
基于mRMR-RF特征选择和XGBoost模型的钓鱼网站检测
2020-09-09 03:15毕青松梁雪春陈舒期
计算机应用与软件 2020年9期
毕青松 梁雪春 陈舒期
(南京工业大学电气工程与控制科学学院 江苏 南京 211816)
0 引 言
钓鱼网站,作为一种伪装成合法网站的虚假网站,是诈骗者通过合法网站的漏洞加入一些病毒代码,通过用户在网站输入来窃取用户的银行卡、信用卡等账号密码以及其他私人信息资料[1]。诈骗者利用用户好奇以及不设防的心理,将钓鱼网站的界面做得与合法网站极其相似,用户在浏览网站时如果不仔细观察根本无法分辨出来,大大降低了用户个人账户信息的安全保障,从而直接损失用户的利益。根据我国反钓鱼网站数据显示,2019年4月该网站共处理钓鱼网站2 414个,环比增长了66.5%,截至2019年4月,反钓鱼网站处理的钓鱼网站数量达到440 995个。
目前钓鱼网站检测方法主要有黑白名单过滤技术[2-3]、钓鱼网站URL地址分析[4-5]和提取网站相关特征来识别钓鱼网站[6-7]。其中,提取网站相关特征来识别钓鱼网站拥有更高的准确率,但是识别效率低,且提取页面特征较为复杂。
针对上述检测方法,众多学者采用机器学习分类算法进行分类检测。比如,文献[8]利用SVM算法分析钓鱼网站URL地址进行识别,但是该方法只对低维小样本数据有较高的预测准确率。文献[9]采用K-means算法对URL特征进行聚类处理,以达到预测的目的,但是该方法分类性能有限。文献[10]提出基于K-means和SVM相结合算法来识别钓鱼网站,该方法虽然提高了预测准确率,但是其只针对低维小样本数据,对于高维数据的预测效果并不理想。
针对上述问题,本文提出一种基于mRMR-RF特征选择和XGBoost模型的钓鱼网站检测方法。在特征筛选阶段,结合了过滤型算法泛化性能好、计算开销小、效率高和装箱型算法模型性能更好的优点。先通过过滤型算法mRMR计算特征之间以及特征与类变量之间的互信息来对特征进行排序,再通过装箱型算法RF计算袋外数据误差值对特征的重要性再次排序,测试不同的特征数对模型准确率的影响来找到最佳的特征数k。综合上述两种特征筛选后的特征排名选出前k个特征得出最优的特征子集,相比未筛选的特征集,最优子集大大降低了无关冗余的特征,对钓鱼网站预测准确率有了明显的提高[11]。在模型分类阶段,采用分类准确率更高的XGBoost集成学习算法作为分类模型,从而进一步提高预测钓鱼网站的准确率。
1 基础理论
1.1 互信息
互信息常被用来对特征间的相关性进行评价,是一种有效的信息度量方法。1994年,Battiti[12]第一次将互信息用于特征筛选,并将其定义为从n个原始特征中找出最相关的k个特征的过程。设X={x1,x2,…,xm}和Y={y1,y2,…,ym}为两个离散随机变量,p(x,y)是X和Y的联合概率分布函数,p(x)和p(y)分别是X和Y的边缘概率分布函数,则X和Y的互信息可以定义为:
(1)
直观上,互信息度量两个变量的共享信息,是其中一个变量对另一个变量提供信息的程度。例如,如果两个变量X和Y相互独立,并且变量X和Y互不提供信息,则它们之间的互信息为零。
1.2 最大相关最小冗余(mRMR)算法
mRMR算法是一种滤波式的特征选择方法,它以不同的方式在相关性和冗余之间进行权衡,并且以互信息作为计算准则来衡量特征之间的冗余度以及特征与类变量之间的相关性,通过最大化特征与类变量的相关性以及最小化特征之间的冗余性来进行特征选择。
最大相关性原则是指选择那些与模型有着最大相关性的特征,相关性越大,则说明训练出的模型解决问题能力越强。最大相关性计算式表示为:
(2)
式中:xi为第i个特征;c={c1,c2,…,cL}为类别变量;L为类别总个数;S为特征子集。
由于特征之间相关性越大,冗余度就越高,为了降低特征之间的冗余度,让每个特征都具有代表性,需要将冗余度降到最低,这就是最小冗余度原则。最小冗余度计算式表示为:
(3)
1.3 随机森林
随机森林[13]是由多棵决策树构成的一种集成学习算法,并且每棵决策树都被分配独立的子空间,任其自由生长,最后采用简单多数投票将投票次数最多的类别指定为最终的分类结果。

