
基于PCA-ESN模型的潘家口水库水位预测研究
2020-09-14 05:30彭宏玉
唐山学院学报 2020年3期
龚 莎,彭宏玉
(1.西南交通大学 唐山研究生院,唐山 河北 063000;2.唐山学院 计算机科学与技术系,唐山 河北 063000)
0 引言
滦河来水量在时间分布上很不均匀,一年之内的来水量主要集中在七、八、九三个月内,且来水量的年际变化悬殊[1]。潘家口水库是整个引滦工程的源头,对其水位进行预测,对于提高滦河水资源的利用率、加强水资源的分配管理以及防洪减灾都具有重要意义。
目前,很多学者致力于湖泊流域水位预测方法的研究,采用的技术主要有遥感技术、物联网技术、机器学习和神经网络。其中应用机器学习和神经网络进行预测在国内外已有不少研究成果。Makhtar等[2]使用Apriori算法从数据集中生成最佳规则,用于查找频繁项集,通过建立洪水预报模型来发现水位与洪水面积之间的相关性,这项研究的结果证明了在水位预测中Apriori算法的可用性。Jangyodsuk等[3]基于贝叶斯的方法,提出了一种新的因果发现算法,利用降水和水文数据来寻找未来洪水的影响特征,但此研究只考虑了降水这单一因素对洪水的影响。赵春雷等[4]采取历史资料回归和机器学习方法,对白洋淀水位随区域降水量变化的规律进行分析,并通过建立最低水位预测模型对已有的数据进行验证。但此研究只考虑了影响水位的雨季自然降水量和白洋淀基础水位这两个因素,造成一定的结果误差,预测精度有待提高。刘亚新等[5]提出了一种基于长短时记忆(Long Short-Term Memory,LSTM)的水位预测方法,用于葛洲坝水电站上下游水位的预测,此方法采用水位和出力等直接监测数据,避免了出入库流量等间接计算值带来的二次误差,但预测精度仍有待进一步提高。Ghorbani等[6]将混合模型的预测能力与FFA集成在一起,作为具有多层感知器(MLP-FFA)的启发式优化工具,用于土耳其埃利迪尔湖水位的预测,实验表明Firefly算法作为优化器,可以使模型预测的准确性更高。Khan等[7]为拉姆甘加河开发了一个人工神经网络模型,使用日常用水对模型化网络进行训练、验证和测试,由于河流流量和水位值难以测量,不能直接预测隐藏层神经元最佳数量,必须通过枚举技术获得最佳网络拓扑结构,计算成本较高,增加了运行时间。Xu等[8]提出了一种基于ARIMA-RNN组合模型的水位预测方案,解决了单个预测模型不能同时考虑数据中线性和非线性成分的问题,实验结果证明,预测模型可以取得较好的效果,但精度仍有待提高。
