
基于ELK4+Kafka的智慧运维大数据分析平台研究与实现
2020-07-24 02:11阮晓龙贺路路
软件导刊 2020年6期
关键词:大数据
阮晓龙 贺路路

摘要:基于ELK在智慧运维大数据分析平台实现海量数据分析,对ELK的部署结构进行优化,并在日志采集和日志处理中间增加KaVa消息处理队列,减轻Logstash压力,增加集群高可用性。通过Logstash的Filter插件利用正则表达式实现日志数据拆分,将拆分后的字段在Elasticsearch中存储,最终利用Kibana对日志数据进行搜索、绘图和展示。使用基于ELK的智慧运维大数据平台解决了运维过程中日志采集、日志处理、日志可视化问题,同时在数据处理上实现了接近1s的延迟搜索。
关键词:ELK;KaVa;日志分析;大数据;流式数据
DOI:10.11907/rjdk.192248 开放科学(资源服务)标识码(OSID):
中图分类号:TP319文献标识码:A 文章编号:1672-7800(2020)006-0150-05
0 引言
让运维更智能、更高效是运维的首要需求,智慧运维是运维发展的必然趋势。对数据中心海量运行数据进行分析,从数据中找规律、找价值是智慧运维的核心。智慧运维的基础是海量日志数据分析,日志分析是日常运维、故障排错、性能分析的重要途径。数据中心每天产生的日志数据越来越多,日志处理工作量越来越大,处理方法越来越复杂,对实时性的要求越来越高。针对传统日志分析方法而言,日志获取难、分析耗時耗力、不易动态扩展等问题逐渐凸显。
随着分析技术及搜索技术的成熟与发展,在日志处理领域出现了以ELK Stack为代表的实时日志分析平台,运维人员从TB甚至PB级的日志中获取所需关注的信息及实现日志实时分析,使可视化展示分析成为可能。ELKStack是日志采集工具Logstash.分布式搜索引擎Elasticsearch、数据可视化分析平台Kibana 3个开源软件的组合。本文基于ELK Stack技术,实现了对海量日志进行实时采集、检索和展示的智慧运维大数据分析平台部署。
1 基于ELK智慧运维大数据分析平台
1.1 平台整体架构
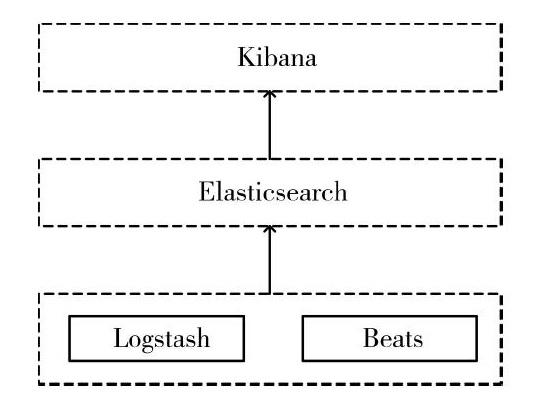
数据采集、数据处理、数据存储、数据可视化展示是一个完整的日志分析系统必不可少的组成部分。在ELKStack架构中,Logstash或Beats作为日志采集器分布于各业务系统进行日志采集,将日志文本按照既定规则解析后输出至Elasticsearch。Elasticsearch是ELK Stack中的核心系统,负责存储和搜索日志。Kibana是大数据图形化展示工具,集成了DSL命令行、数据处理等插件,可以对Elasticsearch中的数据进行搜索、分析以及可视化展示。
ELKStack架构如图l所示。
1.2 日志数据实时收集
日志采集是日志分析的基础,Logstash是一个开源数据收集引擎,具有实时管道功能,可以同时从多个数据源获取数据,并对数据进行处理后发送到Elasticsearch服务器中。
业务数据往往以各种各样的形式分散在不同系统中,Logstash支持各种输入选择,可以在同一时间从众多来源捕捉事件,能够以连续的流式传输方式,实现日志、指标、Web应用、数据存储以及各种AWS服务的日志数据采集。采集的日志数据流通过Logstash中的Input流人,经过Filter实时解析和数据处理后通过Output进行输出。
Logstash拥有丰富的Filter插件,例如Grok是Log.stash的一个正则表达式插件,用于处理Syslog、Apache和其它Web服务日志、MySQL日志以及人为定义的日志格式,且其内置超过120种常用正则表达式。利用Grok处理日志文本时一般按以下步骤进行解析:①对将要进行分析的日志进行解读,理解日志中每一个字段代表的含义;②确定利用Grok要将一条日志分为多少个字段,拆分字段是后期分析的重要指标;③利用Grok Debugger对编写的正则进行调试,获取目标字段。
例如一条访问日志信息如下:
10.10.3.2292019-08-0516:30:58GE//var/www/html 200461120.075