步骤1用k组袋外数据(OOB data)分别计算每棵决策树的误差值,记为ErrOOB1,ErrOOB2,…,ErrOOBk。
步骤2对k组袋外数据的第i个特征进行随机重排并保证其他特征不变,然后重新计算误差值,记为Erri1,Erri2,…,Errik。
步骤3特征重要性的计算公式如下:
(4)
步骤4基于重要性对特征进行排序,根据得出的最佳特征数m选出前m个特征。
2 mRMR-RF特征选择方法在XGBoost中的应用
2.1 XGBoost算法
XGBoost是由Chen等[16]在2016年提出的一种基于回归树的提升算法,是对GBDT算法的进一步优化。XGBoost算法将目标函数在t=0处泰勒二阶展开,并引入正则项来控制模型的复杂度,防止模型过拟合,这使得XGBoost相比GBDT算法,不仅能降低过拟合程度,还能减少计算量,使得求解模型最优解更具有效率。XGBoost目标函数定义为:
(5)

新生成的树需要拟合上次预测的残差,所以当生成t棵树后,将目标函数改写成:
(6)

(7)

(8)
定义Ij={i|q(xi)=j}为叶子节点j中的样本集合,并将式(5)代入式(6),得到最终的目标函数:
(9)

(10)
对应的最优目标值:
(11)
2.2 钓鱼网站检测模型
本文钓鱼网站模型设计主要分为如下两个部分:
