
基于Python的TarBase V8网站爬虫设计与实现
2020-08-26 07:46蒋辉谢云洁
电脑知识与技术 2020年20期
蒋辉 谢云洁
摘要:在数据爆炸的时代,人们通过搜索引擎从网上来查找自己所需要的数据。但并不是所有的网站都提供所需要的数据下载。网络爬虫技术可以将查找到的数据抓取下来,以供研究人员研究使用。Scrapy是使用Python语言开发开源的爬虫框架。该文将利用Scrapy框架和Python语言设计和实现一个TarBase V8网站爬虫,对其网站miRNA靶基因数据进行获取以及存储。
关键词:Scrapy;网络爬虫;搜索引擎;信息检索;miRNA靶基因
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2020)20-0020-03
Design and Implementation of Web Crawler on rrarBase V 8 Web Site Based in Python
JIANG Hui, XIE Yun-jie
(School of Computer Science. University of South C.hina, Hengyang 421001, China)
Abstract: In the era of data explosion, we can get the information or data from the internet by using search engines. But not all web-sites provide the data downloads we need. These data can be captured from the internet for the researching purpose by using webcrawler technology. Scrapy is an open source web crawler framework which is developed by Python. In the paper, we design and de-velop a web crawler which is based on Scrapy framework and Python f'or capturing the miRNA targets data from the TarBase V8website.
Key words: scrapy; web crawler; search engine; information retrieval; miRNA targets
1背景
miRNA是一类非编码的小分子RNA,其在生命活动起着重要的作用。越来越多的研究表明miRNA与疾病的产生与发展有着重要的关系[1]。其机理是miRNA绑定到其靶基因上,使得靶基因降解或者翻译抑制,致使该基因对应的蛋白表达异常,从而导致疾病。在研究miRNA的过程中,生物学实验已经证实了非常多的miRNA靶基因信息,并以论文的方式发表。也有生物信息学的研究人员通过文献挖掘的方法将分布在这些发表在论文中的miRNA靶基因信息挖掘出来,并建立了完善的数据库供相关人员查询或下载。TarBase就是其中之一,但由于TarBase V8[2]的数据库其官网只提供查询和部分信息下载,因此要获取这些数据就变得比较困难。网络爬虫技术可以从网贞上获取用户指定的信息,因此本文使用Python语言设计和实现了网络爬虫来获取这些数据。
