
基于信息最大化变分自编码器的孪生神经主题模型
2020-09-09 03:09刘佳琦
计算机应用与软件 2020年9期
刘佳琦 李 阳
(中国科学技术大学计算机科学与技术学院 安徽 合肥 230027)
0 引 言
主题模型是一种基于有向概率图模型的学习文档向量化表示的方法,在自然语言处理中有着广泛的应用[1-3]。主题模型假设文档是由不同的主题构成,而每个主题可以形式化为词表上单词的概率分布。常用的主题模型有隐语义索引(Probabilistic Latent Semantic Analysis,PLSA)主题模型[4]和隐迪利克雷分布(Latent Dirichlet Allocation,LDA)主题模型[5]等。在求解主题模型的参数时,常用的贝叶斯推理方法需要对具体的问题推导闭式解并设计相应的推理算法。随着问题复杂度提高,主题模型包含越来越多的隐变量和额外信息,模型的推理过程变得愈加复杂,对其参数进行快速准确的推理变得十分困难。
变分自编码器(Variational Autoencoder,VAE)[6]作为一种深度生成模型,在机器学习领域取得了广泛的关注。与以往的贝叶斯推理方法相比,VAE通过神经网络近似模型中隐变量的后验分布。由于神经网络通常采用梯度下降的方式进行训练,简化了对隐变量后验分布的参数更新方法的推导以及相应推理算法的设计步骤。因此,一些研究人员将VAE和主题模型结合,提出了基于VAE的神经主题模型并将其应用于不同的文本处理任务中,得到了较好的实验结果[7-10]。
当使用VAE构建神经主题模型时,存在以下两个问题:(1) 神经主题模型仅针对单个文档进行建模,忽略了不同文档之间的相似度信息。直观上来说,语义接近的文档,它们对应的隐变量之间的相似度应该较高,但是神经主题模型在训练过程中没有引入文档间相似度的信息作为约束。(2) Chen等[11]指出VAE在训练过程中,存在忽视模型中隐变量的现象,使得输入和其隐变量之间的相关性弱化。以上问题导致神经主题模型不能很好地学习文档的向量表示。
County等[13]通过一种孪生网络(Siamese Network)编码变量之间的距离,在计算机视觉领域得到有效的验证。受到该工作的启发,为了引入文档之间的相似性,本文使用孪生网络对神经主题模型进行扩展,提出了孪生神经主题模型(Siamese Neural Topic Model,SNTM)和该模型的一个变种——专家乘积孪生神经主题模型(SNTM with Product of Experts,PSNTM)。两个模型均采用孪生网络结构,使得模型能够在训练过程中同时处理不同的文档,从而引入文档之间的相似度信息。在孪生网络的子结构中,为了提高输入和隐变量之间的相关性,本文使用信息最大化变分自编码器(Information Maximizing Variational Autoencoder,InfoVAE)[14]构建神经主题模型。相比于VAE,InfoVAE在训练过程中能够有效地利用模型中的隐变量,从而得到更有意义的文档的向量表示。