(1) 特征筛选:本文采用mRMR-RF算法从基分类器的特征重要度和相关性冗余度两个方面进行考虑,保证单个特征重要度的同时考虑特征和类别之间的相关性以及特征之间的冗余度,以筛选出最优的特征子集。
(2) 模型构建:采用分类性能更好的XGBoost集成学习算法作为模型,可以进一步提高钓鱼网站预测的准确率。
该模型的检测过程如图1所示:首先从UCI数据集中选取钓鱼网站数据并对该数据进行基本的预处理;然后对该特征数据用mRMR算法和RF算法分别进行特征筛选,综合两种算法特征排名根据试验得出的最好特征数得出最优特征子集;最后将筛选的最优特征子集的一部分作为训练集对XGBoost分类模型进行训练,另一部分对训练好的分类器进行预测。
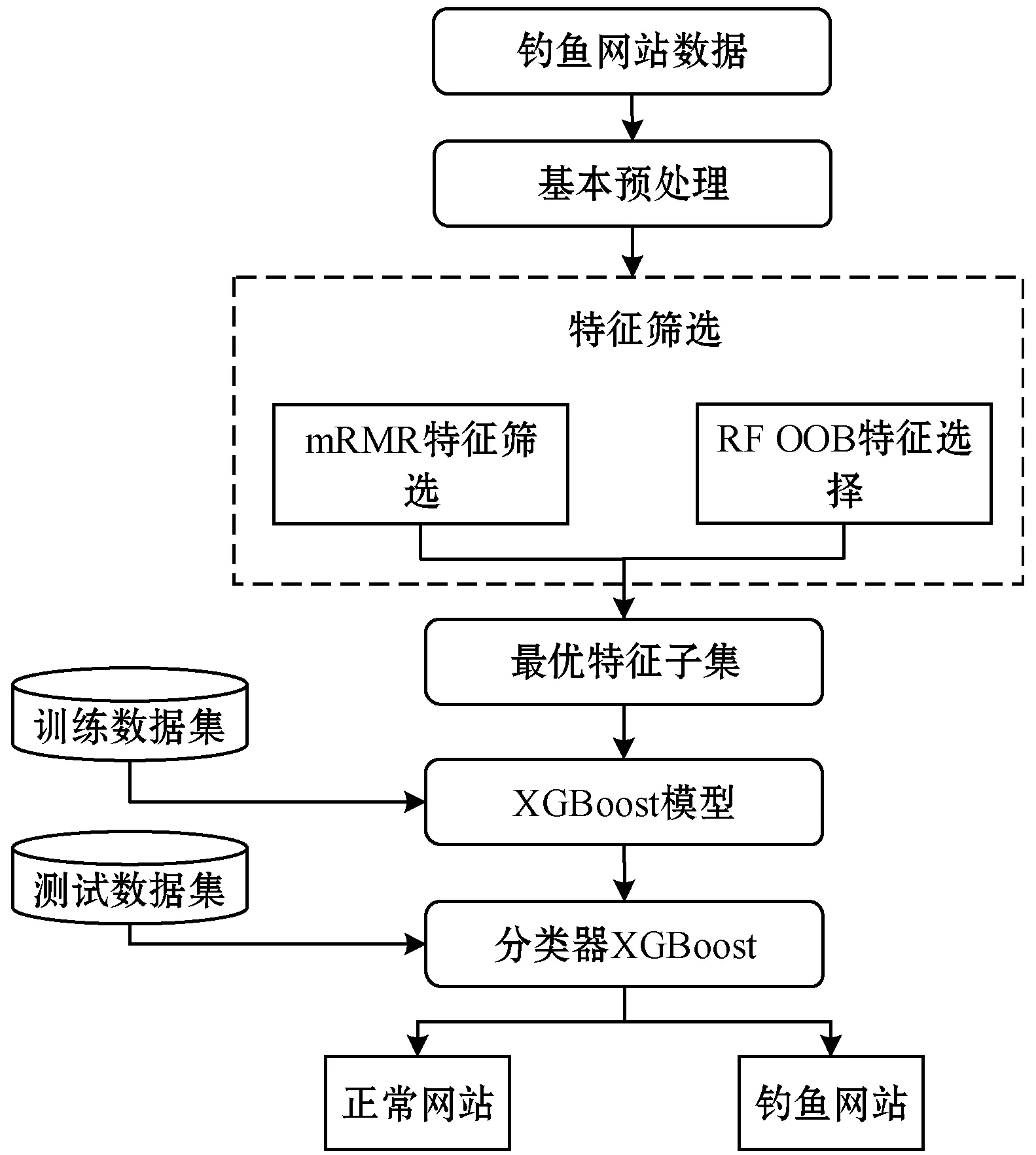
图1 钓鱼网站检测模型
3 实 验
3.1 实验数据及说明
本文采用UCI数据库中的phishing数据集进行实验分析。该数据集由PhishTank档案馆、MillerSmiles档案馆以及谷歌搜索运营商提供,共有11 055个实例,30个属性特征,包括SSLfinal_State、URL_of_Anchor、having_Sub_Domain、web_traffic、Prefix_Suffix等主要特征。实验所用的数据信息如表1所示,其中钓鱼网站占比44%,合法网站占比56%。实验环境如下:操作系统Windows 10,实验平台为Spyder。

