp,σhp)+
wtpN(dtp_norm;μtp,σtp)+wθN(θht;μθ,σθ)
(3)
(4)
式中φa(·)——部位外观特征得分函数
φg(·)——部位间几何约束得分函数
wa、wg——部位外观特征得分、部位间几何约束得分权值
c(·)——部位的检测置信度,由YOLO v3模型输出,取值为[0,1]
N(·)——高斯概率密度函数
dhp_norm——头部与猪只中心点间的归一化距离
dtp_norm——尾部与猪只中心点间的归一化距离
不能在市场经济的浪潮中立足和发展的工匠精神是不可取的。工匠精神所依附的事业如果不能发展,那么再美好的工匠精神也只是镜花水月甚至是自我陶醉。
θht——头、尾部与猪只中心连线形成的夹角
μhp、μtp、μθ——高斯分布均值
σhp、σtp、σθ——高斯分布的标准差
whp、wtp、wθ——3项得分对应的权值
dhp——头部与猪只中心点之间的欧氏距离
dtp——尾部与猪只中心点之间的欧氏距离
dht——头部与尾部间的欧氏距离
头尾部位的外观特征得分φa表示头尾结点检测置信度的平均值。部位间的几何约束得分为3项得分的加权求和:头部与猪只中心点之间的距离约束得分;尾部与猪只中心点之间的距离约束得分;头部、尾部与猪只中心点之间的方向约束得分。为了灵活描述图结构模型中部位间的空间形变约束,几何约束得分中的3个得分项均采用高斯概率密度函数计算部位组合的得分。高斯分布的参数由猪只先验结构知识与训练集中参数的统计规律综合确定。为了保证高斯概率密度函数的参数不受猪只尺寸的影响,将猪只头尾距离进行归一化。
当确定猪只检测矩形框内的头尾组合方式后,利用式(1)可计算当前组合得分,得分反映了部位配置与预先建立的图结构模型的匹配程度。当整体猪只检测矩形框内包含多种可能的头尾组合时,可通过不同组合方式的得分确定正确关联的头尾位置。以图2中的4号猪只为例,其检测矩形框中包含2个头部检测结果,因此可形成两种头尾组合方式,如图4所示。利用式(1)进行计算,图4a的头尾组合得分为0.875 1,而图4b的头尾组合得分为0.374 6,因此判定图4a的组合方式为最终确定的头尾位置。