2 Scrapy框架简介
Scrapy[3]是Scrapinghub公司开发的开源的网站爬虫应用框架,该框架基于Twistid异步网络框架,使用Python语言开发。Scrapy以其开源性及优秀的系统架构获得了广泛的应用。Scrapy组件间的低耦合性,极易扩展性和组件的可定制开发性,使其可以灵活的完成各种需求。除爬虫外,Scrapy框架还应用在数据挖掘、信息处理、存储历史数据等方面。
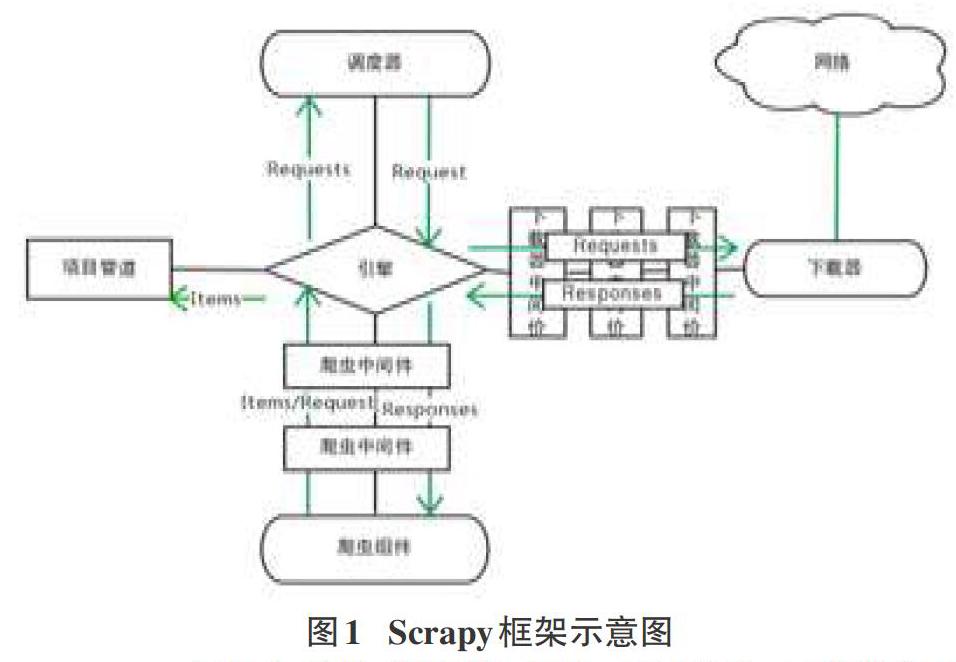
Scrapy框架由引擎、调度器、爬虫、项目管道、下载器中间件、下载器、爬虫中间件等组件构成。引擎负责数据和信号在不同组件间的传递;调度器是一个队列,用来储存请求的URL;爬虫负责定义爬取的动作及分析网页;项目管道处理引擎传过来的数据,如保存,查重和验证数据;下载器中间件处理从引擎和下载器之间的数据传递;下载器负责从网络上下载引擎传过来的请求;爬虫中间件负责处理发送给爬虫组件的Response及爬虫组件产生的Item和Request。其框架的结构图如图l所示。
3基于python的TarBase V8网站爬虫设计与实现
大数据时代的到来,使得人们淹没在数据的海洋,这些数据中蕴含着大量的信息。对这些数据的深入研究可以发现更多有用的知识。网络爬虫技术可以从网络上自动的下载所需要的数据。本文设计了一个基于Scrapy框架的TarBase V8网站爬虫,获取其miRNA靶基因数据。
3.1需求分析
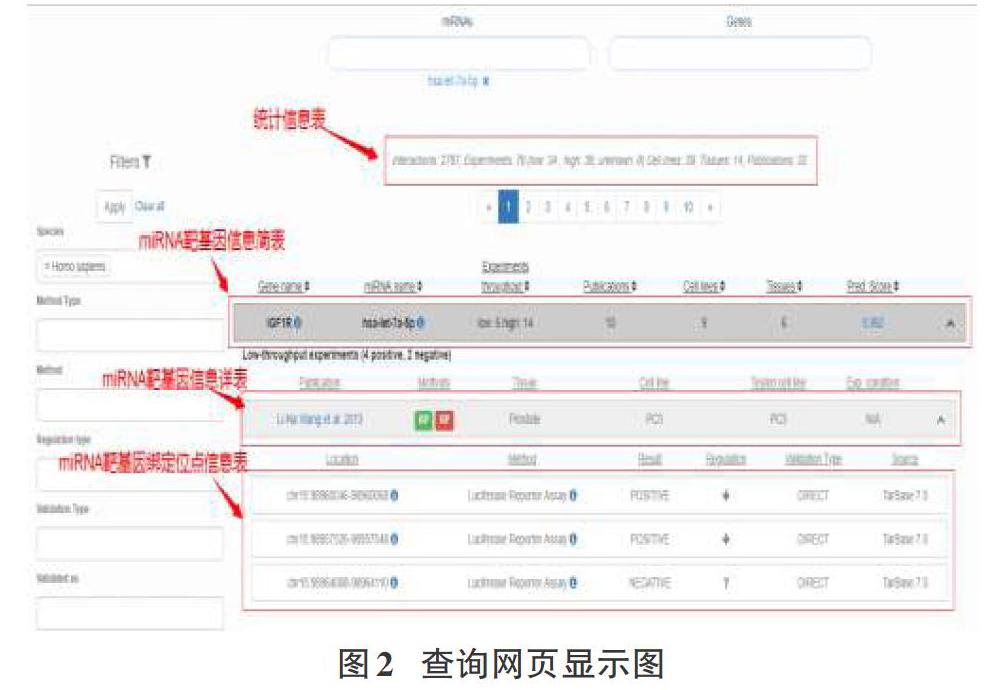
TarBase V8网站上记录了每一对miRNA靶基因的所属物种、验证这miRNA靶基因对的生物实验种类、支持文献的PuLMed ID以及靶位点信息。将人类的miRNA名字“hsa-let-7a-5p”提交到网站的查询页面,服务器生成了URL用来查询该miRNA的靶基因,其结果网页如图2所示。
我们所需要的数据可以分为四个类型:第一,miRNA靶基因信息简表,它描述miRNA靶基因对的miRNA名字、基因名、支持文献篇数以及用来实验的Cell lines、Tissues数目等数据;第二,miRNA靶基因信息详表,它描述每对miRNA靶基因的实验细节,如具体的文献、用来验证的生物学实验方法等;第三,miRNA靶基因绑定位点信息表,它描述miRNA靶基因對之间的绑定细节。如具体的绑定位置、实验方法等;第四,统计信息表,它描述此miRNA查询后的统计结果。
通过对服务器返回的html脚本的分析,前三类关系都是在同一个table标签里面,在
里面的结点包含了miRNA靶基因关系简表信息,后面的里构建了一个table保存miRNA和与之对应的基因的实验细节,第三类型数据位于第二个table下面的子节点table()。由以上分析得出,根据标签的class属性可以区分所需数据类型。统计表则在另一个diy中,可以用来获取。
