
基于深度学习的交通监控视频车辆检测算法
2020-09-09 03:09毛其超贾瑞生左羚群
计算机应用与软件 2020年9期
毛其超 贾瑞生 左羚群 齐 榕
(山东科技大学计算机科学与工程学院 山东 青岛 266590)(山东科技大学山东省智慧矿山信息技术省级重点实验室 山东 青岛 266590)
0 引 言
近年来,智能交通系统(ITS)在我国已经广泛投入使用,而其中最基础的便是交通监控视频中的车辆检测技术,只有在车辆检测达到较高的精度时,才能进行车型识别、车辆定位、驾驶员疲劳检测、车流量统计等后续工作。车辆检测算法属于目标检测算法的分支,主要分为两大类:传统车辆检测算法与基于深度学习的车辆检测算法。对于传统车辆检测算法,其步骤一般可概括为三步:① 人为选择候选区域;② 对候选区域进行特征提取;③ 用分类器判断是否为汽车。2005年,Dalal等[1]在对候选区域进行提取时选择方向梯度直方图(Histogram of Gradient,HOG)算法,并选择线性支持向量机(Support Vector Machine,SVM)作为最终的分类器来进行检测。Felzenszwalb等[2]在2008年提出的基于变形组件模型(Deformable Part Model,DPM)的车辆检测算法。传统算法的优势在于速度较快,但是检测精度堪忧,尤其是在交通监控视频的复杂场景下,如:夜间的低照度、恶劣天气的能见度低都会严重影响视频质量。
最近,深度学习理论日益发展,已在图像检测识别、文字检测识别、语音识别等领域取得卓越成绩[4-6]。文献[7]奠定了基于深度学习检测任务的基础。2014年,Girshick等[8]首次将卷积神经网络引进目标检测任务,采用(Selective Search,SS)方法[9]进行选择候选区域,然后利用CNN对其进行特征提取,将分类器接在卷积特征图上进行检测,最后回归调整检测框的最终位置。该算法在PASCAL VOC2012测试集上的平均准确率(Mean Average Precision, mAP)相较于传统算法提高了30%。2015年,He等[10]提出了SPP net,该网络利用空间金字塔池化层,降低了卷积神经网络对尺寸的限制。Girshick[11]又基于SPP net中金字塔池化的思路,提出了Fast-RCNN,该网络利用一种ROI池化解决了不同大小的候选框无法等长输入检测网络的问题,并将候选区域在Feature map上标示出来,只需要对图像进行一次特征提取,大大加快了网络的运行速度。Ren等[12]提出了Faster R-CNN算法,该算法利用RPN网络进行选择候选区域,进一步降低了网络的运行速度,并提高了检测精度。但将Faster R-CNN应用于监控视频下车辆检测时,监控视频下多为高分辨率图像,提取特征相对较难,且当图像中存在车辆重叠的情况时,该网络易造成漏检。
针对以上问题,本文对Faster R-CNN网络模型进行改进,利用残差网络[13]技术重新设计车辆特征提取网络,并在之后接入空洞卷积[14],在筛选候选框的过程中,对非极大值抑制(Non-Maximum Suppression,NMS)[15]进行改进,克服了高分辨率图像难以提取特征的问题,并且在车辆重叠的情况下降低了漏检率,提高了车辆检测的准确性。
1 相关理论基础
Faster R-CNN网络结构如图1所示,可分为四部分:特征提取层,候选区域推荐网络(Region Proposal Network, RPN),ROI池化和检测网络。为了提取输入图像的特征,特征提取层是由多组连续的卷积层、池化层、非线性化构成。候选区域推荐网络利用一个N×N的滑动窗口在特征图上滑动,并且利用Anchor机制生成初始候选区域。ROI池化层将大小不同的候选区域转换成长度相同的特征向量送入检测网络以回归目标检测框并输出检测结果。
将Faster R-CNN应用到监控视频下车辆检测时,检测效果相较PASCAL VOC 2012还有一定差距。造成这一现象的原因有以下两点:
1) 高分辨率图像造成特征信息冗余。
2) 车辆存在大部分重叠时使用非极大值抑制NMS使检测框丢失。
2 算法设计
2.1 车辆检测模型
本文以深度学习方法解决监控视频下车辆检测问题,车辆检测流程分为训练和检测两个阶段。在训练阶段,首先提取训练样本集,根据PASCAL VOC数据集格式制作样本训练集,然后将样本训练集输入神经网络进行训练,经过多次迭代后得到训练完毕的车辆检测网络;在检测阶段,将图像直接输入到训练完毕的神经网络,得到车辆外围框的具体位置并在原图上标示出来,最后输出车辆检测结果。具体流程如图2所示。

