
基于Flink的海量医学图像检索系统设计与实现
2020-09-26 00:58毛亚青胡俊峰
计算机测量与控制 2020年9期
毛亚青,王 亮,胡俊峰
(徐州医科大学 医学信息与工程学院,江苏 徐州 221000)
0 引言
目前,医学影像数据约占医院内部总数据的70%[1],它们来源于不同设备、对应不同人体组织器官和多种病症,这些海量的医学图像资源为医学图像的存储、检索带来了存储体量大、检索效率低等问题。如何对海量医学图像信息进行高效检索,从海量数据中快速并准确地搜索出满足要求的图像是目前所要解决的重要问题。然而,现阶段国内外关于医学图像检索技术的研究[2-5]依然存在三大问题:1)主要在单机环境下进行,大规模医学影像数据的检索使得该串行模式的医学图像检索技术已出现进程瓶颈;2)当前医学图像检索中主要采用对图像依次进行遍历的方式,而没有很好的索引机制来做索引,也增大了检索系统的负荷;3)传统的图像检索模式大多基于已有的数据进行定时离线构建索引,对于新增的图像检索存在时效性差的问题。
为了解决医学图像检索过程中的效率问题,本课题拟采用基于Flink的分布式技术提高这些海量医学图像的检索实时性,针对海量医学图像检索系统中图像特征索引方式、图像存储以及图像检索的问题,建立一个高效的医学图像检索平台,实现医学图像分布式检索,提高图像处理的实时性以及图像检索准确率,从而更好地辅助医生便捷获取和利用医学图像资源。
1 相关工作
1.1 Hadoop平台简介
从狭义上来说,Hadoop[2-6]是一个由Apache基金会所维护的分布式系统基础架构,旨在解决海量数据的存储和计算问题。而从广义上来说,Hadoop通常指的是它所构建的Hadoop生态,包括Hadoop核心技术,以及基于Hadoop平台所部署的大数据开源组件和产品,如HBase、Hive、Spark、Flink、Pig、ZooKeeper、Kafka、Flume、Phoenix、Sqoop等。这些组件藉由Hadoop平台,实现大数据场景下的数据存储、数据仓库、分布式计算、数据分析、实时计算、数据传输等不同需求,从而构成Hadoop生态。
Hadoop的核心技术:HDFS、MapReduce、HBase被誉为Hadoop的三驾马车,更为企业生产应用带来了高可靠、高容错和高效率等特性。HDFS是分布式文件系统(Hadoop Distributed File System),其底层维护着多个数据副本,即使Hadoop某个计算或存储节点出现故障也不会导致数据的丢失,所以即使部署在成本低廉的服务器上也能同样保障其可靠性和容错性。MapReduce是Hadoop中并行计算编程的基本模型,能够将任务并行分配给多个节点同时工作,从而加快任务处理的速度。HBase是一个可伸缩、分布式、面向列的数据库,和传统关系数据库不同,HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
