
在大规模网络中挖掘恶意软件分布
2020-08-07 07:56国家计算机网络应急技术处理协调中心江苏分中心邱凌志顾弘
网络安全和信息化 2020年7期
■ 国家计算机网络应急技术处理协调中心江苏分中心 邱凌志 顾弘
编者按:恶意软件往往能够逃避传统使用黑名单标记或关注终端恶意代码检测的方法。本文提出一种在大规模网络中检测恶意软件分布的方法,聚焦于恶意软件基础设施之间的网络关系,在大规模网络中区分正常和恶意流量,用以发现传统检测方法无法检测到的恶意软件。
恶意软件作为互联网中最严重的网络安全威胁之一,受害主机一旦感染恶意软件,便可能被发送垃圾邮件、进行拒绝服务攻击以及窃取敏感数据。
笔者对超过500 条近半年的互联网公开威胁情报研究发现,恶意软件无论是利用暴力破解各类服务端口方式传播,或者是利用钓鱼邮件方式传播,亦或是利用浏览器漏洞的水坑攻击方式传播,在注入ShellCode 之后,会从服务端下载真正的恶意程序,然后开展挖矿、勒索及窃取信息等恶意行为,包括组成僵尸网络。
Shell Code 通常利用HTTP 请求从远端服务器下载程序,并在本地安装执行恶意软件。这些请求一般通过用户浏览器进行简单的功能调用,从网络角度来说,与用户的正常软件下载请求很难区分。可是,当进入大规模网络,便会发现大量恶意软件通过不同主机下载,而这些恶意主机又均与某一服务端相关,呈现出恶意软件基础设施分布,这种分布与CDN网络有些类似,但仍有不同。
本文提出一种在大规模网络中检测恶意软件分布的方法,该方案聚焦于恶意软件基础设施之间的网络关系,在大规模网络中区分正常和恶意流量,用以发现传统检测方法无法检测到的恶意软件。
方案设计
图1 展现了方案的整体框架和数据流,整个检测过程可以分为3 个阶段:提取阶段、筛选阶段和分析阶段。
1.提取阶段
系统的输入数据为大规模网络中的HTTP 流量。根据ISP 提供的流量数据,每日的HTTP 请求报文数量达到上亿级别,不可能直接检测这一数量级的报文。因此,这一阶段的目的是利用白名单的方法过滤掉大部分非恶意流量。
恶意软件经常修改后缀类型,因此,不能基于HTTP返回报文中的Content-Type字段判断文件类型,而是需要重放HTTP 请求报文,根据下载文件的MIME 字段判断文件的真实类型。结果如在预先制定的白名单范围内,则过滤掉该报文,否则,提取源IP、目的IP、文件Hash 及完整请求URL 等字段生成待检测记录。

图1 方案整体设计
2.筛选阶段
在筛选阶段,方案针对恶意攻击者常用的4 种技术进行检测。
(1)服务端多态。为了躲避检测,恶意攻击者会经常改变服务端恶意文件下载路径,甚至使用不同的域名,这些方式被称为服务端多态。
(2)分布式主机。恶意攻击者为确保恶意服务端有效,通常会使用多个服务端,这种分布式的主机与CDN 网络有些相似。在这里,使用机器学习的分类算法区分正常CDN 与恶意分布式网络。
(3)专用恶意主机。恶意攻击者可能通过重定向技术将受害主机重定向至专用恶意域名,而这些专用恶意域名与正常网页在页面、CSS文件和JavaScript 脚本程序方面有许多不同,系统对此加以区分。
(4)挂马网页。受害主机首先通过浏览器访问恶意网页,被注入ShellCode 后会再次连接恶意服务端,可考虑利用User-Agent 字段识别这样的网络行为。但用户使用不同浏览器访问同一网站或者NAT 网络可能造成误报,对此需要加以区分。
3.分析阶段
