
基于标签语义相似的动态多标签文本分类算法
2020-10-10 01:00姚佳奇徐正国燕继坤李智翔盲信号处理重点实验室成都610041
计算机工程与应用 2020年19期
姚佳奇,徐正国,燕继坤,熊 钢,李智翔盲信号处理重点实验室,成都610041
1 引言
多标签文本分类是自然语言处理的一个基础问题[1-2]。传统的多标签文本分类算法适用于标签闭集的问题。然而在实际应用中,如根据邮件内容确定接收人、新闻、商品评论的标签分类等问题,都会随着时间的进展,不断出现新的标签,或者标记规则发生变化导致标签的变化,本文将这些问题归纳为动态多标签文本分类问题,由于标签随时间发生变化,传统的多标签文本分类算法在处理动态多标签文本分类问题上出现了应用瓶颈。
一种简单的方法是通过内容相似解决动态多标签文本分类问题。即通过计算待分类文本与历史文本的内容相似度,如计算两个文本的TF-IDF向量的相似度,然后将与待分类文本最相似的历史文本的标签分类给待预测文本。然而内容相似度高并不意味着具有相似的标签。如图1 所示,“我喜欢吃苹果”与“我不喜欢吃苹果”在内容上很相似,但第一句是正向情感标签,而第二句是负向情感标签。

图1 内容相似但标签语义不相似的示例
因而,本文提出了一种基于标签语义相似的动态多标签文本分类算法(Dynamic Multi-Label Text Classification algorithm based on Label Semantic Similarity,DMLTC-LSS)。DMLTC-LSS算法首先按照标签固定的方式训练基于卷积神经网络的多标签文本分类器,然后取出该网络的倒数第二层的向量为文本的特征向量。由于该特征向量是在有标签监督的环境下训练得到的,因而含有标签的语义信息。在测试阶段,将待分类文本通过训练阶段的多标签文本分类器获取相应的特征向量,然后采用最近邻的算法获取与带分类文本特征向量最相似的训练集文本的标签,并将该标签分类给待预测文本。考虑到与待分类文本时间越近的文本越有可靠性,DMLTC-LSS 在标签语义相似的基础上乘以时间衰减因子,使得时间越近的文本的相似度越高。
本文分别测试了基于卷积神经网络、循环神经网络和BERT 的算法以及基于内容相似的算法在处理动态多标签文本分类问题上的性能。然后在基于卷积神经网络的多标签文本分类器的基础上,构建了DMLTCLSS 算法。实验结果表明,本文提出的DMLTC-LSS 算法具有较优的性能。
2 相关工作
2.1 文本特征
文本特征可以按照词的表示方法分成两类:一类将词表示成独热向量(One-Hot),即独热模型;一类将词表示成固定长度的连续向量,即词嵌入模型(word embedding)[3]。基于独热向量的文本特征,如TF-IDF 无法表示词的语义信息,导致了建立在该文本特征上的机器学习模型的性能受限。然而在大规模语料集上训练得到的词嵌入模型利用了词的共现信息,从而一定程度上捕获了词的语义信息。CBOW和Skipgram是两种经典的训练词嵌入模型的算法[4-6]。由于词嵌入上述优势,研究者提出了许多基于词嵌入的文本分类模型[7]。这些模型可以根据采用的神经网络架构划分为基于卷积神经网络[8-9]和基于循环神经网络两大类[10-11]。
最近,一些研究者提出一个词在不同的上下文中具有不同的语义,应当具有不同的向量表示[12]。因而,研究者提出了具有上下文背景的词嵌入模型,如ELMo[12]、GPT[13]和BERT[14]等。这些模型首先根据某些训练目标(如预测下一个词)训练得到语言模型,然后再根据下游任务微调语言模型。实验结果显示具有上下文背景的词嵌入模型在多项自然语言处理任务中取得了最优的性能。
2.2 多标签分类
多标签分类任务是赋予一个样本多个相关的标签。多标签分类算法大体上可以分成两类:问题适应类和算法适应类。
(1)问题适应类:即将多标签分类问题转换成其他学习问题。典型算法包括BR(Binary Relevance)[15]、
Classifier Chains(CC)[16]、Calibrated Label Ranking(CLR)[17]
和Label Power(LP)[18]等。BR 将多标签分类转换成了多个二分类问题,因此,BR算法未能够利用标签之间的关联。CC 算法则构造了链条式的二分类器,链条上后一个二分类器将前一个二分类器的输出作为输入。CLR算法则在两两标签之间构造二分类器。LP直接将多标签分类转换成了多类别分类问题。
(2)算法适应类:即修改分类算法适应多标签分类问题。典型算法有基于KNN 算法的ML-KNN[19]、基于决策树算法的ML-DT[20]、基于SVM算法的Rank-SVM[21],以及利用二值交叉熵损失函数(Binary Cross-Entropy,BCE)代替交叉熵损失函数的神经网络类算法[1]。
3 基于标签语义相似的动态多标签文本分类算法
本文提出了一种基于标签语义相似的动态多标签文本分类算法DMLTC-LSS。DMLTC-LSS 算法的整体流程如图2所示。

