
基于Spark的Canopy-FCM在气象中的应用
2020-08-12 02:35勾志竟宫志宏刘布春
计算机技术与发展 2020年8期
勾志竟,宫志宏,徐 梅,刘布春
(1.天津市气象信息中心,天津 300074; 2.天津市气候中心,天津 300074; 3.中国农业科学院 农业环境与可持续发展研究所,北京 100081)
0 引 言
随着科技的进步,气象部门获取数据的途径也越来越多,收集并产生的气象数据呈指数级增长。如何将数据挖掘技术应用到气象预报预测和气象灾害预测等方面[1-3],从海量的气象数据中挖掘有价值的信息,成为气象行业研究的重点。传统的数据处理方法已经不能很好地处理海量数据,挖掘数据内部规律时更为乏力,而数据挖掘算法与分布式处理框架[4]的出现为挖掘海量气象数据提供了一种新的思路。
陈正威[5]在Hadoop平台上运用预处理有向无环图和支持向量机(PDAG-SVM)算法对降水量做出预测,该方法在预测精度和预测效率上都取得了令人满意的结果;王昊等[6]提出了一种Hadoop平台下基于离散贝叶斯网络的数据挖掘改进算法,预测精度明显高于目前短期气候预测中采用的朴素贝叶斯算法;张晨阳等[7]提出基于Hadoop的计算等价类的数据约简算法与朴素贝叶斯分类算法,该并行数据挖掘方案可以有效处理海量气象数据,并具有良好的扩展性;Lv Zhenhua等[8]提出了并行K-means算法,并用于遥感图像的分类;李莉等[9]基于Spark平台提出并行K-means算法对气候区进行划分,对气象领域研究有重要现实意义。
从目前的相关研究可以看出,学者们不断对海量数据挖掘方法进行研究和优化,而聚类算法作为数据挖掘的重要方法,将其与分布式处理框架相结合[10-12]处理海量数据成为数据挖掘领域越来越活跃的研究方向。文中提出了一种Canopy-FCM算法,可以有效避免模糊C-均值聚类算法对初始聚类中心敏感的问题,同时针对海量气象数据,采用Spark内存计算分布式框架快速有效地从气象数据中挖掘出有用的信息,大大的提高了运行效率。
1 模糊C均值算法(FCM)
模糊C均值(fuzzy C-means,FCM)算法[13]是1974年由Dunn提出并由Bezdek推广的,它是基于模糊集合论,把聚类问题转化为非线性规划问题,并通过迭代求解。
令X={X1,X2,…,Xn}为待分类样本,FCM将其分为c个模糊组,使得目标函数值最小,目标函数如下所示:

(1)
(2)
其中,uij是样本j属于类i的隶属度,Ci为第i类的中心,m∈[1,∞]为模糊因子。
通过式(2),采用拉格朗日乘数法构造以下目标函数:
(3)
对所有参数求导,得到使式(3)达到最小值的必要条件为:
(4)
(5)
由式(4)和式(5)可以知道,给定初始样本集合X,以及分类数目c和模糊因子m,FCM算法按照以下步骤不断迭代就可以计算出隶属度矩阵U和聚类中心C。
(1)用随机数生成器生成初始隶属度矩阵U,且满足约束条件式(2)。
(2)用式(4)更新聚类中心。
(3)用式(5)更新隶属度矩阵U。
(4)计算式(1)的目标函数值,如果小于阈值ε,则算法停止,否则重复步骤(2)和(3)。
2 Canopy-FCM算法设计
2.1 Canopy算法
FCM算法采用随机生成聚类中心的方法,但无法保证为每个分类找到较好的中心,而聚类中心直接影响算法的运行效率。针对初始中心敏感,容易陷入局部最优的问题,文中采用Canopy算法[14]初始化聚类中心。Canopy算法可以很快得到最优的分类数,其具体步骤如下:
(1)给定样本X1,X2,…,Xn,设定初始阈值T1,T2,T1>T2。
(2)在样本中随机挑选样本x,计算x到其他样本点的距离d。
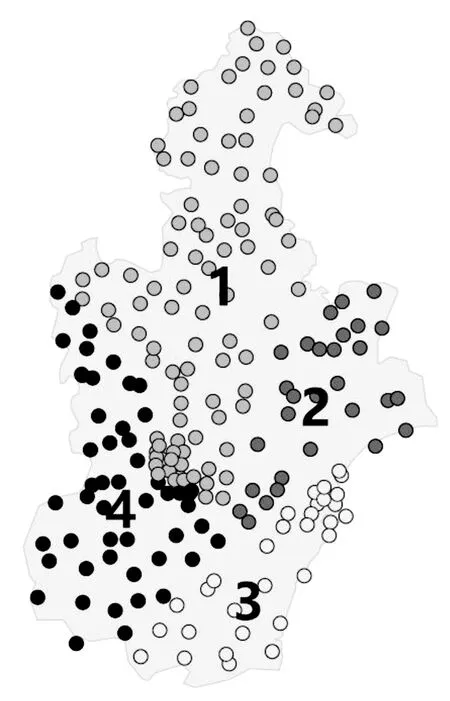
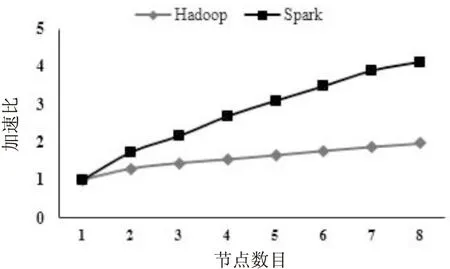
(3)把d (4)重复步骤2、3,直到数据集为空。 Canopy-FCM算法基本步骤如下: Step1:利用Canopy算法生成初始聚类中心。 Step2:初始化隶属度矩阵U。 Step3:更新聚类中心C。 Step4:更新隶属度矩阵U。 Step5:是否满足终止条件,若满足,则算法停止;否则,重复Step3和Step4。 Spark是基于内存计算的分布式计算框架,起源于加利福尼亚大学伯克利分校的实验室研究项目[15],其低延迟、低系统开销、容错性高、分布式数据结构以及强大的函数式编程接口可以很好应对迭代式计算应用的高性能需求,在大规模数据处理任务中有广泛的应用。 Spark在分布式环境下采用主从结构模型,包括Driver和Worker节点,程序运行之前将数据存储在Hadoop Distributed File System(HDFS)中,接着Driver会运行应用中的方法创建SparkContext以及RDD,DAGScheduler对象将每个job分成多个Stage,并为每个stage创建TaskSet,TaskScheduler将task提交给executor执行,executor调用Taskrunner封装task,并行线程池中取一个线程执行task。其架构如图1所示。 图1 Spark架构 基于Spark的Canopy-FCM算法流程如图2所示。 图2 基于Spark的Canopy-FCM算法流程 (1)配置好Spark运行环境并初始化各参数。通过hadoop fs -put命令将数据上传到HDFS上,调用SparkContext的sc.textFile()方法将数据转换为Spark-RDD,通过map操作转换为向量缓存到内存中。 当我们在进行股票运作时,追求的是绩优股,当我们在购买房产时,追求的是未来的黄金地段,同样,国有企业在进行经营时所追求的就是绩优股、黄金地段,就是资产的良性发展。油田企业作为国有企业的一员,就是要维护国有资产安全,保障企业可持续发展。从当前企业审计的要求来看,质量和责任是企业审计的基础,绩效是企业审计的方向和目标,就是要发现企业是否成为了蓝筹股,把投入产出比例如何作为国有资产的组成部分,油田企业的绩效审计越来越被重视,它进一步扩展和深化了油田企业审计的内涵。 (2)在各个子节点通过map操作计算数据集中每个点到Canopy中心点的欧氏距离,进而得到局部的Canopy中心点,然后通过reduce操作得到全局的Canopy中心点,将其作为FCM的初始聚类中心,并广播给各个子节点。 (3)在各个子节点通过map操作计算每个数据点到各中心的欧氏距离和隶属度,然后通过reduceByKey()和collectAsMap()方法得到各数据点到每个分类的距离之和与隶属度之和,对隶属度和聚类中心进行更新。 (4)计算目标函数的值,判断结果是否收敛,如果收敛则算法结束,通过Combine操作合并中间结果,并通过Reduce操作得到全局聚类中心,否则重复步骤(3)。 Canopy-FCM算法并行化[16]的伪代码如下: Input:X={X1,X2,…,Xn},T1,T2,m,K Output:C={C1,C2,…,Cc} Initialization(); l←data.mapPartitions{points⟹ forxi←points{ }.reduce(merge) C'←C;C←null forj=1 toC{ (sumUX,sumU)←l(j) C+=sumUX/sumU } } 实验采用Spark分布式集群,集群搭建在服务器虚拟化平台上,选取1台机器作为主节点,其他7台机器作为工作节点。