
基于双重模糊模拟的直觉模糊向量关联规则挖掘
2020-08-21 02:14樊蓓蓓陈东萍
计算机集成制造系统 2020年7期
陈 通,樊蓓蓓+,陈东萍
(1.上海大学 机电学院,上海 200444;2.临沂大学 物流学院,山东 临沂 276000)
0 引言
关联规则是决策系统中表达经验和知识的一种常用方式[1-2],可以辅助决策者做出有效判断。关联规则挖掘是从现有设计案例中获取关联规则的过程,是决策领域研究的热点之一[3-4],现有文献从算法效率[5]、挖掘规则表示[6]、划分[7]、增量式更新[8]等不同角度对关联规则挖掘方法进行研究。考虑到决策数据的模糊性,章武媚等[9]、沈海澜等[10]、王飞等[11]将模糊集理论融入数据挖掘,研究了模糊关联规则挖掘方法。通过隶属度函数模糊集合可以表达自然语言边界的模糊不确定性,但无法表达决策者做出判断时的犹豫不确定性,Atanassov[12]提出的直觉模糊集合(Intuitionistic Fuzzy Sets, IFS),将只考虑隶属度的模糊集理论推广为同时考虑隶属度、非隶属度和犹豫度3方面信息的直觉模糊集,反映了决策者评价时表现出肯定、否定和犹豫的思维习惯。在实际决策问题中,受客观环境复杂性、决策者知识结构和专业水平以及时间等诸多因素的影响,决策者的判断往往存在一定的犹豫度或表现出一定程度的知识缺乏[13-14],例如观众对电影评价时,惯于采用“轻松”、“感人”、“清新”等自然语言。一部电影是否轻松并非绝对,模糊集可以表达“轻松”这个词的模糊边界,但观众对电影作出“轻松”的判断时可能会有一定程度的犹豫,有些观众是肯定的,有些观众是犹豫的。此时,采用直觉模糊集来表达决策者的观点比用实数和传统模糊数更为全面、细致和直观,直觉模糊集理论已经引起决策[15]、逻辑规划[16]、医疗诊断[17]、机器学习[18]等众多领域内学者的高度重视。南江霞等[16]指出,由于环境和条件的不确定性、信息的不完整性以及经济、政治、心理行为和意识形态等复杂因素,使得局中人对于是否参与联盟存在一定程度的犹豫,因此引入直觉模糊集建立联盟合作博弈的非线性规划模型。为了处理不完全定义的事实和数据以及不精确的知识,文献[17]基于模糊集的隶属度和非隶属度的交集和联合,提出直觉交叉熵的定义,并说明了模糊交叉熵在模式识别和医学诊断中的应用,将直觉模糊集引入关联规则,挖掘具有较高的实际应用价值。虽然直觉模糊集可以更全面地描述决策者的主观判断,在处理不确定信息时具有更强的表现能力[19-20],但现有关联规则挖掘研究中较少考虑直觉模糊集关联规则挖掘的问题。此外,评价对象的属性具有多维度的特性,如从题材、效果、情感等几个属性对电影进行评价,而每个属性又可以从多个维度去描述,情感是{悲怆,忧伤,欢快,恬淡,热情}。因此,本文采用直觉模糊向量表达原始决策表的数据。在解决直觉模糊向量关联规则挖掘的过程中,面临两个难点:一是原始决策表的基本元素为向量,增加了规则前件、后件的维度,导致挖掘算法计算复杂度增大;二是挖掘算法中使用的规则支持度和置信度是对事务数据特性的度量,无法集成直觉模糊集中决策者的犹豫度,导致规则挖掘无法考虑决策者主观性。
为解决以上问题,本文提出了基于双重模糊模拟的直觉模糊向量关联规则挖掘方法。一方面,构建了双层关联规则挖掘方法框架,首先对多维向量的项进行关联规则挖掘,降低项的维度,再对降维后的决策表进行关联规则挖掘,降低了算法的计算复杂度;另一方面,引入双重模糊变量表达直觉模糊集的隶属度和犹豫度,并以双重模糊变量的期望值估算规则的支持度,解决了传统模糊关联规则挖掘无法考虑决策者主观性的问题。
