
基于K-means的政府公文聚类方法
2020-07-24 02:11王获智李建宏施运梅
软件导刊 2020年6期
关键词:means算法
王获智 李建宏 施运梅


摘要:政府公文数量巨大,不同政府网站公文分类规则不一,在引用和参考公文时可能发生混淆。针对该问题,基于政府公文题目、摘要和正文內容,采用K-means算法对公文进行分类。首先对政府公文进行分词及去停用词等数据预处理操作,再通过词频一逆文档频率(TF-IDF)权值计算方法,将处理后的政府文本信息转换成二维矩阵,然后采用K-means算法进行聚类。使用清华大学THUCTC文本分类系统对公文聚类结果进行测试。实验结果表明,采用K-means算法对公文进行聚类,准确率达到82.93%,远高于政府网站公文分类准确率。
关键词:文本聚类;词频一逆文档频率;K-means算法
DOI:10.11907/rjdk.192257 開放科学(资源服务)标识码(OSID):
中图分类号:TP391文献标识码:A 文章编号:1672-7800(2020)006-0201-04
0 引言
K-means聚类算法最早于1967年被提出,众多学者运用该算法进行了文本聚类技术研究。文献对K-means聚类算法进行了详尽介绍。作为一种无监督学习,该算法可将相似对象归于同一类中;文献从中心点选取、K值确定及参数调优等方面设计了优化方案,为提升算法性能提供了指导意义。K-means聚类算法实际应用范围较广,包括中文文献分类、航空旅客划分、行政省份归类等多个方面。
目前,我国省市级政府均设立了官方网站,政府公文持续上传至官网,数量庞大。由于各政府网站相对独立,各地方政府对政府文件的分类方式有一定差异,因此在参考和引用内容相似的政府公文时可能出现混淆。针对该现象,本文使用文本聚类技术对政府公文进行聚类分析,具体指采用K-means算法对政府公文题目、摘要和正文内容进行聚类分析。首先利用Python实现公文信息获取、数据预处理及文本聚类,然后使用北京市政府官方网站发布的公文作为测试文本,并对聚类结果进行分析。
1 政府文件聚类过程
文本聚类作为一种无监督的机器学习方法,不需要大量训练集,故无需人工为文档添加标签。本文选取聚类算法中的K-means算法,对政府文件进行聚类分析。其过程可概括为3个步骤:数据获取、数据预处理、文本向量化及聚类。
1.1 数据获取
以北京市政府网站发布的公文作为原始数据,使用Python爬虫抓取并保存该网站全部公文。
1.2 数据预处理
Python语言作为一种面向对象的程序语言,受到越来越多的关注,目前已拥有了十分丰富的库。本文利用PY.thon实现文本预处理。首先安装并加载Python的jieba分词工具包。iieba分词工具包是供Python语言使用的一款中文分词组件,使用其中的函数可将文本切分成词或字;接着对切分之后的文本进行去停用词操作。由于在政府公文中存在大量不具有代表性的词语,比如“会议”、“报告”、“通知”等。这些词不仅对聚类没有帮助,还会降低聚类效率。本文参考了文献的停用词表,通过编写PYthon代码,对获取的所有文本进行切词和去停用词操作,处理结果如图1所示。
1.3 文本向量化与聚类
1.3.1 文本向量化
K-means算法依靠向量判断某个样本从属类别。因此,仅通过分词及去停用词处理的政府公文无法直接用于聚类,需对政府公文进行向量化处理。
