
数据库模式匹配:一种查询逆向工程方法
2020-10-15 11:00刘履宏何震瀛荆一楠
计算机应用与软件 2020年10期
刘履宏 何震瀛 荆一楠
1(复旦大学软件学院 上海 201203) 2(复旦大学计算机科学技术学院 上海 201203)
0 引 言
在大数据时代,用户对数据公开、数据共享与数据融合等的需求越来越迫切。数据库模式匹配(Database schema mapping)作为解决这些问题的一个有效手段,成为数据库领域一个重要的研究问题[1]。
数据库模式匹配通过在数据库模式之间建立映射关系,帮助用户实现从源数据模式到目标数据模式的转换。传统的模式匹配技术[2-7]将两个异构数据源作为输入,根据数据源的元信息或是数据实例对数据源的模式进行匹配。在对数据源进行匹配的过程中,使用的是基于属性相似度的方法[4-7]。在得到可能的匹配后,用户需要人为指定哪些匹配是用户真正想要的。
图1为一个整合图书数据源的例子,给定需要做模式匹配的数据源SBook和TBook(假定SBook是源数据模式,TBook是目标数据模式),用户需要将源数据模式SBook映射到目标数据模式TBook。传统的模式匹配方法通过语义学或者是统计学等方法计算SBook和TBook不同属性之间的相似度从而得到SBook和TBook之间的可能匹配,但是这些匹配仍然需要用户再次检查以确保匹配的准确性。这不仅要求用户对两个数据源都很了解,而且费时费力(真实场景可能要比给出的示例复杂得多)。
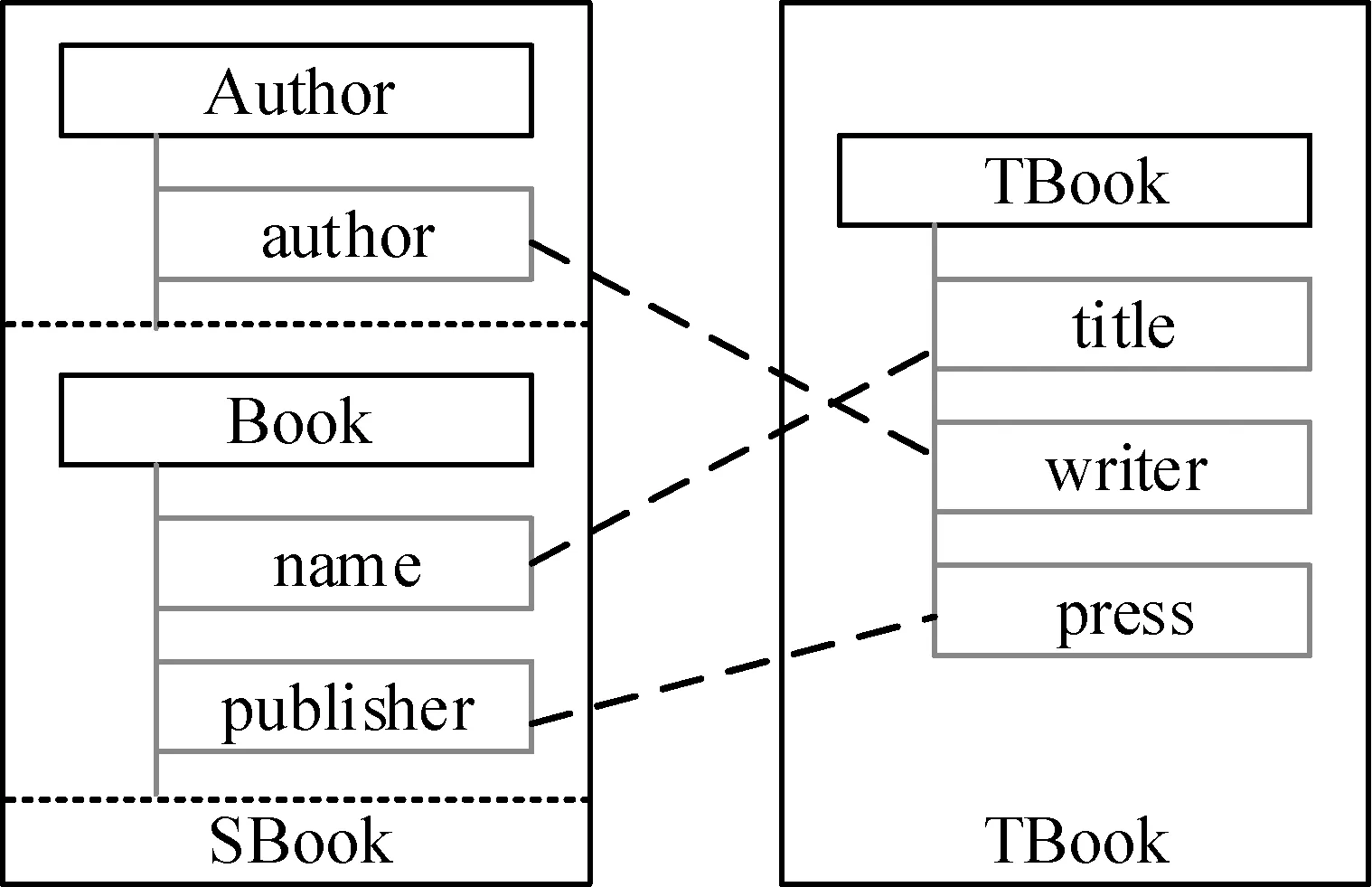
图1 示例源数据模式和目标数据模式