本文的贡献包含以下几点:
(1) 通过孪生网络结构对神经主题模型进行扩展,提出了孪生神经主题模型及其变种。与神经主题模型相比,该模型在训练过程中引入文档之间的相似度信息。
(2) 在孪生网络的子结构中,选择InfoVAE构建神经主题模型,相比基于VAE的神经主题模型,该模型的输入与隐变量之间具有更强的相关性。
(3) 使用文档检索(Document Retrieval)和主题一致性(Topic Coherence)两种方式对所提出的模型进行评估,实验结果验证了其有效性。
1 相关工作
主题模型在文档建模和信息检索中有着广泛的研究与应用。许多研究人员利用不同的信息,对主题模型进行了扩展:Mcauliffe等[15]提出了监督式主题模型(Supervised Topic Model),将文档的标签信息引入LDA主题模型,实验结果表明该模型能够有效地对文档的类别进行预测。Wang等[16]将时间序列和单词共现信息相结合,提出了时间推移主题模型(Topic Over Time Topic Model)。Rosen-Zvi等[17]将文档的作者信息考虑在内,认为不同作者对主题有着不同的偏好,提出了作者主题模型(Author-Topic Model)。Qiu等[18]对用户在社交媒体上兴趣和行为模式进行建模,提出了基于LDA的行为主题模型(LDA-based Behavior-Topic Model)。Du等[19]的研究指出,通过在主题模型中引入文档之间的相似性信息能够提高所提取的主题的质量。然而,为了引入额外信息,上述所有模型均需要精心设计概率模型和相关的推理算法。
VAE通过神经网络近似模型中隐变量的后验分布,提供了一种通用并且扩展性更强的选择。许多研究人员将VAE与主题模型结合,并取得了一定的效果。Miao等[20]选择高斯分布作为主题模型中主题的先验分布,采用VAE进行文本建模,提出了神经变分文档模型(Neural Variational Document Model,NVDM)。Srivastava等[7]通过VAE实现了LDA主题模型,称为神经变分LDA主题模型 (Neural Variational LDA,NVLDA)。Miao等[8]提出了多种不同的方式来构建文档中主题的先验分布,并研究了构建任意数量主题的实现方式。Card等[9]通过在文本建模过程中引入了文档所包含的元数据,对神经主题模型进行了扩展,改善了模型的主题一致性。Lin等[10]将注意力机制中的“sparsemax”函数引入神经主题模型中,提高了文档中主题分布的稀疏性。 然而,上述工作中均没有考虑到文档之间的相似度信息。除此之外,基于VAE的神经主题模型在训练过程中可能会忽视模型中的隐变量,从而导致输入和隐变量之间的相关性较弱。
2 神经主题模型的文本建模