图2 改进后的Faster R-CNN车辆检测算法流程
在交通监控视频中高分辨率图像容易造成特征信息冗余并且存在车辆大部分重叠时使用非极大值抑制NMS易使检测框丢失。针对以上两个问题,我们对网络进行改进:① 采用残差网络[16]技术对特征提取层进行改进;② 采用空洞卷积过滤冗余特征;③ 使用Soft-NMS筛选候选框。其神经网络结构如图3所示。
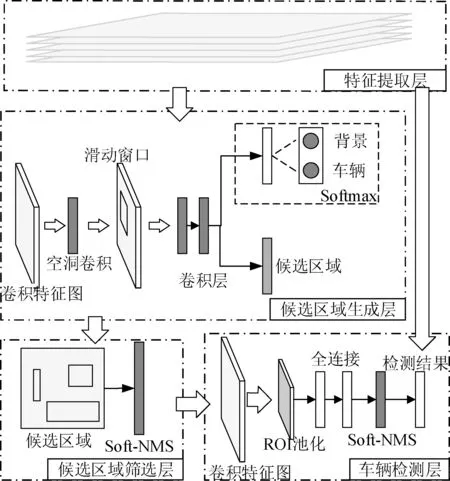
图3 神经网络模型结构图
本文神经网络模型分为特征提取网络、候选区域生成网络、候选区域筛选网络、检测网络四个部分。
1) 特征提取网络:对输入图片进行特征提取,生成特征图。具体网络如表1所示。

表1 网络结构表
2) 候选区域生成网络:使用膨胀系数r=2的3×3的空洞卷积过滤冗余特征,并在其中加入Anchor机制生成初始候选区域。空洞卷积本质上是对一般卷积运算的扩展,空洞卷积的输出y[i]可以表示为:
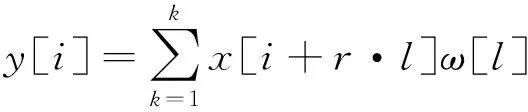
(1)
式中:x[·]表示一维输入信号;ω[l]为卷积核;l为卷积核大小;r为膨胀系数,表示能将卷积核扩张到膨胀系数所约束的尺度中,并将原卷积核中未被占用的区域填充0。图4为二维空洞卷积示意图,空洞卷积使卷积核的作用范围扩大,得到的有效卷积核高为fh+(fh-1)·(r-1),宽为fw+(fw-1)·(r-1) ,其中:fh代表原始卷积的高;fw代表原始卷积核的宽。而使用空洞卷积可以在增大感受野的同时保持特征图尺寸,灵活地添加空洞卷积可以在感受野不变的条件下过滤掉冗余特征,因此空洞卷积在监控视频下车辆检测中有较优秀的性能。
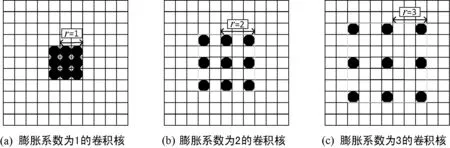
图4 不同膨胀系数下的空洞卷积示意图
3) 候选区域筛选网络:对初始候选区域使用Soft-NMS(Soft Non-Maximum Suppression)进行粗筛,相较于NMS,Soft-NMS是一种比较柔和的对候选框的筛选准则,如算法1所示。
算法1Soft-NMS
输入:初始候选区域集合B={b1,b2,…,bN},对应的置信度S={s1,s2,…,sN}。
输出:筛选后的区域集合D={d1,d2,…,dN},对应的置信度S={s1,s2,…,sN}。
1.D←{}
2. whileB≠empty do
3.m← argmaxS
4.M←bm
5.D←D∪M;B←B-M
6. forbiinBdo
7.si←si·f(IOU(M,bi))
8. end
9. end
10. returnD,S
其中:f(IOU(M,bi))定义为:
(2)
Si表示当前框的得分;M为当前得分最高框;bi为待处理框;Nt为设定阈值。可以看出,bi和M的IOU越大,bi的得分si就下降得越厉害(而不是直接置零),算法变得柔和并且解决了两物体重叠导致漏检率升高的问题。
4) 检测网络:对候选区域进行ROI池化,实现固定长度并输出至全连接层,然后再次接Soft-NMS对车辆检测框进行精筛,最后输出车辆检测结果。
2.2 损失函数
为了训练神经网络,我们定义了一个多任务损失函数:
(3)
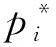
(4)
(5)