1 预备知识
本文研究的直觉模糊向量关联规则挖掘方法,是将传统模糊关联规则挖掘方法中原始决策表里的模糊集替换为直觉模糊向量(由直觉模糊集构成)。
1.1 模糊关联规则
记模糊关联规则挖掘的原始决策表为Df,原始决策表的每一行称为一个事务T(transaction),Df=∪T,T是项(item)If的子集,T⊆If。所有项的集合构成If,If={i1,i2,…,ip,…,im},其中ip为模糊集。模糊关联规则即形如X→Y的蕴涵表达式,表示IFXTHENY,其中项集X和Y满足X⊆I,Y⊆I且X∩Y=∅。通常,关联规则的强度由其支持度(support)和置信度(confidence)共同度量,X→Y的支持度记作sup(X→Y),反映关联规则存在的普遍程度,是重要性的测度;置信度记作con(X→Y),反映关联规则的强度,是可信性的测度。强关联规则就是支持度和置信度大于关联规则的给定值,记给定的最小支持度为minsup,最小置信度为minconf。
X在模糊数据库Df中的支持度为
(1)
式中X={X1,X2,…,Xδ,…,XΔ}⊂If。
含有X的数据共有Ω条,supω(X)表示X在第ω条数据中的支持度
supω(X)=X1ωX2ω…Xδω…XΔω。
(2)
其中Xδω表示第ω条数据中Xδ的模糊值。
模糊关联规则X→Y的支持度
(3)
式中‖Df‖表示数据库Df中项的数量。
模糊关联规则X→Y的置信度
(4)
1.2 Apriori算法
模糊关联规则挖掘,即找出支持度和置信度大于给定值的强关联规则的过程,一般包括以下两个步骤:
(1)找出支持度大于给定值的关联规则 该步通常采用Apriori方法,过程如下:
1)扫描事务数据库Df。根据最小支持度minsup,产生频繁1-项集的集合L1,由L1执行连接和剪枝操作,产生候选2-项集合C2,并根据minsup产生频繁2-项集合L2;再由L2产生L3,重复以上步骤直到Lk为空集。
2)连接操作。连接操作记做∞。设Lk={l1,l2,…,ln},li={li[1],li[2],…,li[k]}是其中的元素。Lk中的两个元素li、lj是可连接的,当且仅当这两个元素的前k-1个元素相同,即当li[1]=lj[1],li[2]=lj[2],…,li[k-1]=lj[k-1],li[k]≠lj[k]时,li∞lj={li[1],li[2],…li[k],lj[k]},li∞lj∈Ck+1
3)剪枝操作。设ck∈Ck,即ck是一个候选k-项集,ck-1是ck的一个(k-1)-项子集。若ck-1∉Lk-1,则将ck从Ck中删除。
(2)找出置信度大于给定值的强关联规则 由频繁模糊项集中的生成规则,通过与给定的最小置信度比较得到满足需要的强关联规则。
1.3 直觉模糊集
设Θ是一个给定论域,则Θ上的一个直觉模糊集A由μA(θ),νA(θ),πA(θ)表示,A={[θ,μA(θ),1-νA(θ)]|θ∈Θ},其中μA(θ):Θ→[0,1]和νA(θ):Θ→[0,1]分别表示A的隶属函数μA(θ)和非隶属函数νA(θ),且对于A上的所有θ∈Θ,μA(θ)+νA(θ)≤1成立,πA(θ)=1-μA(θ)-νA(θ)表示θ∈Θ的犹豫度。