1) 对随机变量θ~Dirichlet(α)进行采样,得到文档X的主题分布。
2) 对文档X中的每个单词xi:
(1) 对随机变量ci~Multi(θ)进行采样,得到主题ci的观测值。
(2) 对随机变量xi~Multi(φci)进行采样,得到单词xi的观测值。
其中,α∈RK是迪利克雷分布的参数。值得注意的是,对于每个主题对应的向量φk,同样可以选择迪利克雷分布作为其先验分布。基于文献[8],本文将其视为模型中的参数。因此,文档X的似然函数可以表示为:
(1)
式中:Φ=[φ1,φ2,…,φK]。
当使用VAE或其变种构建神经主题模型时,对于迪利克雷分布,因为很难找与之对应并且有效的重参数技巧(Reparameterization trick),所以无法使用梯度下降的方法对模型进行优化。为了解决这一问题,本文选择文献[7]的方式,通过高斯分布来近似迪利克雷先验。高斯分布的均值μ0∈RK和协方差矩阵Σ0∈RK×K的计算公式如下:
(2)
(3)
式中:αk表示向量α中的第k个元素;μ0k表示向量μ0中的第k个元素;Σ0kk表示矩阵Σ0主对角线上的第k个元素。值得注意的是,协方差矩阵Σ0为对角阵。
在得到均值μ0和协方差矩阵Σ0后,隐变量θ的先验分布可以表示为以下形式:
θ=softmax(z)
(4)
式中:z~N(μ0,Σ0)。因此,对于文档X,其似然函数可以表示为如下形式:
(5)
图1描述了神经主题模型所对应的概率图模型。
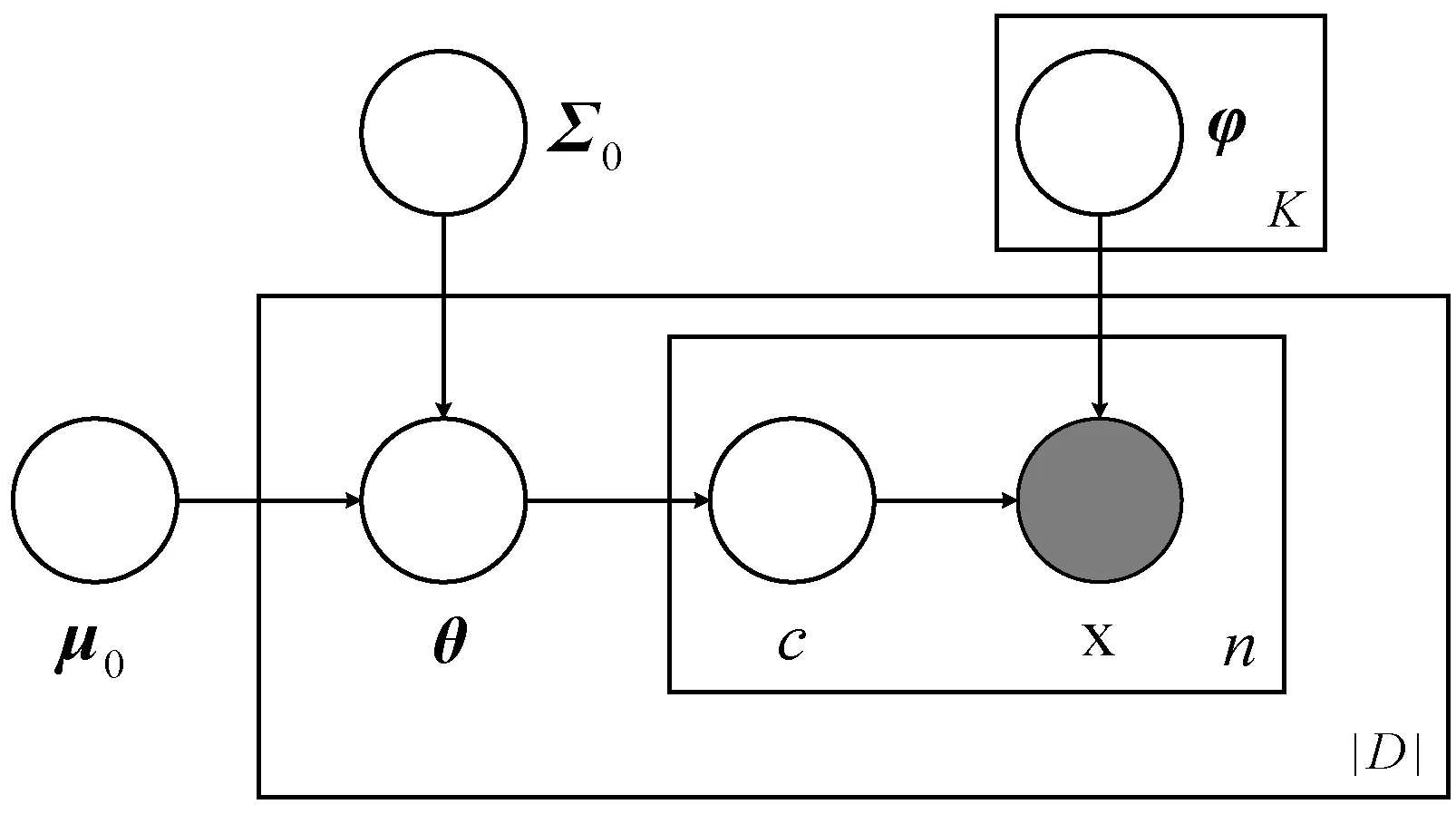
图1 神经主题模型的概率图模型
3 孪生神经主题模型
3.1 整体结构及优化目标
在神经主题模型中引入文档之间的相似度,有助于模型在计算文档表示过程中利用更多的信息。本文研究目标是构建一种能够利用文档之间的相似度信息,同时不改变神经主题模型建模结构的模型。