1.2 Flink平台简介
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。Flink基于Flink流式执行模型(Streaming execution model),能够支持流处理和批处理两种应用类型。流处理和批处理所提供的服务等级协议完全不相同,流处理一般需要支持低延迟、Exactly-once保证,而批处理需要支持高吞吐、高效处理,所以在实现的时候通常是分别给出两套实现方法,或者通过一个独立的开源框架来实现其中每一种处理方案。如:实现批处理的开源方案MapReduce、Spark;实现流处理的开源方案Storm;微批处理方案Spark Streaming。
与传统方案不同,Flink在实现流处理和批处理时,将二者统一起来:Flink是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,即有界的数据流。这种批、流一体的架构使得Flink在执行计算时具有极低的延迟。
2 系统架构设计
2.1 系统总体架构设计
为了实现海量医学图像的实时检索和高效存储,设计基于Flink的海量医学图像并行检索系统总体架构共包括:数据采集层、数据存储层、资源管理层、数据计算层和应用层。
如图1所示为医学图像检索系统架构图,具体如下。
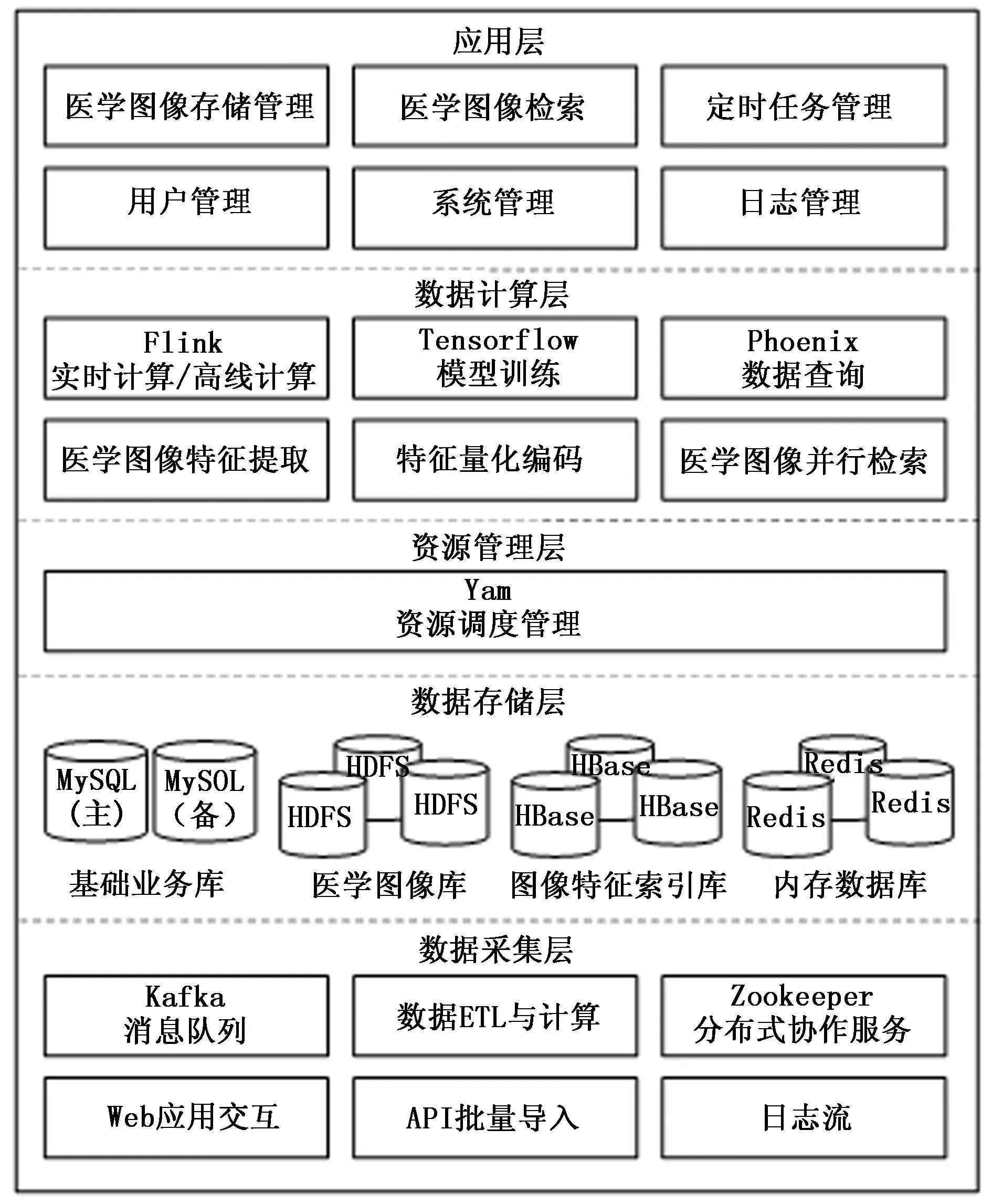
图1 系统总体架构图
1)数据采集层:
系统的数据源主要包括:用户通过Web界面上传医学图像、通过API批量导入的医学图像和系统操作日志流。对于实时产生的数据首先放入Kafka消息队列进行缓冲中以供后续计算,通过Zookeeper组件对Kafka服务器消费生产速度进行同步。此外,还可以通过ETL导入数据作为系统的数据源。
2)数据存储层:
系统的数据存储根据数据类型和应用场景分为基础业务库、医学图像存储库、图像特征索引库和内存数据库。其中,基础业务库通过MySQL存放系统的结构化信息,如:人员列表、组织架构、图像基础信息等。医学图像存储库通过Hadoop平台的HDFS进行存储,图像ID对应MySQL中的图像基础信息表的记录。同时,该ID图像的特征索引存储在HBase数据库中。此外,服务器将经常访问的数据缓存在内存数据库Redis中,从而提高访问速度和计算效率。
