
基于稀疏子空间的局部异常值检测算法
2020-10-10 01:00覃凤婷杨有龙仇海全
计算机工程与应用 2020年19期
覃凤婷,杨有龙,仇海全,2
1.西安电子科技大学 数学与统计学院,西安710126
2.安徽科技学院 信息与网络工程学院,安徽 凤阳233100
1 引言
随着信息科学技术的发展,越来越多的数据被收集和储存在数据库中。从海量的数据中挖掘一些新颖的、潜在有用的、最终可理解的知识是非常有意义的。大部分研究的重点是构造一个对大多数数据(正常值)的通用模式映射,然而,从知识发现的角度来看,异常数据通常比正常的更有趣,因为它们包含异常行为背后的有用信息。因此,异常值检测渐渐引起广大研究者的关注,成为数据挖掘领域的重要组成部分。其主要任务是识别出与大多数据明显不同的数据。异常值检测(也称离群点检测)往往在网络入侵检测[1-2]、电话和信用卡欺诈检测[3]、医疗诊断[4]等方面有着重要的研究价值。例如,在医疗诊断中,误诊的情况远远少于确诊的情况,但是误诊付出的代价往往比确诊要高很多。
现有的异常值检测方法大部分侧重于从全局角度识别异常值,但是随着数据量和维度的爆炸性增长,全局异常值的挖掘变得很难实现。为了克服这个困难,局部异常值检测技术逐渐引起研究者的重视。文献[5]最早提出了局部异常值概念,该方法依据对象与其k 近邻的差异定义对象的异常度,高于给定阈值的数据对象即为异常值,但该方法并不适用于大规模高维数据集。因为高维数据集中存在部分不相关的属性,导致一些异常值在全维空间中可能无法检测出来。而且这种不相关的维度会影响异常值检测的效率,同时会减小异常值挖掘的准确性。换言之,如果数据点的异常度是从全维空间中得到的,则大多数现有的异常值检测算法的效率会非常的低。
在高维数据集中,异常值通常包含在一些由部分维度构成低维子空间中,并且不同的异常对象可能存在于由不同的部分属性张成的不同子空间中[6],因此,如何找到包含局部异常值的子空间是高维异常值挖掘的一个非常关键的问题。另外,在全维空间中一般无法体现异常数据与其他正常数据的偏差,这些偏差往往嵌入在一些低维的子空间中。即,局部异常值可以投影到低维的子空间中,因此目标可转为搜索有利于表征异常值的子空间。但是,数据集中的维度和数据对象的指数型增长使得异常子空间检测成为一个NP 难问题[7]。直接使用穷举搜索一一列举显然是不可行的。
为克服高维数据异常值检测的缺点,本文提出了一种基于稀疏子空间的局部异常值检测技术(Sparse Subspace-based method for Local Outliers Detection,SSLOD)。该方法首先在每个维度上分析每个对象的局部异常程度,据此删减高维数据集中与异常值不相关的维度以及冗余的数据,对初始的数据集进行一个初步的约简。然后,给出了满足稀疏子空间的判断标准。最后,利用改进的粒子群优化算法在约简属性和对象后的子空间中搜索稀疏子空间,从而挖掘出异常值。实验结果表明,SSLOD算法具有良好的性能。
2 相关工作
