
基于改进生成式对抗网络的图像超分辨率重建
2020-09-09 03:14贾振堂
计算机应用与软件 2020年9期
米 恒 贾振堂
(上海电力大学电子与信息工程学院 上海 200090)
0 引 言
图像超分辨率重建是机器视觉领域的经典应用分支,基于低分辨率图像(LR),重构得到一幅高分辨率图像(HR),并还原低分辨率图像(LR)中的细节信息。该技术被广泛应用于高清成像、军事卫星、医学构图等领域,所以图像超分辨率技术一直广受学术界关注。
深度学习技术出现于2006年,并发表于《科学》杂志,近年来得到快速发展[1-3]。2014年,Dong等[9-11]应用深度学习方法来完成图像超分辨率,将卷积神经网络(CNN)用于图像超分辨率,即SRCNN。该神经网络学习数据集中大量的HR、LR图像对数据,可以建立一个输入低分辨率图像(LR),输出高分辨率图像(HR)的函数映射关系[6-8]。SRCNN算法的提出,证明了深度学习应用于图像超分辨率领域的理论可行性。
自SRCNN问世以来,前人增加了卷积神经网络的结构层数,图像超分辨率重建性能也随之提高。研究结果表明,增加网络的层数可以得到更好的重建效果,但也会增加数据的维度和计算量,容易导致网络训练梯度过大或消失,使网络不易收敛,在一定程度上限制了网络结构的发展[5]。Kim等[4]引入了残差网络(Resnet)思想,在深层网络结构上采用跳跃连接(skip connection)的方式,通过将特征图累加的方式来解决梯度过大和消失的问题,极大地改善了深层次网络收敛难的问题,也可以加入更多深层次的网络结构,扩大了网络层数。基于残差网络思想,Ledig等[20]提出了基于生成式对抗网络的图像超分辨率(SRGAN)。SRGAN设计了深层次的生成网络重建图像(SR),鉴别网络将重建图像(SR)与高清图像(HR)进行比较,给出鉴别结果[11-13]。经过生成网络和鉴别网络的相互博弈,重建图像(SR)的质量不断朝着更像真实图像(HR)的方向改进。与SRCNN相比,SRGAN使重建效果更加真实,质量更好。
然而,在实验中发现,SRGAN的重建图像观感仍然不够真实,与真实图像仍有差距。本文对SRGAN的组成部分进行研究,并对损失函数和网络结构进行改进。首先,SRGAN的感知损失函数仍然以像素差异为目标进行优化,并且损失函数的主体是均方误差形式的L2型损失函数,因此该形式的损失函数不符合人类视觉系统(human visual system,HVS)的定义。该形式的损失函数一味追求极小的像素值均方误差,而忽略了图像的SSIM指标,导致仍然存在结果过度平滑、缺少高频信息、图像观感不真实等问题。