3)资源管理层:
系统通过由Yarn进行资源管理,负责在有数据计算请求时根据集群状况分配计算资源和计算节点,从而提供MapReduce、Spark、Flink等组件的计算环境。
4)数据计算层:
系统首先对于用户输入的医学图像通过Flink进行特征提取,根据图像上传形式分为实时计算和离线批量计算两种;进而对图像进行特征量化编码便于检索,特征编码存储在HBase中,并由Phoenix进行HBase中数据的查询计算;在用户需要检索时通过医学图像并行检索比对特征相似度计算返回检索结果。
5)应用层:
系统通过Web的形式提供用户交互界面,实现对医学图像的存储管理、医学图像检索操作、用户管理、系统管理和日志管理等。
2.2 系统功能结构设计
医学图像检索系统主要设计包括系统管理模块、用户管理模块和图像管理模块三部分。其中,系统管理模块包括系统管理、日志管理、异常报警;用户管理模块包括用户注册、用户登录、个人信息管理;图像管理模块包括图像上传、图像批量导入、图像查看和图像检索检索。具体功能如图2所示。
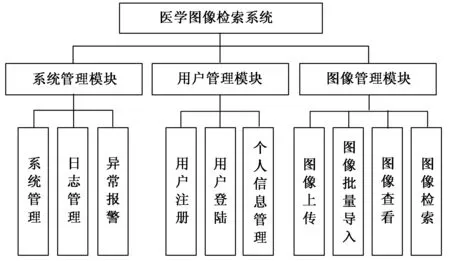
图2 系统功能结构图
2.3 系统集群网络架构
系统集群网络架构共包括前端集群、后端业务集群和数据计算集群,医学图像并行检索系统网络架构如图3所示。
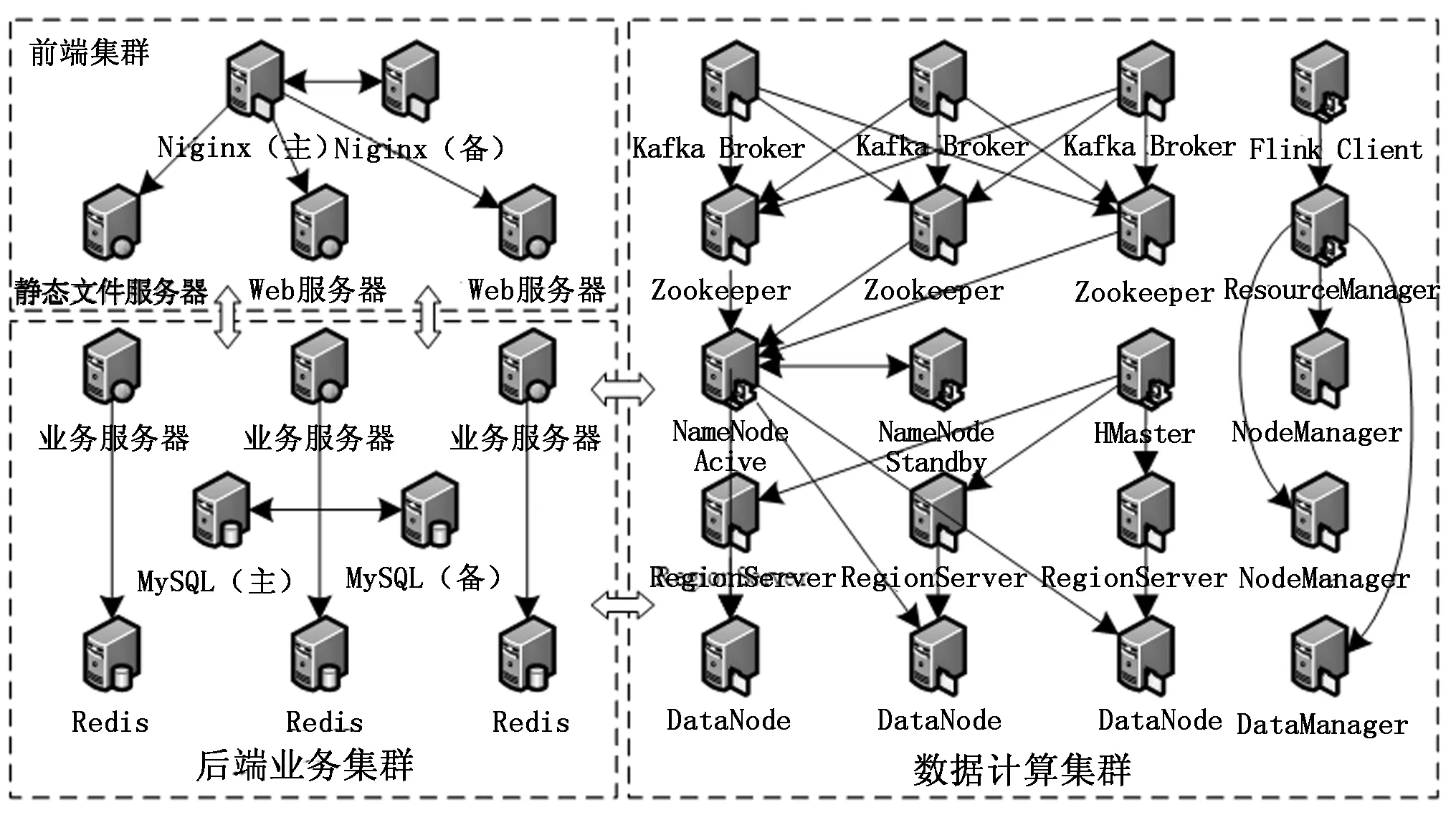
图3 系统集群网络架构图
系统主要采用前端界面和后端业务分离的思想,在提高各个模块的内聚性的同时降低各模块之间的耦合性。在前端集群中,由Nginx负责请求的反向代理和负载均衡,根据用户操作分别指向静态文件服务器或Web服务器,实现网页相关界面的显示与交互。前端集群通过远程调用的方式与后端业务集群进行通信,实现相关业务操作、MySQL数据库交互操作、数据计算与结果缓存到Redis等操作。对于后端业务操作中的数据计算环节则由数据计算集群负责,如:实时图像上传、批量图像导入、特征提取模型计算、特征编码模型计算等。