虚拟机各项配置及集群的配置信息分别如表1、表2所示,实验数据采用天津经过质控后的208个区域自动气象站4~10月夏半年逐月降水观测数据。 表1 虚拟机配置信息 由表2可以看出Spark分布式集群在运行时需要一系列的后台程序,主要有: Master-负责资源的调度(决定在哪些Worker上执行executor)和监控Worker。 Worker-负责执行任务的进程(executor),并将当前机器的信息通过心跳汇报给Master。 NameNode-负责管理文件系统的Namespace。 DataNode-负责管理各个存储节点。 SecondaryNameNode-NameNode的热备,负责周期性地合并Namespace image和Edit log。 表2 集群信息配置 实验结果如图3所示,由图3可以看出天津208个区域自动气象站降水分布可分为4个区域,1区主要集中在中部和北部区域,共有96个站;2区集中在东部区域,共有29个站;3区集中在东南部,共有31个站;4区主要集中在西南部,共有52个站。 图3 天津降水区划图 图4是实验得到的天津市4个分区降水量年平均分布图,由图4可以看出,4个分区的降水主要集中在6~9月,7月降水量最为显著,其次是8月、6月、9月,这一趋势与中国气象局气象数据中心发布的天津气候类型图(1981-2010)一致。4个分区的具体分析如下: 图4 天津市4个分区降水量年平均分布 1区主要位于天津中部和北部区域,该区域土壤以盐化潮土和粘质土为主,5月年平均降水量远低于其他分区,4~10月总年平均降水量485.7 mm。 2区主要位于天津的东部区域,属于海积、冲积平原区,地势北高南低,4月、7月、10月年平均降水量高于其他三个分区,6月年平均降水量远低于其他分区,4~10月总年平均降水量498.1 mm。 3区主要位于天津市的东南沿海地区,地势低平,以海积低平原为主,土层受海潮影响盐渍化比较严重,5月、8月、9月年平均降水量远高于其他三个分区,4~10月总年平均降水量508.1 mm。 4区主要位于天津的西南部,该区域以洼地冲积平原和滨海平原为主,地形平坦但多洼地,地势南高北低,西高东低,4月、7月、8月、9月及10月年平均降水量均低于其他分区,4~10月总年平均降水量425.2 mm。 为了对比文中设计的Spark平台和Hadoop平台的集群性能,分别在Hadoop环境下和Spark环境下由单节点到8节点执行相同大小的区域自动站降水数据文件,得到两种环境下的加速比,如图5所示。 图5 Hadoop平台和Spark平台的加速比 由图5不难看出,当节点数目为单节点时,Hadoop平台和Spark平台的性能都处于最差。随着DataNode节点数量的增加,Spark平台和Hadoop平台算法的运行时间都有不同程度缩短,而Spark平台的加速比要优于Hadoop平台,说明文中提出的算法在Spark平台下能有效地提高算法的性能,及时准确地挖掘出海量气象数据的有价值信息。 针对模糊C-均值聚类算法对初始聚类中心敏感及因迭代计算次数增加导致内存不足的问题,设计了一种基于Spark框架的Canopy-FCM并行化聚类算法。该算法结合Canopy算法与模糊C-均值聚类算法,避免了FCM算法对初始化敏感的问题,并结合Spark分布式框架内存计算的优势,大大降低了海量气象数据的处理时间。通过采用天津市208个区域自动气象站4~10月逐月降水观测数据,评估了天津市不同区域的降水情况。实验结果表明,提出的方法不仅可以快速有效地从气象数据中挖掘出有用的信息,同时还有良好的扩展性,能够为相关部门做好抗旱救灾、防灾救灾工作提供一种全新的思路和方法。但方法仅针对降水区进行了划分,未来可以结合温度、湿度、干燥度等因素做进一步的气候区划研究。2.2 Canopy-FCM算法框架
3 基于Spark的并行Canopy-FCM模型
3.1 Spark计算模型

3.2 Canopy-FCM算法的并行化

4 实例分析
4.1 实验环境与数据集


4.2 实验结果及分析

5 结束语
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
电气技术(2022年8期)2022-08-20
成都信息工程大学学报(2022年3期)2022-07-21
北京航空航天大学学报(2022年6期)2022-07-02
导航定位学报(2022年2期)2022-04-11
今日农业(2021年17期)2021-11-26
现代农业科技(2019年22期)2019-12-25
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
当代陕西(2019年14期)2019-08-26
现代农业科技(2017年16期)2017-09-22
