
基于MAML方法的佤语孤立词分类
2020-09-11 08:01解雪琴杨建香和丽华侯俊龙潘文林
云南民族大学学报(自然科学版) 2020年4期
王 翠,王 璐,解雪琴,杨建香,和丽华,侯俊龙,潘文林
(云南民族大学 数学与计算机科学学院,云南 昆明 650500)
佤语是跨境的少数民族语言,对少数民族语言佤语的识别研究有利于国家安全和少数民族文化保护.佤语作为中国语言资源保护工程采集的少数民族语言之一,专家在语料库中抽样发现人工标注仍然存在很多问题,说明精准的标注不仅昂贵而且十分困难.然而,目前对佤语的研究主要停留在语音学的角度[1-2],主要包括音素,音节,词法分析等,这些研究为佤语的实验语音学发展提供准确的人工标注样本奠定了语音学基础.佤语数据集包含1 860类孤立词,每类仅包含20个样本;imageNet数据集的分类类别大约在1 200类,每类超过1 000张图片,所以本文的实验数据存在分类类别多,每类所包含的分类样本数目少的情况.
由于深度学习的成功,许多领域利用深度学习的方法来处理识别和分类的研究问题:语音[3],视觉[4]和语言[5].目前最好的机器学习系统需要成千上万的例子用于训练,例如:GoolNet[6]模型拥有22层神经网络,ImageNet作为训练数据集,对1 000类进行分类,训练数据达到120万,准确率达到93%;Inception[7-8]模型结合残差连接,同样以ImageNet作为训练数据集,准确率达到96.7%.一些主流语言凭借大量数据样本应用深度学习方法的研究产品基本已落地:Google利用注意力机制LAS对英语的识别率达到94.6%;百度利用端到端模型[9-10]识别英语和汉语2种语言.Qingnan Wang[11]利用端到端模型对藏语的音节进行识别.蔡琴[12]利用HTK对维吾尔语的连续数字短语的识别率达到80%,对词的识别率达到91.19%.然而,佤语的手工标注昂贵费时且缺乏标签,寻找一种适合小样本学习的方法对佤语的识别研究非常有帮助.
目前,常规分类方法对小样本的识别研究主要有2种方案:①利用支持向量机对小样本进行研究;②通过扩充数据样本应用深度学习的方法进行研究.傅美君[13-14]通过提取佤语的2个动态特征基因和共振峰,并基于遗传支持向量机和免疫遗传多核支持向量机完成对佤语的分类准确率达到86%,精度还有一定的提升空间.机器学习在少量数据下学习新概念的能力欠缺,如果直接将深度学习方法应用到小样本学习容易发生过拟合现象,直接扩大佤语的标记样本难以实现,且效果不一定好.人类仅仅通过少量的学习便可以辨别不同物体,元学习模仿人类学习的能力适合小样本学习.王璐[15]采用元学习方法Reptile对小样本的佤语进行识别,最终识别率达到93%.MAML是Chelsea Finn[16]借助从其他任务学习到的经验知识应用到新任务的方法,加快小样本中新任务的训练。MAML成为小样本领域的一种主流方法, 具有快速学习的能力,本文选用MAML方法对小样本的佤语孤立词进行识别研究.
1 相关工作
人类具有快速学习的能力,已经证明人类在学习新事物时只需要少量的样本且准确率较高[17].借鉴人类的学习经验仅仅通过少数的例子就可以快速学习新例子,元学习模仿人类的学习能力,让模型学会学习,元学习的快速发展将缩短人类和机器学习对小样本识别的差距.元学习在小样本识别[18]主要有2个研究方向:概念学习和经验学习.目前小样本识别发展快速:谷歌的One-shot匹配网络[19]通过在神经网络结构上添加外部记忆,将学习到的新概念知识应用到小样本学习,在imagenet数据集上的One-shot学习准确率从87.6%提升到93.2%. Finn[16]提出MAML是小样本识别领域非常好的方法之一,模型不仅简单而且功能强大,可以快速适应深度网络,在不同任务上训练的模型可以快速适应仅有少量样本的新任务,在图像分类、回归、微调的强化学习上产生不错的效果.
近两年对MAML的研究及相关扩展非常多,例如:Finn[20-21]通过在MAML模型上添加概率得到一种概率元学习算法,可以从模型分布中为新任务模拟目标模型,处理小样本的模糊性任务效果较好;Boney[22]将半监督和无监督方法扩展到MAML模型,对无标记的样本效果明显优于其他方法;Triantafillou[23]构造元数据集为了在不同的任务上得到更好的泛化性由大量种类繁多的数据组成,Prototypical网络和MAML网络在元数据上的表现欠佳,而在Proto-MAML表现良好.Antonious[24]提出的MAML++是针对MAML的改进算法,明显提升收敛速度和泛化性能; Singh Behl[25]提出的Alpha MAML合并在线超参数自适应方案从而规避了MAML的稳定性需要大量的参数调整.MAML成为小样本领域的一种主流方法,对小样本的研究,有助于对少量标记语言的识别,本文主要解决小样本的语音识别问题.
2 元学习
2.1 元学习的基本单位——任务
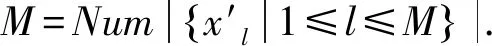
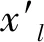
(1)
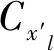
(2)

表1 元学习基本单位(任务)
2.2 元学习的学习过程
对于特定场景的模型学习分2个阶段完成,模型训练阶段和模型测试阶段.同样,元学习也不例外,由元训练Metatrain和元测试Metatest共同完成我们的任务,所不同的是,针对模型的优化程度、模型的灵敏度及模型的泛化性能,我们的元学习在Metatest阶段针对不同场景存在2种处理方式,经微调后完成元测试Metaindirect-test和直接元测试Metadirect-test,2个阶段的数据设置如表2所示.Metatrain阶段任务批次数为P,每个批次含有Q个任务;Metaindirect-test阶段有O个任务用于Metatest,Metadirect-test阶段有M个样本用于Metatest.一般情况下,元训练Metatrain和元测试Metatest遵循两不交叉原则:
1)元训练类别CMetatrain(taskpq(xij))和元测试类别CMetatest(taskp′q′(xi′j′))不能完全相同,即
(3)
2)元训练任务TMetatrain(taskpq)和元测试任务TMetatest(taskp′q′)遵循单个任务的两不交叉原则.