在数据集中,异常值往往是与大多数对象表现相对不一致的数据对象,以至于怀疑它是由其他机制产生的。现存的异常值检测方法可分为以下几个类[8-9]:基于分布的、基于距离的、基于聚类的、基于密度的、基于角度的、基于子空间的。
基于分布的方法源自统计,它基于一些标准分布模型(正态、泊松等),如果一个数据点偏离标准分布的程度太大,则该数据点被认为是异常值[10]。例如,在正态分布中,异常值与数据期望的距离大于方差的3 倍[11]。但是在现实世界中,数据的分布函数的情况通常是未知的,尤其是对于高维数据集。由于在实际应用中,数据并不能保证服从某一标准分布,从而无法从数据中找出异常值。
基于距离的方法不需要假设任何数据的分布情况,其基本思想是利用已有的距离度量方法(如曼哈顿距离、欧几里得距离等)计算所有数据点之间的距离,根据距离关系识别异常值。文献[12]将异常值定义为:当某个数据点与数据集中p%的数据点的距离超过d 时,该数据点被认为是异常值。该方法的难点是参数p 和d对异常值检测结果影响大,且不易找到合适的值。同时,对于高维数据集在计算距离之前首先需要降维。
基于聚类的异常值检测方法是由聚类算法优化而来的[13]。在基于聚类的方法中,常见的异常值定义有两种。一种是将聚类后的较小的簇视为异常值,但是不能判断单独的点是否是异常值;另一种是聚类后将不属于任何簇的数据点视为异常值,但是聚类结果很影响异常值检测的结果。
基于密度的方法的基本思想是通过数据点的局部密度检测异常值,局部密度较低的数据点是异常值的可能性大。此类方法将异常值定义为局部密度与其邻域内的其他点明显不同的数据点,换句话说就是正常点的局部密度与其邻域点的密度非常相似。最早的基于局部密度的异常值检测方法是LOF(Local Outlier Factor)[5],该方法根据局部邻域密度为每个数据点分配一个局部异常因子LOF,LOF值高的数据点视为异常值。随后又出现了LOF模型的几个扩展,例如,基于连接的异常值算法(Connection-based Outliers Factor,COF)[14]、不确定的局部离群因子(Uncertain Local Outlier Factor,ULOF)[15]、核密度估计异常分数(Kernel Density Estimates,Outiler Score,KDEOS)[16]、基于排序差的异常值检测(Rank-difference based Outlier Detection,ROD)[17]、基于局部相对核密度的异常值检测(Relative Density-based Outlier Score,RDOS)[18]等。这些方法在一定程度上提高了异常值检测能力,但是,在测试阶段的时间复杂度偏高。
基于角度的方法一般用于检测高维数据集中的异常值。因为高维数据集一般分布在一个超球体的表面,此时欧式距离将随着维度的增加渐渐失效。基于角度的异常值检测方法将对象与其k 个近邻两两之间的夹角的方差作为判断异常值的准则[19]。方差越小越说明该对象分布在整体数据的边缘,越有可能是异常值。但是该方法无法将被几个簇包围的局部异常值检测出来。另外,由于每次都需要计算对象与其近邻两两之间的夹角,因此算法的复杂度非常高,导致算法的效率较低。