为此,本文使用孪生网络对神经主题模型进行扩展,使得模型整体由两组结构和参数都完全相同的神经网络构成。给定两篇不同的文档Xi和Xj,本文分别将Xi和Xj作为两个网络的输入,得到文档的向量表示zi∈RK和zj∈RK。为了使得zi和zj之间依然能够保留文档Xi和Xj之间的相似度信息,本文设计了如下损失函数:
Lsim(Xi,Xj)=(g(f(zi,zj))-sim(Xi,Xj))2
(6)
式中:sim(Xi,Xj)表示文档Xi和Xj之间的相似度;函数f(zi,zj)表示向量zi和zj之间的相似度。对于sim(Xi,Xj),本文选择能够较好地反映之间语义差异的词移距离(Word Mover Distance,WMD)[21]的相反数衡量文档之间的相似度。对于f(zi,zj),本文选择余弦相似度作为zi和zj之间的相似度度量方式。由于f(zi,zj)和sim(Xi,Xj)的取值范围并不相同,无法直接进行比较。因此本文使用一个线性函数g(x)=ax+b将f(zi,zj)转换到sim(Xi,Xj)的取值范围内,其中a∈R+,b∈R均为模型的参数。
本文所使用的孪生网络不仅需要考虑不同文本之间的相似度,还需要考虑子结构对文本的表示能力。孪生网络的子结构为神经主题模型,完成对文档的“编码-解码”过程:编码器将文档X作为输入,首先得到文档表示z,之后通过z计算出神经主题模型的隐变量θ。值得注意的是,文档表示z与θ存在如下的关系:
θ=softmax(z)
(7)
由式(7)可知,隐变量θ与z之间存在确定的依赖关系。但是相比于θ,z的取值范围更大,所以使用z作为文档表示能使得语义不同的文档之间更加分散。因此本文选择z作为文档表示。在得到隐变量θ之后,解码器将θ作为输入,计算输入文档X的条件概率p(X|θ)。至此,神经主题模型完成了对文档X的“编码-解码”过程。
通过上述分析,对于输入文档Xi和Xj,孪生神经主题模型的整体目标函数如下:
LSNTM(Xi,Xj)=LInfoNTM(Xi)+LInfoNTM(Xj)-
γLsim(Xi,Xj)
(8)
式中:LInfoNTM(·)表示基于InfoVAE的神经主题模型的目标函数;γ为模型的超参数。模型整体的网络结构如图2所示。