在数据计算集群中部署了Hadoop平台(HDFS、HBase、Yarn)以及Flink、Kafka、Zookeeper等组件。其中HDFS负责进行底层数据的存储,具体由HDFS的DataNode进行文件分片多备份存放,由NameNode进行元数据管理和文件操作管理,同时通过Zookeeper注册两个NameNode并实时监控状态,防止一方故障立即切换到另一个,从而保证NameNode的高可用性。HBase负责对医学图像和特征编码进行存储,由HMaster管理多个RegionServer进行数据维护和查询,底层由HDFS进行存储。对于实时计算部分通过Kafka Broker接受Kafka生产者生产的实时消息,再通过Kafka消费者Flink进行处理计算,其中Kafka的生产、消费进度由Zookeeper进行记录。Flink不仅提供实时计算,同时提供离线批量计算,其计算过程通过Yarn申请计算资源,具体由ResourceManager管理资源并分配到NodeManager上进行计算。
3 主要模块设计
3.1 医学图像存储模块
系统在接收到Web端的医学图像上传请求后,首先在MySQL业务库中创建图像记录,然后服务器后台将图像文件的字节码对应业务库中的图像ID存储到HBase中,实现海量医学图像数据的存储。在图像经过特征提取和编码后,将编码后的图像特征对应图像ID存储到HBase中,在图像检索的过程中通过Phoenix进行查询。
对于海量文件的存储,通常的方案是通过HDFS进行分布式存储。HDFS系统在存储过程中将文件切分成多个block多副本存储在多个节点上,从而保障文件的可用性和拓展性,默认每个block的大小为128 MB。然而,HDFS通过NameNode加载每个文件的元数据信息,一般上传图像文件的尺寸都较小,在大量这种小文件的存储情况下,其每个小文件都会占用一个block,造成HDFS产生大量的文件元数据信息。这些元数据信息会给NameNode的内存和计算带来很重的负担,从而降低系统的存储效率。为了解决HDFS在小文件存储方面的问题,通常的做法是先将很多小文件合并成一个大文件再保存到HDFS,同时为这些小文件建立索引,以便进行快速存取,如Hadoop自带的HAR文件和SequenceFile方案。但是这两种方案均需要用户编写程序定时进行小文件的统一合并,且不支持文件追加和修改,并不适合医学图像实时上传、频繁更新业务库的场景。因此,系统将图像文件通过字节码的形式直接存储在HBase中,从而避免HDFS存储过多的小文件、影响效率的情况。
系统利用HBase存储医学图像文件数据和特征编码等数据,进而通过Phoenix进行结构化查询。HBase作为分布式数据库,通过多个Region对数据进行存储,在实时查询方面具有很强的优势。然而默认情况下HBase的表结构分区只有一个,在写入读取时会增大单节点的负担,没有发挥集群的优势。此外,一条记录由它的RowKey唯一标志,并决定该条记录存储于哪个分区。因此,在设置多个分区后也需要考虑分区的分配策略,即进行合理的RowKey设计,从而对数据进行均匀分布,防止出现数据热点问题。