基于子空间的方法被设计为通过搜索子空间来检测异常值。由于高维空间中的数据对象是稀疏的,异常值是根据部分维度而不是整个空间来确定的。因此一般是将数据集映射到子空间,在子空间中搜索异常数据。根据子空间的度量方法不同,基于子空间的异常值检测方法又可以分为两类:相关子空间投影方法和稀疏子空间投影方法。
相关子空间投影方法是在数据集中选出对异常值有意义的属性构建子空间来进行异常值检测,投影方法一般有两种:基于线性相关的[20]和基于统计模型的[21]。前者使用局部参考集之间的线性相关性创建子空间,而后者通过在局部参考集上应用统计模型构建子空间。例如,文献[19]提出了一种在高维空间的轴平行子空间中检测异常值的方法,该方法主要是在子空间中描述数据对象的异常度。文献[22]用统计方法选择相关子空间,然后在该子空间中根据数据的偏差程度确定了异常值排名算法,数据集中每个对象均对应一个相关子空间。文献[21]提出了一种子空间搜索方法来建立高对比度子空间,确定了基于密度的异常值排序。
稀疏子空间由密度明显低于平均值的数据点构成的,密度可以根据稀疏系数来测量。根据稀疏系数阈值,可以将高维数据集投影到稀疏子空间中,该稀疏子空间的点可设想为异常值。文献[23]提出了一种高维异常值检测算法,其主要思想是将高维数据投影到低维子空间,利用遗传算法来确定异常值。该算法虽然提高了异常值检测的效率,但是异常值的完整性和准确性并不能得到保证。为了解决这个问题,文献[24]利用异常值的概念和改进的遗传算法搜索子空间。文献[25]利用网格概念来表示子空间,并研究了一种通过引入密度系数来提取稀疏子空间的方法,该方法提高了异常值检测的准确性和完整性,但是由于构造概念格的复杂性导致其检测效率较低。文献[26]为提出了一种基于属性相关性的局部异常值检测算法,该算法不同于上面方法的是使用粒子群算法搜索子空间,大大提高了异常数据的挖掘效率。
3 约简数据集
在高维数据集中实现异常值检测的高精度和高效率是一个挑战。本章提出了一种新的数据集约简方法,其作用是进行异常值检测算法之前减少数据对象和维数。该方法通过每个维度上分析数据对象的异常度,将与异常值无关的维度与异常值相关的维度分来,将与异常值无关的冗余数据识别出来。
假设D 是N×d 维的空间,A={A1,A2,…,Ad}表示属性集,X={X1,X2,…,XN}表示N 个数据点,其中Xi={xi1,xi2,…,xid}。对象Xi在属性Aj上所对应的值表示为xij(i=1,2,…,N;j=1,2,…,d)。通过检测每个维度上数据点的密度,识别与异常值不相关的属性和数据对象。密度较大的数据点一般聚集在密集区域,而密集区域的数据点是由一些相似特征构成的,这些特征对于检测异常值往往作用不大。因此,在每个维度上分析对象的密度可以更好地区分与异常值不相关的维度和相关的维度。这里利用对象在每个属性上的k 最近邻估计其在该属性上的密度。