根据直觉模糊集的定义,直觉模糊集由隶属度、非隶属度和犹豫度3个参数(μ,ν,π)确定,在μ,ν,π确定的三维空间中直觉模糊数的几何表示如图1所示[21]。在图1a中,面ABC上的任意一点表示一个直觉模糊集,满足μ+ν+π=1。当犹豫度为0时,直觉模糊集即转化为模糊集,为直线AB上的任意一点;当非隶属度为0或隶属度为0时,即A点和B点,模糊集进一步转化为传统的精确数,表示绝对的属于或者不属于。
根据正隶属度、犹豫度即可确定一个直觉模糊集[23]。如图2所示为电影属性及犹豫度的隶属度函数。以对片源的情感属性评价悲怆(l1)为例,用精确集合表示为l1/l1,意为悲怆或不悲怆;用模糊集合表示为意为悲怆的程度为低/中/高,其隶属度函数如图2a所示;用直觉模糊集合意为悲怆的程度为低,且犹豫度为0.2。决策者表达犹豫度时,通常习惯用“非常不犹豫”、“犹豫”、“非常犹豫”等自然语言表达(如图2b),因此用模糊集表达犹豫度更符合决策者的习惯。在上述例子中,犹豫度为模糊集的直觉模糊集合表示为意为悲怆的程度为低,且犹豫度为非常不犹豫。犹豫度为模糊数的直觉模糊数的几何表示如图1b所示,为面SRPQT,传统直觉模糊集为面SRPQT上的一点。由此可见,犹豫度为模糊集的直觉模糊数是传统直觉模糊集的集合。

2 直觉模糊向量关联规则挖掘
本文构建的原始决策表中的元素有如下两个特点:①具有多维度属性,即每个元素都是一个多维度的向量;②具有直觉模糊属性,即向量的每个维度都是一个直觉模糊集。下面给出直觉模糊向量关联规则挖掘的定义,通过对比精确集、模糊集合直觉模糊集的支持度和置信度的计算,分析直觉模糊集关联规则挖掘的特点及难点。同时,提出直觉模糊集的支持度和置信度的计算方法,并给出直觉模糊向量的关联规则挖掘步骤。
2.1 直觉模糊向量关联规则
(1)直觉模糊向量关联规则定义
根据1.1节模糊关联规则支持度和置信度的定义,给出直觉模糊向量关联规则度定义如下:
记直觉模糊关联规则挖掘的原始决策表为Dff,原始决策表的每一行称为一个事务Tff(transaction),Dff=∪Tff,Tff是项(item)Iff的子集,Tff⊆Iff。所有项的集合构成Iff,Iff={iff1,iff2,…,iffp,…iffm},其中iffp为直觉模糊集。直觉模糊关联规则是形如X′→Y′的蕴涵表达式,表示IFX′ THENY′,其中项集X′和Y′满足X′⊆I,Y′⊆I且X′∩Y′=∅。
若iffp是直觉模糊集构成的向量,则X′→Y′称为直觉模糊向量关联规则。
X′→Y′的支持度记作sup(X′→Y′),置信度记作con(X′→Y′)。强关联规则是支持度和置信度大于给定值的关联规则,记给定的最小支持度为minsup,最小置信度为minconf。
直觉模糊集X′在直觉模糊数据库Dff中的支持度为
(5)

含有X′的数据共有Ω条,supω(X′)表示X′在第ω条数据中的支持度
(6)

直觉模糊关联规则X′→Y′的支持度为:
(7)
直觉模糊关联规则X′→Y′的置信度为:
(8)
(2)直觉模糊集的双重模糊变量建模
由于置信度和支持度计算方法类似,不失一般性,仅以支持度为例说明精确集合、模糊集合和直觉模糊向量的关联规则挖掘异同及难点。式(1)中supω(X)表示X在第ω条数据中的支持度,是X各个项Xδω的模糊值的乘积,对于精确集合,此值为1,表示X出现了1次,可由式(1)直接计算出支持度supω(X);若X是模糊集合,其模糊值一般是模糊变量的隶属度μA(θ),表示隶属于某一概念的程度,出现了μA(θ)次,可根据式(2)计算出支持度supω(X)。对于直觉模糊集合,由于式(5)和式(6)中除了隶属度还有犹豫度,现有研究尚无计算方法。为此,引入双重模糊变量的期望值,估算直觉模糊集的支持度和置信度。双重模糊变量定义[24]如下:
若η为从可能性空间(θ,Ρ(θ),Pos)到模糊变量集合的函数,则称η是一个双重模糊变量。
当犹豫度表示为模糊集合时,可将直觉模糊集看作隶属度和犹豫度的双重变量。犹豫度的隶属度函数表示为μπ(φ),直觉模糊集A(μA(θ),πA(θ))又可记做A(μA(θ),μπ(φ)),记其双重模糊变量为γ,其隶属度函数为
μγ(γ)=μA(θ)+φ×(1-μA(θ))。
(9)
采用双重模糊变量的期望值去估算直觉模糊集的值,因此式(6)可转化为
supω(X′)=E(γ1)E(γ2) …
E(γδ) …E(γΔ)。
(10)
期望值的估算方法将在2.2节中给出。
2.2 基于双重模糊模拟的直觉模糊集支持度、置信度估算方法
模糊变量的期望值由可能性、必要性和可信性3个参数决定。记模糊变量为ξ,其隶属度函数为μ(u),设r是一个实数,则模糊变量ξ的可能性Pos、必要性Nec和可信性Cr的计算公式如下:
(11)
Nec{ξ≥r}=1-supu (12) (13) 其中sup表示上方有界中的最小值。 定义1如果下式右端两个积分中至少有一个为有限的,则称 (14) 为模糊变量ξ的期望值。 定义2设η为双重模糊变量,如果下式右端两个积分中至少有一个为有限的,则称 (15) 为双重模糊变量η的期望值。 采用双重模糊模拟的方法估算E[η]的值。从Θ中均匀抽取满足pos{θk}≥ε的θk,并记υk=pos{θk}(k=1,2,…,N),其中ε是一个充分小的正数,当N充分大时,对任意的r≥0,可信性Cr{θ∈Θ|E[η(θ)]≥r}可以近似为 (16) 而对任意的r<0,可信性Cr{θ∈Θ|E[η(θ)]≤r}可以近似为 (17) 其中E[η(θk)]通过模糊模拟估计得到: (18) 算法1基于模糊模拟的均值估算算法 步骤1置e=0。 步骤2从Θ中均匀抽取满足pos{θk}≥ε的θk(k=1,2,…,N),其中ε是一个充分小的正数。 步骤4从区间[a,b]中均匀产生r。 步骤5如果r≥0,则e=e+Cr{θ∈Θ|E[η(θ)]≥r}。 步骤6如果r≤N,则e=e-Cr{θ∈Θ|E[η(θ)]≤r}。 步骤7重复步骤4~步骤6共N次。 步骤8E[η]=max{a,0}+min{b,0}+e(b-a)/N。 对于直觉模糊向量事务数据库,本文提出分层挖掘的方法挖掘模糊关联规则(如图3)。在传统关联规则挖掘问题中,原始决策表的基本元素为一个数,而本文所解决的直觉模糊向量关联规则问题,其原始决策表的基本元素为向量,因此本文提出双层挖掘的框架,底层关联规则挖掘是为了将向量转化为一个数,其挖掘的对象是原始决策表的基本元素(向量),利用得到的关联规则将原始决策表的基本元素向量转化为一个数,从而达到降维的目的。降维之后再进行顶层关联规则挖掘,顶层关联规则挖掘出的是最终的关联规则。两个最小支持度的取值相互独立,本文不对两个最小支持度的取值做特殊规定。具体步骤如下: (1)阶段1 底层关联规则挖掘 (2)阶段2 底层模糊向量转化 (3)阶段3 顶层关联规则挖掘 裸眼3D技术被认为是最有生命力且终将成为显示技术共性平台的下一代显示技术,代表着显示行业最新的发展趋势。