图4 同一检测矩形框内的2种头尾组合示例Fig.4 Examples for two combinations of heads and tails in one detection bounding box of a pig
1.5 基于阈值分割与椭圆拟合的部位推理
1.4节中的部位组合方法要求猪只整体检测矩形框内同时存在头部和尾部两种部位。当其中一种类型的部位缺失时,需要推理出缺失部位的位置才能构建出完整的图结构。因此,本文提出了一种利用猪只身体的灰度特性与形状特性推理缺失部位位置的方法,方法流程如图5所示。
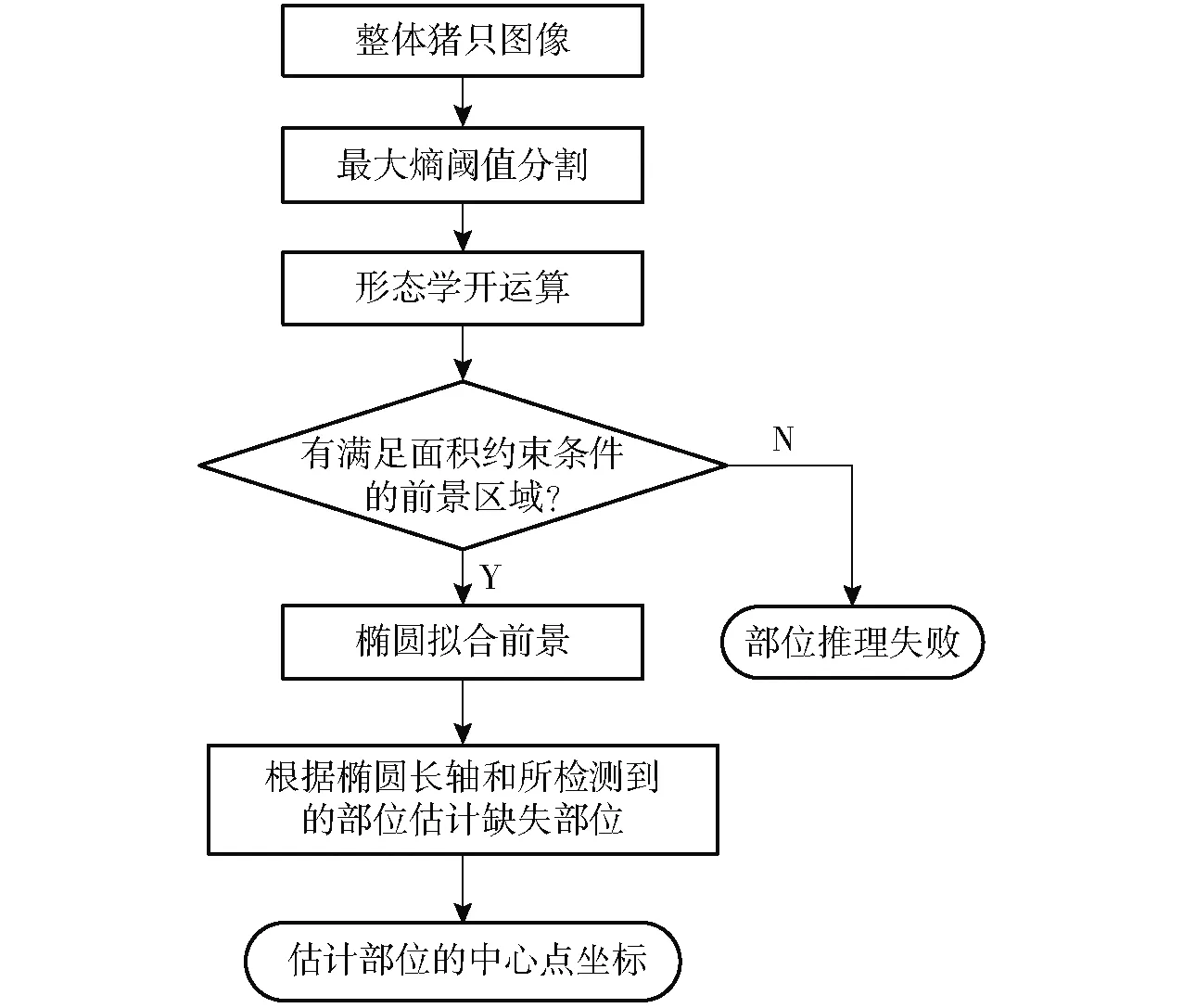
图5 缺失部位推理流程图Fig.5 Flow chart of missing part inference
首先,提取猪只检测矩形框内的图像,使用最大熵阈值分割法[25]对该图像进行二值化操作。最大熵阈值分割法可以根据图像中像素灰度的统计特性自动确定阈值,无需设定参数即可分割出具有较亮灰度的前景像素。然后,进行形态学开运算操作,目的是去除前景中小面积的连通分量区域,且尽可能将粘连区域分割。接下来,选出图像中面积最大且面积超过一定阈值的连通分量区域,即满足
Amax≥αWimgHimg
(5)
式中Amax——连通分量区域的最大面积
α——最大面积阈值
Wimg——整体猪只图像的宽度
Himg——整体猪只图像的高度
若存在满足面积约束条件的连通分量,则对该区域进行椭圆拟合,获取拟合椭圆的各项参数。根据猪只的身体形状特点,理想情况下猪只的头部和尾部应该处于拟合椭圆长轴的两端。因此,在已知椭圆中心点坐标(x0,y0)、长轴长度a、椭圆倾斜角φ的条件下,根据
(6)
(7)
式中 (x1,y1)——推断头部中心点坐标
(x2,y2)——推断尾部中心点坐标
β——头尾位置分割椭圆长轴的比例,为常数
θe——椭圆长轴与水平方向的夹角
推断出两个备选部位中心点(x1,y1)和(x2,y2)。最后,选取两个备选部位点中距已知所检测到的部位较远的点为推理结果。部位推理结果与所检测到的部位一同构成一种头尾组合,当存在多种头尾组合时可利用1.3节的方法选取最优的组合方式作为头尾辨别的结果。
以图2中的2号猪只为例,图6展示了尾部推理过程。图中推理出的部位中心点用虚线框标记,可以看到被遮挡的尾部能够被正确推理。