本文在SRGAN的感知损失函数基础上设计了L1型的基于SSIM优化的损失函数,使重建效果更符合人眼能够接受的本质特征。在SRGAN中,LR图像的特征信息都是通过单一尺度的特征提取层提取的,这样会导致无法充分提取LR图像的特征信息,遗漏掉某些频段的信息[16-17]。本文在SRGAN生成网络结构基础上加入3种不同尺度的卷积核,通过多个不同尺度的卷积核提取LR图像更多层次的特征信息,然后将提取到的特征图输入到残差网络中进行全局残差学习,输出特征与低分辨率图像特征融合初步重建出HR图像。接着去除生成网络中的批规范化层(BN层),引入图像上采样步骤,再加入1×1像素值尺度的卷积核对高频信息降维,最终输出HR图像。
1 理论基础
1.1 生成式对抗网络
生成式对抗网络(GAN)理论基础受博弈论启发[18],GAN网络中博弈双方分别为生成器(Generator)和鉴别器(Discriminator)。生成器不断学习真实数据的分布,基于该分布的噪声生成一个类似于真实数据的样本。而鉴别器目的是判别样本数据是否是真实数据,如果是,则输出1,反之,则输出0。基于这种博弈思想,生成器不断学习并生成和真实数据一样的数据样本,使鉴别器无法分辨真假,达到骗过鉴别器的目的,而鉴别器则试着鉴别生成器生成的样本[14-15]。在这个过程中,双方不断更新网络权值配置,最终双方达到一个动态平衡的状态,此时生成器生成了和真实数据一样的样本,鉴别器无法准确判别出结果,优化过程目标函数为:
minGmaxDV(D,G)=Ex~pdata[logD(x)]+
Ez~pz[log(1-D(G,Z))]
(1)
在更新参数时,采用交替更新,即采用固定一边,更新另一边的方式,更新方式如下:
当固定G更新D时,对于来自真实数据pdata的样本x而言,通常希望D确定为真实数据样本,即D的输出接近1的大概率,logD(x)数值比较大。对于生成器学习生成的数据G(z),通常希望D能够分辨出真假数据,即D输出接近0的小概率,D(G(z))数值比较小,接近于0,所以log(1-D(G(z)))数值应该比较大,也需要最大化更新。
当固定D更新G时,通常希望生成数据G(z)尽可能接近真实数据,即pg=pdata,此时要求D(G(z))尽量接近1,即log(1-D(G(z)))数值应该比较小,因此需要最小化G。
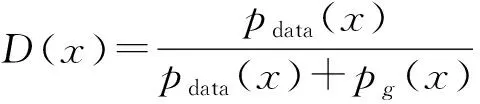
1.2 基于生成式对抗网络的图像超分辨率重建
