
基于哈希和路网边权的地图匹配算法及其应用
2020-08-12 02:32邵天浩张宏军唐新德
计算机技术与发展 2020年8期
邵天浩,张宏军,程 恺,唐新德,莫 斐,张 可
(陆军工程大学 指挥控制工程学院,江苏 南京 210000)
0 引 言
近年来,随着车载导航的普及率越来越高,海量的车辆行驶数据被导航收集并上传至车联网系统。这些数据可以体现车辆在行驶过程中的各种信息,如经纬度、方位角、GPS速度、行驶里程等。如何从海量的行驶数据中分析出车辆驾驶行为的特征,将数据转化为价值,是当前研究的一个热点问题[1-2]。但是由于车载导航自身的局限性以及数据采集的不稳定性,采集到的行驶数据往往质量不高,这会导致其分析出的结果与实际情况有所偏差。因此,对车辆行驶数据进行有效的预处理以提高其质量,是后续数据分析的重要前提。
通过地图匹配来修正车辆行驶数据是如今最常用的方法,目前地图匹配算法主要有确定性地图匹配算法和不确定性地图匹配算法两种[3]。
确定性地图匹配算法是指匹配的结果是确定而非随机的,主要通过几何方式进行匹配,包括点到点、点到弧、弧到弧三种方式[4]。它考虑了车辆方位角与道路方向的相似性、采样点与道路的距离以及车辆行驶速度等多个方面,将各要素加权之后选择最合适的匹配路段。这类算法原理简单,实现容易,但其稳定性不高,尤其是在选择初始匹配路段时没有进行初步筛选[5],导致匹配的精度下降。
不确定性地图匹配算法是指相同数据点多次匹配的结果是非确定的,依据一定概率进行匹配,主要分为概率统计算法和模糊逻辑算法两种。概率统计算法主要依据采样点信息设置置信区域,利用概率准则来确定需要搜索的道路阈值,在匹配过程中需要通过复杂的数学公式来推导定位误差椭圆,这一方法虽然有较高的匹配精度,但大量的推导使其匹配速度下降[3]。模糊逻辑算法与传统的模糊推理系统类似,通过模糊化、模糊推理机和去模糊化三个部分搭配隶属度函数在推理过程中进行道路匹配,这一算法的实现虽然较概率统计算法来说容易,但其模糊推理机中参数的设定主要依靠专家知识,缺少一定的推理支撑[6]。
总的来说,相对容易实现的匹配算法其匹配精度较低,匹配精度高的算法计算复杂,匹配速度较慢。同时,上述匹配算法均没有提出存在大段异常点时的匹配模式。为了兼顾高效与匹配速度,文中在确定性地图匹配算法的基础上,提出了一种新型地图匹配算法。首先将路网信息以邻接表形式存储,然后通过geohash函数来筛选数据点周围的道路,并添加一个滑动窗口来减小匹配错误率,最后通过修正路网边权来填充空白数据点。该算法实现简单,较传统的地图匹配算法有更高的匹配精度,较概率统计算法和模糊逻辑算法有更快的匹配速度,并且在数据存在大段异常时也能很好工作,匹配结果提高了车辆行驶数据的质量,可以推广到车辆的实时定位。
1 算法的设计与实现
基于哈希函数与路网边权修正的地图匹配算法的具体流程如图1所示[7]。

图1 地图匹配算法流程
主要包括剔除明显异常点、路网信息的获取与存储、数据点与路网匹配、明显异常点填充四个步骤,其中数据点与路网匹配、明显异常点填充又包含相应的子流程。下面分别阐述每个步骤及子流程的设计实现方法。
1.1 剔除明显异常点
由于GPS信号有时候存在不稳定性,车辆行驶数据中包含了大量的漂移数据,这些数据与正常的数据偏差很大,是明显的异常点,首先需要对这样的明显异常点进行剔除。
信号漂移会导致最后一个正常的数据点和第一个异常的数据点之间有较大的经纬度差异,可以根据这一差异对数据集中明显的异常点进行剔除[8]。
已知地表上两点的经纬度,可以得出两点间的最短距离De,如式(1)所示。
De=R·arccos(cosxbcosybcos(ya-xa)+
sinxbsinyb)
(1)
根据两个数据点i、j采集到的经纬度数据,可以求出两个数据点之间的平均速度,并用平均速度代替后一个数据点的瞬时速度,如式(2)所示,其中De为两数据点的经纬度距离。
(2)
若某一数据点i的经纬度速度与GPS速度满足式(3),则认为其是正常数据点,否则将其剔除,选择下一数据点继续判断。
VG<|Vi-VG|×30%
(3)