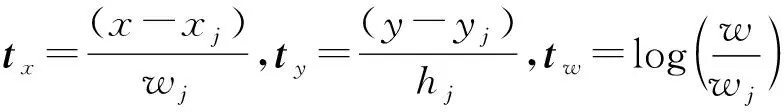
(6)
式中:(x,y)、(xj,yj)、(x*,y*)分别表示预测区域、候选区域、真实区域中心点坐标; (w,h)、(wj,hj)、(w*,h*)分别表示预测区域、候选区域、真实区域的宽和高。
2.3 算法流程
本文车辆检测算法分为训练和检测两个阶段,其主要步骤如下:
(1) 训练:
Step1抽帧截取监控视频,人工筛选剔除相似图片,得到图片集合R={R1,R2,…,Rn}。
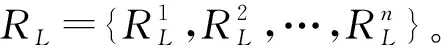
Step3初始化特征提取网络,将样本集RL输入该网络。则单幅图片Ri ∈{1,2,…,n}在区域生成网络中利用Anchor机制则可得到若干初始推荐区域A={A1,A2,…,An}。
Step4若初始推荐区域Ai∈{1,2,…,n}与已标注的车辆真实边界的IoU为O,当O=Omax或者O≥0.6时,该初始推荐区域为正样本,当O<0.3时,该初始推荐区域为负样本,故可得到大量训练样本集合S={S+,S-},其中:S+为正样本;S-为负样本。
Step5利用正负训练样本S结合式(5)多任务损失函数,按照梯度方向进行反向传播,学习修改网络参数,直到训练完毕,得到训练完毕的网络参数M。
(2) 检测:
Step1抽帧截取检测视频,得到输入图像P(x,y),然后将其输入训练完毕的车辆检测网络。
Step2首先在卷积层对图像P(x,y)进行特征提取,得到卷积特征图,然后输入至候选区域生成网络,生成候选区域集合Bi∈{1,2,…,n}。
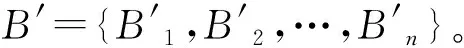
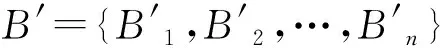
Step5用X、Y、W、H在输入图像P(x,y)上标定出车辆检测框,输出车辆检测结果。
3 实 验
3.1 数据集
(1) Car_VOC:我们从道路监控视频中选取不同时间段、不同地点、不同天气下的视频片段,对其进行抽帧截取,得到大小为2 592×2 048像素的高分辨率图像,经过手工筛选过滤掉相似的样本图片,对样本图片进行水平翻转,得到数据集总计图像1 710幅,部分样本如图5所示。将数据集用labelImg进行手工标注,并且按照Pascal VOC[15]数据样本格式重新编号,制作数据集Car_VOC,根据4∶1∶1的比例随机划分训练集、验证集、测试集,且互无交集,共计标注车辆4 572辆。

图5 部分Car_VOC数据集样例
(2) KITTI[17]: KITTI数据集是在中等城市卡尔斯鲁厄(Karlsruhe)农村地区和高速公路周围驾驶而拍摄的,数据集中单幅图像的特点与监控视频下视频图像有着很高的相似度。部分数据集样例如图6所示。

图6 部分KIYTTI数据集样例
(3) UA-DETRAC[18]: 该数据集是在中国北京和天津的24个不同地点使用Cannon EOS 550D相机拍摄的10小时视频。 视频以每秒25帧的速度录制,分辨率为960×540像素。UA-DETRAC数据集中有超过14万个帧,手动注释了8 250辆车辆。部分数据集样例如图7所示。