图2 DMLTC-LSS算法流程



图3 基于卷积神经网络的多标签文本分类器示意图

加上时间衰减因子修正的相似度函数为(*表示逐元素相乘):

4 实验结果与分析
4.1 实验数据集
(1)Reuters-21578新闻数据集
本文使用Reuters-21578 新闻数据集构造了用户感兴趣主题随时间变化的数据集。具体构造方式为:首先筛选出样本数目最多的10 个标签,并按照时间顺序排序;然后创建了5 个用户(A~E),3 种感兴趣主题关系,分别是{A:labels[0:3],B:labels[1:4],C:labels[2:5],D:
labels[3:6],E:labels[7:9]},A:labels[0:2],B:labels[3:3],C:labels[2:4],D:labels[3:5],E:labels[6:9]},{A:labels[2:4],B:labels[4:5],C:labels[5:6],D:labels[4:7],E:labels[5:9]},其中A:labels[0:3]表示用户A感兴趣0,1,2,3主题,其余类似;最后按照时间顺序每2 000个样本改变一次感兴趣主题关系,3种感兴趣主题关系循环使用。本文按照文献[22]的方式划分了训练集和测试集,并从训练集中选取按照时间排序的后10%的样本作为验证集。此外,本文公将在Reuters-21578数据集上的实验代码公布在了Github上(https://github.com/JiaqiYao/dynamic_multi_label)。
(2)中文邮件数据集
本文采集了某公司内部1年的74 000份邮件,抽取邮件中的邮件内容(content)、接收人列表(receivers)和发送时间(post_time)要素,构造成(content,receivers,post_time)三元组,并按照发送时间顺序排序,选取1~60 000 份邮件为训练集,60 001~67 000 份邮件为验证集,67 001~74 000 份邮件为测试集。不同的收件人的总数为232个。
4.2 对比模型与实验配置
本文选取了基于卷积神经网络的XML-CNN[9]、基于循环神经网络的HAN[10],并改造BERT[14]使其适用于多标签文本分类。同时,本文构造了基于TF-IDF 特征向量的最近邻算法,用以验证基于内容相似的算法的性能。下面分别介绍上述各个算法以及本文提出的DMLTC-LSS算法的详细实验配置。
对于Reuters-21578 数据集,本文使用Google 预训练的词向量[6]。而采集的中文邮件数据集,本文首先应用jieba将采集到的邮件内容分词,然后采用word2vec[4-6]的Skip-gram 模型预训练词嵌入模型WE∈RNw×dw,Nw为语料集的词的个数,dw为词嵌入向量的维度,本文设定为300。此外,本文所有基于神经网络模型的损失函数均为二值交叉熵(Binary Cross Entropy,BCE)损失函数,并采用Adam[23]优化算法,学习速率通过验证集上的性能确定。
(1)基于卷积神经网络的XML-CNN
XML-CNN 采用卷积神经网络作为基本架构。本文采用了尺寸为3×300、4×300、5×300的卷积核,每个卷积核的个数为256,激励函数未Relu 函数,应用最大池化函数,在倒数第二层加入了随机失活层(Dropout)减少模型的过拟合,提高模型的性能,随机失活率为0.5。
(2)基于循环神经网络的HAN
HAN(Hierarchical Attention Network)模型为层次注意力模型,分别在词级(word-level)和句子级(sentencelevel)应用自注意力机制。本文仅应用了词级的自注意力机制,采用GRU 的循环神经网络模型,每个GRU 中含有128个单位,激励函数为双曲正切函数(tanh),在循环神经网络层之后加入随机失活层,随机失活率为0.5。
(3)BERT模型
本文使用了预训练的BERT 模型,英文模型为uncased_L-12_H-768_A-12,中文模型为chinese_L-12_H-768_A-12[14]。这两个模型均由12层Transformer模块构成,每个Transformer 模块由768 个隐层单元和12 个多线头(multi-heads)组成,总共约110M个参数。
(4)基于TF-IDF的最近邻算法
首先在jieba 分词的基础上构建文本的TF-IDF 特征,本文没有使用停用词表,而是将文档频率超过0.9的词滤除掉,然后基于向量的余弦相似度应用最近邻算法分类待分类的文档。
(5)DMLTC-LSS
DMLTC-LSS 算法建立在XML-CNN 模型的基础上,在训练好XML-CNN 模型后,按照第3 章的描述运行DMLTC-LSS算法。DMLTC-LSS算法的超参数衰减因子η的具体数值通过验证集上的性能确定。同时,本文对比了基于HAN 和BERT 的最近邻算法,其中HAN也取倒数第二层为文本的特征向量,BERT 则取原模型中的[CLS]对应的向量。
4.3 结果与分析
本文采用基于样本平均的精确率(Precision)、召回率(Recall)和F1指标度量算法的性能。令yi表示一个样本xi的标签集合,f(xi)表示分类器预测的标签集合,N表示总共的样本个数。