表1 实验数据
3.2 评价指标
为了衡量训练后的模型性能,本文采用ROC曲线、AUC值以及精确度对算法性能进行评价。
ROC曲线一般指接受者操作特征曲线,该曲线以负正类率(False Positive Rate,FPR)特异度为横轴,以真正类率(TRUE Positive Rate,TPR)灵敏度为纵轴的各点的连线。FPR和TPR计算公式如下:
(12)
(13)
精确度(accuracy)又叫准确度,是用来衡量一个算法与理论值符合的程度,计算公式如下:
(14)
TP(TRUE Positive)为模型正确分类的正样本;TN(TRUE Negative)为模型正确分类的负样本;FP(FALSE Positive)为模型错误分类的负样本;FN(TRUE Negative)为模型错误分类的正样本。
AUC(Area Under Curve)值为ROC曲线下的面积,介于0.1和1之间。ROC曲线越向左上方凸AUC值越大,代表模型性能越好。
3.3 实验结果及分析
(1)实验一利用mRMR-RF算法进行特征筛选。
该实验先是通过mRMR算法对预处理后的数据进行相关性和冗余性的度量,通过计算特征之间、特征与类变量之间的分布及互信息将各个特征进行排序,得到每个特征的mRMR分值排名,特征具体排名如图2所示。
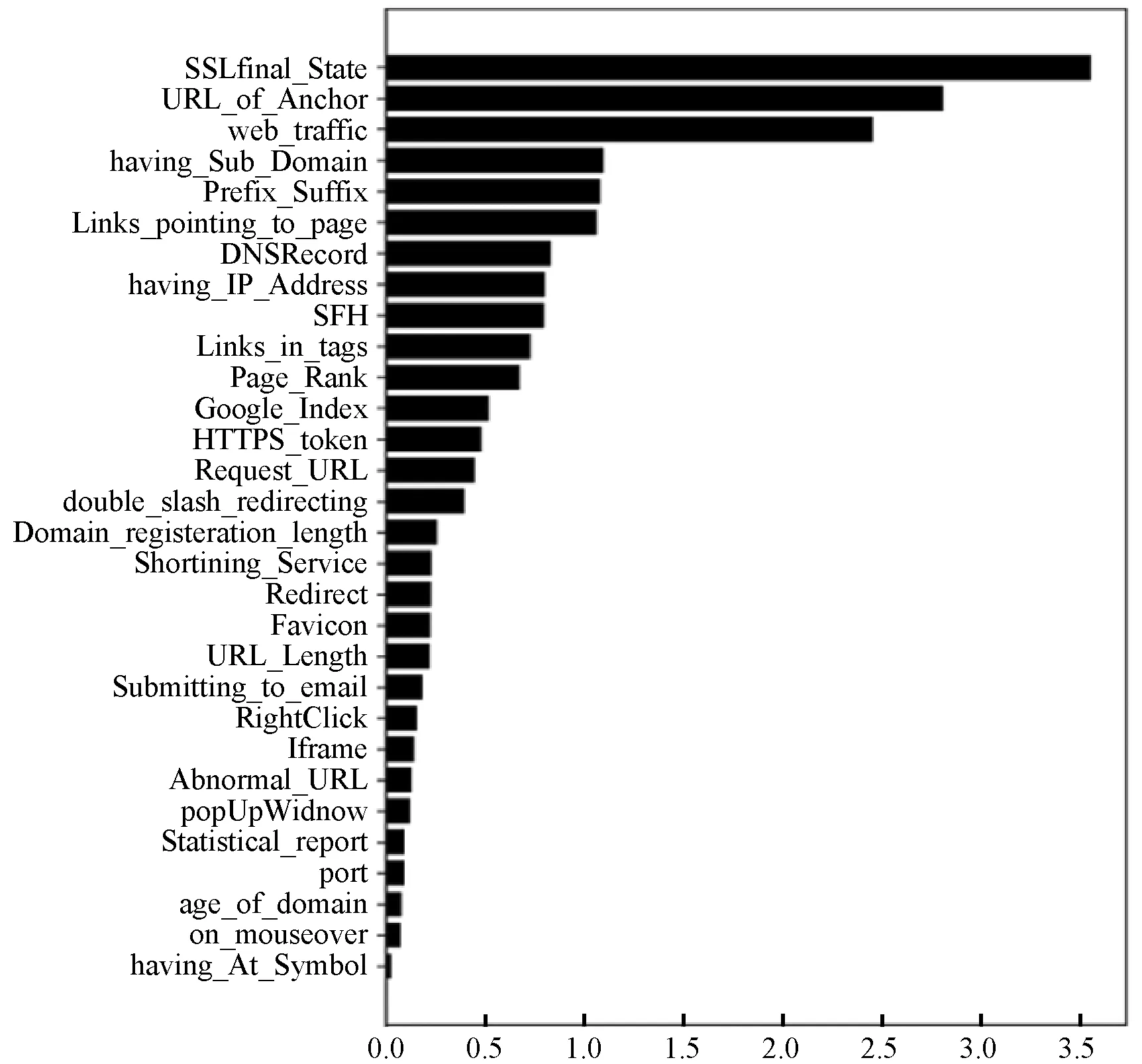
图2 mRMR特征重要性排序图
接着利用RF算法OOB data计算误差值并对特征进行排序,得到如图3所示的特征排序图。