目前文本向量化主要有两种方法:one-hot表示法与TF-IDF表示法。one-hot表示法首先提取文本中不重复的词语,产生长度为L的词语表,用1个L维的向量表示一篇公文,若第i号词语出现在一篇公文中,则该篇公文的第i维度为1。One-hot表示法仅能表示某个词语是否出现在某篇公文中(出现为l,反之为0),无法描述该词语在该篇公文中出现的频率等信息,而TF-IDF表示法则弥补了这一不足。因此本文中采用TF-IDF表示法进行政府公文向量化处理。
TF-IDF是一种比较常见的统计方法,用于描述某一个词在文档集合之中的重要程度。在一份给定的文件里,词频(Term Frequency,TF)指某个给定的词语在该文件中出现的频率,它是对词数(term count)的归一化,以防止文件偏长。逆向文件频率(Inverse Document Frequency,IDF)是词语普遍重要性的度量。某一特定词语的IDF值可由总文件数目除以包含该词语的文件数目、再将得到的商取对数得到。
高权重的TF-IDF值体现一个词汇在某一特定文件出现频率高,而在整个文件集合中出现频率低。因此,TF-IDF可用于过滤常见词语并保留重要词语。公文TF-IDF计算结果以矩阵方式呈现,如图2所示,图2上半部是从公文中提取的词语,下半部是每个词对应的TF-IDF值。
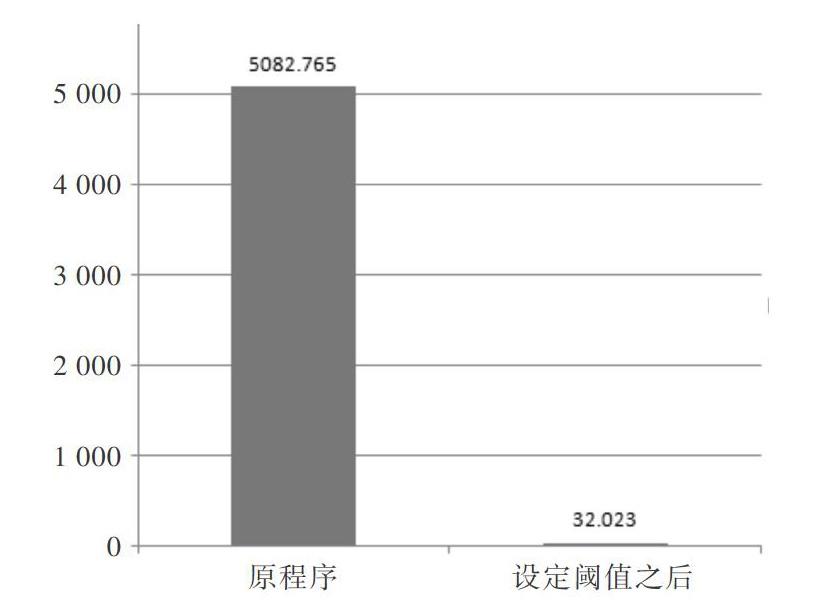
公文越多,提取的词语越多,矩阵维度将急剧上升,而高维度的矩阵将严重拖慢算法运行速度,且在高维空间中,欧式距离的值可能会呈现迅速增长的趋势。因此公文聚类算法准确性和效率均与TF-IDF生成矩阵的维度有关,高维度矩阵会使聚类算法准确性和效率下降,需通过降维改进算法。矩阵高维度现象是由数量巨大的词汇和公文数量引发的,在不能对公文进行删减的情况下,只能设法删减词汇。一种方法是根据文本特性,补充停用词表。比如在北京市政府的公文集合中,“北京市”一词没有聚类意义,可添加到停用词表中。该方法需对文本有一定理解,且补充停用词时耗较大;另一种方法是根据每个词的TF权重和IDF权重,通过设定阈值筛选词语,从而降低矩阵维度。TF为词频,代表词条在某一文档中出现的频率;IDF为逆向文件频率,代表如果包含该词条的文档越少,则IDF越大,说明该词条具有很好的类别区分能力。根据该特性,可设定阈值对词进行筛选,比如删除掉TF低于20%的词,或删除IDF高于80%的词。如图3所示,在设定TF阈值为20%、IDF阈值为80%时,程序占用的CPU时间大幅降低。
1.3.2 公文聚类
K-Means是一种无监督的机器学习算法,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密地连在一起,而让簇间距离尽量大。而在K-means算法中,K值选取极大影响聚类实际效果,为了衡量k值是否恰当,可使用inertia值作为衡量标准。inertia值也称作簇内误差平方和(Within-Cluster Sumof Squared Errors,SSE),是K-means算法中的一种度量聚类效果优劣的数值,一般来说,inertia值越小,说明聚类效果越好。为确定最佳k值,使用手肘法确定K值。实际inertia值会随着k值增加不断减少,但当k值低于最佳值时,inertia值会随着k值增加而急剧下降;当k值大于最佳值时,随着k值增加inertia值不会明显下降。本文根据这种特性,不断调整初始质心数k的取值,并绘制折线图,观察斜率即可得出最佳k值(k=30),如图4所示。