基于上述两个阶段筛选出的可疑记录,生成恶意软件基础设施网络分布图,直观展现恶意软件的网络分布。
系统实现
1.过滤预处理
在提取阶段,首先将存储在HDFS 的海量HTTP 流量请求报文检索出来。为了提升下一步重放报文的效率,检索过程同样采用域名白名单的方法。域名白名单的制定由统计平均和经验总结相结合,既包含传统互联网头部企业域名,例如baidu.com、qq.com。也包含新兴流行互联网应用域名,例如yximgs.com、miwifi.com。由此,制定域名白名单Top 100。
第二步,遍历检索出的HTTP 请求报文,如果包含文件下载的请求,则重放该报文。然而,下载文件开销很大,尤其是大文件。幸运的是,可以使用wget 命令只下载文件的前1 KB 大小。此后,通过Linux 的file 命令判断文件类型,file 命令通过文件头判断文件真实类型,而不依据文件后缀。如果命中MIME 白名单(如视频、音频、图片等格式)则舍弃,否则计算文件Hash 值,并提取IP、URL、User-Agent 等字段作为一条记录,进入下面检测阶段。
2.服务端多态检测
第一个检测机制是捕捉恶意软件发布者尝试绕过反病毒软件基于签名检测的行为。检测方法是检索满足如下两个条件的下载记录:相同的URI;下载超过n 个不同的文件,文件依据上一阶段的Hash 值进行区分,n 的取值在实验中将进行评估。实际的例子触发这一检测机制的URI 如/dlq.rar,该URI 有多种域名变化,如www.9530.ca、585872.com。可以看出,发布者不仅重打包恶意软件,而且通过域名变换增加了恶意软件的鲁棒性。
3.分布式主机检测
检测方法分为两个阶段:首先,试图找到CDN;然后,使用一个分类器区分正常CDN与恶意CDN。
第一步,根据文件Hash值将所有记录进行聚类,即当两条下载记录拥有相同 的Hash 值h,而 对 应 的URL 分 别 为u1 和u2 时,将这两条记录关联,形成一个Cluster。如果两个Cluster存在相同的Domain 或服务端IP,则将这两个Cluster合并为一个。系统认为所有的Cluster 至少包含两个记录,否则无法构成CDN 网络。
第二步,使用机器学习的方法在上一阶段的结果中区分正常CDN 与恶意Cluster,检测分布式恶意软件主机。通过对训练集中的数据手工打标签的方式,训练分类器。方案选择随机森林的算法作为分类器,以满足需求。根据对恶意软件基础设施的研究,总结以下6 个分类特征:
域名共存:为了减少开销,恶意软件常常将很多域名放在同一台服务器上,这个特征值等于一个Cluster中所有的域名数/IP 数。
顶级域名数:为了逃避域名黑名单的检测,恶意软件通常会使用一系列不同的顶级域名,正常的CDN 一般使用同一顶级域名下的二级域名。
每个域名上的路径数、文件名数:正常的CDN 考虑用户体验,会有完整的目录结构,而恶意软件则相反。对于上述特征,计算路径数、文件名数/域名数。
自体输血也有禁忌证,以下患者不适合自体输血:采血可能诱发疾病加重者、菌血症患者、贫血、肝肾功能不良或严重心脏病等患者[20]。
每个域名上的URI 数量:恶意软件发布者在每个域名上通常只使用很少的URI 数量,最常见情形是只有一个。对于这一特征,计算集群域名中所有域名的URI 数量/域名数。
文件类型:正常CDN 会提供不同的文件类型供用户下载,而恶意软件服务端提供的最多的是可执行文件。系统计算集群中所有主机的可执行文件数/所有文件数,作为特征指标。