基于GAN的架构,Goodfellow等[21]将GAN与图像超分辨率重建结合,提出了用于图像超分辨率重建的GAN网络(SRGAN)。与SRCNN相比,由于引用了残差网络思想,SRGAN能够加入更多网络层数,处理较大的放大倍数,网络性能优于SRCNN。并且SRGAN重新定义了生成模型G和鉴别器D,网络对生成器G进行训练生成重建高分辨率图像(SR),再通过训练鉴别器D鉴别生成图像(SR)是否是真实图像,通过GAN网络里的博弈思想使生成重建图像(SR)骗过鉴别器D,使输出重建图像SR的视觉效果更加真实,一定程度上改善了SRCNN重建图像过度平滑、缺少高频的问题。
如图1所示,生成器网络结构由3个3×3卷积层,2个完成上采样的视觉层,1个特征融合层以及1个残差网络构成。其中,残差网络由若干个残差块相互跳跃连接组成,每个残差块中包含2个3×3的卷积层,卷积层后接批规范层,激活函数为LeakyRelu,2层上采样层被用来增大尺寸,特征融合层与LR短接用来重建生成图像。在鉴别器网络中,网络中有多层卷积层,激活函数采用LeakyRelu,最后由2层全连接层输出判定概率,输出激活函数为sigmoid函数。
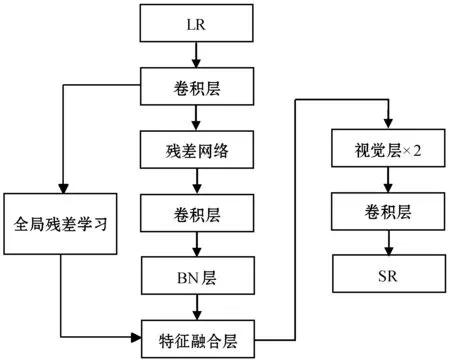
图1 生成器网络结构
SRGAN的损失函数为:
(2)
(3)
式中:r、W、H是单幅图像的尺度数据,分别是图像通道数、宽度、高度。
(4)
式中:φi,j是通过VGG19网络得到的特征图;i表示VGG19网络中的第i个最大池化层;j表示卷积层的层数,VGG损失函数定义了重建图像特征分布GθG(ILR)和真实图像IHR之间的欧式距离。相应地,Wi,j和Hi,j是VGG网络中对应特征图的维数。通过VGG损失函数,可以准确提取VGG19网络上某一层的特征图,并将提取的特征图和真实图像的特征图进行比较。对抗损失函数就是GAN模型定义的鉴别器在所有的生成重建图像样本上的概率判断:
(5)
由式(3)-式(5)可以看出,SRGAN定义了基于内容损失与对抗损失加权和的感知损失函数,并将VGG损失引入到内容损失中,使网络能够根据VGG19网络提取的特征图之间的欧式距离来进行优化,并且能够将博弈思想中的对抗性质的相似性引入到传统的像素空间的像素差异中,基于这些改进,达到改善效果的目的。
2 改进方法设计
2.1 方法介绍