TarBaseV8中的所使用的miRNA名字来源于miRNA信息数据库miRBase[4](21版)。该数据库中共有2588条人类的miRNA成熟体信息,可以每次获取一个miRNA靶基因数据,然后循环2588次,就能将该数据库中miRNA靶基因信息全部获取出来,并保存在数据库中。
3.2系统设计
3.2.1系统架构及其类的设计
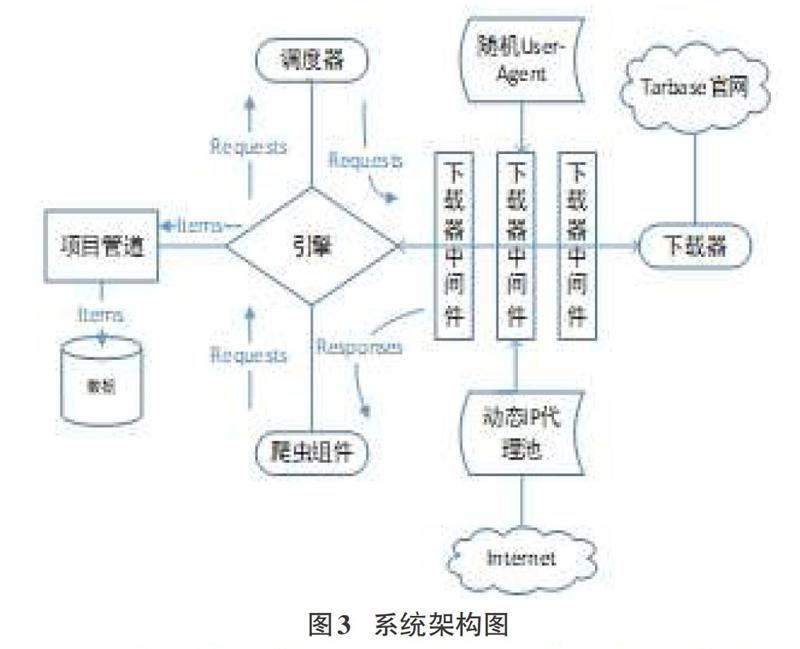
根据需求,并结合SCrapy框架,此爬虫分为两个主要的模块:数据获取模块和数据存储模块。其整体的结构如图3所示。
这样设计使得模块之间功能独立相互独立,降低了模块间的耦合性。数据库用来保存从网页上获取的数据,随机User-Agent和动态IP代理池解决了网站反爬虫的问题。
图4为系统的类图,其中getmiRNACount类为获得统计信息表结果的类,ltem是一个字典类型,用于保存从网页中解析到的统计信息结果;在search方法中解析网页,其他的一些方法用于数据库的操作。TarBase.py.Tarbase类用于爬取miRNA靶基因信息简表,在start_requests方法中构造请求URL,在parse方法中解析获取网页中的数据。Spilder.get_second_third.py.TarhaseSpilder类用于爬取miRNA靶基因对信息详表以及绑定信息表,在start_requests方法中根据在简表中已经获取到的miRNA名和基因名构造请求URL,在parse方法中解析获取网页中的数据。Item类型的类用于保存结构性数据,Tmiddler-wares.py.ProxyMiddleware类是一个下载器中间件,用于设置代理IP。
3.2.2数据库的设计
根据上面对需求和网页结构的分析,可以创建四个实体类,分别是mirna_info(miRNA靶基因信息简要信息),through-put_experiments(miRNA靶基因信息详细信息),binding_site(miRNA靶基因绑定位点信息),mirna_count(统计信息),数据库的物理模型,如图5所示。
由于TarBase V8中的miRNA靶基因对数据量比较大,会使得数据表中的数据非常多,从而导致查询速度变慢。而查询的主要关键词为MiRNA名称和基因名称,因此为所有表的miR-NA name和gene_name属性创建了索引。由于一个miRNA靶基因对有大于等于一条详情,以及大于等于一条绑定位点信息,所以其基数比约束都为1:n。
3.2.3遇到的问题及其解决方案
在系统的设计中要遇到如下4个问题。
1)爬虫获取网页数据时无法建立前三个表数据之间关联
由于TarBase V8网站网页结构的限制,以及爬虫的并发操作等原因使得简表数据与详细表的数据以及绑定表数据之间没有关联。因此爬虫所获得的数据就是散乱的、相互之间没有关系可循的。
为了解决这个问题,本文在设计了一个分步获取数据的方法,先获取所有miRNA靶基因信息简表的数据,为每一对miR-NA靶基因在数据表中生成唯一id号。这样就可以根据简表中的每对miRNA名和Gene名来构造相应的请求URL,来获取miRNA靶基因信息详表和miRNA靶基因绑定位点信息表的数据,通过每个miRNA靶基因对的唯一id就可以关联这三张表中的数据。