针对应用传统神经网络进行水位预测存在的问题,本文提出了一种基于PCA-ESN模型的水位预测方法。首先,在数据预处理部分利用主成分分析法(Principal Component Analysis,PCA)有效提取多元时间序列数据的特征并对原始数据进行重组,降低了水位数据的信息冗余;其次,使用回声状态网络(Echo State Network,ESN)建立水位预测模型,克服了传统递归神经网络梯度消失和梯度爆炸问题,网络具有较好的信息处理能力和泛化能力。具体过程为,根据河北省潘家口水库的水位日数据,先通过PCA算法选取影响水位的相关变量,然后设计ESN模型预测水位。
1 数据预处理
对数据预处理是实验结果准确的前提。作为多元统计中常用的数据分析方法之一,主成分分析法能够在降低原始数据变量维数的同时有效提取各个变量的特征,产生新成分,新成分能够克服因原始变量信息重叠而对数据分析结果造成的不良影响[9]。
设原始数据集包括n个数据样本,每个样本具有p个变量,对此数据集的主成分分析计算流程如下。
(a)对原始数据集进行标准化处理,组成标准化数据矩阵Z。
(b)引入Pearson相关系数(式(1))计算各个变量数据间的相关性,组成相关系数矩阵R。
(1)
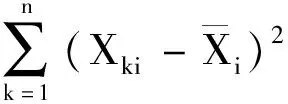
(c)求解相关系数矩阵R的特征方程,对求出的特征值按从大到小的顺序进行排序λ1≥λ2≥…≥λp,并求出每个特征值相对应的单位特征向量li,li组成如式(2)的主成分得分矩阵L。
(2)
其中,lij(i=1,2,…,n;j=1,2,…,p)。
(d)根据式(3)计算累计贡献率ki,保留累计贡献率在85%以上的前m个成分作为新主成分。
(3)
(e)根据第(c)步、第(d)步计算新主成分Y的各个主成分,得到原始数据集经过PCA处理后的重组数据集,第m个新主成分的数学模型Ym如式(4)所示。
Ym=l1m×X1+l2m×X2+…+lnm×Xp。
(4)
原始数据为河北省潘家口水库2009年9月3日至2019年12月29日的3 770组水位日数据,数据来源于实验室搭建的野外人工湖水位智慧预警系统的数据采集部分。该系统的数据采集部分比较完善,经过了长时间的运行,已经采集到定量的水位及相关信息。部分历史水位及相关信息数据如表1所示。