图7 部分UA-DETRAC数据集样例
3.2 实验及结果分析
(1) 在Car_VOC数据集上的实验:
为了验证本文算法的有效性,实验一选择Faster R-CNN车辆检测算法作为参照,对比本文模型的检测效果。我们选取平均精度Ap、平均误检率Af、平均漏检率Am作为评价指标,定义如下:
(7)
式中:Tp表示被车辆检测算法检测出的正确的车辆目标数目;Fn表示没有被车辆检测算法检测出的车辆目标数目;Fp表示被车辆检测算法误检的车辆目标数目;Tn表示没有被车辆检测算法误检成车辆的目标数目。
考虑到白天与夜间检测效果会有所差异,我们分别进行了两组对比实验。拥挤的交通存在车辆相互遮挡的情况,增加了检测的难度。我们在对比实验中分别设置了3个梯度,分别为:自由流,同步流,阻塞流。定义图中车辆数目为N,当N<10时,定义为自由流;当10≤N<25,且并不存在明显车辆遮挡的情况定义为同步流;只要N≥25,并且不管是否存在车辆遮挡统一定义为阻塞流。实验从Car_VOC测试集中随机分别选取80幅图像对应3个梯度构成本实验的测试集。图8为2种算法在Car_VOC下的部分检测结果。使用2种算法对测试集的图像进行检测,检测结果如表2所示。

图8 本文算法与Faster R-CNN算法在Car_VOC下的部分检测结果
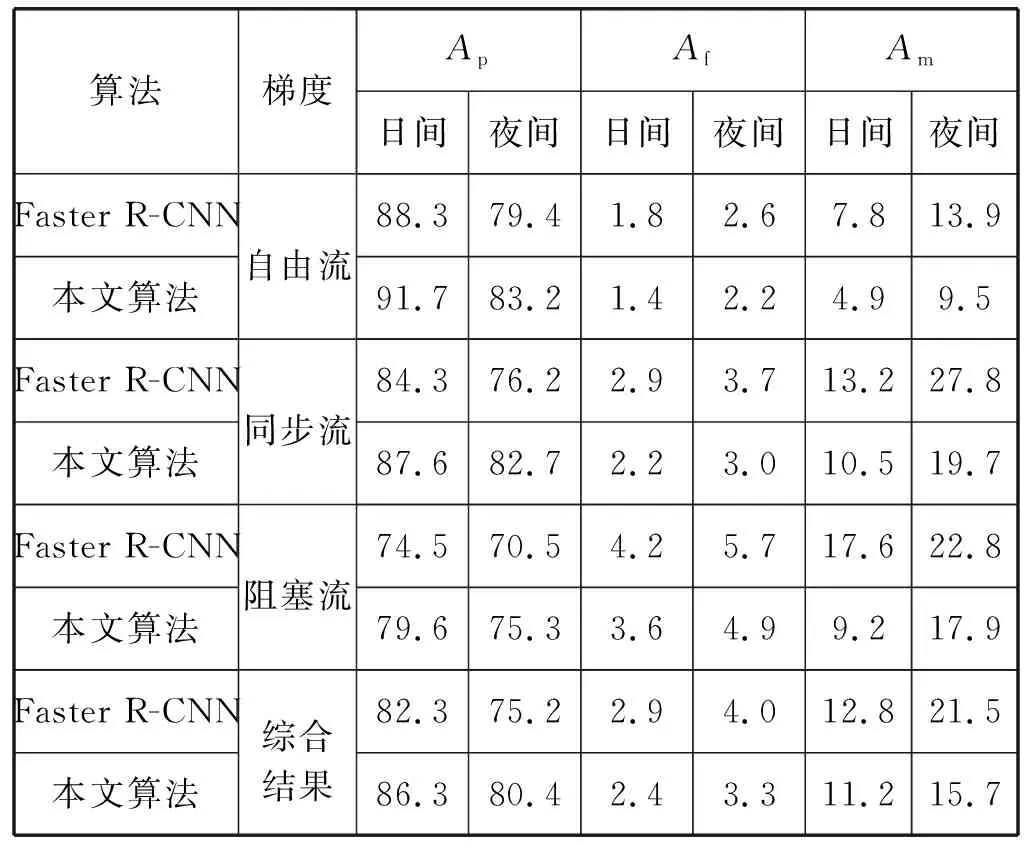
表2 Faster R-CNN与本文算法在Car_VOC数据集下日间夜间三个不同梯度下的平均准确率 %
可以看出,本文算法在日间自由流Ap为91.7%,Af为1.4%,Am为4.9%,相比Faster-RCNN提高显著。2种算法的最佳检测效果均出现在日间自由流梯度下,而在夜间阻塞流下,虽然2种算法在此状态表现最差,但是本文算法相较于Faster R-CNN其他两个状态下提升较大,从综合结果来看本文算法在监控视频下车辆检测效果优于Faster R-CNN算法。
(2) 在KITTI数据集上的实验:
将本文算法与Faster R-CNN、Yolov2[19]、OC-DPM[20]在KITTI数据集中进行对比实验,根据KITTI数据集的规定,有三个检测难度:Easy、Moderate、Hard。图9为4种算法在KITTI数据集3个不同的检测难度测试中的准确率与召回率图。