图6 部位推理过程示例Fig.6 Example for process of part inference
经过上述方法的处理,图2中的猪只均能正确分辨其头尾位置,结果如图7所示。

图7 对图2中所检测到猪只的头尾辨别结果Fig.7 Head/tail identification results for Fig.2
2 实验结果与分析
2.1 实验配置与评价指标
实验所用的硬件处理平台为台式计算机,配置为Intel i7-8700K 3.7 GHz CPU,GPU为GTX1080Ti,带有11 GB独立显存和16 GB内存。实验中YOLO v3模型的学习和测试部分在开源的Darknet框架下使用GPU运行,对部位检测结果的处理分析,如计算头尾组合得分、部位推理等操作则在Matlab平台上运行。实验中的关键参数如表1所示。

表1 实验中的关键参数Tab.1 Settings of important parameters in experiments
使用精确率(Precision)和召回率(Recall)两个指标衡量猪只整体及部位的定位精度。需要注意的是,对猪只整体来说,若检测矩形框与预先标定的真实矩形框的交并比(Intersection over union)大于0.5,则定义为检测正确;而对于检测或推理获得的头尾位置,其中心点处于预先标记的真实头尾矩形框范围内,则认为部位定位正确。另一评价指标为猪只头尾辨别的精确率,即计算头尾与猪只整体正确关联且头尾位置均准确的猪只占所有检测到猪只的比例。
2.2 猪只头尾辨别结果
为了验证本文方法的有效性,本文在测试集上进行了实验。表2为直接利用YOLO v3模型检测猪只整体及部位的结果和在此基础上进一步利用图结构模型进行部位组合和部位推理后的结果。从表2可以看出,YOLO v3模型在检测猪只整体方面可以获得较理想的结果。但由于头、尾部位的图像尺寸较小,使得图像中包含的视觉特征不足,头部和尾部检测的精确率和召回率均低于整体猪只的检测精度。同时也注意到,尾部检测的精确率和召回率略低于头部,这也符合图像的特点,即尾部图像相对于头部图像更缺乏明显的视觉特征,且相对于头部更容易因拥挤被遮挡,导致尾部检测的漏检增多。表2说明经过部位组合和部位推理等操作后,头部和尾部检测的精确率和召回率都有明显提升。一方面是因为成功推理出了部分缺失部位,另一方面是由于一些部位检测虚警(False alarms),未能与整体猪只相关联而被去除。由于部位组合后每头猪只整体都能确认一对头尾组合,因此漏检部位数与虚警部位数是相同的,这时精确率与召回率相等。