在本系统的HBase存储设计部分共包括创建表、预分区、RowKey设计等环节,包括:
1)创建图像存储表,设计两个列族MD(image data)、MI(image info)分别存放图像的字节码和图像信息(图像id、图像特征码等),在创建表的同时进行预分区操作,设计共9个分区,指定每个分区的RowKey范围,建表语句如下:
create2′'image_info′, {NAME => ′MD′}, {NAME => ’MI’}, SPLITS => [′0000|′, ′0001|′, ′0002|′, ′0003|′, ′0004|′, ′0005|′, ′0006|′, ′0007|′, ′0008|′]
2)根据预分区设计,在向HBase中插入数据时需要对RowKey进行相应的格式约束,即在保证RowKey唯一性的同时确保其前缀格式为“000x|”。本系统首先根据医学图像在业务库的唯一ID通过MD5加密生成Hash值;然后获取RowKey前缀:将得到的Hash值转成Long型,并根据预分区数对9取余,其中字符’a’~’f’替换为’10’~’15’;再取Hash值的后八位作为RowKey的后缀,拼接前缀作为最终的Row Key。
3.2 图像特征提取与编码模块
传统树结构索引方法存储空间占用过大,且随着维度的增长空间代价成倍变大,因此需要通过对原始数据进行哈希编码压缩以节省空间。目前对哈希编码的研究主要包括数据无关哈希和数据驱动哈希:数据无关哈希方法以局部敏感哈希[7]为代表,在不考虑数据分布的情况下将原始空间中的数据投影到超平面获取相应编码。数据驱动哈希方法主要通过判别数据结构及分布信息来自动学习哈希函数,代表方法有谱哈希[8]、迭代量化[9]、乘积量化[10]、笛卡尔K均值[11]及组合量化[12]等。与其他编码方法相比,乘积量化模型能够有效解决聚类中心数量膨胀问题,进而提升大规模图像检索过程中的数据存储效率。
系统根据应用场景分为批量导入图像时的特征量化以及用户在实时上传图像时的特征量化。
1)批量导入图像特征量化:
系统实现医学图像的批量导入功能,用于历史或外部图像的离线导入场景。其过程如下:
(1)将图像信息记录到业务库并将图像字节码和图像id存储在HBase中;
(2)通过DeepLearning4J调用预训练的深度卷积神经网络VGG-16模型提取图像特征;