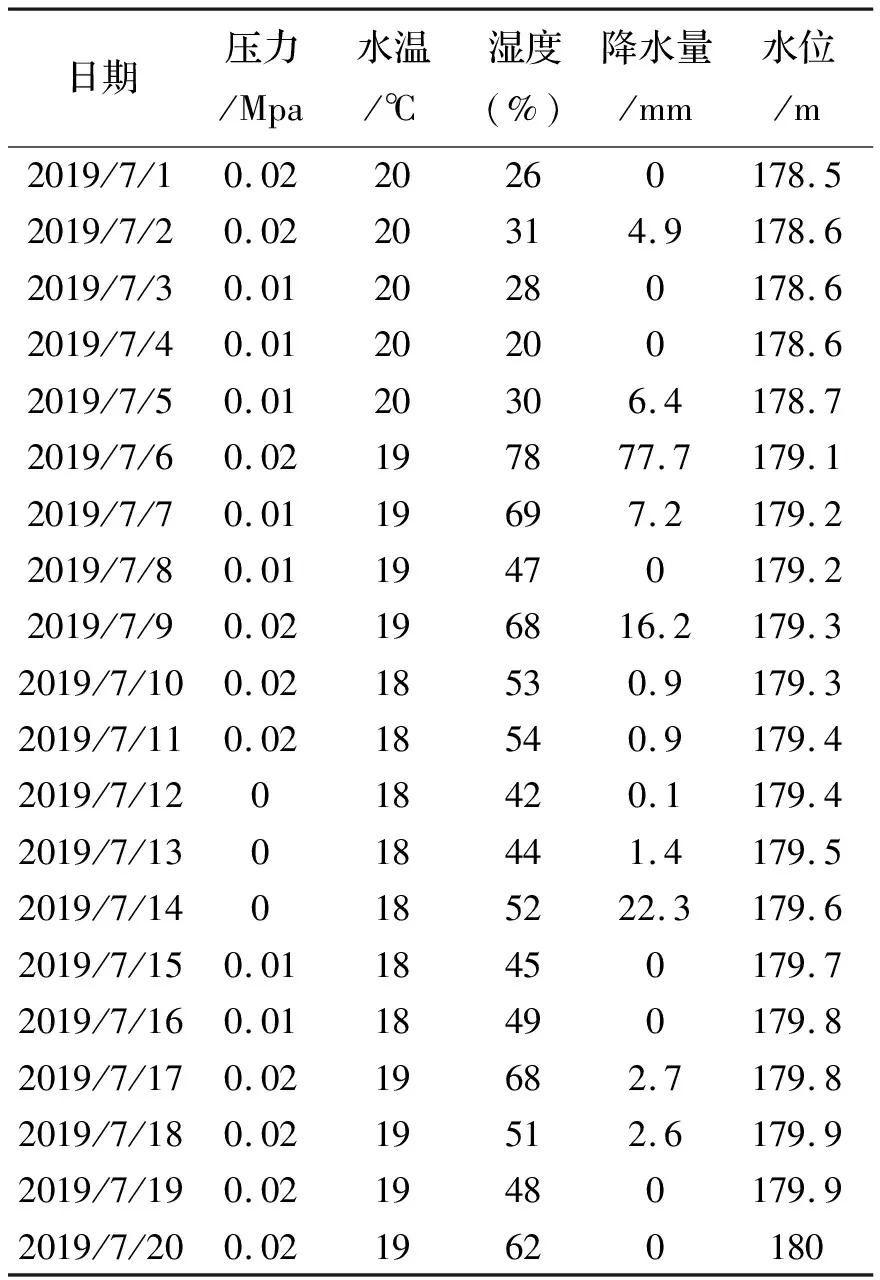
表1 部分历史水位及相关信息数据
在进行ESN模型构建之前,要把ESN结构中输入层因子的具体数值进行预处理,输入层因子的选择和主成分分析相关性很强,无论是因子初选还有因子精选都是其范围内的,因子选择过程本质上来说就是主成分分析过程。
将历史水位、降水量、水温、湿度、压力作为主成分分析过程的备选因子。数据集的变量分别为历史水位(X1)、降水量(X2)、湿度(X3)、水温(X4)、压力(X5)。对5个初始因子进行主成分分析,结果如表2所示。
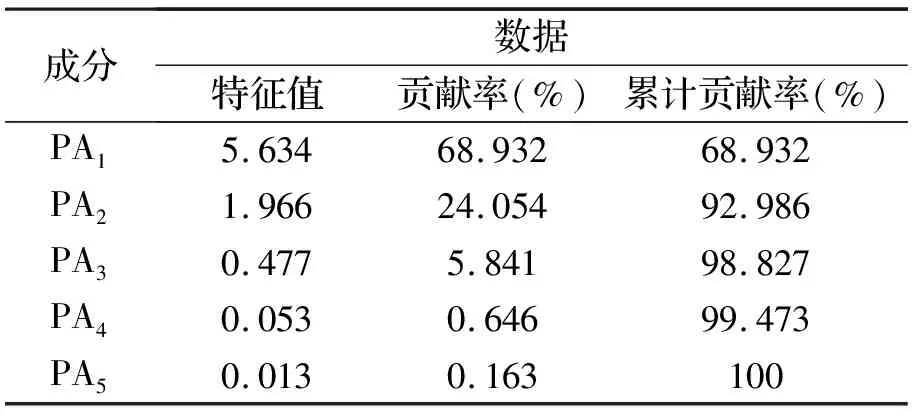
表2 PCA分析结果表
经主成分分析,得到各个主成分的特征值、贡献率、累积贡献率。由表2可知,历史水位和降水量2个主成分的累计贡献率已经达到92.986%,说明这2个主成分取代先前的5个因子可以让信息丢失的程度降低,主成分的分析效果更稳定。
数据集经过PCA处理得到2个新主成分PA1,PA2,由主成分得分矩阵计算得到新主成分的模型如式(5)所示:
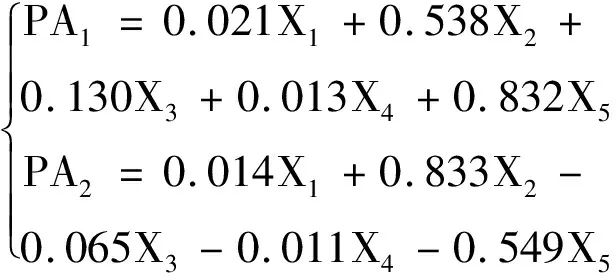
(5)
2 模型设计
回声状态网络ESN由2001年Jaeger提出[10],是典型的储备池计算网络,具有复杂的动力学特征。目前ESN已经在智能控制、语音识别、非线性时间序列预测等领域取得了广泛的应用。ESN主要由输入层、储备层和输出层组成,其特点是储备层由一个包含大量神经元的动态储备池(DR)构成,储备池内的神经元采用随机、稀疏的方式连接,其蕴含了网络的运行状态,具有短期记忆功能。储备池是回声状态网络结构的核心部分,对于网络最终的性能起着至关重要的作用。ESN结构如图1所示。
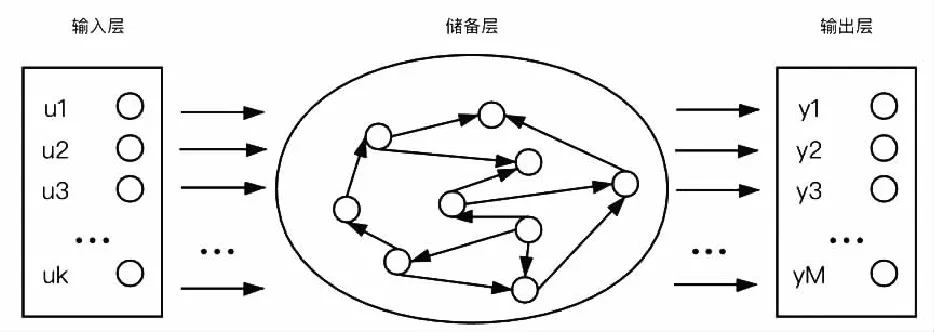
图1 ESN结构图
设输入矩阵、状态矩阵、输出矩阵分别为:
u(t)=(u1(t),u2(t),…,uK(t))T,
(6)
x(t)=(x1(t),x2(t),…,xN(t))T,
(7)
y(t)=(y1(t),y2(t),…,yM(t))T,
(8)
其中,K为输入维数,N为储备池内部神经元个数,M为输出维数,t=1,2,…,T。