4.专用恶意主机
恶意软件发布者经常使用专用主机隐藏在僵尸网络幕后。这些主机通常只会存放少量的可执行文件,很少有其他类型的文件。正常主机则包含了HTML 页面、CSS 文件以及JavaScript 脚本等等。利用这个特征,可以检测出专用恶意主机。据此,系统发现了112adfdae.tk 这个域名,它被KingMiner 挖矿网络用来传播挖矿程序。
5.挂马网页
观察挂马网页的网络流量行为特征:连续两条请求报文,一条来自浏览器,一条来自ShellCode。因此,系统寻找来自同一源IP,但User-Agent 字段不同的连续HTTP 请求报文。其中,第一个请求的文件类型必须是可执行文件,然而,NAT 环境会对检测产生干扰。对此,可以设定一个请求报文的时间间隔阈值,实际检测过程中设定为1 min,当时间间隔小于这个阈值时,则认为其是恶意软件行为。符合这一策略的是znshuru.com 域名下的setup_pgytg001.exe文件,浏览器下载后会再次下载.dat 格式的恶意文件,User-Agent 字段为NULL。
6.恶意软件基础设施网络分布图
如图2 所示,一个最简单的网络图由8 个节点构成,方案关心以下节点之间的关系:
URL 属于同一完整域名FQDN 或顶级域名Domain;
同一URL 下载的不同文件Hash;
相同URI 或文件名file。
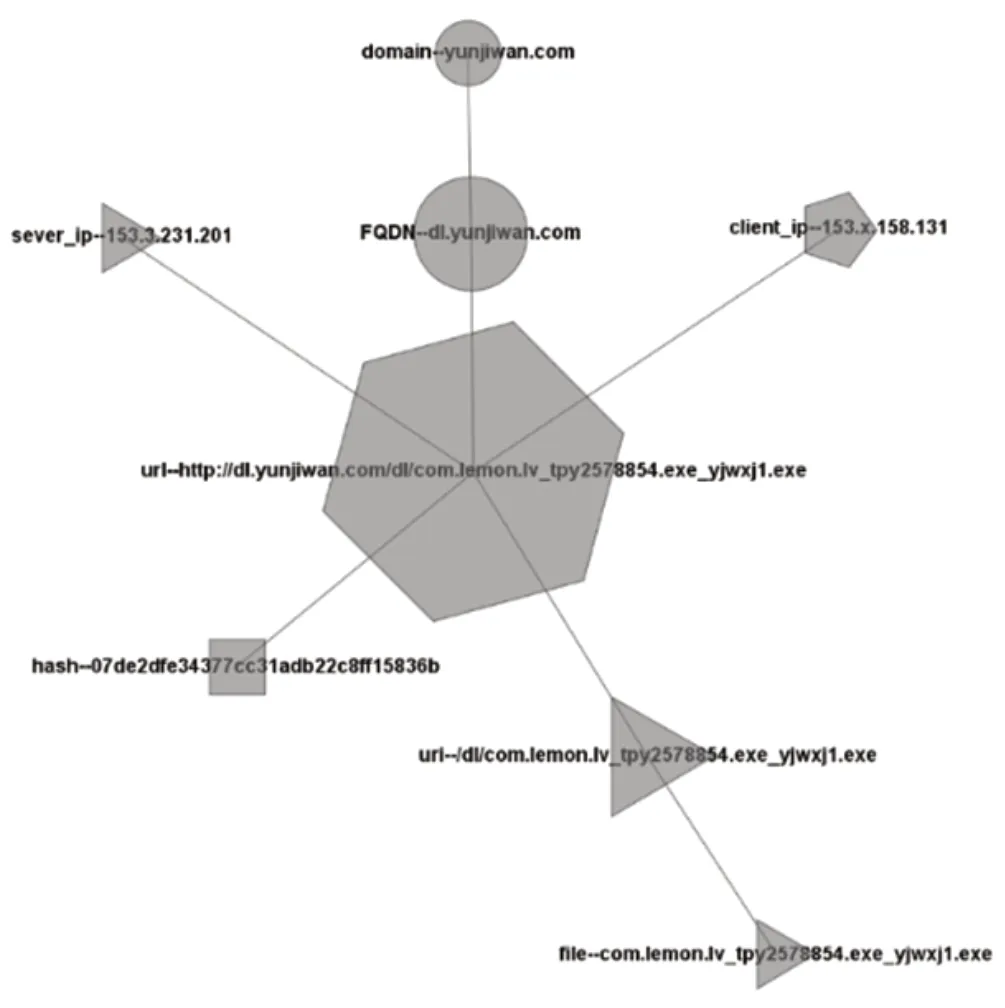
图2 简单恶意软件基础设施网络分布图
开始图中只有一个URL节点,然后添加URL 到各节点的边,当2 条记录存在上述关系时,合并2 条记录。如此迭代,直到图无法增长或达到预先设定的大小(比如800 个节点)。
一旦恶意软件基础设施网络分布图生成,安全分析人员可以直观地看出图中的哪个URL 节点或服务端节点(包括域名、IP)是恶意的。这基于简单的规则:如果节点越孤立,则可能性越低,否则,属于恶意的概率越大。当然,为了量化这一概率,需要先对边赋值:
边url-hash,权重为1;
边url-server,权重为1;
边url-client,权重为4;
其余的边权重均为2。
然后,给出节点j 的恶意概率Pj的计算公式:
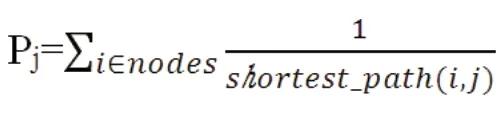
其中,shortest_path(i,j)为节点i 到节点j 的最短加权路径。可以看出,节点距离越近,权重越小,则概率越大。
结果分析
在讨论实验结果之前,需要先明确判断下载文件是否为恶意软件的标准。本文使用VirusTotal检 测URL、域 名 以 及IP,VirusTotal 使用多个反病毒引擎,当有2 个及以上反病毒引擎检测结果为恶意时,判断该对象为恶意的。对于那些VirusTotal 未检测为恶意的可疑对象,通过沙箱结合人工的方式进行验证。
服务端多态:在训练集中,当n 取2 时,检测恶意URL 的数量为55。然而此时,反病毒软件的升级请求数量为423,会造成大量误报,极高的假阳率影响检测。因此,一方面可通过域名白名单对反病毒软件进行过滤,另一方面根据实验结果,取n 为10。改善后,该方法的检测准确率达到93.4%,假阳率仅为6.6%。
分布式主机:实验中使用随机森林作为分类器区分正常CDN 和恶意CDN。在训练集中,初始参数的随机森林成绩仅有0.87 左右,经过参数调整优化,方案对分布式主机的检测准确率达到92.1%。在测试集中,经验证实际的准确率稍有降低,数值为85.2%。