直观上讲,ρ(xij)的值越大,就意味着xij是在该维度上是正常值的可能性越大,因此其在密集区域的可能性就越大;反之,表示xij在该维度上是异常值的可能性越大,即其在稀疏区域的可能性较大。
由于密集区域往往由具有相似特征的数据点构成。为了找到密集的区域,用γij=1/ρ(xij)表示一维对象xij的异常因子。显然,λij的值越大,xij在属性Aj上越可能是异常的,说明xij越可能在稀疏区域,反之亦然。
接下来用K(N×d)表示原始数据集所对应的稀疏密度矩阵,Kij(i=1,2,…,N;j=1,2,…,d)表示矩阵K 中的元素。给定异常因子阈值 τ ,若 γij<τ ,将Kij设置为1,表示xij是在属性Aj上是正常值,包含在密集区域;若 γij>τ ,将Kij设置为0,表示xij在属性Aj上是异常值,在一个稀疏区域。在形成稀疏密度矩阵K 的过程中涉及到参数k 的选取问题。k 值表示在一维属性上对象的近邻数,取值较小时,异常因子γij几乎没有意义。显而易见,k 值应该小于N(数据集中对象的数量)。参考其他属性约简方法PCKA[27],将k 值设置为。当然,在实际应用中,参数k 也可以由用户根据相关领域的知识自行设定并且调优。
下面用一个简单的例子说明生成稀疏密度矩阵的过程。表1 是由一个病例信息组成的数据集,包括7 个属性和12个数据对象。属性A1表示性别,0表示女性,1表示男性;属性A2表示年龄;属性A3和A4分别表示鼻塞程度和头疼程度,其值范围从0到5,表示症状从轻微到严重。属性A5的值为0时表示喉咙不痛,1时表示喉咙痛;属性A6代表患者的体温;属性A7的值从0 取到3,分别表示感冒程度是由轻微到严重。根据以上参数k 的取值方法,k=3,计算每一个属性下的一维数据点的异常因子γij,设定异常因子阈值τ 的取值为0.7,进一步得到该数据集对应的稀疏密度矩阵,如表2所示。

表1 病例信息数据
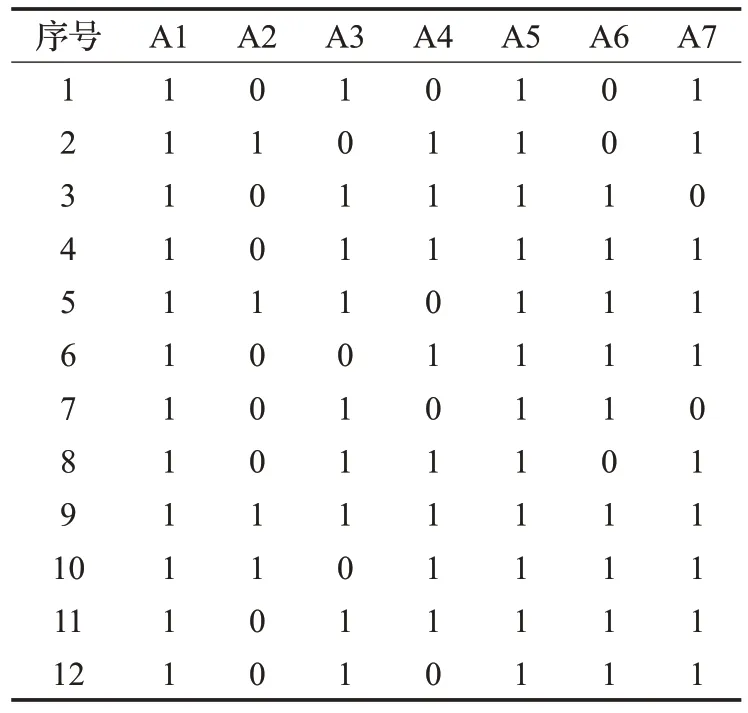
表2 病例信息数据的稀疏密度矩阵
在表2中,属性A1和A5在稀疏密度矩阵中的值都是1,说明这两个属性上的对象均是正常值,处在一个相对密集的区域,这些属性显然对异常值检测没有作用,这表明了属性A1和A5是与异常值不相关的属性。因此,在检测异常值之前,就可以先将这两个属性修剪掉。同理,第9 条数据在各个维度上的Kij值均为1,说明其在各个维度上均为正常值,为冗余数据,应修剪掉。当然,在不影响挖掘结果的正确性的前提下,对这些属性和对象进行初步约简可以显著地提高异常值挖掘的效率,数据集初步约简方法总结见算法1和算法2。
算法1稀疏密度矩阵的形成


4 基于初步约简的稀疏子空间
4.1 稀疏子空间
局部异常值是在部分维空间中与其他数据点表现明显不一致的数据对象。本文利用搜索数据空间中稀疏子空间的方法检测局部异常值。稀疏子空间是指数据的密度明显低于平均值的数据点构成的子空间,其中的数据对象即为异常值[23]。下面介绍稀疏子空间的相关知识。