根据日志字段含义,通过Grok编写规则如下。拆分日志后的内容及格式如下:
Beats是ELK Stack的一系列数据采集器的总称,对于不同的日志使用不同的采集器,目前Beats系列包含以下7个成员,如表1所示。
相比Logstash,Beats只负责采集数据而不处理数据,因而占用的CPU和内存比Logstash少得多,其对业务服务器的影响可忽略不计。在实际应用环境中,推荐在业务系统部署Beats系列而不是Logstash采集数据从而来减轻服务器自身压力,并由Logstash进行数据处理。
1.3 日志数据存储
Elasticsearch为开源、分布式、基于Restful API、支持PB甚至更高数量级的搜索引擎工具,作为ElK Stack的核心,可以集中存储数据。
Elasticsearch在生产环境中一般以集群的形式存在,在集群中节点分为主节点、数据节点、客户端节点3种角色。主节点负责集群中索引的创建、删除以及数据的Rebalance等操作,但不负责数据的索引和检索,一般负载较轻。数据节点负责集群中数据的索引和检索,一般压力较大,对机器配置要求较高。客户端节点负责来自不同请求的分发、汇总等,增加客户端节点更多是为了负载均衡。
为了更好地理解Elasticsearch,将Elasticsearch与关系型数据库MySQL进行对比如表2所示。
1.4 日志数据可视化
数据可视化主要借助于图形化手段,清晰有效地传达与沟通信息。Kibana是一款开源的数据分析和可视化平台,它是ElKStack成员之一,用作与Elasticsearch交互,可以对Elasticsearch索引中的数据进行搜索、查看,同时利用图表、表格及地图对数据进行多元化分析和呈现。
2 基于ELK+Kafka的智慧运维大数据分析平台部署
ELK Stack在实际生产环境中通常以集群的方式部署,集群部署的好处就是系统扩展容易且能够实现负载均衡,保持系统长期稳定运行。
整个ELK Stak架构的调优不仅是Elasticsearch集群的调优,同时包含数据采集、数据处理过程调优,因此在数据采集后增加Kafka集群。Kafka是一个适合离线和在线消息的队列,Kafka消息保留在磁盘上,并在集群内复制以防止数据丢失。部署Kafka可以减轻Logstash压力,避免日志在处理前丢失。
经过系统拓扑优化,结合现有实际情况,本文部署结构使用10台服务器,拓扑结构如图2所示。服务器功能划分如表2所示。
2.1 Kafka集群部署
部署kafka集群需要3个基础软件,分别为Java环境、ZooKeeper和Kafka。目前JDK最新版本为12.0.2,下载地址为https://www.oracle.com/technetwork/java/javase/down10ads/jdkl2-downloads-5295953.html。ZooKeeper最新版本为3.5.5,下载地址为https://www-us.apache.org/dist/zookeepedzookeeper-3.5.5/(推薦使用bin格式的压缩包)。Kafka最新版本为2.3.0,下载地址为http://kafka.apache.org/downloads(推荐使用bin格式且为Scala 2.12)。建议在部署时关闭CentOS 7的防火墙以及SELinux,待部署完成后开启相应端口。
2.1.1 Java环境安装
将JDK安装包上传到CentOS 7相应目录下。通过如下命令进行JDK压缩包解压,并将解压的目录重新命名,其命令如下:
#tar-zxvfjdk-12.0.2_linux-x64_bin.tar.gz
#my jdk-12.0.2/jdk
安装JDK后需要配置环境变量,编辑/etc/profile文件。在文件尾部添加如下配置。
#vim/etc/profile
export JAVA_HOME=/opt/jdk
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JA.VA_HOME/lib/dtjar:$JAVA_HOME/lib/tools.jar