图2 孪生神经主题模型的整体结构
3.2 基于InfoVAE的神经主题模型
根据式(5),可以得出文档X的对数似然函数的证据下界(Evidence Lower Bound,ELBO):
KL(q(θ|X)‖p(θ|μ0,Σ02))
(9)

λ1KL(q(θ|X)‖p(θ|μ0,Σ20))-
(10)


图3 基于InfoVAE神经主题模型的网络结构
h1=softplus(W1e+b1)
(11)
h2=softplus(W2h1+b2)
(12)
μ1=W3h2+b3
(13)
log(Σ1)=W4h2+b4
(14)

(15)
式中:(xi|Φ,θ)服从多项式分布Multi(Φθ)。
目标函数中的第二项为近似后验分布和先验分布之间的KL散度,由于q(θ|X)=q(z|X)=q(z|μ1,Σ1),并且p(θ|μ0,Σ0)=p(z|μ0,Σ0)。因此分布q(θ|X)和p(θ|μ0,Σ0)之间的KL散度可转换为q(z|μ1,Σ1)和p(z|μ0,Σ0)之间的KL散度,后者存在闭式解,具体公式如下:
KL(q(z|μ1,Σ1)‖p(z|μ0,Σ0)=

(16)
值得注意的是,在训练初期,由于隐变量θ中只包含输入X中的少量信息,相比于损失函数的第一项,该项更容易优化,因此在训练过程中可能会出现信息选择(Information Preference)问题[11],导致模型倾向于将近似后验分布q(θ|X)直接设置为先验分布p(θ|μ0,Σ0),降低了模型的表示能力。为了处理上述问题,本文将该项的权重λ1设置为一个较小的值,降低该项在目标函数中所占的比例。
目标函数中的第三项J(q(θ)‖p(θ|μ0,Σ0))表示分布q(θ)和p(θ|μ0,Σ0)之间任意严格的散度。Zhao等[14]指出通过在目标函数中添加该项能够提升近似后验分布q(θ|X)中θ和X之间的互信息。本文根据文献[14]的建议,使用最大平均差异(Maximum Mean Discrepancy,MMD)度量分布q(θ)和p(θ|μ0,Σ0)之间的散度。令κ(·,·)表示任意正定核函数,分布p和q之间的最大平均差异定义如下:
MMD(p‖q)=Ep(θ),p(θ′)[κ(θ,θ′)]+Eq(θ),q(θ′)[κ(θ,θ′)]-
2Ep(θ),q(θ′)[κ(θ,θ′)]
(17)
本文选择高斯核函数进行计算。值得注意的是,高斯核函数通常要求输入数据的每一维均值为0,方差为1。隐变量θ显然并不满足上述要求,为了处理该问题,本文将分布q(θ)和p(θ|μ0,Σ0)之间的最大平均差异替换为分布q(z)=q(z|X)pD(X)和p(z|μ0,Σ0)之间的最大平均差异。一方面,本文可以对z进行批标准化处理,使得其每一维均值为0,方差为1,同时不影响隐变量θ的物理意义;另一方面,当且仅当q(θ)=p(θ|μ0,Σ0)时,MMD(q(z)‖p(z|μ0,Σ0))=0。依然满足了严格散度的要求。
4 专家乘积孪生神经主题模型
神经主题模型认为文档是由不同主题合成,每一个词都与一个特定主题相关。在文献[7]中,作者提出了一种新的能够提高模型主题一致性的建模方法,该方法不需要显式地对每个主题中单词的分布建模,而是直接对文本中单词的概率分布建模。在计算方式上与之前的建模方法相比,区别在于该方法放松了每个主题对应的向量φk中所有元素的和为1的要求。具体描述为:在给定θ的条件下,单词xi|Φ,θ服从多项式分布Multi(softmax(Φθ))。值得注意的是,矩阵Φ被视为模型中的参数。
在上述建模方法中,单词xi的概率分布的计算方式可以视为Hinton提出的专家乘积模型(Product of Experts)[22]。基于以上分析,本文将上述修改应用在孪生神经主题模型中,得到了专家乘积孪生神经主题模型。
5 实 验
5.1 实验数据集