给定一个N×d高维数据集D,将每个属性上的数据划分为φ个离散区间。这些离散区间是在等深的基础上划分的,因此每个区间上都包含g=1φ的对象。这里使用等深划分而不是等频划分的原因是不同位置的数据可能具有不同的密度。在d维属性上选择t个属性构成一个t维的数据集,记为D1。如果属性在统计上是独立的,根据伯努利概率,N个对象在t维属性上随机分布的概率是gt,对应的数学期望可以表示为N⋅gt,标准差是在选择出的t个属性上分别取一个区间,构成另一个t维数据集,记为D2。由于真实数据集在统计上并不一定是独立的,因此t维数据集D2中对象的实际分布与原数据集D1的期望值存在着显著地差异。那些低于平均值的异常偏差通常是由异常数据造成的,因此更有利于异常值检测。
假设数据是均匀分布的,t维数据集D2中的对象总个数可以近似为正态分布。设n(D2)是t维数据集D2中对象的个数,为了度量子空间中数据的偏离程度,D2的稀疏系数[23]定义为:

从(2)式中可以得到,若D2是稀疏子空间,那么D2中的数据点个数会小于平均值,n(D2)<N⋅gt。此时,S(D2)的值定是一个负数。然而,异常值往往分布在比较稀疏的区域,即包含在某个稀疏子空间中。
因此,稀疏子空间即为:当S(D2)小于某一个阈值θ(θ <0)时,D2就是一个稀疏子空间,其中的数据对象就是异常值,n(D2)即为异常值的个数。
要找到准确稀疏子空间的一个重要问题是如何选择参数t和φ。在d维属性中选择t个属性形成N×t的子空间,每个子空间含有期望数是N⋅(1/φ)t的数据对象。因此,当t很大时,N⋅(1/φ)t的值会很小,而稀疏因子阈值θ是一个负数,导致n(D2)很小,从而无法检测出异常值。例如,若φ=10,t=5,t维子空间中数据对象的个数须大于105,否则数据对象的期望值将会比1小,即t维子空间中包含小于1 个点数据点,这意味着不可能找到有着高稀疏系数且至少包含一个数据点的稀疏子空间。因此,参数t和φ的值应该设置的足够小,使得恰好包含一个数据点的子空间的稀疏系数是一个合理的负值。同时φ应该设置的够大,使得每个维度上有足够数量的区间对应一个合理的局部性概念。一旦给定了参数φ,参数t的范围将由极端情况导出。假设t维子空间是一个空子空间,有n(D2)=0,计算该空子空间的稀疏系数,可得:

本文的算法均选取参数t的上界。对于参数θ的取值,θ=-3 是决定参数t的一个很好的参考值[23]。在具体应用中,用户也可以根据实际情况设定不同的θ值,以确定适当的t值。
4.2 改进的粒子群算法搜索稀疏子空间
粒子群优化(Particle Swarm Optimization,PSO)算法一种基于群体的智能全局搜索优化算法[28]。由于概念简单,参数少,收敛速度快,PSO算法渐渐被应用到各类算法中。本文将使用改进的粒子群算法搜索稀疏子空间。
4.2.1 标准粒子群算法