实验结果如表1和表2所示(其中*表示采用了时间衰减因子,HAN#*和BERT#*分别表示基于HAN 和BERT的最近邻算法)。
从实验结果中可以看出:
(1)基于TF-IDF 的最近邻算法是一种基于内容相似的算法,在精确率、召回率和F1 性能指标上表现均不好。
(2)DMLTC-LSS*算法,即基于标签语义相似的动态多标签文本分类算法在两个数据集上均取得了最优的结果,充分说明了本文提出的算法的有效性。
(3)DMLTC-LSS*相较于DMLTC-LSS 的性能更优,表明加入时间衰减因子使得较新的样本具有相对更近的距离,对动态多标签文本分类的必要性。
(4)本文对比了基于HAN 和BERT 的最近邻算法,并且也加上了时间衰减因子,实验结果表明相对于原始的HAN 和BERT 而言,性能有所提升,但是没有超过DMLTC-LSS*算法。动态多标签文本分类数据集的概率分布p(x,y)随着时间发生变化,因而对于HAN 和BERT 等具有较大模型容纳能力的模型而言,容易过拟合,从而影响其倒数第二层提取含有标签语义信息的特征能力。

表1 Reuters-21578实验结果
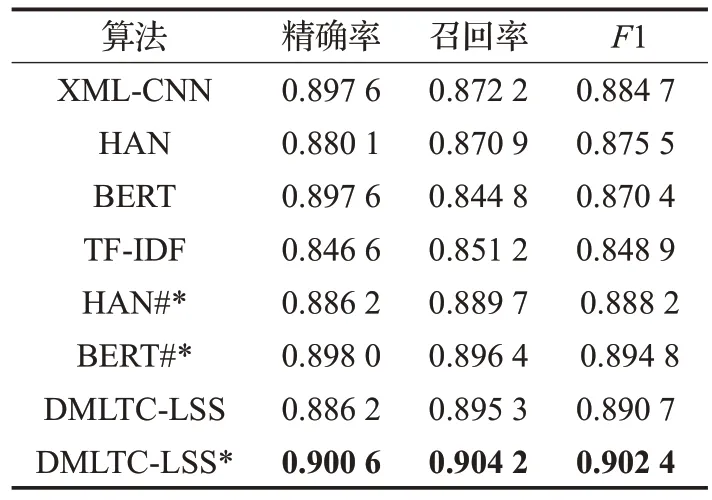
表2 中文邮件实验结果
5 结束语
本文提出了一种基于标签语义相似的动态多标签文本分类算法(DMLTC-LSS),主要用于解决标签随着时间的进展不断发生变化的多标签文本分类问题。DMLTC-LSS算法利用传统多标签文本分类提取文本的特征向量,该特征向量是在标签监督下训练得到,因而内涵标签语义信息,从而使得基于该特征向量的相似度反映了标签语义的相似度。在标签语义相似度的基础上,本文加上了时间衰减因子的修正,进一步提升了算法的性能。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
开放教育研究(2020年2期)2020-03-31
数学大世界(2019年7期)2019-05-28
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
中华建设(2017年1期)2017-06-07
中国修辞(2017年0期)2017-01-31
中国社会历史评论(2016年2期)2016-06-27
长江学术(2016年4期)2016-03-11