export PATH=$PA7H:$JAVA_HOME/bin
通过source命令重新加载/etc/profile文件,使得修改后的内容生效,命令如下:
#source/etc/profile
#java-version
2.1.2 ZooKeeper集群部署
将ZooKeeper压缩包上传到CentOS 7相应目录下。通过如下命令进行ZooKeeper压缩包解压,并将解压的目录重新命名,其命令如下所示:
#tar-zxvf apache-zookeeper-3.5.5-bin.tar.gz
#mv apache-zookeeper-3.5.5-bin/zookeeper
ZooKeeper的配置文件在zookeeper/config/目录下,首先复制zoo_sample.cfg为zoo.Cfg,然后在zookeeper目录下创建data目录和logs目录,用于存放zookeeper数据和运行日志。相关命令如下:
#cp zoo_sample.cfgzoo.Cfg
#mkdir/opt/zookeeper/{data,logs}
在data目录下创建myid文件,myid值是zoo.cfg文件里定义的server.A项的值。10.10.2.226、10.10.2.227、10.10.2.228的myid值分别为l、2、3,myid值可配置为1-255。
zoo.CfC配置文件配置内容如下:
dataDir=/opt/zookeeper/data
dataLogDir=/opt/zookeeperflogs
clientPort=218l
server.1=10.10.2.226:2888:3888
server.2=10.10.2.227:2888:3888
server.3=10.10.2.228:2888:3888
按照上述方法完成3台Kafka服务器配置,分别在3台Kafka服务器上启动ZooKeeper集群,启动、查看状态命令如下。启动后会显示当前ZooKeeper节点属于主节点还是从节点。
#/opt/zookeeper/bin/zkServer.sh start//启动命令
#/opt/zookeeper/bin/zkServer.sh status//状态查看
2.1.3 Kafka集群部署
将Kafka压缩包上传到CentOS 7相应目录下。通过如下命令进行Kafka压缩包解压,并将解压的目录重新命名,其命令如下:
#tar-zxvf kafka_2.12-2.3.0.tgz
#mv kafka_2.12-2.3.0/kafka
Kafka的配置文件在/opt/kafka/config目录下,编辑server.properties文件,编辑内容如下:
broker.id=1
listeners=PLAIN了EXT:H10.10.2.226:9092
advertised.1isteners=PLAINTEXT://10.10.2.226:9092
log.dirs=/opt/kafka/logs
zookeeper.connect:10.10.2.226:2181,10.10.2.227:2181,10.10.2.228:2181
按照上述方法完成3臺Kafka服务器的配置,分别在3台Kafka服务器上启动Kafka集群,启动命令如下。其它两个节点的的broker.id不同,另外分别为2、3。
#/opt/kafka/bin/kafka-server-start.sh/opt/kafka/config/server.properties
2.2 Logstash部署
目前,Logstash的最新版本为7.2.0,下载地址为:https://artifacts.elastic.co/downloads/logstash/logstash-7.2.0.tar.gz。将Logstash压缩包上传到CentOS 7相应目录下。
通过如下命令进行Logstash压缩包解压,并将解压的目录重新命名,其命令如下:
#tar-zxvf logstash-7.2.0.tar.gz
#mv logstash-7.2.0/logstash