图3 RF特征重要性排序图
综合以上两种算法各特征的排名,得到最终特征排名如表2所示。
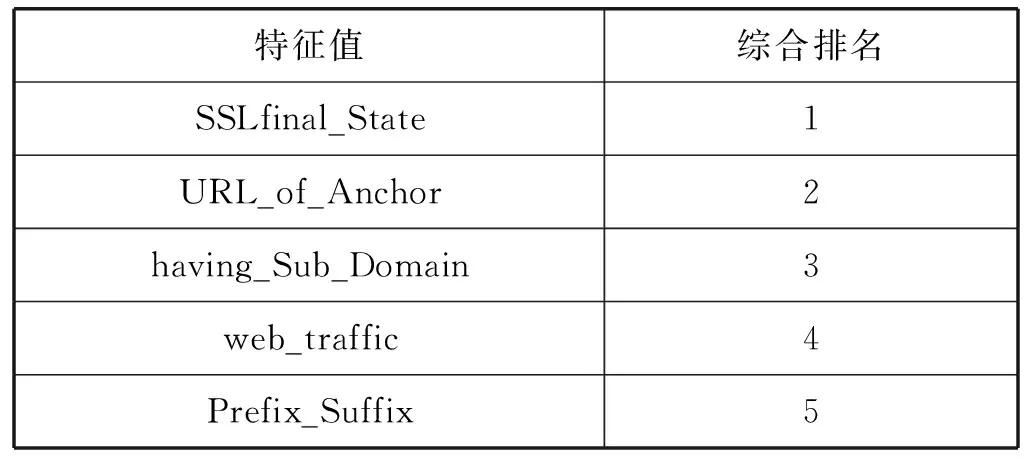
表2 特征最终重要性排序
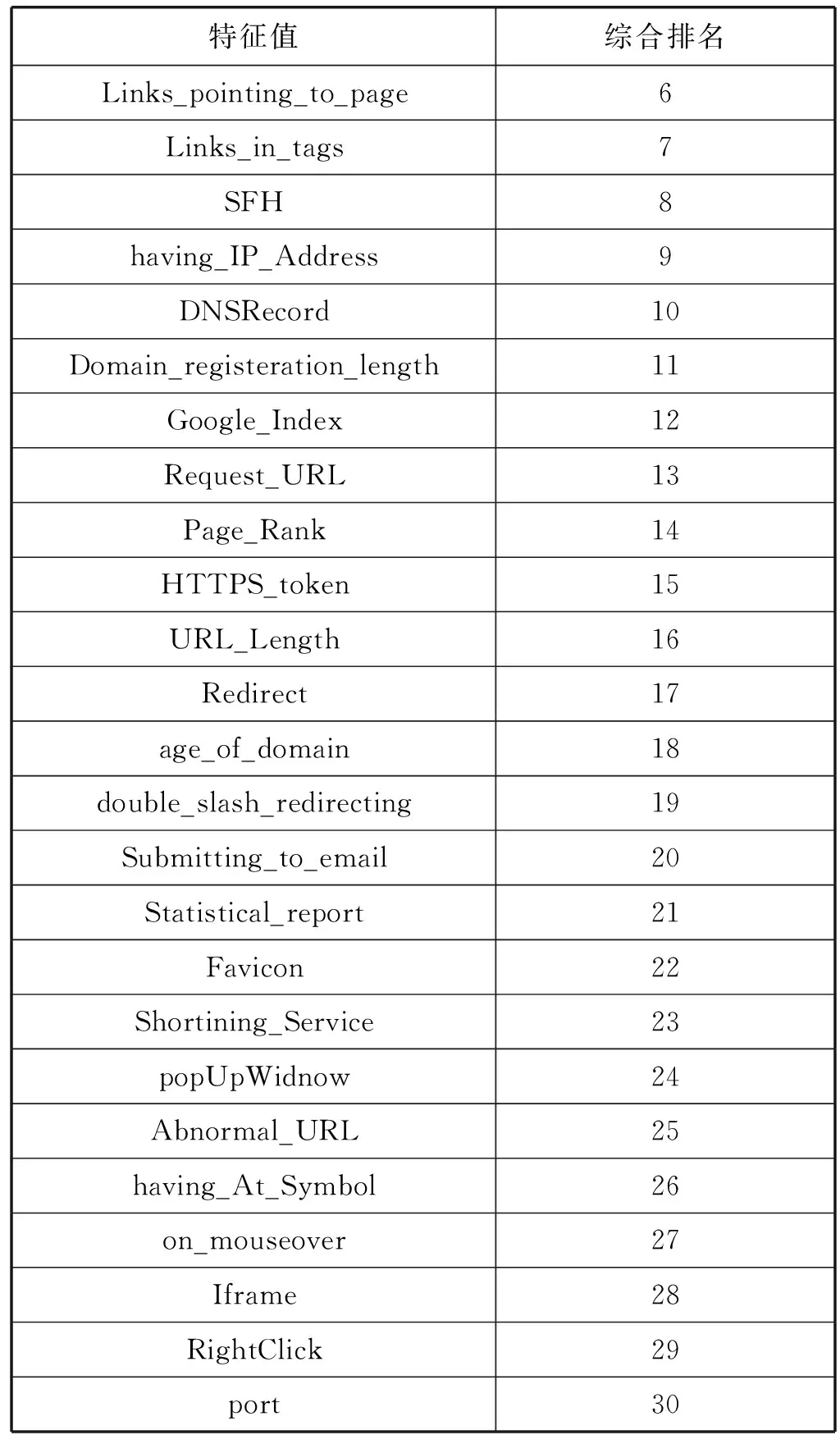
续表2
表2得出了最终的特征重要性排序表后需进行特征筛选。因为特征选取过多或过少都会影响模型的准确率,所以为了找到合适的特征数量k,本文选取不同的k值进行实验,通过比较k值对模型AUC值的影响来选出最好的k值,实验结果如图4所示。