利用上述过程对明显错误的异常点进行剔除的方式较为粗糙,会留下一些异常点没有剔除干净,但这种方法的好处是可以处理大段的连续异常数据,这是利用隐马尔可夫模型[9]来进行预处理所不能达到的,因为过长的隐马尔可夫链会失去预测的准确性。未被剔除的不太明显异常点可以通过道路匹配的方式来进行修正。同时,针对明显异常点剔除之后的大片缺失数据,可以通过修正路网边权来进行填补。
1.2 路网信息的获取与存储
想要将数据点与道路进行匹配,从而修正数据点的值,首先需要获取路网信息,获取的信息主要包括地图上的每条道路和每个点,以及它们之间的内在联系。
将路网信息中的道路信息和交叉点信息进行提取,分别用ways道路和nodes点来表示,对两者进行简化,留下各自的唯一标识id、经纬度坐标以及其关联关系。最后用邻接表来存储化简之后的信息,邻接表中的顶点对应nodes点,有向边对应两个nodes点之间有一条单向的道路。
式(4)表示邻接表存储的数据结构,其中id表示某一数据点的唯一标识id,该数据点与附近n个数据点相邻;idn表示与该数据点相邻的第n个数据点;widn表示对应两数据点连接而成的道路的唯一标识符id;dn表示对应两数据点之间的距离;an表示对应两数据点连接而成的道路的方位角,以正北方向为基准线。
id:[id1,wid1,d1,a1;…;idn,widn,dn,an]
(4)
需要注意的是,在实际应用中,为了减少搜索空间,会先确定车辆轨迹的经纬度范围矩阵,根据范围矩阵来生成邻接表,从而减少数据点匹配所用时间。
1.3 数据点与道路匹配
剔除了大部分异常点之后行驶数据在地图上表示为多段行驶轨迹,每行驶轨迹之间缺失的数据即是被剔除掉的明显异常点。需要将每段行驶数据进行更进一步的处理,使其具有一定的规律性,处理依据如下:
如果相邻两个数据点之间的采样间隔超过2分钟,则认为两者属于不同的行驶段;如果某一段行驶段的起始点和终点的采样间隔小于2分钟,则抛弃这一行驶段。
对数据分段之后,可以将每个数据点与附近的道路进行匹配,并且修正数据点。可以按照如下步骤来完成,以每个数据点作为基本操作单位:
Step1:利用geohash函数求出每个数据点周围的nodes点,并将找到的nodes点通过其与ways道路的关系连接成线段arc;
Step2:求出数据点与arc线段的距离distance和夹角angle,依据数据点的行驶速度对两者进行加权,求出每个数据点与周围arc线段的匹配值match;
Step3:依照一定的筛选规则,选出与每个数据点最匹配的arc线段,使其与上一数据点匹配的arc线段相连,并修正数据点的属性值;
Step4:对下一个数据点计算Step1,直到该行驶段的数据点计算完为止。
其中Step1~Step3的具体实现过程如下。
1.3.1 筛选数据点周围道路
由于数据点与路网信息的邻接表之间没有直接的关联关系,因此,若需要寻找数据点周围的nodes点是十分困难的,需要遍历整个邻接表,通过计算数据点与nodes点之间的距离来筛选符合条件的nodes点。虽然已经通过范围矩阵将邻接表中的数据进行初选,但逐条计算的方式仍然要耗费大量时间,因此在寻找数据点周围的nodes点时,文中利用了空间搜索算法中的geohash函数。
geohash函数的基本思想是将地球根据经纬度看成一个二维平面,将二维的经纬度转换成字符串编码[10],例如,图2展示了某一地区中9个区域的geohash编码,每一个5位字符串编码代表了一块矩形区域。而不同的编码长度表示不同的范围区间,字符串越长,表示的范围越精确。geohash的前5位编码精度大约在2 km,文中使用的算法需要筛选每个点周围500 m内的nodes点,因此5位geohash编码可以满足条件。

图2 geohash编码示意图
利用geohash函数求出每个nodes点的geohash值,通过字符串匹配的方式,寻找与数据点的geohash值前5位相同的nodes点。需要注意的是,虽然前5位geohash值匹配的精度在2 km,但如果数据点的位置靠近划分矩形的边缘,那么某些距离数据点500 m内的nodes点也不在矩阵内。因此,在经过geohash函数计算之后,还需要基于nodes值对数据进行进一步拓展筛选。对于数据点所在矩阵内的每个nodes点,拓展寻找其500 m范围内的nodes点,寻找的方法是基于给定Limit的深度优先搜索。邻接表的深度优先搜索可以基于栈结构快速进行,当搜索深度大于500 m时即停止该分支的搜索进行回溯。这样就对原有矩阵进行了拓展,保证了原本距离数据点500 m内但不在矩阵内的点也在拓展之后的nodes点内。