本文选取20Newsgroups、REUTERS和BBC三个新闻数据集进行实验。20Newsgroups数据集包含了20个不同类别,近20 000个新闻组文档,其训练集大小为11 314,测试集大小为7 531。REUTERS数据集包含了路透社1987年新闻专线数据。本文选择文献[23]中所使用的8个类别版本的划分结果,记为R8,其中训练集大小为5 485,测试集大小为2 189。 BBC数据集大小为2 225,包含了5类不同类型的新闻数据。本文随机地从中选取了400个文本作为测试集,其余的数据作为训练集。
5.2 评估方式
为了评估本文模型的文档表示能力以及挖掘文本中潜在主题分布的能力,使用文档检索(Document Retrieval)和主题一致性(Topic Coherence)检测模型的有效性。
(1) 文档检索。文档检索任务用于检测模型的文档表示能力。本文采用文献[24]的实验方式,将测试集中的每个文档作为查询,根据文档表示之间的余弦相似度从训练集中获取一定数量的检索文档,之后将检索文档中与查询文档具有相同标签的文档的比例作为精度。本文使用P@10(Precision At 10)值(从训练集中选取和查询文档距离最小的10个文档时的精度)作为评估指标,检测所提出模型的文档表示能力。
(2) 主题一致性。主题一致性用于评估模型从文本数据中所提取的主题的质量,反映了模型提取的主题中单词分布的解释性。本文采用文献[25]所提出的计算方式衡量主题一致性。对于每个主题,本文选取概率分布最大的前10个单词,使用各个单词之间的归一化的点互信息(Normalized Pointwise Mutual Information)计算每个单词的向量表示,之后计算每个单词之间的余弦相似度的均值(记为TC)。在得到所有主题的TC后将其均值作为评估指标,记为ATC。ATC越大,整体的主题一致性越好。
5.3 对比模型
本文选择NVDM、NVLDA和ProdLDA三种不同的模型进行对比实验。
NVDM:Miao等在文献[20]中提出了神经变分文档模型(NVDM)。 NVDM使用变分自编码器对文档进行建模,使用高斯分布作为文档的主题分布,与“主题-词”矩阵相乘之后进行归一化得到文本中单词的分布情况。
NVLDA/ProdLDA:在文献[7]中,作者在VAE的框架下实现了LDA主题模型(NVLDA)。随后,对该模型进行修改,将文档建模过程中的“主题-词”多项式分布混合结构替换为专家乘积模型并称之为ProdLDA。相比于NVLDA,ProdLDA在数据中提取的主题的一致性较好。
5.4 实验设置
对于所有数据集,本文去除文本中所有非UTF-8字符,之后将数据集中的所有单词转换为小写形式并去除停止词。对于BBC数据集和20Newsgroup数据集,本文选择其中出现次数最多的2 000个单词作为词表。对于R8数据集,本文选择文献[21]中所采用的大小为13 311的词表。
本文模型需要不同文档之间的词移距离作为输入。对于BBC和R8数据集,本文计算了训练集中任意两个个体之间的词移距离。由于20Newsgroup数据集的训练集较大,计算其中任意两个个体之间的词移距离所花费的时间较长,因此对于训练集中的每个个体,本文随机地选取200个与其不同的个体计算它们之间的词移距离。对于文档检索任务,本文对所有数据集的训练集上划分出10%的数据作为验证集。
在所有实验中,编码器部分的每层神经网络的节点数量为100。对于主题数量K,本文基于文献[20],分别对K=50和K=200进行实验。对于超参数λ1,本文在所有实验中将其设置为0.01。本文使用Adam优化算法[26]对模型进行训练,在所有实验中,SNTM和PSNTM学习率的分别设置为0.005 0和0.002 0。对于模型中其余的超参数,本文使用网格搜索的方式进行选择。
5.5 结果与分析
(1) 文档检索实验。表1和表2分别显示了当主题数量K分别为50和200时,各个模型在三个数据集上P@10值。可以看出,当主题数量K=50时,SNTM在BBC数据集上表现最优,PSNTM其余的两个数据集上表现最优;当主题数量K=200时,PSNTM在R8数据机上表现最优,SNTM在其余的两个数据集上表现最优。除此以外,SNTM和PSNTM在所有实验中表现均优于对比模型。