裸眼3D片源设计过程是设计师不断对模型和场景的大小、位置、色彩等做出决策的过程,需要大量的知识供设计师参考,具有知识高度密集、分布式、协同工作等特点。在裸眼3D知识管理系统中,设计师按照流程制作裸眼3D片源,其大量的经验、知识被记录在系统中。裸眼3D片源设计与制作包括脚本设计、建立三维模型、场景制作、渲染以及制片、合成与剪辑等关键步骤。在场景制作过程中,设计师需要根据主体、陪体、背景、效果、题材、情感等判断场景如何制作,此过程抽象为配置过程,如图4所示。推理机基于配置规则,可以根据用户输入的需求进行配置计算,输出用户所需的配置方案。本文以裸眼3D片源设计与制作中场景制作为例,验证本文提出的直觉模糊关联规则挖掘方法的可行性和有效性。 条件属性集包含主体(A)、陪体(H)、背景(I)、效果(J)、题材(K)、情感(L),决策属性为画面布局(M),各属性的取值如表1所示。选取1 500条记录,犹豫度的取值为{非常不(NV),稍微(M),中等(V),特别犹豫(P)},设计实例经过预处理后,得到表2所示的原始决策表。 表1 各属性取值 表2 原始决策表 采用本文提出的分层关联规则挖掘方法: (1)底层关联规则挖掘 首先对每个属性进行挖掘,设置最小支持度为minsup1=0.2,最小置信度为minconf1=0.6,挖掘出来的规则如表3所示。 表3 底层关联规则挖掘出的规则表 (2)底层模糊变量转化 应用第(1)步挖掘出来的规则,将原始决策表简化为97条数据(如表4)。 表4 底层模糊变量转化后的决策表 (3)顶层关联规则挖掘 采用模糊关联规则挖掘方法对这97条数据进行挖掘,设置最小支持度为minsup2=0.15,最小置信度为minconf2=0.5,挖掘出来的规则如表5所示。 表5 顶层关联规则挖掘出的规则表 本文采用直觉模糊集表达决策者的犹豫信息,与传统方法有两点不同:①原始决策表为多维的向量(如附表3);②每项的元素为直觉模糊集。两种方法对比时,为保证变量的唯一性,进行如下两组对比: (1)多维向量给算法带来的区别 表6 降维对比组的原始决策表 由于每个元素只有一个维度,仅需挖掘一次,其步骤与本文提出的双层关联规则挖掘框架的阶段1相同:①按照Apriori方法生成满足最小支持度的频繁模糊项集,其中原始决策表的元素为犹豫度为模糊数的直觉模糊集合,需采用2.2节提出的方法计算支持度;②生成满足最小置信度的关联规则,得到的关联规则数目为17个(如表7)。由于对比组一次挖掘出最后的关联规则,与顶层关联规则挖掘的目标相同,最小支持度和最小置信度的值与顶层关联规则挖掘的值相同,最小支持度为minsup2=0.15,最小置信度为minconf2=0.5。本文直觉模糊关联规则挖掘方法得到的规则数目为9个,传统方法挖掘出的17条关联规则包含本文方法挖掘出的8条关联规则(见表7前8条)。为分析两者之间的关系,列出所挖掘出的关联规则的支持度和置信度,可以看出,对比组挖掘出的关联规则支持度更高。这是因为化简之后,项目重复出现的数量增多,即支持度计算公式中分子变大。在支持度整体变大的情况下,挖掘出的规则数目就增多。由于本文方法挖掘出的关联规则大部分与传统关联规则挖掘出的相同,可以认为本文挖掘的结果是合理的。 表7 对比组一传统模糊关联规则挖掘 (2)直觉模糊集和传统模糊集给算法带来的区别 1)底层关联规则挖掘。首先对每个属性进行挖掘,设置最小支持度为minsup1=0.2,最小置信度为minconf1=0.6,挖掘出来的规则如表8所示。 表8 对比组二底层关联规则挖掘出的规则表 2)底层模糊变量转化。