表2 元训练和元测试设置
2.3 与模型无关的元学习——MAML

在特定批次的任务中(采样p-th(1≤p≤P)批次,其中包含Q个任务),2个学习器的学习过程如下:
2.3.1 基学习器
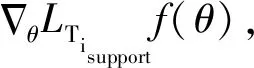
2.3.2 元学习器
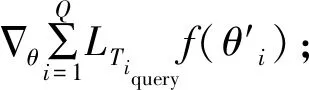
元训练过程如算法1所示.

表3 算法1: MAML-training[16]

表4 算法2:MAML-test[16]
整个MAML-Training阶段所要完成的工作是对先验任务的经验积累.内循环(4~8)即快速学习阶段,学习特定先验任务属性;外循环(9)即元学习阶段,将特定先验任务属性元平摊给模型参数(元级参数).这样,网络一旦收敛,元级参数即为我们需要学习的初始化参数.
MAML-test阶段是将先验任务学习到的模型初始化参数(即经验)应用到新任务上,该阶段模型只需要几步微调即可收敛.
2.4 Reptile
Reptile[26]基于元学习的一阶梯度学习网络的初始参数,从而利用元知识快速适应新任务.Reptile能有效避免像二阶微分近似所需的计算时间和计算量,所以收敛速度快.梯度下降的更新公式如下.
(4)
Retile通过学习不同任务的初始参数W,当面对新任务时能够通过公共最近快速找到新任务的梯度下降方向,如图2所示.
3 实验
元学习能够利用其他任务上的先验知识补充新任务数据不足的缺陷.采用不同大小的佤语训练任务5-way 1-short和5-way 5-short对新任务识别精度对比,发现MAML和Reptile不仅具有快速学习能力提升小样本的识别精度,而且不会出现过学习现象.
3.1 数据说明
佤语数据集作为实验的研究对象,数据集由两男两女对1 860类孤立词进行发音,每人对每类孤立词读5遍,总计37 200条佤语孤立词语音.相比imageNet数据集中1 200类,每类1 000个样本,佤语数据集中的数据类别多,每类所含数据少的特点,训练样本不足.将语音信号通过傅里叶变化转换成对应的语谱图,分别选用元学习领域的Reptile和MAML对小样本的佤语数据集进行研究.以编号0078和1 550类语音信号为例,佤语语谱图如图3所示,横坐标表示时间,纵坐标表示频率,颜色的深浅表示能量.
3.2 模型
模型由4层卷积和一层全连接构成,每个卷积层由64个3×3的卷积核构成,每个卷积操作按先卷积,批量正则化,Relu激活函数,2×2的最大池化顺序进行.
3.3 实验过程
MAML和Reptile模型对佤语数据集的超参数设置如下:训练周期epoch=100,epoch_len=400,evel_batches=40,meta_batch_size=4,inner_learning_rate=0.01,meta_learning_rate=0.001,n= 1,k= 5,q=5;n= 1,k= 5,q= 5代表1个任务总共有5类,每类训练样本数为1测试样本为5,即5-way 1-short 5-query任务.利用公式(2)进行梯度的迭代更新得到参数θ′.
3.4 实验结果
基于二阶梯度更新的MAML模型和一阶梯度更新的Reptile模型分别对5-way1-short任务和5way 5-short任务的实验结果显示.图4表示MAML的准确率变化曲线:(a)在5-way 1-shot的训练准确为89.7%,验证准确率为78.6%;(b)在5-way 5-shot的训练准确率为96.5%,验证准确率为94.5%.图5表示Reptile模型的准确率变化曲线(a)在5-way 1-shot的训练准确率接近100%,验证准确率61.6%;(b)表示Reptile模型在5-way 5-shot的训练准确率为100%,验证准确率为93.6%.
实验结果分析:横向比较,同类样本数越多,识别率越高.而元学习是一种基于任务的平摊机制,学习任务之间的共性,单类样本数对MAML模型的结果影响没有Reptile模型敏感.纵向比较:基于相同网络的迭代轮数,一阶梯度更新的Reptile模型明显快于二阶梯度更新的MMAL模型,可以使网络快速的达到收敛状态.
4 结语
元学习使任务分配上的损失最小化,在同一任务的梯度更新内积最大化,即使在小样本学习的情况下也能达到不错的效果.MAML和Reptile模型在相同的实验设置下对佤语语谱图进行识别,实验结果表明MMAL达到的识别精度更高,而Reptile的收敛速度更快.本实验的佤语语谱图并非全屏语谱图,去除语谱图的白边信息提高语谱图的有效区域可能改善实验的识别精度.充分考虑语谱图之间的特性,佤语语谱图之间存在高相似性这一特征,怎样改进元学习的方法使其充分利用这一特征将是一个有趣且值得探究的问题.
猜你喜欢
导航定位学报(2022年4期)2022-08-15
小天使·三年级语数英综合(2022年4期)2022-04-28
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
健康体检与管理(2021年10期)2021-01-03
领导决策信息(2018年16期)2018-09-27
汽车导报(2017年5期)2017-08-03
数学学习与研究(2017年3期)2017-03-09