通过研究发现,SRGAN重建图像效果相比SRCNN模型在纹理细节和观感上均有提升,但与真实图像相比,效果仍然还有提升空间。通常对于图像超分辨率,特征提取网络结构的设定和损失函数的定义至关重要。因此,本文从网络的特征提取结构和损失函数这两个关键组件入手。首先,虽然SRGAN网络引入了VGG损失函数,使网络更容易提取图像的高层特征图,相比以MSE为目标优化的损失函数提升了细节,但是在损失函数的定义上是针对空间像素值差异进行优化的,没有将图像更多的观察特性定义到损失函数中去,并且损失函数形式是基于均方误差的L1形式导致重建图像在实际观感上和真实图像仍然有差距。其次,单一尺度的卷积核进行特征提取会造成LR图像细节信息丢失。本文对SRGAN的感知损失函数和生成器网络结构进行改进,基于SSIM设计L1形式的损失函数并加入到现有的感知损失函数中,替换掉基于MSE的L2型损失函数,保留VGG损失函数,将SSIM损失函数、VGG损失函数以及对抗损失函数进行加权求和作为改进后的感知损失函数。在SRGAN的生成器网络结构里加入多尺度卷积核对输入图像进行特征提取,使SRGAN从LR图像里提取更多细节信息。
2.2 损失函数的改进
本文基于结构相似性(SSIM)设计损失函数,在深度学习中,处理真值和预测值的欧式距离等回归问题通常采用L2形式的损失函数,非凸形式而且可微分[19],例如常用的MSE损失函数。这种形式的损失函数问题在于没有考虑人类的视觉系统HVS(human visual system),HVS包含了图像局部光照、颜色变化等细微变化信息,基于像素值差异的损失函数没有将符合HVS的指标,所以,本文设计了以SSIM为目标的损失函数,SSIM损失函数形式上属于L1形式,没有均方误差项,并且SSIM的理论设计和HVS一致,即可以体现图像局部结构、色彩、光照等变化,损失函数形式可导,可以用作损失函数。通常,PSNR定义为:
(6)
可以看出,PSNR的计算是以MSE为基本进行计算的,这就造成了SRGAN网络在训练时过度追求极小的MSE,得到较高的PSNR值,但重建出来的图片通常缺乏高频内容,细节纹理过于平滑,图像整体观感失真。而本文基于人眼对图像局部光照、灰度变和结构化敏感的光学特性,设计了SSIM损失函数,定义如下:
(7)
对于两个图像之间的结构相似性,0表示完全不同,1表示完全相似。其中:μxμy是图像X,Y所有像素的平均值;σxy是图像X,Y像素值的方差;C1、C2和C3均为常数。SSIM可以看作3个比较部分,分别是:
图像照明度比较部分:
(8)
图像对比度比较部分:
(9)
图像结构比较部分:
(10)
可以看出,因为SSIM加入了图像照明度、图像对比度、图像结构这3个更加符合人类眼球观感的衡量指标,所以重建出来的图像更贴近人眼的光学观测特性。SSIM数值大小通常在0~1之间,越接近1表示两幅图像之间的差异性越小,由于在网络训练的过程中损失函数是朝着不断变小直至收敛的方向迭代优化的,要使重建图像和真实图像之间的SSIM数值随着迭代次数增加接近1,可以设计SSIM损失函数如下:
(11)
式中:Xi与Yi表示重建图像SR与真实图像HR;θ表示网络权值参数和偏置;i表示遍历整个训练集的序号。
2.3 网络结构的改进
在生成器网络结构上,本文基于SRGAN生成器网络结构基础上引入了多尺度底层特征提取结构,如图2所示。
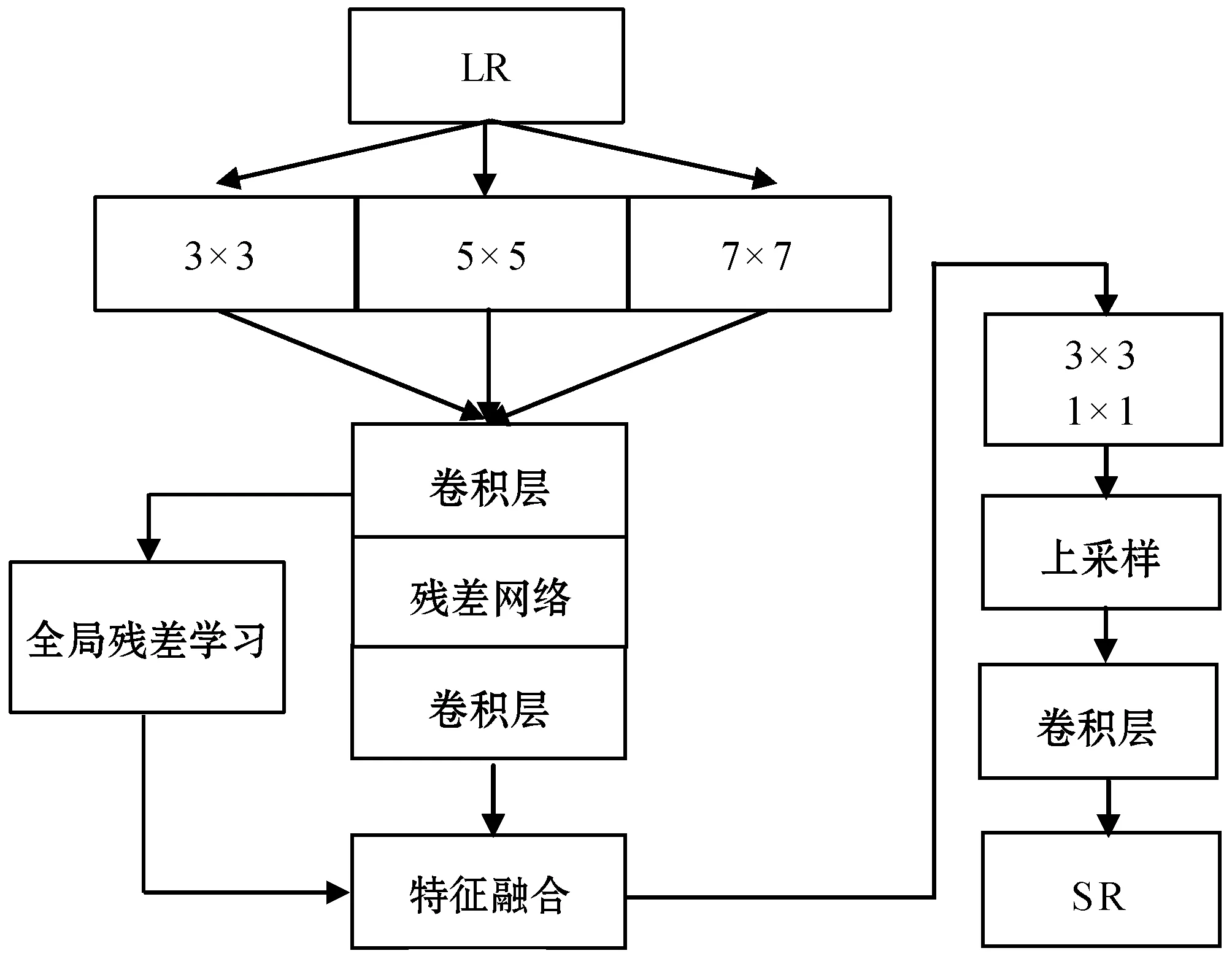
图2 改进的生成器网络结构
本文使用尺度分别为3×3、5×5、7×7像素值的卷积核提取特征。基于Googlenet思想进行直接连接,会造成经过多尺度卷积层后,输出维度过大的状况,故本网络采用Maxout激活函数,使最终的输出维度不会很大,并对输出特征经过一个1×1大小的卷积核,再次起到降维的作用。将提取到的底层特征图输入密集残差网络进行处理,由于密集残差网络内部每一层的卷积层之间采用跳跃连接的方式,每一层之间都可以保证短接,这样最终输出特征既不会维度过大导致梯度爆炸,也不会出现梯度消失的情况。另外,去除BN层,使用上采样层替代,因为根据He等的实验结果,使用BN层来归一化特征会大量增加网络计算量,占用较多内存。
F=H3×3(ILR)
(12)
式中:H3×3表示用3×3像素的卷积核进行卷积操作得到低分辨率图像特征图。同理,基于式(12)可以提取到5×5像素和7×7像素卷积核的图像特征图。
如图3所示,残差块网络内部的特征提取单元由多个卷积层和激活层的组合单元构成,加深了网络的结构层数。
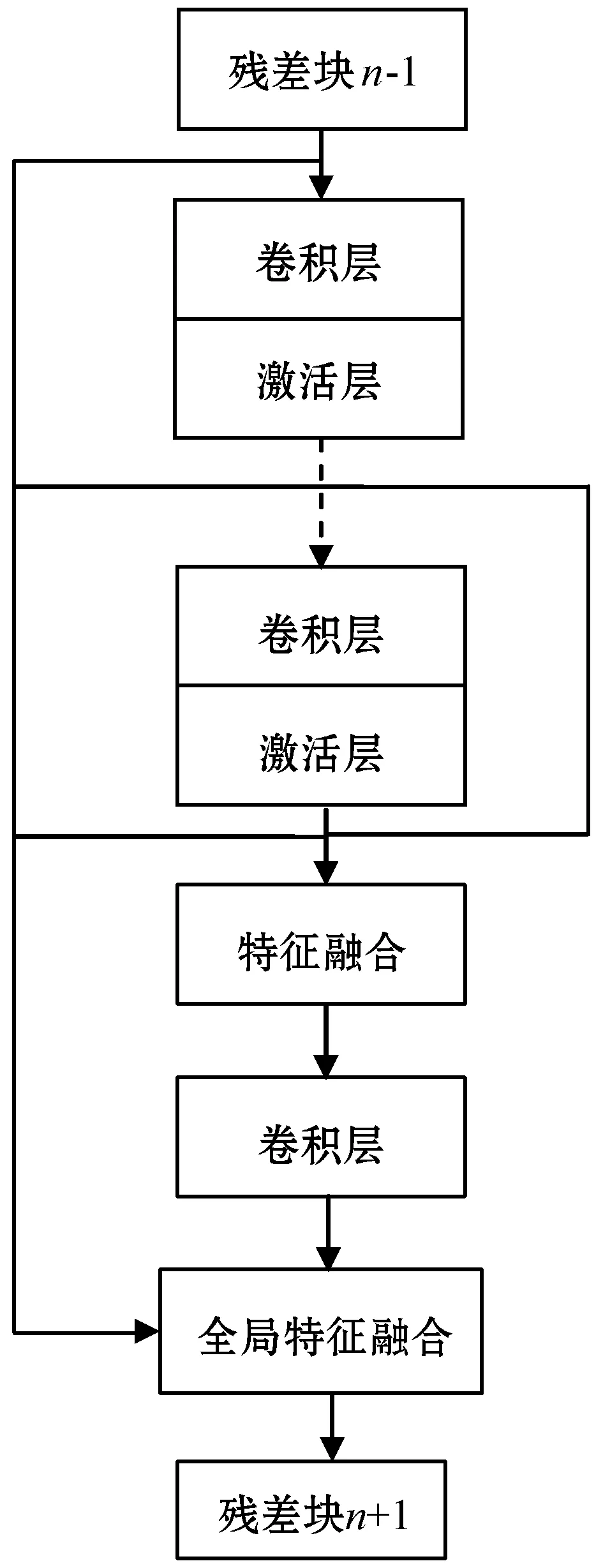
图3 残差网络结构
同时,网络内部采用跳跃连接的连接方式,即各个单元之间相互串接。具有相同特征映射大小的所有特征映射通过此方式连接,并且每个层的输入被添加到所有先前层的输出。从前层到后续层的这条短路径不仅减轻了梯度消失的问题,而且增强了特征传播,促进了特征重用,并保留了前向传播的特性将卷积层和活动层的输出附加到后续卷积层的输入。这种方法使网络具有连续存储功能并连续发送每层的状态。这样可以高效地利用每一层网络,防止网络梯度冗杂,造成梯度爆炸。
经过残差网络里的卷积层和激活层后,第一个残差块的输出为:
F1=max(c(RDBn-1),0)
(13)
后续特征图经过d个特征提取单元后的结果为:
Fd=Fd-1(…(F1)…)
(14)