其伪代码如下:
BECIN:
//循环从已知miRNA名列表中得到miRNA名称;
Foreach miRNA_name in miRNA_list(已知数据miRNA名列表)
URL=generate url for miRNA_name;
//根据miRNA名生成的URL请求爬取网页数据;
Html=spider(“URL”);
//将从网页中筛选出所需要的信息并保存进数据库表;
Save(Find the data in Html);
//循环从第一次保存的数据表中得到miRNA名和基因名;
roreach miRNA-gene pair in miRNA_info(简表)
//根据miRNA名和基因名再次生成请求URL;
URL=generate url for miRNA_name and Gene_name;
Html= spider(“URL”);
Sava(Find the data in Html);
END
2)无法为抓取统计数据页面构造URL
由于统计数据以ajax异步请求的方式获得的,因此对获取miRNA的统计数据带来了一定的麻烦。对所抓得的统计数据进行分析发现,其URL的请求参数是一条sql语句,该语句中查询条件是一串无规律的数字,这使得请求的URL构造困难。为了解决这个问题,本文使用selenium和Webdriver[5]来模拟人操作浏览器的方式获取ajax请求返回的数据。
Selenium是ThoughtWorks专门为Web应用程序编写的运行在浏览器上的Web测试工具,它能够像人操作浏览器那样模拟操作浏览器。Wehdriver是基于selenium設计的操作浏览器的一套API,它针对不同语言有对应的实现。
3)爬取数据时的翻页
在查询结果数据量大的情况下,TarBase V8网站会分页展示结果。本文将采用递归的方式来做分页请求并解析数据。
4)反反爬虫技术
TarBase V8网站设置了反爬虫机制来保证网站的正常运行。,本文采用IP代理和设置随机User-Agent来解决这个问题.lP代理设置是在爬虫外部构建一个动态代理lP池,其能不断的从网上获取免费的可以使用的代理IP,并定时更新动态池中的数据,然后将这些IP存人Redis数据库中;随机User-Agent的设置通过Python的第三方庫fake-useragent来生成。
为了让此网站不发现是爬虫程序在访问,我们降低Scrapy框架中的并发数量并设置为10个。
4爬虫的实现
本系统采用Python3.7,Selenium 3.141.0,Chromedriver和SCrapyl.6.0,Mysql 8.0来实现。
基于Scrapy框架的可定制性和易扩展性,根据对系统的需求分析,需要创建暂存爬取数据的Item组件,实现spider组件,用于构造请求的URL并调用parse方法解析请求返回的数据,并将其暂存到Item中,经引擎通过项目管道保存到数据库中。随后在scrapy框架的下载器中间件组件中,创建ProxyMiddle-ware类和RandomUserAgentMiddleware类,用以设置IP代埋和设置随机User-Agent,创建getmiRNACount类。用selenium和webdriver来获取通过ajax返回的统计结果的数据;最后在pipe-line组件中实现数据的持久化。