PSO算法首先初始化一群粒子,即优化问题的候选解。每个粒子都有一个位置向量和一个决定方向和步长的速度向量,并且都有一个由优化函数给出的适应值。然后粒子在解空间中跟随最优的粒子进行搜索并且更新自身的位置和速度。同时粒子自身的最优位置(称为Pbest)和整个种群的最优位置(称为Gbest)也在算法的每次迭代中不断地更新直到达到终止条件,最后得到的全局最优位置就是优化问题的最优解。粒子的速度和位置可表示为:

4.2.2 改进的粒子群算法
随机惯性权重在PSO算法中,惯性权重控制粒子的历史因素对其当前状态的影响程度。为了平衡算法的全局搜索能力以及它的局部搜索能力,可以对惯性权重进行调整。在大多数改进的PSO 算法中,权重ω一般使用线性递减的方法进行更新。这种更新方法在搜索算法的前期时,ω有利于取到全局搜索的最优值但是搜索效率比较低;在后期时ω虽然有利于加快算法的收敛速度,但是很容易导致算法陷入局部最优。
为了克服这个缺点,可以将惯性权重设置为随机变量。惯性权重的随机性可以使粒子在前期和后期都有可能取到较大或较小的权值,有利于算法跳出局部最优,同时可以提高算法的全局搜索能力。因此,提出以下惯性权重的公式:

其中,μmin表示随机惯性权重的最小值,μmax表示其最大值,rand( )是[0,1]之间的随机数。μmin和μmax的初始值分别设定为0.5和0.95。
异步学习因子在PSO 中,若学习因子c1和c2在优化问题过程中有着不同的变化方式,那这两个学习因子就是异步变化的。异步学习因子表示为:
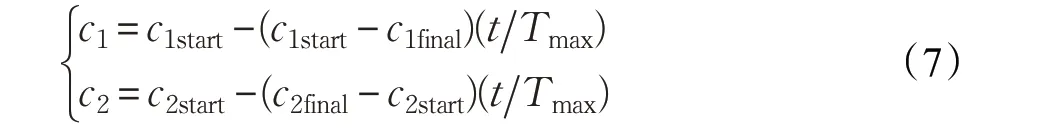
其中,c1start和c2start分别是c1和c2的初始值,c1final和c2final分别表示其迭代后的终值。t是当前迭代次数,Tmax是最大迭代次数。
若在前期阶段取较大的c1和较小的c2,会使得粒子更多地向自身最优学习而较少地向全局最优学习,可以使粒子的全局搜索能力得到提升。在后期取较小的c1和较大的c2,会使得粒子更多地向全局最优学习而较少地向自身最优学习,有利于算法快速收敛到全局最优解。因此,改进PSO 算法的初始参数设定如下:c1start=2,c1final=0.5,c2start=0.5,c2final=2。
假设约简后的数据集D1的维度是d1。本文利用该改进的粒子群算法在约简的数据集中搜索稀疏子空间。在d1中选择t个属性,而每个属性被划分为φ份,此时将会有φt种子空间,每一种子空间即为粒子群算法的一个候选解。粒子群算法从p个随机解开始,随后根据局部最优Pgest和全局最优Gbest对随机解的位置和速度进行迭代和更新,并且对可能的子空间进行随机搜索。每一个可能的子空间D2都有一个稀疏系数S(D2),稀疏系数S(D2)即为粒子群优化算法对应的适应度函数。迭代中Pgest和Gbest都是通过适应度函数得到的。这个过程一直持续到达到最大迭代次数为止。在算法的每一个阶段都是在追随最佳的t个属性(即具有最小的稀疏系数),在算法的最后阶段,这t个属性为数据集中与异常值最相关的特征集。粒子群搜索算法的总体过程见算法3。
