
DBSCAN聚类处理的改进蚁群算法在车辆路径问题中的应用
2020-08-19 06:47徐书扬俞鸿烽潘华铮张宇来
电脑知识与技术 2020年19期
关键词:蚁群算法
徐书扬 俞鸿烽 潘华铮 张宇来


摘要:传统的蚁群算法在求解车辆路径问题时迭代速度较慢,且求解精度较低,易陷入局部最优。针对这些问题,利用DB-SCAN聚类算法对车辆路径问题中的各个物料配送点进行聚类划分,并根据聚类划分的情况对蚁群算法中的信息素矩阵合理初始化,实现对蚁群算法的改进,使得改进后的蚁群算法能有更高的求解精度和更快的收敛速度。通过MAT-LAB2019A对实验结果进行仿真测试,并与其他算法橫向对比,可得改进后的蚁群算法在求解辆路径问题时有着更高的求解精度和更快的收敛速度,特别是在配送点分布相对密集和各配送点需求量较小时有着明显的效果。
关键词:蚁群算法;DBSCAN聚类算法;车辆路径问题
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2020)19-0182-05
开放科学(资源服务)标识码cOSID):
1 概述
随着互联网科技的不断完善,人们越来越多的选择通过网上购物来满足自己的购买需求。因此合理的物流方案设计,也成为物流配送中的难点与焦点。早在1959年,Dantzig和Rems-er提出了车辆路径问题(Vehicle Routine Problem)[1],将复杂的物流问题抽象成了图论问题供学者研究,该问题的优化目标为货车在载重有限的情况下如何规划路径使得完成货物配送所经过的路程长度最短。VRP问题属于NP问题,随着所要配送的点数增多,用精确算法求解会导致计算量过大,因此精确算法求解VRP问题并不适用。1986年,Solomon首次提出用启发式算法来求解VRP问题[2],研究发现,启发式算法能在保证一定的求解精度的情况下有着较小的算法复杂度,因此更适用于VRP问题的求解。1999年,Dorigo和Gamberdella首次提出利用启发式算法中的一种:蚁群算法来求解VRP问题[3-4],由于蚁群算法本身具有良好的鲁棒性和较高的求解精度,国内外学者开始尝试利用改进的蚁群算法或是相关的混合算法来求解VRP问题,例如,赵群在文献[5]中提出利用蚁群算法和遗传算法的混合算法求解VRP问题;刘春英在文献[6]中提出利用粒子群算法和蚁群算法的混合算法求解VRP问题;石华踽在文献[7]中将车辆转移规则应用到算法中使算法具有更强的应用;郑文艳在文献[8]中更改了信息素更新方式和可行解构造以提高算法的求解精度。