5结束语
本文在分析TarBase V8网站网页结构的基础上,使用py-thon语言和Scrapy框架设计与实现了TarBase V8网站数据爬虫。针对网页中各表数据之间无关联性的问题,设计了分两步获取的方法来解决,即先获取简表信息,再根据简表中的数据生成相应的请求URL获取详表及绑定表的信息;针对ajax网页局部渲染更新的问题,使用了selenium加无头的chromedriver来解决;针对网站反爬虫机制的问题,使用了随机User-Agent和IP代理的方式来解决。本爬虫在网络状态良好的情况下,爬取2588条miRNA的数据需要60多小时,共爬取数据约100多万条。
参考文献
[1] Huang Y, Shen X J, Zou Q, et al. Biological functions of mi-croRNAs:a review[J]. Journal of Physiology and Biochemistry,2011, 67(1): 129-139.
[2] Karagkouni D. Paraskevopoulou M D, Chatzopoulos S. et al.DIAhrA-TarBase v8:a decade-long collecticm of experimental-ly supported miRNA ~ gene interactions[J]. Nucleic Acids Re-search. 2018, 46(DI): D239-D245.
[3]崔庆才.Python 3网络爬虫开发实战[M].北京:人民邮电出版社,2018.
[4] Kozomara A,Criffiths-Jones S.MiRBase:annotating high confi-dence microRNAs using deep sequencing data[J].Nucleic Ac-ids Research. 2014. 42(D1): D68-D73.
[5]时永坤.基于WehDriver的定向网络爬虫设计与实现[J].软件,2016, 37(9): 94-97.
【通联编辑:谢媛媛】
收稿日期:2020-05-08
基金项目:湖南省教育厅科研课题(项目编号:17C1377)
作者简介:蒋辉(1981-),男,湖南衡阳人,讲师,硕士,主要研究方向为生物信息学、信息检索与知识发现、软件工程;谢云洁(1996一),男,学士。
猜你喜欢
中国新通信(2016年21期)2017-01-06
新闻传播(2016年18期)2016-07-19
现代计算机(2016年11期)2016-02-28
中国卫生(2015年12期)2015-11-10
警察技术(2015年3期)2015-02-27
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
技术经济与管理研究(2014年11期)2014-03-11
河南科技(2014年11期)2014-02-27
图书馆界(2013年5期)2013-03-11