(3)使用乘积量化编码模型对提取的图像特征进行量化编码;
(4)将图像特征编码存储到HBase中。
2)实时图像特征量化:
在多用户同时在线的场景中,为保证用户在上传图像后能被其他用户同步到以供检索,设计实时图像检索模块,对增量上传的图像进行实时特征提取和特征量化编码,从而实现系统的时效性。其实现过程包括:
(1)通过命令行创建Kafka消息订阅的topic,表示一条图像上传的实时记录,设计topic名为imageupload,定义副本数2个,分区数9个。
bin/kafka-topics.sh --zookeeper node01:2181 --create --replication-factor 3 --partitions 9 --topic imageupload
(2)Web服务响应用户的上传请求,首先将图像基本信息存入MySQL库中;接着创建Kafka的生产者,由Kafka生产者将图像上传消息类进行序列化,包括图像的基本信息及图像文件字节码;然后,通过KafkaProducer类发送到imageupload的topic中;同时,利用回调函数监测是否发送成功,异常则触发报警。因为系统对图像上传顺序的要求不高,因此Kafka的消息按照轮询的方式进行存放在每个分区中。
(3)创建Flink on Yarn任务实现Kafka的消费者进行实时处理。Flink任务实现记录图像信息到业务库、提取图像特征、存储图像字节码和图像特征编码到HBase中。
3.3 图像并行检索模块
在医学图像并行检索的Flink任务执行过程中,对于输入查询的医学图像,本文首先利用CNN模型进行深度特征提取,然后对哈希编码后的特征向量采用非对称距离度量进行距离计算,最终输出距离最近的相似医学图像。利用非对称距离度量的优势在于能够避免直接计算查询医学图像深度特征向量与数据库中每个向量的欧式距离,从而减少查询时间、提高检索效率。
图4是医学图像并行检索过程的示意图。通过事先计算深度特征哈希数据库中每个聚类中心与其子向量的距离建立检索查找表;对于需要查询的医学图像深度特征向量q,计算其与数据库中聚类中心xi′的距离,即为该向量与其他图像向量之间的非对称距离;通过比较q与聚类中心的距离找出最近的聚类c,设距离为l;最后,遍历查找表将c聚类中每个向量与聚类中心的距离与l相加,即获得q与该聚类中所有向量的距离,筛选距离排序获得最近似的特征向量并返回对应的医学图像。
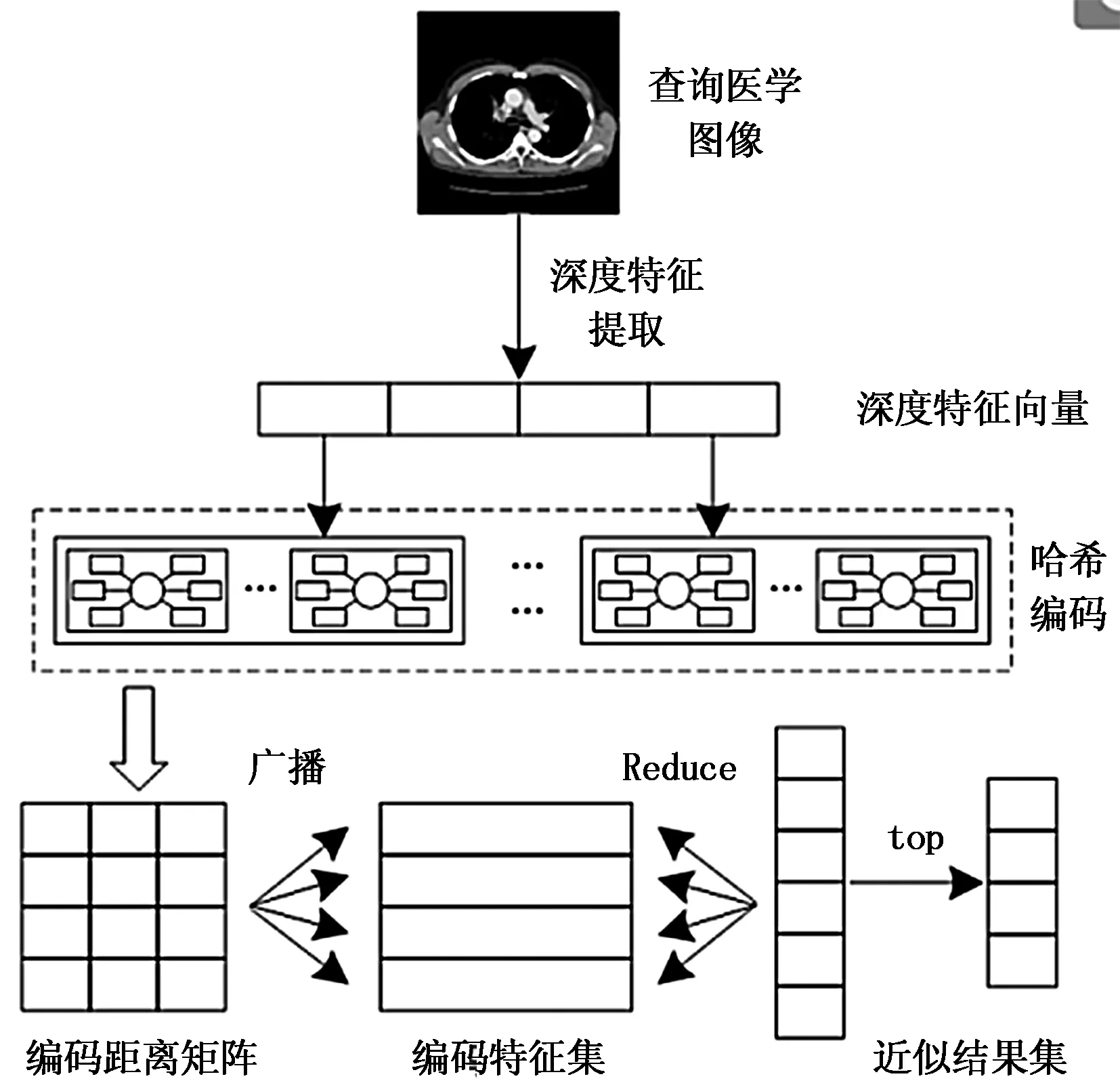
图4 医学图像并行检索过程