表1 当K=50时,所有模型在各个数据集上的P@10值 %

续表1

表2 当K=200时,所有模型在各个数据集上的P@10值 %
为了直观地显示各个模型在文档检索任务中的表现,本文计算了当主题数量K=50和K=200时,各个模型在20Newsgroup数据集上使用不同文档检索比例时的精度。图4和图5显示了相应的实验结果。可以看出,在不同的文档检索比例下,SNTM和PSNTM的表现均优于对比模型。

图4 当K=50时,所有模型在20Newsgroup数据集上文档检索任务表现

图5 当K=200时,所有模型在20Newsgroup数据集上文档检索任务表现
文档检索任务的实验结果表明,SNTM和PSNTM在计算文档的向量表示时,能够较好地保留文档中的语义信息,使得同类文档之间的相似度更高,在文档检索任务中表现更好。
(2) 主题一致性实验。表3和表4分别显示了当主题数量K分别为50和200时,各个模型在不同数据集上的ATC。实验结果表明,除了当主题数量K=50时,SNTM在R8数据集上表现最好以外,PSNTM在其余的实验中表现最好。值得注意的是,NVLDA与SNTM的子结构具有相同的概率图模型。从实验结果中可以发现:相比于NVLDA,SNTM在各个数据集上的主题一致性表现略有优势;ProdLDA和PSNTM均使用了专家乘积代替文本建模过程中的“主题-词”多项式分布结构;相比于ProdLDA,PSNTM在各个数据集上的主题一致性表现更好。

表3 当K=50时,所有模型在各个数据集上的ATC

表4 当K=200时,所有模型在各个数据集上的ATC
表5显示了PSNTM在20Newsgroup数据集上所提取的一些具有代表性的主题,每个主题由该主题下概率分布最大的10个单词表示。表5的第一行是每个主题的简要概括。可以发现,单词和主题之间的匹配程度较好。

表5 PSNTM在20Newsgroup数据集上提取的部分主题

续表5
(3) 文档间相似度信息对模型的影响。为了分析文档间相似度信息对所提出的模型在文档检索和主题一致性中的影响,本文使用SNTM在R8数据集上进行实验。由于超参数γ是目标函数L(Xi,Xj)中Lsim(Xi,Xj)项的权重系数,控制文档间相似度信息对模型的影响。因此在实验过程中,模型中的其余超参数不变,γ取值范围为{0,30,60,90,120}。表6显示了当γ取不同值时,SNTM在R8数据集的验证集上所取得的P@10值和ATC。可以看出,相比于γ=0(即模型中不引入文档之间的相似度信息),当γ取其余不同的值时,模型的文档检索精度和主题一致性均得到了不同程度的提升。该实验结果验证了在神经主题模型中引入文档之间的相似度信息,能够改进模型在文档检索任务中的表现和增强模型所提取的主题的一致性。
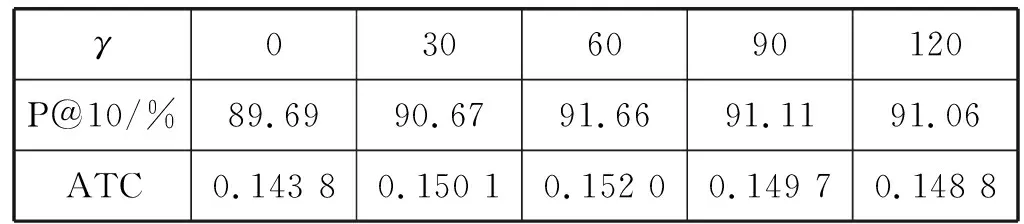
表6 超参数γ取不同值时,SNTM在R8数据集的验证集上所取得的P@10值和ATC
6 结 语
本文提出了孪生神经主题模及其变种——专家乘积孪生神经主题模型。两个模型整体采用孪生网络结构,能够在训练过程中引入文本之间相似度信息。对于孪生网络中的子结构,本文使用信息最大化变分自编码器构建神经主题模型,提升了模型中隐变量和输入之间的相关性。在三个不同的数据集上的实验结果表明,和对比模型相比,本文模型在文档检索任务中有更好的表现。除此之外,模型从文本数据中提取的主题具有良好的一致性。
猜你喜欢
客联(2022年3期)2022-05-31
计算机研究与发展(2022年1期)2022-01-19
中国新闻周刊(2021年26期)2021-07-27
计算机应用(2020年12期)2020-12-31
科学与财富(2019年27期)2019-10-25
电子制作(2019年14期)2019-08-20
科学与财富(2017年28期)2017-10-14
电脑爱好者(2017年7期)2017-05-06
文苑(2015年9期)2015-09-10