Logstash的配置文件在/opt/logstash/config目录下,编辑logstash.yml文件,配置内容如下:
node.name:asc-analysis
path.data:/optflogstash/data
http.host:“10.10.2.229'
http.port:9600-9700
配置完成后通过运行最基本的Logstash管道测试Logstash是否安装成功。Logstash管道有两个必需元素:input和output,相关测试命令如下:
#/opt/logstash/bin/logstash-e‘input{stdin{}}output{std-out{}}
测试时无论输入什么内容,Logstash都会按照规范格式输出,其中-e参数允许Logstash直接通过命令行接受设置,以实现在测试配置时不需要频繁编辑配置文件。
2.3 Elasticsearch集群部署
目前,Elasticsearch的最新版本为7.2.0,下载地址为:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.2.0-1inux-x86_64.tar.gz。将Elasticsearch压缩包上传到CentOS 7相应目录下。通过如下命令进行Logstash压缩包解压,并将解压的目录重新命名,其命令如下:
Elasticsearch的配置文件在/opt/elasticsearch/config目录下,编辑elasticsearch.yml文件,进行Elasticseach集群名称、节点IP地址、通信端口、数据存放目录、运行日志目录配置,注意在配置时每一个配置项前需要有空格。
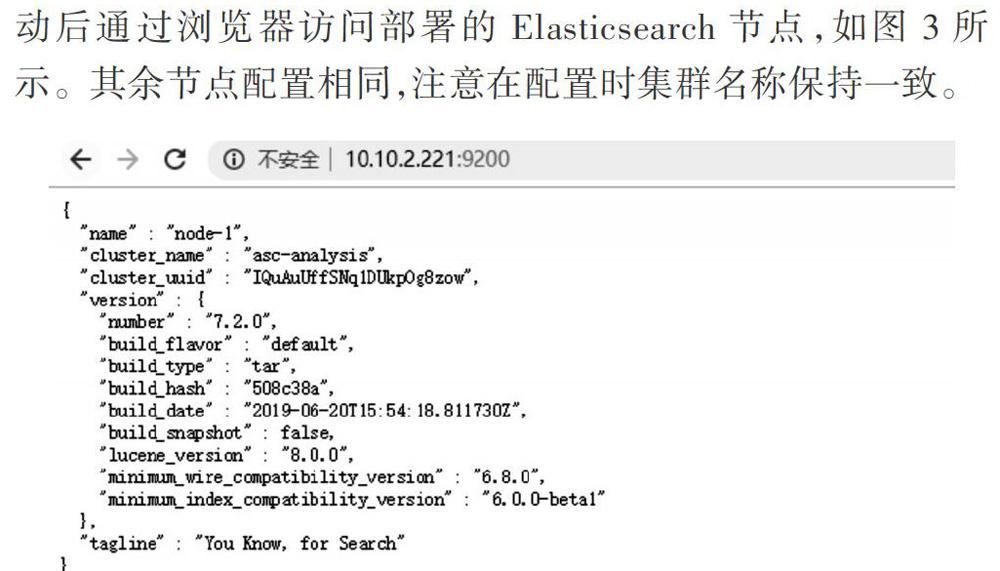
配置完成后使用创建的elk用户启动Elasticsearch,启动后通过浏览器访问部署的Elasticsearch节点,如图3所示。其余节点配置相同,注意在配置时集群名称保持一致。
2.4 Kibana部署
目前,Kibana的最新版本为7.2.0,下载地址为:https://artifacts.elastic.co/downloads/kibana/kibana-7.2.0-1inux-x8664.tar.gz。将Elasticsearch压缩包上传到CentOS 7相应目录下。
通过如下命令进行Logstash压缩包解压,并将解压的目录重新命名,其命令如下:
#tar-zxvf kibana-7.1.1-linux-x86_64.tar.gz
#mv kibana-7.1.1-linux-x86_64/kibana
编辑Kibana的配置文件kibana.yml。其中Server.host是部署Kibana机器的IP地址,服务端口为5601,Elastic.search.url是部署Elasticsearch机器的IP地址。配置完成后通过http:HIP:5601访问。
3 数据可视化展示
Kibana具有多个功能,Discover、可视化、仪表盘是常用的3个功能。Discover对搜索到的数据进行展示并用柱状图表示统计结果。可视化支持柱状图、面体图、饼图、折线图等18种图形创建。仪表盘将创建的可视化聚合在一起,整体反映整个业务或者系统运行情况,且支持任意时间段的数据信息查看。信息技术学院教学云平台业务整体运行情况分析部分截图如图4所示。
4 结语
本文对ELK进行研究与部署应用,实现了Kafka、Elas.ticsearch集群部署并使用Logstash对日志数据进行正则处理,最终在Kibana上绘制图表加以展示。基于ELK的智慧运维大数据分析平台的建立和应用解决了日志采集、日志处理、日志可视化等一系列问题,使得日志实时分析成为可能,为日常运维管理和日志分析提供了新的解决方案。
目前只是对ELK的简单应用,后续将研究ELK的机器学习功能,实现故障发生时间、业务宕机、业务访问突增的预测,并结合移动端实现故障与预警的实时推送。
猜你喜欢
今传媒(2016年9期)2016-10-15
今传媒(2016年9期)2016-10-15
新闻世界(2016年10期)2016-10-11