4 实验结果与分析
4.1 实验环境
为了实现医学图像特征提取模型的高效训练和并行检索模型的分布式执行,本文将模型训练和集群应用两部分实验分在不同的环境中执行。其中,模型训练过程环境选用GPU型号为Tesla K80、12 GB内存的Google云服务器,并采用Python 3.6和Tensorflow 1.7的深度学习框架。集群应用环境选用1个主节点和3个计算节点,各节点配置情况如表1所示。
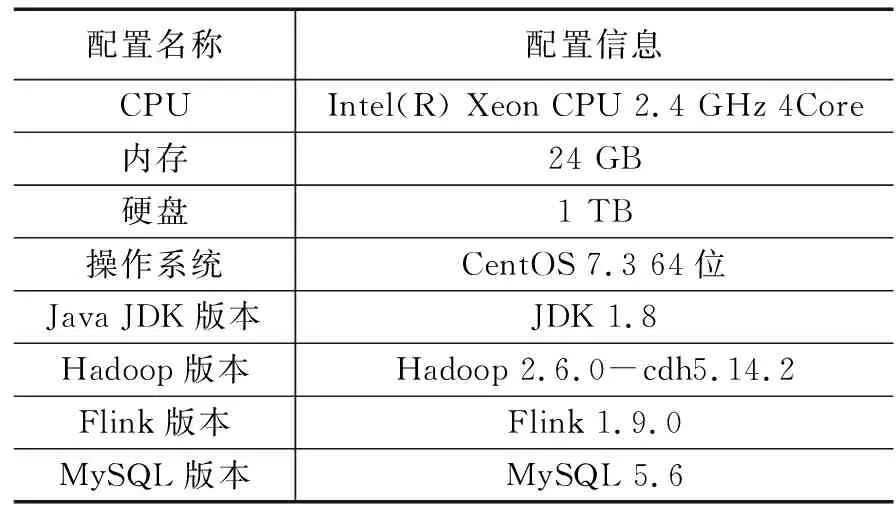
表1 分布式节点配置情况
服务器集群采用4个节点(node00~node03)并采用CDH进行部署管理,包括HDFS、Yarn、Zookeeper、Kafka、HBase等组件的部署、监控管理。此外,还部署了Flink计算组件、MySQL主备节点、Redis内存数据库等,具体组件子服务的分配状况如表2所示。
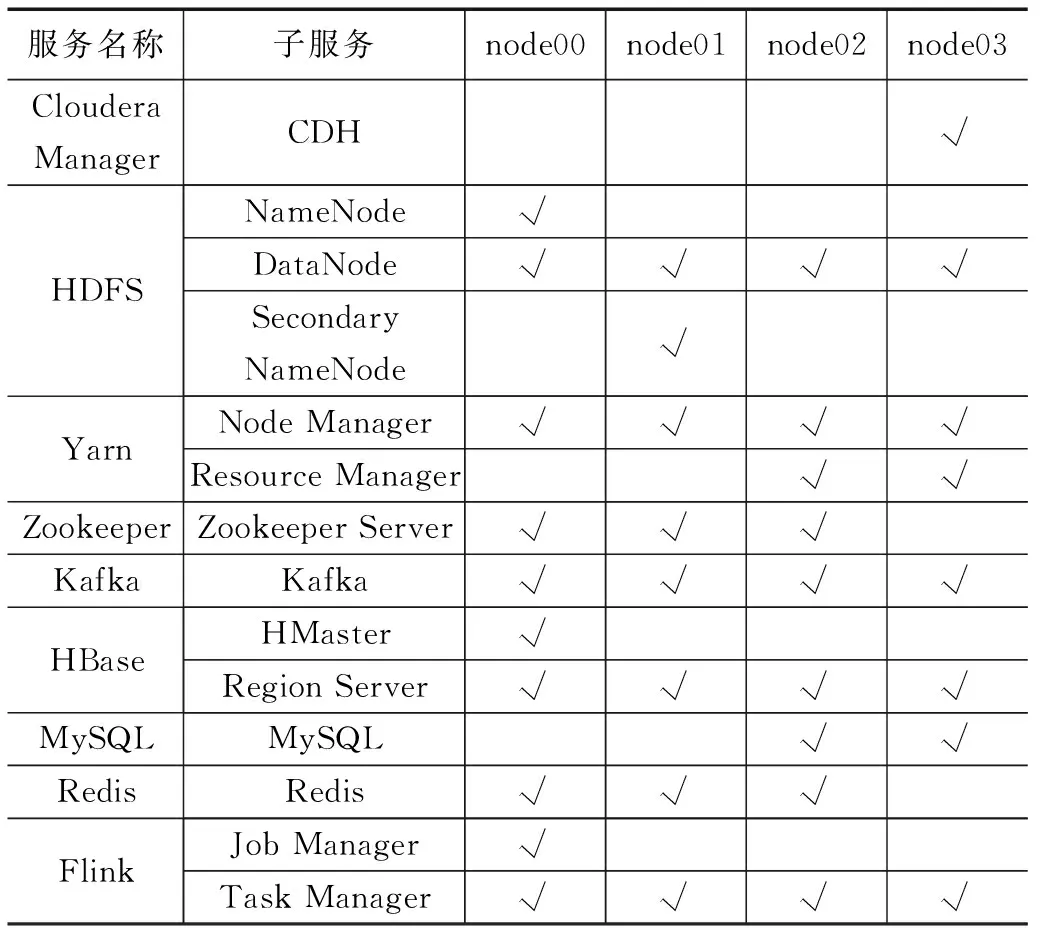
表2 服务器集群组件分配情况
实验数据集选用由美国国立卫生研究院临床中心(NIHCC)的团队开发的医学图像数据集DeepLesion[13],是来自4 427个患者的多类别、病灶级别标注临床医疗CT图像开放数据集。该数据库中目前已有32 735张CT图像及病变信息,去除重复记录后共有已标记的病变图像9 624个,包括:肺(2 370)、腹部(2 119)、纵隔(1 640)、肝脏(1 257)、骨盆(843)、软组织(660)、肾(488)和骨(247)共8种损伤类型。
本文实现的医学图像检索方法在DeepLesion数据集上进行医学图像特征提取和分布式并行检索。根据给定医学图像实现数据集中相同病灶、相似损伤的其他医学图像的检索,从而有效地辅助医疗诊断过程。
4.2 图像检索效率分析
为了验证基于Flink的医学图像检索系统的图像检索效率,本文分别使用MapReduce、Spark和Flink三种分布式计算组件实现并行检索环节,并对比不同组件在不同图像数据量下进行医学图像检索的时间。
各组件检索时间对比如图5所示。在使用3种组件时,并行检索的时间均随着数据量的增大而增加。其中MapReduce效果相对更差,且使用时间增长也较快。Spark和Flink使用时间相差不多,总体来说Flink的处理效果更好,且随着处理数据量的增加,Flink的计算效率明显更优于Spark。因此,使用Flink进行分布式图像检索的计算更具优势。
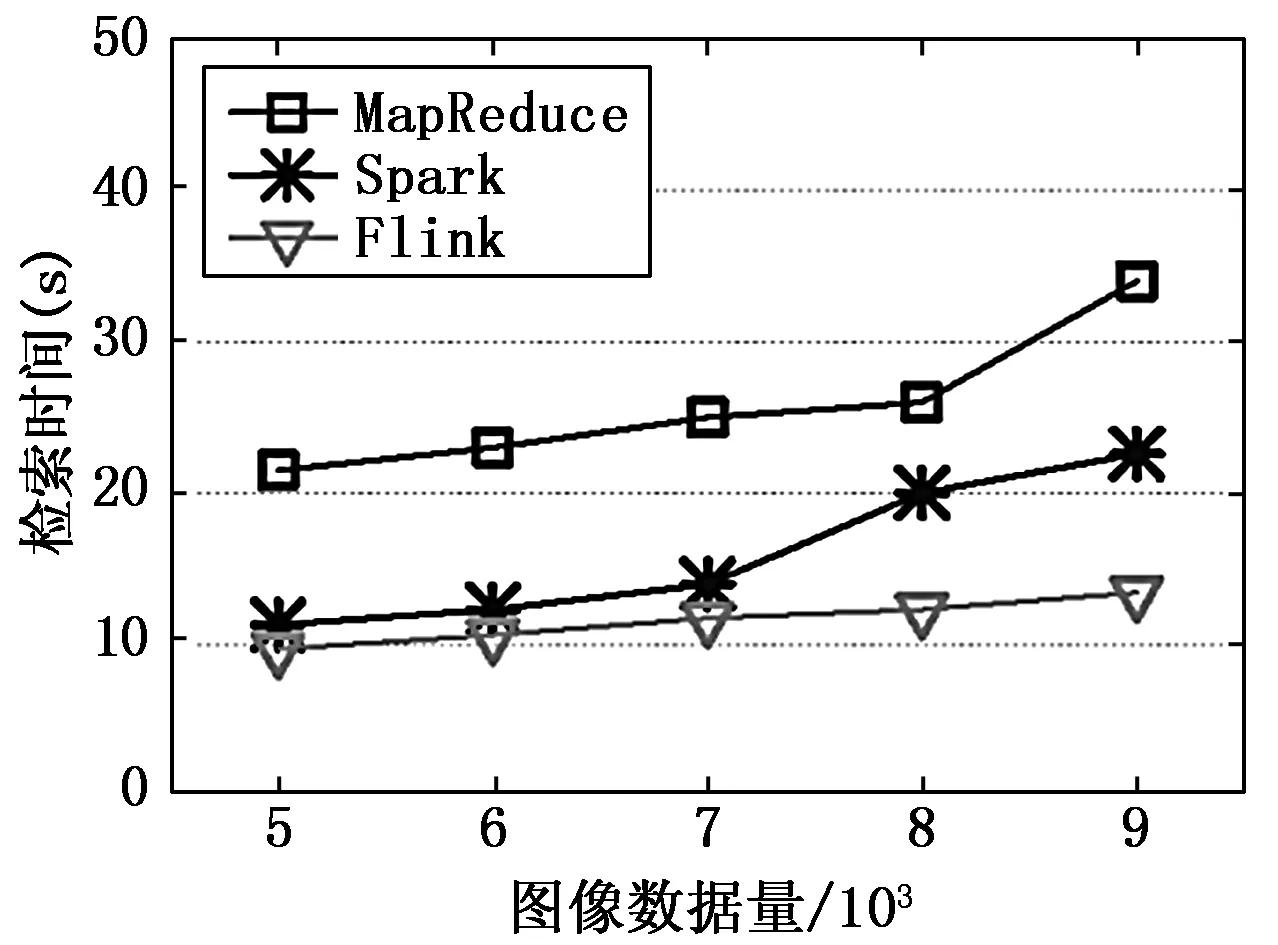