算法3 用改进的粒子群算法搜索稀疏子空间
输入:约简后的数据集D1,稀疏因子阈值θ,原始数据集数据对象的总数N=||D。
输出:异常值集合O。

5 实验结果分析
为了说明SSLOD算法的有效性和异常因子阈值以及稀疏因子阈值方法的准确性,在仿真数据集上和UCI数据库真实数据集上进行了测试。
仿真数据集:用文献[26]的产生数据方法生成了3个仿真数据集。假设数据服从正态分布,首先生成均值是0,方差是1的数据集;其次向数据集额外增加0.1%的点作为异常值,加入的数据服从0到1的均匀分布;最后不断复制第一步生成的数据集扩充数据量。基本信息见表3。首先说明在算法过程中的属性初步约简的性能,表4列出了约简的数据属性和对象随着异常因子阈值τ的变化趋势。可以发现,异常因子阈值τ的增大,属性和对象个数显著减少。例如,当τ=0.005 时,仿真数据集Data1、Data2、Data3减少的属性所占比例分别是16%、17%、20.7%,减少的数据对象所占的比例分别是13.31%、18.45%、14.29%。将一个N×d高维数据集D每个属性上的数据划分为φ个离散区间,在d维属性中选择t个,那么这t维属性就可以构成φt种子空间。所以减少属性和数据对象,以减少需要搜索的子空间的个数,有利于提高算法的效率。

表3 仿真数据集信息
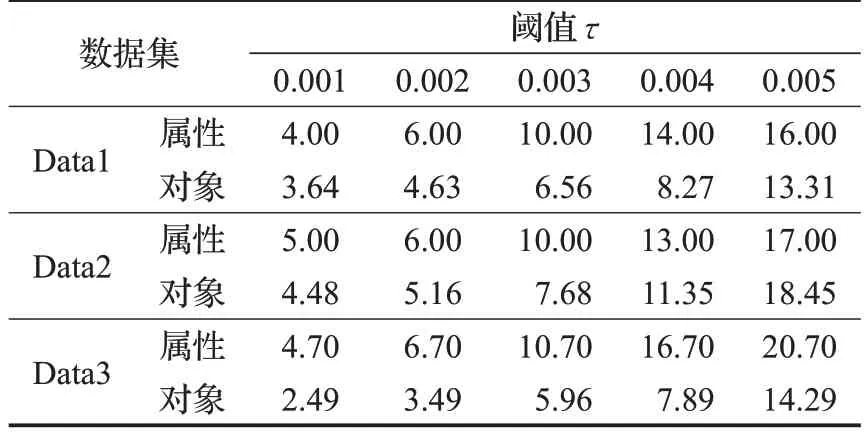
表4 约简对象及属性的比例%
分析了异常因子阈值τ和稀疏系数阈值θ对算法精度(Accuracy)的影响。为表示精度,先给出混淆矩阵,见表5。混淆矩阵一般应用在二分类中,这里将异常值认为是正类。精度[29]的计算公式如下:


表5 混淆矩阵
如图1 给出了算法精度随异常因子阈值τ变化情况,可以看出,当异常因子阈值τ逐渐增大时,算法的精度会略下降。这是因为τ越大,被减少的属性和对象就越多,使得产生的稀疏子空间可能会丢失一些有用的信息,导致算法的精度出现下降的趋势,由图2 的信息可以看出随着稀疏系数阈值θ的增大,算法的精度在渐渐地上升,但是在后期上升的速度要缓慢一些。这说明在后期算法的精度前后相差不大,这种现象可以给在实际试验中如何取θ值做一个较佳的参考。
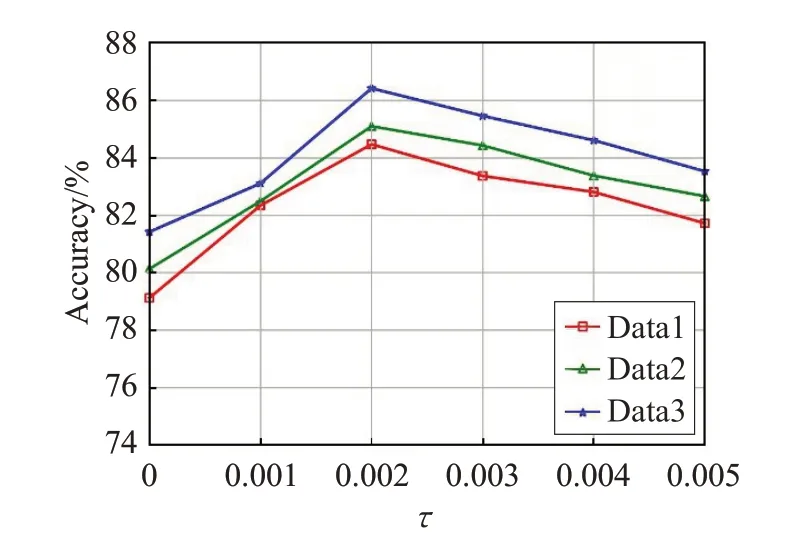
图1 异常因子阈值τ 对算法精度的影响

图2 稀疏系数阈值θ 对算法精度的影响
UCI数据集:在3个真实的数据集上实现SSLOD算法,这些数据集是高度类不平衡的,一般应用在数据分类和其他机器学习算法中,数据集中的少数类认为是异常值,多数类是正常值。另外,在实验之前还对数据进行了清洗以便处理分类属性和缺失数据。表6 给出了UCI真实数据集的基本信息。对于这3个不同的数据集均将参数φ设置为7,稀疏系数阈值θ可根据仿真数据集的分析结果选择,建议在[-1.5,-0.5]之间选择,其余参数的设定已在相关章节给出。将算法SSLOD的精度和效率与遗传算法和标准粒子群算法进行了对比。