此外Dhawan C.Kumar Nassa V在文献[9]中总结了前人的研究,在蚁群算法解决VRP问题上做了总结,比对了各代改进算法的优缺点,为今后的研究做了导向。M artin等人对DB-SCAN算法进行了简单的阐述[10],该算法能在具有噪声的空间数据库中发现任意形状的簇,可将密度足够大的相邻区域连接,能有效处理异常数据,主要用于对空间数据的聚类。作为一种知名的聚类算法,BDSCAN算法广泛地应用于各个领域,例如无线电技术[11],复杂环境监测[12]屏常数据处理[13]等.在物流管理问题中也有着应用,张洪奉在文献[14]中提出了利用BDSCAN算法的改进算法来设计物流信息管理系统。前人对于蚁群算法求解VRP问题的改进有着明显的效果,但是都未考虑到信息素矩阵的合理初始化对于算法收敛的导向作用。本文对传统的蚁群算法进行改进,通过BDSCAN算法将VRP问题中的各个物料配送点进行划分聚类,并以此作为信息素矩阵初始化的依据,使得初始信息素矩阵对算法的收敛有导向作用,让算法有着更高的求解精度和更快的收敛速度。
2 背景知识和算法描述
2.1 VRP问题
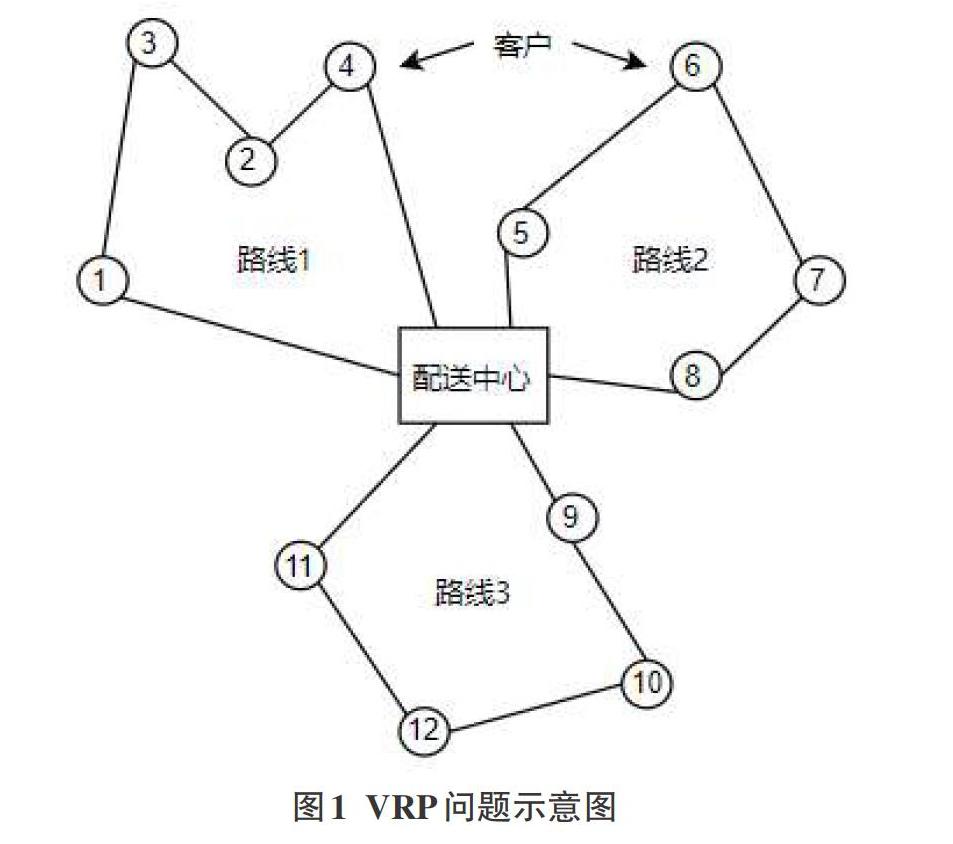
Dantzig和Remser提出了车辆路径问题(Vehicle RoutineProblem,简称VRP),它是运筹学重要的研究问题之一。VRP问题关注一个供货商与k个销售点的路径规划的情况。该问题可以简述为:给定配送中心、一个车辆集合和一个顾客集合,车辆运载能力和顾客需求量已知,每辆车都从配送中心出发,完成运送任务后重新返回配送中心,目标是在特定的约束条件下满足客户需求并且使得成本最小化,配送订单最大化,满载率最大化。图形表示如下:
2.2 蚁群算法
蚁群算法(Ant Colony Algorithm,AC)由Dorigo和Gam-berdella首次提出,该算法能够模拟自然界中蚂蚁的觅食行为。昆虫学家们发现蚂蚁在行走过程中能够释放用来标识自己行走路径的称为“信息素”的物质,路径长远可以通过信息素浓度大小表示,信息素浓度越高,对应的路径越短。该算法的其基本思路为:将蚂蚁的行走路径作为待优化问题的可行解,整个蚂蚁群体的所有路径构成待优化问题的解空间。路径较短的蚂蚁所释放的信息素量较多,随着时间的推进,较短的路径上累积的信息素浓度逐渐提高,选择该路径的蚂蚁也随之越来越多。最终,整个蚂蚁群体通过信息素交换路径信息在正反馈的作用下集中到最佳路径上,该路径对应的就是待优化问题的最优解。
蚁群算法流程如下:
(1)初始化参数
对相关参数进行初始化,如蚂蚁数量m、信息素重要程度因子a、启发函数重要程度因子6、信息素挥发因子a、路径信息素常量Q、最大迭代次数iter max、迭代次数初值iter=1。
(2)构建解空间
将各个蚂蚁放于不同出发点,对每个蚂蚁根据概率公式计算其下一个访问城市,直到遍历完所有城市。
(3)更新信息素
计算各个蚂蚁经过的路径长度,记录当前迭代次数中的最优解(最短路径),同时进行信息素浓度的更新。
(4)判断是否终止
如果iter< iter max,则令iter= iter+1,清空蚂蚁经过路径的记录表,返回步骤二;否则,终止计算,输出最优解。
2.3 DBSCAN密度聚类算法