图5 各组件检索时间对比图
4.3 系统功能效果
进入医学图像检索系统,用户首先通过用户名、密码、验证码的方式进行登陆。如果忘记密码可以通过邮箱找回密码。具体操作如图6所示。

图6 系统用户登陆界面
同时,新用户进入系统可以通过注册账号,填写用户名、姓名、邮箱、设置密码等表单信息进行新用户的申请。具体操作如图7所示。
图7 新用户账号注册界面
进入桌面化的系统界面后选择打开桌面上的应用进行操作,系统根据权限不同提供医学图像管理、用户信息管理、日志管理、系统状态管理、多媒体应用等应用。
在医学图像管理模块,用户通过医学图像上传应用对图像信息、图像描述、图像文件进行填写,图像上传后存储在HBase平台中。具体操作如图8所示。
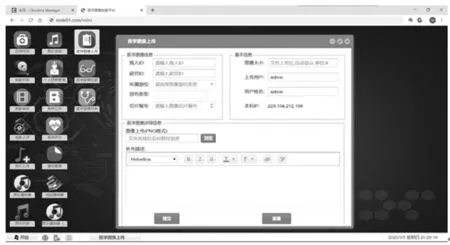
图8 医学图像上传应用操作界面
用户可以通过医学图像列表应用查看医学图像记录,可以根据图像类型、开始时间和结束时间进行简单筛选。具体操作如图9所示。

图9 医学图像列表应用操作界面
在医学图像检索应用中,用户可以通过以图搜图的方式对医学图像库中已有的图像进行检索,检索结果按相似度从小到大进行排序。具体操作如图10所示。
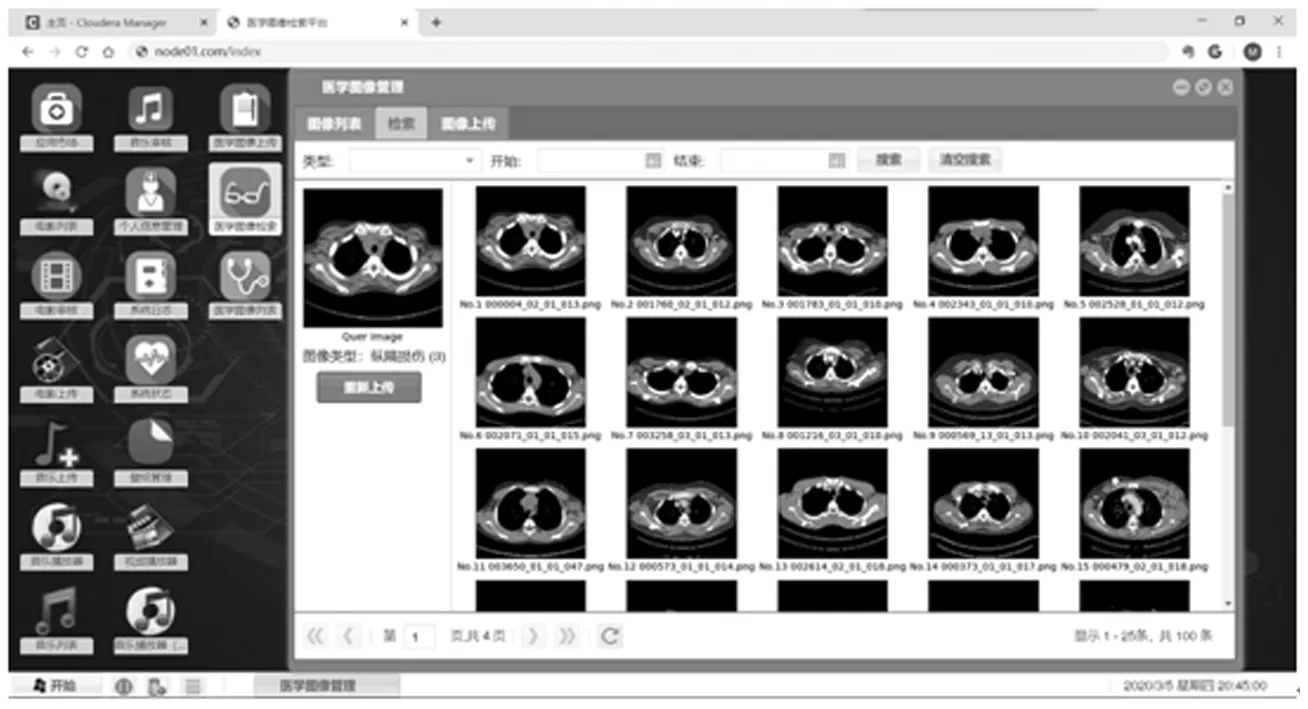
图10 医学图像检索应用操作界面
5 结束语
针对海量医学图像存储、检索的效率问题,本文设计并实现一种基于Flink的医学图像检索系统。系统利用Flink批流一体的架构提高并行检索效率,实现实时图像编码、批量图像上传编码和图像并行检索。图像检索过程使用深度卷积神经网络模型提取图像特征并利用乘积量化编码模型进行特征编码。同时,通过Web应用作为用户操作入口,系统通过HBase存储医学图像数据和图像特征编码数据。实验结果表明,本系统具有更好的检索效率表现,满足实际应用需求。
猜你喜欢
小学生学习指导(中年级)(2021年12期)2021-12-30
昆明医科大学学报(2021年4期)2021-07-23
纺织科学研究(2021年6期)2021-07-15
技术与创新管理(2020年5期)2020-10-09
科学与财富(2019年27期)2019-10-25
意林(图解作文)(2019年6期)2019-07-16
信息化建设(2019年2期)2019-03-27
疯狂英语·新读写(2018年3期)2018-11-29
科学与财富(2017年28期)2017-10-14
知识就是力量(2017年2期)2017-01-21