表2 部位组合及推理前后猪只整体和部位的检测结果Tab.2 Detection results for pigs and their parts before and after part assemble and inference %
本文方法、文献[10]方法、文献[16]方法的猪只头尾辨别精确率分别为96.22%、91.53%、79.41%。需要注意文献[10]方法仅实现了头部与整体的关联,且使用的检测模型为Fast R-CNN。为了便于比较,在实验中将尾部也用同样的方法与整体猪只相关联,且将检测模型替换为YOLO v3,这样更能在同等条件下证明本文所提出的图结构模型与部位推理方法的作用及意义。另外,实验中使用文献[16]的方法时,利用了本文的部位推理方法获取拟合椭圆,然后将椭圆长轴两端的前景区域作为猪只身体两端的轮廓,用于计算广义Hough聚类的结果。这里与原文的轮廓提取方法有细微差别。本文方法相对于另外两种对比方法在头尾辨别精确率上具有明显优势。相对于文献[10]中的方法,本文方法的优势在于增加了构建图结构模型计算头尾组合得分及部位推理两部分,因此可以处理猪只整体矩形框内存在多种头尾组合方式或部位漏检等特殊情况,而文献[16]的方法需要在头尾轮廓准确提取的基础上实现。本文实验的测试图像拍摄于光照不均匀、背景干扰复杂的圈舍环境下,使用阈值分割方法很难获得完全精确的猪只前景区域,因此依靠前景轮廓判断头尾也很难获得准确结果。图8为测试集中猪只头尾辨别结果示例。图8中左图为本文方法辨别头尾的结果,右图为文献[16]方法的辨别结果,其中蓝色和绿色框分别为头部和尾部的辨别结果。图8a和图8c为检测部位缺失时的情况,图8b和图8d为整体猪只矩形框内存在多种部位组合的情况。从图8中可直观感受到本文方法相对于其他两种方法的优势。需要注意的是,本文在猪只整体矩形框内没有检测到任何部位时,使用文献[16]中的方法作为补偿方案。由于这种情况非常少见,因此少量的精度损失是可接受的。

图8 头尾辨别结果示例Fig.8 Examples of pig head/tail identification
本文所提出的猪只头尾辨别方法是建立在对猪只整体及其头尾准确定位的基础上,即确保YOLO v3模型的检测精度。作为一个深度神经网络模型,决定YOLO v3模型检测性能的重要因素为训练样本的质量。因此,若要将本文方法推广应用到其他俯视拍摄的视频监控场景中,只需将该场景下的猪只样本图像进行标记,并用其对YOLO v3模型进行参数微调即可。图9为另一个场景中,对YOLO v3模型进行参数微调并结合图结构模型对猪只头尾辨别的结果。从图9中可以看出,本文方法依然能正确辨别出猪只头尾位置,证明了本文方法具有良好的泛化性能。

图9 另一场景下的猪只头尾辨别结果示例Fig.9 Examples of pig head/tail identification results in another scene
3 讨论
虽然本文方法取得了可靠的猪只头尾辨别效果,但依然存在一定的缺点。首先,本文方法必须建立在猪只整体正确检测的基础上,且最终头尾辨别的正确率高度依赖头尾检测的精度。若部位漏检率较高,或存在大量的虚警目标,会降低头尾辨别的精度。其次,本文方法限定一个猪只整体检测矩形框内仅存在一种正确的头尾组合,若猪只过于密集,导致一个矩形框内存在两个完整的猪只身体时,本文无法辨别两只猪各自的头尾组合。另外,本文所用的部位推理方法依然较为基础,虽然目前作为一种弥补手段暂时可行,但若希望继续提高算法精度,仍需要进行更深入的考虑。
4 结束语
提出了一种基于YOLO v3与图结构模型的群养猪只头尾辨别方法。在实际圈舍群养环境下的监控图像集上进行了实验,结果表明,本文方法比YOLO v3模型在头尾定位的精确率和召回率上均有明显提高,本文方法的头尾辨别精确率可达96.22%,优于文献[10]和文献[16]的方法。因此,本文方法可有效实现群养猪只的准确检测及头尾辨别,受光照、猪只头数、姿态等干扰因素的影响较小。
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
畜禽业(2021年7期)2021-12-04
汽车零部件(2021年9期)2021-09-29
军事文摘(2020年22期)2021-01-04
中国畜禽种业(2020年4期)2020-12-16
猪业科学(2020年10期)2020-12-13
猪业科学(2020年7期)2020-12-11
红领巾·探索(2019年6期)2019-08-01
学生导报·东方少年(2019年28期)2019-01-17
早期教育(美术教育)(2010年7期)2010-06-28