特征图输入到残差块网络中,残差块网络的内部残差块之间也采用跳跃连接的方式,即上一个残差块的输出会接入到下一层残差块的输出,达到内部残差学习的效果。
fRDBn+1=fRDBn-1+F1×1(PFF(F1,F2,…,Fm))
(15)
式(15)表示经过n+1个残差块的残差网络后的输出;m表示提取特征单元的数目;n表示残差块的数目;PFF表示特征融合;F1×1表示用1×1像素值的卷积核卷积,进行降维。
在残差网络提取到图像多层局部密集特征后,进行全局特征融合,在重建前与未经过残差网络处理的特征图再次融合,形成全局残差学习,有利于保持网络训练时的梯度,防止梯度弥散或梯度消失。
3 实 验
3.1 实验参数设置
本文实验基于Google云服务器完成,配置为Kaggle k80图形处理器,12 GB运行内存,运行环境为Windows 10系统,深度学习环境框架为TensorFlow,CUDA加速版本为CUDA Toolkit 8.0,OpenCV3.4版本。本文将学习率设置初始值为0.000 1,当训练到一半的epoch时更新学习率,学习率会适当衰减以防止训练时间过长。本文优化器采用随机梯度下降法(SGD)来训练网络。
3.2 训练过程
本文的训练集和测试集采用DIV2K数据集,该数据集包括了1 000幅HR图像,图像细节部分比较清晰,适合用作图像超分辨率。
在训练过程中,训练每个LR图像生成重建的SR图像,并且在数据集中使用相应的HR图像来计算两个图像之间的损失值。神经网络模型通过这种从LR到SR再到HR这种端到端的映射关系学习网络中的权值参数配置。
3.3 实验结果及分析
为了具体评价本文方法的效果,在同一数据集下分别对比测试了SRCNN方法、SRGAN方法和本文方法。实验结果采用主观观感感受评价和客观数据指标评价。主观观感感受评价就是直接通过人眼观察给出评价意见,客观数据指标评价是以目前主流的峰值信噪比PSNR和结构相似性SSIM来评价分析。
峰值信噪比是用来衡量两幅图像之间的像素值差的量度,可以用于评价图像质量,单位为dB,定义如下:
(16)
(17)
式中:m和n分别为图像的长和宽。
结构相似性衡量两幅图像的相似度,度量范围[0,1],值越大就表示两幅图像相似度越大
(18)
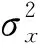