状态矩阵的更新如式(9)所示:
x(t+1)=f(Winu(t+1)+Wx(t)),
(9)
y(t)=fout(Woutxout(t)),
(10)
其中,Win是N×K输入层到储备层的权重矩阵,W是储备层权重矩阵,Wout是M×K储备层到输出层的权重矩阵,此矩阵的更新如式(11)所示:
Wout=((STS+βI)-1STD)T,
(11)
其中,β表示非负正则化系数,S表示全部状态矩阵,I表示单位矩阵,D为全部输出矩阵。
3 算法设计
在设计算法前首先需要进行关键参数选择,具体参数包括储备池规模、稀疏度、谱半径、输入缩放因子。
(ⅰ)储备池规模N是指ESN储备池内神经元的个数。储备池是随机生成的,其规模必须足够大,以捕捉潜在的数据特征。一般来说,如果采取适当的正则化措施,则储备池规模越大,获得的网络性能就越好。但过大也会导致“过拟合”。文中选取N为500。
(ⅱ)稀疏度s是指储备池中存在相互连接的神经元个数与神经元总个数的百分比,反映了储备池神经元间连接的稀疏程度。ESN储备池内神经元是稀疏连接的,即连接输入层与储备层的输入权重矩阵Win中大部分元素值为0。文中设定稀疏度为5%。
(ⅲ)谱半径ρ(W)是指储备层权重矩阵W的特征值绝对值中的最大值。当谱半径介于[0,1]之间时,回声状态网络具有回声状态特性。但由于激活函数引入非线性因素,最佳ρ(W)值有时可能会比1大得多,意味着ρ(W)<1并不是网络具有回声状态特性的必要条件。因此,实际任务中的谱半径应更大,需要更大的输入存储空间。
(ⅳ)输入缩放因子是指在输入信号传送到网络储备池前,对输入权重矩阵Win进行尺度变换的一个缩放因子。输入缩放因子的大小与网络处理问题的非线性程度有关,非线性程度越强,输入缩放因子值越大。
ESN模型训练:
Step1:进行初始化操作,先确定储备池的规模,即神经元的个数。
Step2:随机生成输入权重矩阵Win和储备层权重矩阵W。调整输入缩放因子,使ρ(W)谱半径小于1。
Step3:样本数据依次加载到输入、输出,更新储备池内部状态。
Step4:前n个数据因受到初始瞬变的影响,所以删除x(1)至x(n),即前n个数据不用于学习Wout,并收集第n个数据以后的状态变量。
Step5:计算输出权重矩阵Wout。
Step6:用新输入和训练好的Wout计算相应输出进行测试。
4 仿真实验