聚类分析属于无监督学习,DBSCAN( Density-Based Spa-tial Clustering of Applications with Noise)是一种典型的基于密度的聚类算法,这类聚类算法一般假定类别可以通过样本分布的精密程度决定,同一类别的样本,在该类别任意样本周围不远处一定有同类别样本存在。将这些紧密相连的样本划分为一类,就可以得到一个聚类类别。通过将所有各组紧密相连的样本划为各个不同的类别,就可以得到最终的所有聚类类别结果。DBSCAN算法可以将数据点分为三类:1、核心点:在半径Eps内含有超过MinPts数目的点。2、边界点:在半径Eps内点的数量小于MinPts,但是落在核心点的邻域内的点。3、噪音点:既不是核心点也不是边界点的点。
03-opt算法的具体流程如下:
Stepl:按图(2)所示从路径中删除3条边,从别的部分加入三条边使得路径保持完整。判断路径的交换是否能让路径总长度变短,若能,则交换;若不能,则不交换。
Step2:重复执行Stepl,直到遍历完成所有的可能情况后输出结果。
相较于其他opt算法,圖(2)中除了交换的各个边之外,所有的曲线段的方向在交换后都未发生变化,这样极大地减少了检查可行路径的工作量,使得该算法在嵌入到蚁群算法中后整体的算法时间复杂度并未发生明显变化[15]。
3 改进算法的设计
3.1改进DBSCAN算法邻域半径计算
标准DBSCAN算法中,邻域半径为常数,且点与点之间的边权重为点与点之间的距离。而在车辆路径问题中,每个物料配送点具有各不相同的物料配送需求量,在邻域半径的计算中合理考虑每个物料配送点的需求量可以使得聚类划分的结果更合理。当物料配送需求量较大时,在单次配送中消耗了车辆更多的物料,根据贪心法则,优先考虑将物料配送至物料配送需求量大的物料配送点可以提高单次配送中卡车的物料装载空间利用率,因此,对于物料配送需求量大的配送点,需要适当增加其邻域半径,使其更易被划分为核心点,具体数学表达式如下:
3.2 改进蚁群算法信息素初始化方案
传统蚁群算法中,各条路径上初始信息素浓度相等,这意味着初始信息素分布对算法的收敛不具备导向作用,这也是传统蚁群算法收敛速度慢,易陷入局部最优的一个重要原因[16]。为了使得初始信息素分布能够对算法具有合理的导向性,可以通过聚类的划分区分各个配送点的相对位置[17],并据此生成聚类,在同一聚类中的各点通过Kruskal算法生成最小生成树,在所生成的最小生成树中的各条路径中初始化信息素,具体表达式如下:
3.3 基于03-opt算法的局部优化方案
在VRP问题的讨论中,通常将会存在诸多从配送中心出发完成配送任务后回到起点的子路径,例如在本文图(1)所示范例中就存在3条子路径:1-3-2-4,5-6-7-8,9-10-11-12。为使得算法能有更高的求解精度,在每一次蚁群算法迭代完成后对每一条子路径进行03-opt局部优化,从而更好地探寻更优解。
3.4 改进算法流程图
4 实验内容及结果分析
4.1 算例及初始数据
为验证算法的有效性,选取一个物流配送的实例情况对问题进行讨论。该实例选取(70,40)作为供货点,各个配送点的相关信息如表1所示,各个基本参数的设置值如表2所示:
其中,p表示信息素挥发参数,N_表示算法运行迭代最大限制次数,表示蚂蚁循环一周释放的信息素总量,m表示蚂蚁数,τ0表示不同簇上点之间的信息素初始参数值,τ1表示相同簇上核心点之间的信息素初始参数值,τ2示相同簇上非核心点之间的信息素初始参数值,CAP表示火车最大载重量。
4.2 仿真测试与结果分析
首先通过DBSCAN算法对配送点进行聚类划分成各个不同的簇,接着对各个簇利用Kruskal生成最小生成树,结果如图3所示:
DBSCAN算法的应用成功将各个配送点划分在不同的簇中,并在簇中生成了最小生成树。根据本文2.4部分的内容对蚁群算法中的初始信息素矩阵进行更新。之后分别用本文改进后的算法,传统蚁群算法,传统粒子群算法和文献[14]提出的算法通过MATLAB2019A对实例进行1000次仿真测试,并将结果每种算法的1000次仿真测试结果求其均值后观察每种算法的求解精度与收敛速度。为了更好地衡量算法的收敛速度,这里做如下定义:
当算法得到最佳求解结果时说需要的最少迭代次数值为算法的最佳迭代点。
程序运行结果如表3所示:
1)本文算法;
2)传统蚁群算法;
3)传统粒子群算法;
4)文献[8]提出的算法。
由表3可知,本文所提出的算法在求解该实例时所规划的路径相较于其他算法更短,并且有着更小的最佳迭代点,由此可以验证无论在求解精度还是收敛速度上相较于其他算法都有着明显的优势。由此可以验证,本文所提出的算法有着较高的求解精度,在求解VRP问题时为货车制定的路径相较于其他算法更短,为货运公司节省更多的时间和成本;同时本文算法也有着更快的收敛速度,在解决实际问题时能够以较小的计算量解决问题,使得方法的应用更快捷,占用更少的时间。
5 结束语
本文通过DBSCAN聚类算法对蚁群算法的初始信息素矩阵进行更新,使得初始信息素分布对算法的合理收敛有着良好的导向性从而得到更精确的结果和更快的收敛速度。然而,本文对于同一簇中的配送点间的信息素的初始化值设定为自定义参数,因此该自定义参数值的选取会对结果产生较大的影响,如果该值过大,则算法收敛速度过快,容易陷入局部最优而影响求解精度;如果该值过小,则算法中初始信息素分布对算法的收敛缺乏良好的导向性,使得收敛速度较慢,且求解精度相对不高,相较于传统蚁群算法没有明显的优势。此外值得一提的是,算法本身的参数值也会影响算法的求解效果,例如在配送点分布相对较为分散时,DBSCAN算法对于簇的分类效果较差,导致求解精度相较于传统蚁群算法的提高并不明显;在配送点需求量较大时,同一簇的配送点需要货车多次运输,则本文算法易在迭代初期陷入局部最优。总之,相较于其他算法本文算法对VRP问题的求解有着明显的优势,但是依旧存在可改进空间,在之后的研究中,如何确定相关基本参数以及如何选择性地对同一簇内点间的信息素进行更新成为重点和难点。
参考文献:
[1] Toth P, Vigo D. Vehicle routing Problems,