图9 4种算法在KITTI数据集下3个不同难度中的检测结果
不难看出,本文算法的准确率相较于原Faster R-CNN算法在Easy、Moderate、Hard 3个困难度下检测效果均有所提升,并且在准确率与召回率方面明显高于OC-DPM算法与Yolov2算法;本文算法相较于其他三种算法与X、Y轴所包围的面积要大,故算法平均精度(Average Precision,AP)更高。为了更好地对算法进行定量分析,本文计算所有算法平均准确率,结果如表3所示,计算方法如下:
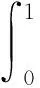
(8)
式中:Pre为准确率;Rec为召回率。

表3 4种算法在KITTI数据集下3个不同难度中的平均准确率 %
由表3数据可知,本文算法相较于原Faster R-CNN算法在3个困难度下的平均准确率分别提升了1.26%、2.56%、2.50%。KITTI数据集是由车辆摄像头在道路上的实拍图像组成,与监控视频下图像有很高的相似度,含有较大的信息冗余,利用空洞卷积减少了相邻冗余像素对特征的干扰,外加摄像头位置固定,拥挤的交通会产生一些重叠样本,而Soft-NMS较NMS更适合处理重叠样本。本文算法相较于OC-DPM和Yolov2提升较为明显,尤其是与Yolov2的一步检测相比在3个困难度下更是有着60.79%、62.36%、56.75%的巨大提升。Yolov2舍弃了候选框生成的过程,直接采用卷积神经网络获得最终结果,虽然速度得到较大提升,但准确率却大大下降。图10为在KITTI数据集上的部分检测结果。

图10 在KITTI数据集上部分检测结果
(3) 在UA-DETRAC数据集上的实验:
在UA-DETRAC数据集上进行训练和测试,并将本文算法与Faster R-CNN算法、DPM算法、R-CNN算法、Yolov2算法、SA-FRCNN算法在其测试集中进行对比实验。其中,在UA-DETRAC下,共有8个检测条件:full、easy、medium、hard、cloudy、night、rainy、sunny。图11为以上算法在UA-DETRAC数据集8个不同的条件下的召回率与准确率图,表4为在UA-DETRAC数据集下8个不同条件中的平均准确率。

表4 6种算法在UA-DETRAC数据集下8个不同条件下的平均准确率 %
从表4中可以看出,传统车辆检测算法DPM在复杂环境下的检测效果表现较差,即使在easy条件下平均准确率也没有达到35%。从R-CNN开始,基于深度学习的算法在复杂环境下例如在交通视频下车辆检测平均准确率相较于传统算法实现了质的超越,在sunny下平均准确率可以达到69.75%。本文算法相较于Faster R-CNN提升较为明显,在每个检测条件下都有提升。图12为在UA-DETRAC数据集下的部分检测结果。

图12 在UA-DETRAC数据集下的部分检测结果
4 结 语
本文将Faster R-CNN网络引入交通监控车辆目标检测中,并发现监控视频中高分辨率图像造成特征信息冗余和车辆存在大部分重叠时使用非极大值抑制使检测框丢失是其在交通监控视频下车辆检测方面存在的主要问题。本文对其进行改进,首先在网络中加入空洞卷积过滤掉高分辨率视频影像下存在的冗余特征,然后用Soft-NMS替换掉原有的NMS机制以适应车辆重叠的情况,使之更适用于交通监控视频下的车辆检测。在Car_VOC、KITTI、UA-DETRAC数据集上进行实验,实验结果表明,改进后的模型在不影响检测速度的情况下,提高了检测的准确性,尤其是在车辆产生较大重叠的情况下相较于原模型降低了漏检率。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
电子制作(2019年11期)2019-07-04
小太阳画报(2018年3期)2018-05-14
北京航空航天大学学报(2018年1期)2018-04-20
阅读与作文(小学低年级版)(2016年12期)2016-12-22