应用第1)步挖掘出来的规则,将原始决策表简化为136条数据(如表9)。 表9 对比组二底层模糊变量转化后的决策表 3)顶层关联规则挖掘。采用模糊关联规则挖掘方法对这136条数据进行挖掘,设置最小支持度为minsup2=0.15,最小置信度为minconf2=0.5,挖掘出来的规则如表10所示。 表10 对比组二顶层关联规则挖掘出的规则表 传统方法挖掘出的10条关联规则包含本文方法挖掘出的7条关联规则(见表10前7条)。为分析两者之间的关系,列出所挖掘出的关联规则的支持度和置信度,对比组挖掘出的关联规则支持度更高,因为删除犹豫度之后,支持度计算公式中分子变大。在支持度整体变大的情况下,挖掘出的规则数目也相应地增多。 表1 直觉模糊对比组原始决策表 为了验证所提方法的效率,变换不同的项目数和最小支持度,比较两个算法的执行时间。由于第一对比组的原始决策表的元素为一维,只需挖掘一次,其效率比第二对比组和本文提出的方法都高。下面只对第二对比组和本文的方法进行分析,结果如图5所示。其中,图5a所示为项目数量变化时,传统模糊关联规则挖掘方法与本文所提方法效率的对比。当项目数量较少时,传统模糊关联规则方法的执行效率更高,因为原始决策矩阵规模较小,受向量维数影响较小,而本文所提方法需进行两次挖掘,所以本文所提方法用时较长。随着项目数量的增加,本文所提方法的效率明显优于传统模糊关联规则挖掘方法。图5b所示为项目数为8时,不同最小支持度条件下,两种算法的执行时间。由于顶层关联规则直接影响最终响果,为保证变量唯一性,此组对比只改变顶层关联规则挖掘的最小支持度。结果表明,本文所提方法的执行效率优于传统模糊关联规则挖掘方法。 考虑裸眼3D片源设计与制作过程决策数据的模糊性,本文采用直觉模糊向量对数据进行建模,并针对关联规则挖掘过程中决策者犹豫度难以表达的问题,引入双重模糊变量思想,采用双重模糊变量的期望值计算规则的支持度。以裸眼3D片源设计与制作过程为例,验证了所提方法的可行性和有效性。本文的主要贡献在于: (1)提出了双层关联规则挖掘方法框架。底层关联规则挖掘方法降低了规则前件的维度,同时为顶层关联规则提供了更多的有效数据,提高了关联规则挖掘的成功率。 (2)提出了基于双重模糊思想的支持度计算方法。将直觉模糊集中的犹豫度建模为双重模糊变量,并采用双重模糊模拟的方法计算支持度,解决了传统关联规则挖掘中难以表达决策者犹豫度的问题。后续将继续优化挖掘算法的效率,并将其应用于大数据场景。



2.3 直觉模糊向量关联规则挖掘步骤





3 实例
3.1 实例分析






3.2 对比讨论
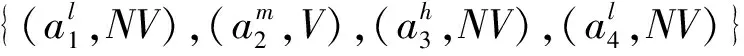







4 结束语
猜你喜欢
舰船电子工程(2022年4期)2022-05-11
湖北民族大学学报(自然科学版)(2021年1期)2021-04-02
数学大世界(2021年4期)2021-03-30
山东农业大学学报(自然科学版)(2020年5期)2020-11-02
小型微型计算机系统(2019年10期)2019-11-11
家庭影院技术(2019年8期)2019-08-27
西华大学学报(自然科学版)(2018年6期)2018-11-24
传媒评论(2018年5期)2018-07-09
成长·读写月刊(2017年4期)2017-05-16
计算机与数字工程(2016年11期)2016-12-13