将基于PCA-ESN的预测模型用于潘家口水库水位的预测。
首先对输入数据进行归一化处理:
x′=(xy-xmin)/(xmax-xmin),
(12)
其中,xy为数据序列的原始值,x′为归一化后的值,xmin为序列的最小值,xmax为序列的最大值。
将3 770组数据归一化处理后,利用PCA算法对数据进行分析处理,选取新主成分。取前2 000组数据用作训练样本,后面1 770组数据用作测试样本。ESN网络的输入节点为2,储备池神经元个数为500,稀疏度为5%,输出节点数为1。
基于处理的数据集,对PCA-ESN模型进行水位预测的实验模拟。将模型运行30次以求得较为稳定的模拟结果,采用30次的平均值绘制ESN测试效果图图2。由图2可知,ESN的测试输出接近真实水位数据,效果较好。
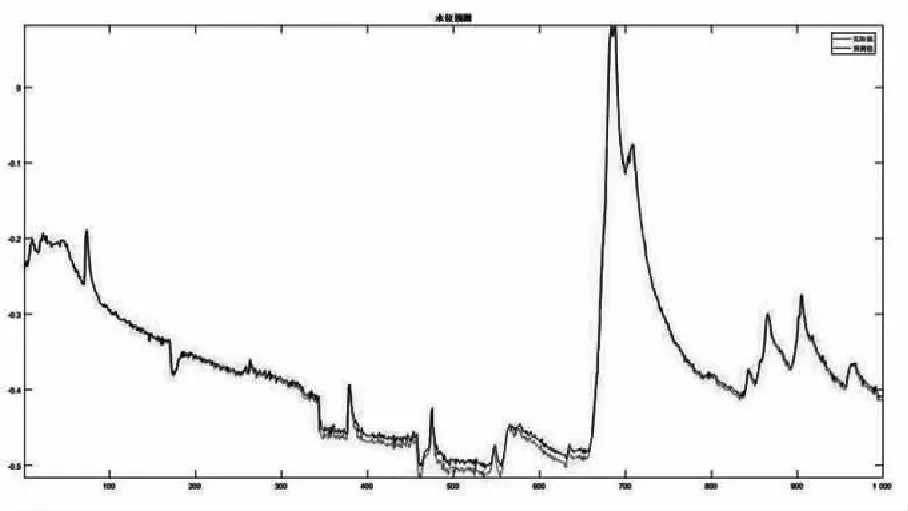
图2 ESN测试效果图
为了进一步说明ESN的优越性,本实验选取均方误差(MSE)作为模型预测性能的评价指标,计算公式如下:
(13)
ESN误差测试如图3所示。由于ESN模型的输入权重矩阵与储备层权重矩阵在每次训练时均需随机生成,因此ESN模型的误差分布有一定波动,但基本比较平稳,误差控制在7.278E-05左右,预测效果较好。说明ESN的神经网络数据处理能力强,训练效果好。

图3 ESN误差测试图
5 结论
采用PCA算法对数据集进行预处理,选取新的主成分作为输入变量,建立ESN预测模型,对潘家口水库水位进行预测。仿真实验结果表明,采用PCA算法对数据进行预处理,提取到历史水位和降水量的累计贡献率达到92.986%,将这2个主成分作为输入变量,减少了重复率,降低了复杂度。实验展示了ESN预测非线性时间序列数据的优势,收到了较好的预测效果。因此,基于PCA-ESN模型预测水位的误差小,准确性高,具有一定的实用价值。
猜你喜欢
粮食与饲料工业(2022年2期)2022-04-27
电子产品世界(2021年8期)2021-01-16
绿色中国(2019年19期)2019-11-26
中国疼痛医学杂志(2019年9期)2019-01-04
支点(2017年3期)2017-03-29
创新时代(2016年8期)2016-10-21
弹箭与制导学报(2015年1期)2015-03-11
中学生数理化·七年级数学人教版(2008年10期)2008-01-21