图4 特征数对模型AUC值的影响
通过图4可以看出,特征数n选19时,AUC值达到最高,因此本文特征数k选取为19。根据表2可知,选取的特征为综合排名前19名的特征,即SSLfinal_State特征一直到double_slash_redirecting特征。
为了比较本文特征筛选算法的性能,本文从UCI数据集中随机选择一个个人信用风险评估数据集对不同特征选择算法进行实验对比,并且采用XGBoost算法对其进行训练,10折交叉进行验证。其中Acc表示精确度,AUC值为ROC曲线下的面积,介于0到1之间,用来衡量分类器的好坏。具体实验结果如表3所示。

表3 不同特征选择算法基于XGBoost模型实验结果比较
从表3数据可知,本文采用的特征选择算法mRMR_RF精确度达到了92.374%,AUC值达到了87.7,特征选取的维数为19。就精确度和AUC值而言,本文方法明显优于RF、GR、mRMR、CFS特征选择算法,RF和GR在特征降维上表现较好,但是因为筛选特征过多导致原始信息不足,最终表现出精确度不够。因此,本文提出的特征选择算法在总体上是优于RF、GR、mRMR、CFS算法的,这也验证了本文特征选择的有效性。
(2)实验二利用XGBoost模型进行钓鱼网站检测。
为了检验本文提出的钓鱼网站检测方法是否有效,本文选取了随机森林(RF)和支持向量机(SVM)两种常见类型的分类模型与XGBoost模型进行对比,对于特征选择部分,均采用实验一提出的mRMR_RF算法。对以上3个模型进行5次实验取其均值最后得出的数据如表4所示,其中TPR为真正类率,FPR为负正类率。由表4可知,本文方法的准确率最高,达到90.25%,AUC值也最高,为0.87,真正类率达到91.35%,负正类率为10.06%。可以看出本文方法的综合性能优于RF和SVM分类算法。

表4 基于mRMR-RF特征选择不同分类器实验结果
为了更直观地看出本文钓鱼网站模型预测的能力,图5给出了不同分类器的曲线,ROC曲线越往左上角凸说明AUC值越大,AUC值越大说明模型的分类效果越好,可以看出本文提出的基于mRMR-RF特征选择和XGBoost的钓鱼网站检测方法效果最好。

图5 不同分类算法的ROC曲线图
4 结 语
针对大量冗余不相关的数据导致钓鱼网站检测准确率不够,误判率较高的问题,本文提出一种基于mRMR-RF特征选择和XGBoost模型的钓鱼网站检测方法。通过结合mRMR算法和RF算法对特征进行相关性和冗余度的筛选,利用极端梯度提升(XGBoost)算法构建钓鱼网站检测模型。本文方法在特征选择过程相比RF、GR、mRMR、CFS特征选择算法精确度更高,AUC值也更大,在模型对钓鱼网站检测过程中,应用mRMR-RF特征选择的XGBoost模型相比SVM和RF在精确度和AUC值上具有一定优势。但是本文钓鱼预测的准确率还可以进一步提高,如何找到最优特征子集并找到契合该特征子集的模型,提高预测准确率将是今后研究的方向。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
小学生导刊(低年级)(2016年8期)2016-09-24
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
小学科学(2015年6期)2015-07-01