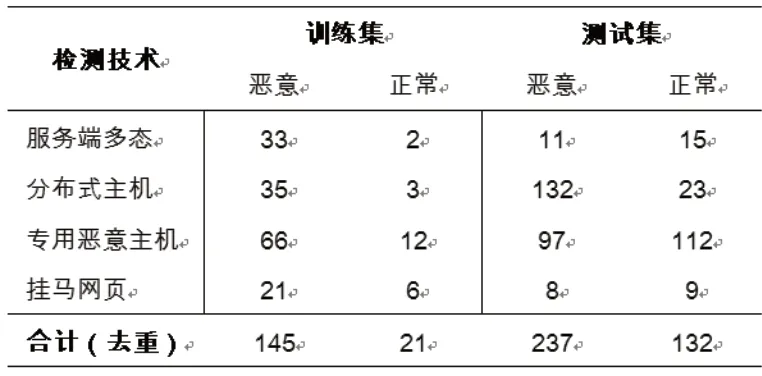
表1 方案整体评估
整体评估:实验中发现专用恶意主机、挂马网页两种检测方法相较前两种方法准确率稍微低一些,这是因为有小部分正常的流量请求也满足检索条件。将4 种检测方法结合,在表1 中给出整体实验结果,评估方案的有效性。
在训练集中,检测结果去重后给出166 条恶意记录。通过验证后,发现其中存在21 条误报,准确率为87.3%。在测试集中,检测结果去重后给出369 条恶意记录,通过验证后,发现其中存在132 条误报,准确率为64.2%。可以看到,随着测试数据的增多,系统准确率也出现了下降。幸运的是,由于恶意软件基础设施变化较快,检测对象为一段时间T 内的流量数据,T 的取值一般为最近一天,最长至最近一周。T 如果时间太长,许多设施便会无法访问。
此外,使用样本集共161条恶意流量数据进行测试,方案共检测出其中108 条,假阴率为32.9%。这是因为,样本集中有一些独立的恶意URL,比如doc、jar 为后缀的,与其他URL 未呈现相关性,方案对此难以识别。不过,传统恶意软件可以通过黑名单的方式检测,方案的目标是辅助传统检测方法,而不是代替它。
最后,在2019 年11 月的测试集中,方案检测到一个恶意域名es.ldbdhm.xyz,它被用作发布众多jpg 后缀的恶意文件,这些文件实际上是可执行pe 文件。可以关注到,2019 年12 月互联网公开了相关威胁情报,它是“紫狐”木马使用的最新恶意域名,这表明了方案的有效性。
生成图统计:图3 展现的一个真实恶意软件基础设施网络分布图,包含14 条检测记录,由于部分节点相同,因此节点数小于14 乘以字段数8,实际共79 个节点。实验中,训练集、测试集中分别生成了30 和66 幅恶意软件基础设施网络分布图,占比最多的为节点数小于50的生成图。节点数小于50的生成图网络关系比较简单甚至无相关性,因此方案的误报也集中在这一区间。

图3 真实的恶意软件基础设施网络分布图
结语
本文提出一种新的在大规模网络中挖掘恶意软件分布的方法,区别于传统恶意软件检测方案,该方案不使用黑名单或终端行为特征检测技术,而是聚焦挖掘恶意软件网络基础设施,辅助发现那些多变化的恶意软件,弥补传统检测方案的不足。
然而,在大规模网络流量中区分正常和恶意报文给检测工作带来挑战。本文使用白名单、机器学习分类技术,结合网络关系可视化,完成了检测方案的设计。笔者实现了方案的原型系统,分别选择真实的2 天HTTP 城域网级别流量作为训练集,7 天城域网级别HTTP 流量作为测试集,对系统进行了评估。
实验表明,系统能够有效检测大规模网络中的恶意软件网络分布关系,以及尚未公布的恶意软件网络基础设施。
猜你喜欢
商品与质量(2020年21期)2020-11-26
电脑爱好者(2020年12期)2020-08-15
江苏教育研究(2020年2期)2020-04-10
中国计算机报(2019年9期)2019-04-23
消费导刊(2018年8期)2018-05-25
智富时代(2017年10期)2017-11-22
智富时代(2017年10期)2017-11-22
中国计算机报(2016年6期)2016-05-14
互联网天地(2012年6期)2012-03-24