2 聚类结果及测评
2.1 公文聚类结果
本文中采用无监督算法中的K-means聚类算法。随后使用K-means包含的函数将经过预处理的文本向量化,转换成通过TF-IDF权值计算算法生成的二维矩阵。设定初始质心数及最高迭代次数等相关参数后进行聚类,并在聚类完成后显示结果。聚类结果如表1所示,5038篇公文共分为30个类别。
2.2 结果评测
本文借助清华大学的THUCTC(THU Chinese TextClassification)文本分类系统对公文聚类效果进行验证。THUCTC是由清华大学自然语言处理实验室推出的中文文本分类工具包,可自动高效地实现用户自定义文本分类语料训练、评测、分类等功能。对于文本分类而言,有可能出现4种可能性:TP(True Positive),代表该文本预测类别和真实类别均为该类;FP(False Positive),代表文本不屬于该类,但分类器预测其属于该类;TN(True Negative),代表文本属于该类,但分类器预测其不属于该类;FN(False Negative),代表文本不属于该类,分类器同样预测其不属于该类。
准确率P的定义为P=TP/(TP+FP),召回率R的定义为R=TP/(TP+FN)。
准确率和召回率虽可衡量某个类别的分类效果,但难以用于衡量分类器整体分类效果。因此使用微平均值度量分类器性能,微平均可被理解为预测正确的文本个数除以样本总数。对于包含n个样本的集合而言,微平均Micro_F的计算公式如(1)所示。其中,Micro_P为n个样本的TP平均值除以TP平均值与FP平均值之和,Micro_R为11个样本的TP平均值除以TP平均值与FN平均值之和。
北京市政府网站将北京市政府所有文件分为“综合政务”、“国防”及“对外事务”等共计20个类别,不过呈现效果不理想,许多公文从属类别出现了明显错误。使用该网站提供的20个分类中80%的文本作为训练数据,20%作为测试数据,使用清华大学THUCTC系统进行文本分类测试,得到的准确率(P)仅为31%,召回率(R)为25%,微平均值为33%。
针对K-means算法的公文聚类结果,使用THUCTC系统作为评测手段。公文聚类结果包括从0至29共30个类别,使用其中80%作为训练集,20%作为测试集。使用最终训练完成的分类器在测试集上进行测试,准确率达到82.39%,召回率为77.72%,微平均值达到78.13%。实验结果表明采用K-means算法可取得较好的公文聚类效果。
3 结语
本文采用K-means算法进行政府公文聚类,取得了较好的聚类效果。下一步可从以下方面进行改进。首先,本文实验结果并未注明分类完成的公文具体属于何种类别,可通过提取特征词的方式注明类别。在注明类别的基础上可添加其它政府网站的公文继续聚类操作;其次,矩阵高维度仍是限制算法准确性的原因,可参考其它降维策略提升准确性;另外,欧式距离对于高维矩阵十分敏感,可考虑采用余弦距离算法更换欧氏距离。
猜你喜欢
哈尔滨理工大学学报(2017年1期)2017-04-08
商业经济(2017年3期)2017-03-20
哈尔滨理工大学学报(2016年4期)2016-11-10
现代电子技术(2014年8期)2014-09-27