观察表7,在相同的数据集下,提出的算法SSLOD 算法的精度均高于其余两种算法,特别是对于数据集Internet Usage Data,SSLOD 的精度比遗传算法的精度提高了13.07%。由图3中可以看出,SSLOD的效率在不同的数据集上均高于其余两种算法。这是因为SSLOD算法在搜索稀疏子空间之前先用算法1和2约简了原始数据集维度和对象,然后用算法3对标准粒子群算法惯性权重随机化,对其学习因子异步化,使搜索算法不易陷入局部最优,同时又可以快速收敛到全局最优。与标准粒子群算法相比,进一步提高了算法效率。与遗传算法相比,不需要进行交叉变异等遗传操作,降低了计算复杂度,提高了算法效率。
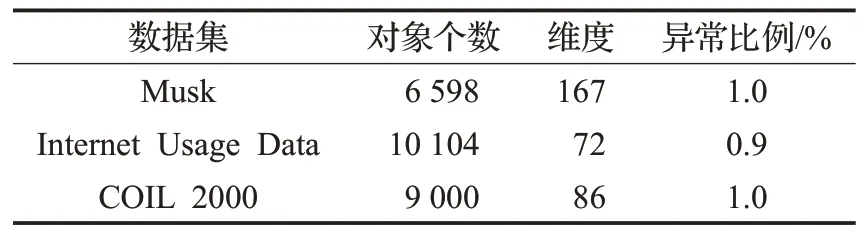
表6 UCI数据集信息

表7 3种算法精度比较%

图3 3种方法的效率比较
算法1 的复杂度主要体现在第3 步到第5 步,若采用蛮力法构造KNN 图,N个对象的计算复杂度为O(N2),而使用R*-tree索引结构可以将搜索k近邻的复杂度减少到O(N⋅lgN),第6步到第11步以及算法2复杂度均为线性阶,因此算法1 和算法2 的复杂度即为O(N⋅lgN)。算法3 的计算量主要体现在更新速度、位置和计算适应度函数。设粒子规模是p,最大迭代次数是T,约简后数据集的大小是N,待搜索的空间被划分为φ×t份。速度和位置更新的复杂度为O(T⋅p⋅2N),计算适应度函数的复杂度是O(T⋅p⋅φ⋅t)。因此,SSLOD算法总时间复杂度为O(N⋅lgN)+O(T⋅p⋅2N)+O(T⋅p⋅φ⋅t)。
6 结束语
在高维数据集中,异常数据往往在部分维度构成的子空间中能被识别,而在高维空间中表现并不异常,这使得高维空间中直接检测异常值变得困难。此外,不同的异常值可能存在于由不同属性张成的不同子空间中,因此需要搜索有利于表征异常值的子空间。本文针对上述问题,在检测异常值之前先对属性和数据对象进行约简,并用改进的粒子群搜索算法在约简后的数据集中搜索稀疏的子空间,进一步将局部异常值挖掘出来。在仿真数据集上充分分析了SSLOD 算法的有效性,并将该算法与遗传算法和标准粒子群算法在真实数据集上作比较。综合实验结果表明,本文所提出的基于稀疏子空间局部异常值算法具有良好的性能和较高的效率。
猜你喜欢
昆明医科大学学报(2022年1期)2022-02-28
四川师范大学学报(自然科学版)(2021年6期)2021-11-15
湖南税务高等专科学校学报(2021年4期)2021-08-30
中学生数理化·中考版(2020年10期)2020-11-27
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
成都信息工程大学学报(2019年2期)2019-08-28
自动化学报(2018年2期)2018-04-12
意林(2018年3期)2018-03-02
浙江工业大学学报(2017年5期)2018-01-22