最后,遍历所有拓展后得到的nodes点,筛选出数据点500 m范围内的nodes点,并将其依据邻接表的信息进行连接,得到基于ways数据的线段,将其称为arc线段。
1.3.2 计算道路与数据点的匹配度
对于每一个数据点,已经得到其周围500 m范围内的arc线段,对数据点与arc线段之间的距离和夹角进行加权,计算数据点与每个arc线段的匹配值match,该值越大,说明数据点与道路越匹配。两者的距离distance用点到线段的最小距离表示,夹角angle为点的方位角与线段的夹角,两者的值越小,说明数据点与道路越匹配,匹配度应该越高,因此它们之间有负相关的关系。
得到distance与angle之后,首先对其进行归一化,然后利用式(5)计算数据点到每个arc线段的match值[11]:
match=1-[(1-λ)×distance+λ×angle]
(5)
其中,λ表示angle指标的权重,λ的值与数据点的GPS速度有关:当数据点的速度小于1 m/s时λ的值为0,速度大于10 m/s时λ的值为0.5,速度介于两者之间时λ的值按线性从0到0.5增长[12]。假设distance指标的权重永远大于0.5,这是因为本文认为距离指标的重要性大于夹角指标,因为数据点需要选择更相邻的道路进行匹配。
1.3.3 求最佳匹配道路
有了数据点与arc线段的匹配值match,就可以将两者进行匹配,这一过程主要分为三步。
首先,根据distance对arc线段进行初选,依据为arc线段中“highway”属性的值,选出距离数据点100 m内的所有道路,距离数据点200 m内的所有主要道路,距离数据点400 m内的所有干线道路,距离数据点500 m内的所有高速公路。
其次,将初选之后arc线段依match值从大到小排序,选择match值最大的5条arc线段[13],作为最终匹配的候选线段。若需要匹配的数据点为行驶段的起始点,则选择match值最大的那条线段作为匹配的道路;若需要匹配的数据点为非起始点,需要判断5条arc线段是否满足以下两个条件之一[14]:
(1)该arc线段与上一数据点匹配的线段是否重复;
(2)该arc线段与上一数据点匹配的线段是否相连。
若5条arc线段中存在某条线段满足上述两个条件之一,则认为这条线段是与该数据点匹配的arc线段,将其与前一数据点匹配的arc线段相连,将其认为是车辆的真实行驶轨迹。
若不存在arc线段满足上述条件中的任意一个,则计算上一数据点匹配的arc线段尾端点到5条arc线段首端点的最短路径,这一最短路径并非直线最短,而是在邻接表中通过可达边的最短路径。最终选择最短路径最小的arc线段作为该数据点匹配的arc线段,将前一数据点匹配的arc线段经过最短路径上的nodes点与其连接,将其认为是车辆的真实行驶轨迹。
需要注意的是,这一方法的基本思想是贪婪的,即倘若在后期发现某条arc线段完全不符合要求,也无法改变前面的匹配结果。为了避免这种情况,文中在实际求解中利用一个滑动窗口,该窗口保留当前匹配数据点前500 m里程内所有数据点的5条最佳arc线段匹配列表,若发现当前数据点的5条arc线段均无法匹配,则说明匹配出错,应该向前回溯至上个数据点,选择下一条最合适的arc线段重新匹配。
完成数据点与附近的路网信息匹配之后,倘若数据点不在所匹配的道路上,则需要利用投影法[15]对数据点的经纬度信息进行修正,将数据点在道路上的垂足(垂足在arc线段上)或道路中点(垂足不在arc线段上)作为修正的新数据点。
1.4 明显异常点填充
1.3节将数据点与路网信息结合,通过路网信息对异常的数据点进行了有效的修正,但修正的数据点并不包含1.1节中被剔除的明显异常的数据点,这使得修正完之后的数据存在大段缺失,导致在车辆行驶轨迹中存在一定的空白段。
为了填充各个行驶段之间的空白数据,文中提出通过修正路网边权来寻找空白段之间最合适的填补路径,寻找步骤如下:
Step1:寻找空白数据段可能经过的nodes点以及nodes点连接成的ways道路;
Step2:按照“highway”属性修改邻接表中属性“d”的值;
Step3:求出空白段之间的最佳路径;
Step4:依据最佳路径填充空白数据点。
Step1~Step4的实现过程如下:
在填充明显异常点之前,首先选择空白数据段前后两段数据的尾部和头部的nodes点,以前段数据尾部的nodes点为圆心,以1.3.1节中方法来寻找两个nodes点之间距离1.5倍范围内的所有nodes点。将符合条件的所有nodes点仍然以邻接表的形式存储,但必须将两点之间的经纬度距离进行加权。
1.4.1 修改邻接表“d”属性
由于现实中公路的建设并非是两点之间的最短路径,因此在填充两段行驶段之间空白时不能简单地通过寻找最短路径;并且考虑到车辆运输过程中很少会跨越多等级的公路行驶,即从高速公路直接行驶到县区道路的情况是很少的,只有在开头与结尾才会出现,因此可以按照“highway”属性的关系来对邻接表中“d”属性进行修改。
想要对邻接表中的属性“d”进行修改,首先需要知道空白数据前后两段数据点所匹配道路的“highway”属性,若需要加权的ways道路其“highway”属性与前后两段的“highway”属性相同或者相近,则赋予较小的权重,这样在搜索时可以更优先选择这一道路。同时依据需要加权的ways道路中点与前后两段数据点的直线距离,重新分配前后两段数据点对其的权重分配。
根据“highway”属性赋予权重的依据如表1所示。

表1 highway属性权重
表1中第一列表示前后两段数据点所匹配道路的“highway”属性,第一行表示需要加权的ways道路的“highway”属性。根据式(6)重新分配权重方式。
(6)
其中,ω1、ω2表示前后两数据段赋予的权重,d1、d2表示ways道路中点距离前后两数据段端点的直线距离。
图3示例表示了实际中的权重确定方式。

图3 权重修改示意图
图3中空白数据前后两段端点用三角形表示,前段数据匹配的道路属性为motorway,后端数据匹配的道路属性为trunk。上侧虚线ways道路属性为trunk,下侧虚线ways道路属性为primary。上侧虚线中点到前后端点的直线距离分别为2和3;下侧虚线中点到前后端点的直线距离分别为5和1。
若要求图中虚线所示两段道路的权重,结合属性和表1,得出上侧虚线道路的ω1=0.5、ω2=0,又因为d1=2、d2=3,因此求出上侧虚线道路的权重:
同理,上侧虚线道路的ω1=1.0、ω2=0.5,又因为d1=5、d2=1,因此求出上侧虚线道路的权重:
根据上述方式求出每条道路的权重,然后用权重乘以原始数据,即得到修改之后“d”属性内的值d’。
1.4.2 填充异常数据点信息
对邻接表中属性“d”进行加权修改之后,利用传统的Dijkstra算法或者Floyd算法搜索得到空白段之间基于权重的最佳路径。将最佳路径通过的nodes点连接起来,认为是车辆实际的行驶轨迹。
有了车辆的行驶轨迹,仍需要在轨迹上寻找数据采样定位点,最终完成填充空白段之间的数据。将在1.1节中被剔除的所有异常数据点连成一条直线,算出每个异常点在整条直线上的比例,在空白段的相同比例处添加相应数据点,这样保证了重新填充的正常点个数与剔除的异常点个数相等。
对于新添加的数据点,仅存在经度与纬度两个属性的值,需要获取对应原始数据点中的方位角、GPS速度和行驶里程等信息,作为新添加数据点中对应属性的值。
2 实验验证
文中以某公司运输车辆的10份行驶数据作为实验数据集,数据集包括车号、方位角、经纬、纬度、GPS速度和里程6个属性值。
从网站OpenStreetMapnodes上下载开源地图数据,该网站提供的地图数据是以xml格式存储的,将全球的地图数据保存为一个大型的xml文件,并用特定的属性来描述存储的数据。
提取地图数据中属性为“nodes”的节点信息和“ways”的道路信息。“nodes”表示地图上的节点,包括唯一标识符id和经纬度坐标lng与lat,其属性中的“ways”表示该点落于这条道路上;“ways”表示地图上的道路,包括唯一标识符id和道路属性highway,其属性中的“nodes”表示该道路所经过的点。根据式(4)的邻接表存储格式,将“nodes”信息和“ways”信息转化为邻接表存储的一个实例的表示如下:
052:[756,131,128.10,6.67;045,500,244.37,186.81]
其中052表示某一nodes点的id,该nodes点与2个附近nodes点相邻,756和045分别为两个相邻点的id;131和500表示原数据点和两个相邻数据点连接而成的道路的id;128.10和244.37表示原数据点和两个相邻数据点之间的距离;6.67和186.81表示原数据点和两个相邻数据点连接而成的道路的方位角。
以1号车为例,将未经数据预处理的车辆行驶轨迹绘制在图4所示的左侧地图上。
由图4左侧地图可以看出,原始的车辆行驶数据由于具有较多异常点而导致轨迹难以辨认。将剔除明显异常点之后的数据集与道路进行匹配,并且在匹配的过程中修正和填充数据点的值,最终修正完成之后的车辆行驶轨迹如图4右侧地图所示,其中,不同灰度的轨迹表示不同的行驶阶段。

图4 1号车初始行驶轨迹与修正轨迹
可以看出,车辆行驶轨迹与未经数据预处理时比较有了明显的改善,这说明文中的地图匹配算法对车辆行驶数据进行预处理可以取得较好的效果。
文中用匹配时间、匹配率以及匹配完成后数据点剩余比例三个指标来衡量算法的性能[16]。匹配时间指完成数据预处理以及数据点匹配所用总时间;匹配率指数据点匹配到真实行驶道路上的比例;数据点剩余比例指匹配完成后未被当作异常点剔除的数据点占总数据点的比例。
将文中算法、不使用geohash函数与异常点填充的确定性匹配算法以及依据概率统计的不确定性匹配算法分别在10份行驶数据上运行,运行的硬件条件是具有Inter Core i7-7700HQ CUP的个人计算机。实验结果如图5~图7所示。
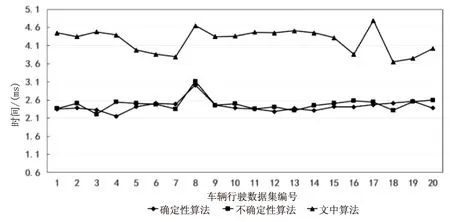
图5 三种算法匹配时间对比

图6 三种算法匹配率对比

图7 三种算法剩余比例对比
图5表示三种算法所使用的匹配时间。可以看出,文中算法所用匹配时间虽然比普通确定性匹配算法略长,但远小于依概率统计的不确定性匹配算法。
图6表示三种算法的匹配率。可以看出,文中算法的匹配率稍高于依概率统计的不确定性匹配算法,远高于普通确定性匹配算法。
图7表示三种算法的数据点剩余比例。可以看出,由于进行了异常数据点填充,文中算法的剩余比例永远是100%,远大于其余两种算法,原因是文中算法对异常数据点进行了按比例填充,将剔除的数据点全部填充回原始数据集。
综上所述,文中使用的基于哈希和路网边权的地图匹配算法综合了效率和准确率两个优点,并且保留了大部分的原始数据。可以满足对车辆行驶数据的预处理,同时也可以推广至车辆的实时定位修正。
3 结束语
依据地图匹配算法对车辆行驶数据进行修正对分析车辆驾驶行为起着至关重要的作用。文中设计的新型地图匹配算法,利用geohash函数筛选数据点附近的道路,并且添加滑动窗口来减小匹配错误率,最后通过对路网边权进行修正来填充缺失数据点。原理易懂,实现简单,并且具有传统确定性地图匹配算法不具有的高准确率和高时效性,不仅能够在很大程度上提高车辆行驶数据的质量,还能应用于车辆行驶过程中的实时定位修正,有很高的可推广性。
目前该地图匹配算法中两处用到了加权法,一处是计算数据点与道路的匹配度,另一处是依据“highway”属性来修改邻接表。但权重的确定对加权法的使用有很大的要求,文中权重的确定主要依靠人为经验,这会导致算法缺乏理论依据,如何确定最佳权重来提高算法的匹配率,将会是未来研究的重点。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
快乐语文(2021年35期)2022-01-18
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
科技资讯(2018年10期)2018-10-26
新课程·中旬(2017年1期)2017-03-27
环球时报(2016-08-01)2016-08-01
旅游纵览(2015年8期)2015-09-25