表1和表2分别表示本文方法和对比测试方法的PSNR和SSIM值,本文选取了部分图像作为展示效果。从图4(a)和图4(b)的展示结果可以看出,SRGAN相比于SRCNN的效果,在图片明亮度、清晰度、对比度上均有提升。例如对城堡墙壁的还原,使用SRCNN方法还原得到的图像较模糊,而使用SRGAN方法还原得到的细节较清晰真实,相比SRCNN有明显提升。对于本文方法,从图片展示效果可以看出,在图4(c)城堡顶部的阴影处的纹理和背景纹理过度的地方,本文方法的锐化处理更加自然一些,在图5(c)蝴蝶背部翅膀的花纹图案上,本文方法相比SRCNN和SRGAN都更加柔和真实、观感更加舒适、翅膀上的斑点细节还原的最多,也是这几种方法中最接近真实图像的。同样,从图6(c)与图6(a)和图6(b)的对比也可以看出,企鹅后脑部位的黄色羽毛细节也是本文方法还原较多,黑白两色羽毛间的纹理过度也处理得较好。
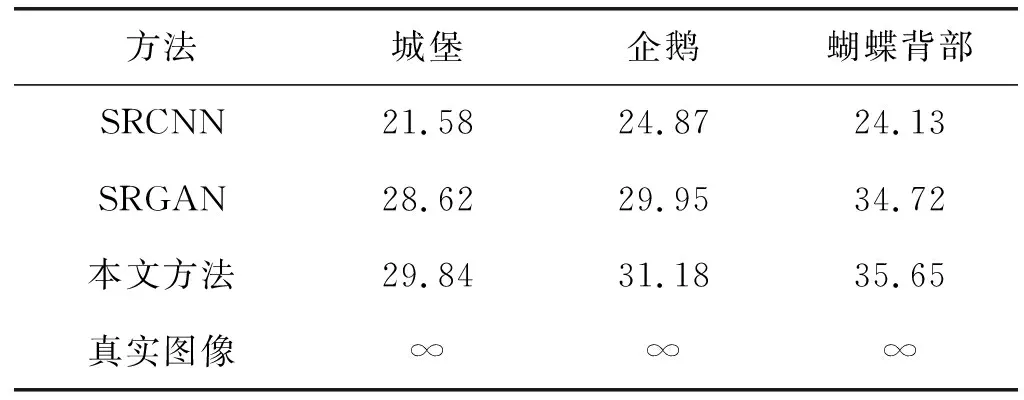
表1 重建图像的PSNR值 dB
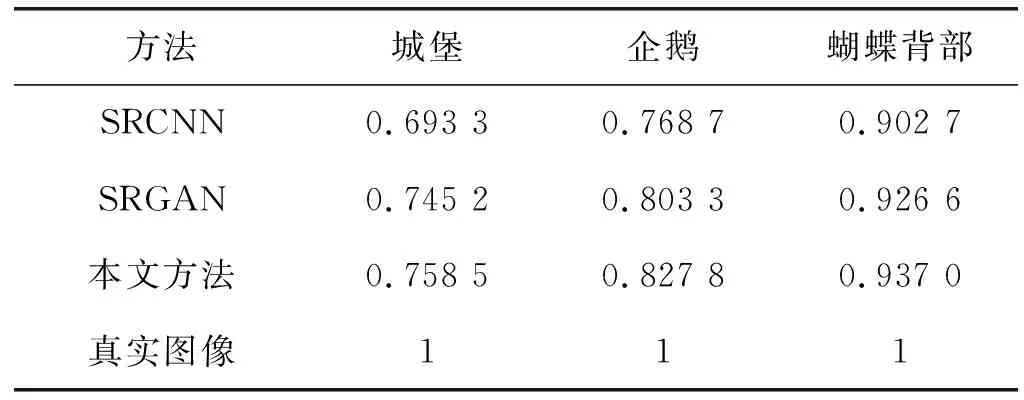
表2 重建图像的SSIM值

(c) 本文方法 (d) 真实图像图4 城堡图结果对比
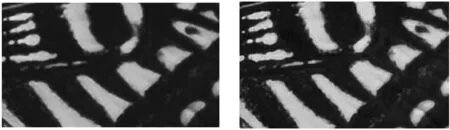
(a) SRCNN方法 (b) SRGAN方法
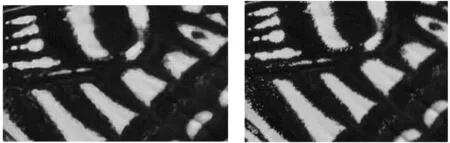
(c) 本文方法 (d) 真实图像图5 蝴蝶背部结果对比

(a) SRCNN方法 (b) SRGAN方法

(c) 本文方法 (d) 真实图像图6 企鹅图结果对比
而在客观评价指标下,本文方法的表现均优于其他主流方法,相比SRGAN模型本文模型在峰值信噪比(PSNR)上提高了1.22、1.23、0.93 dB,在结构相似性(SSIM)上提高了0.013 3、0.024 5、0.010 4,可以证明本文方法训练的模型测试得到的效果显著好于其他方法。
4 结 语
本文对前人提出的SRGAN网络算法上进行了改进,重新设计了损失函数的形式并引入了多尺度卷积核模型,改善了图像超分辨率后过度平滑,丢失细节的问题,提升了图像重建效果。实验结果表明,使用本文方法得到的重建效果在主观评价和客观指标评价上均好于SRCNN和SRGAN,证明了其有效性。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
西安邮电大学学报(2020年1期)2020-12-17
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
计算机系统应用(2019年9期)2019-09-24
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