查询逆向工程技术为数据库模式匹配提供了新的思路。给出如图2所示的源数据库SBook,有两张表Book和Author。在Book中,a_id是其主键,其余四列依次为书籍名称name、出版社publisher、连接Author的外键f_id、评论comment;在Author中,a_id是主键,其余两列依次是作者名称author和作者国籍from。用户可根据TBook的数据模式,提供来自源数据库SBook的实例,构成实例表,如表1所示。然后通过查询逆向工程的方式得到生成这些实例的SPJ查询。在这些查询的投影(projection)列和其对应的实例表列之间构建映射关系,即可获得实例表列和SBook列之间的匹配,也就是TBook和SBook之间的模式匹配。通过查询逆向工程的方法获得的模式匹配,可以确保用户提供的每一行实例数据的内部具有逻辑一致性,即实例表中的每一行数据要么来自SBook的某一张表的同一个元组,要么来自SBook不同表的元组,而且这些元组根据SBook的主外键关系可以连接(join)。
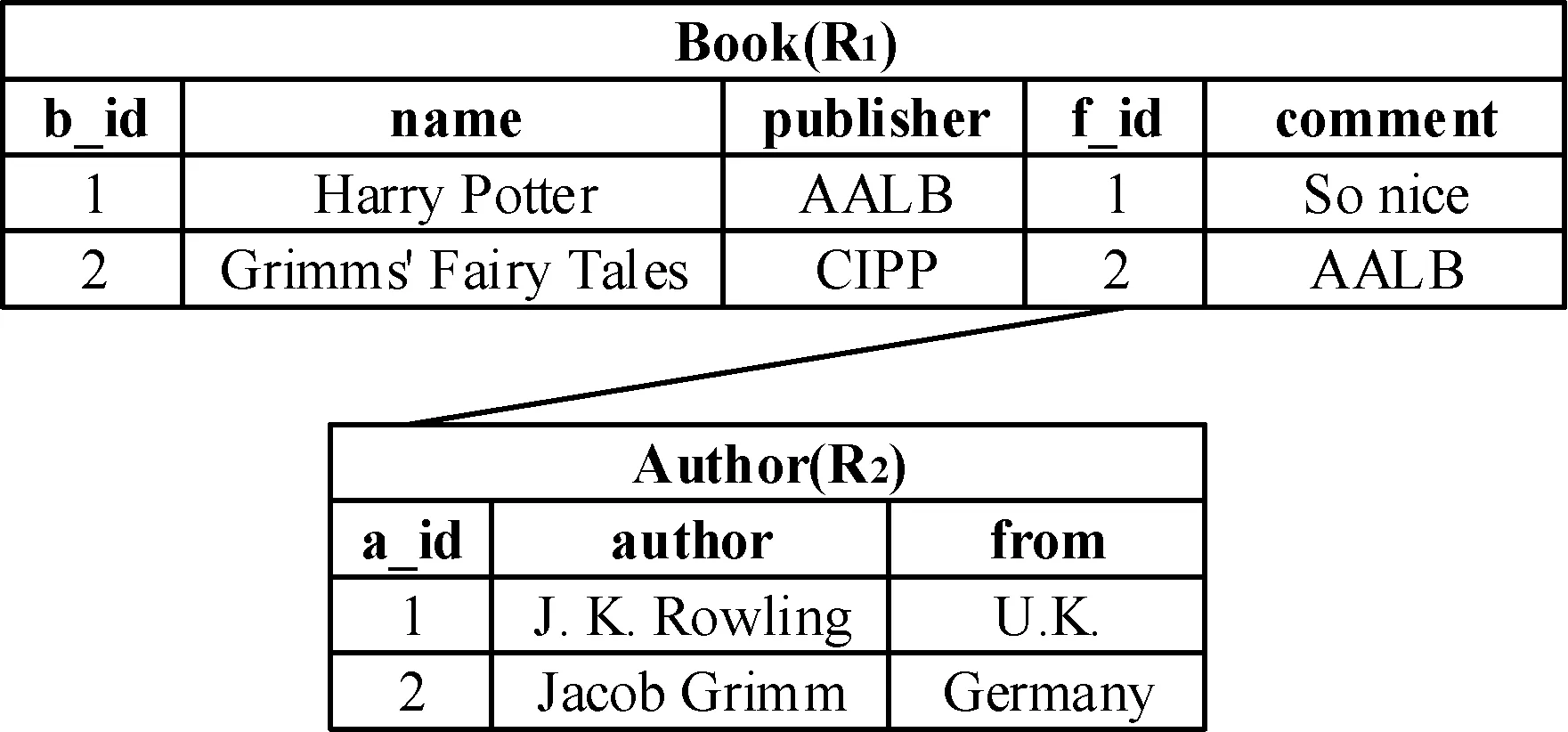
图2 源数据库SBook

表1 实例表
这种基于实例的模式匹配以实例表和源数据库为输入,可以帮助用户提供确切的模式匹配结果。用户只需要提供上述实例表和源数据库,并不需要用户对源数据库有任何了解。
查询逆向工程(Query Reverse Engineering,QRE)技术[8-10]和上文描述的基于实例的模式匹配技术相关。QRE技术根据实例表和对应数据库可以求解出从数据库得到给定实例的查询。尽管QRE技术不是直接用来解决模式匹配问题的,但是从QRE求解到的查询可以用来获得给定实例表列和数据库列之间的映射关系,从而确定源数据模式和目标数据模式之间的匹配。但使用QRE技术来求解基于实例的模式匹配问题也有不足之处。QRE中的一些过程在模式匹配问题中是不必要的,这些不必要的计算过程给模式匹配问题带来了更大的优化空间。
据此,本文提出了基于查询逆向工程的模式匹配方法。本文的主要贡献在于:(1)形式化定义了基于查询逆向工程的模式匹配问题。(2)以查询逆向工程方法为基础,提出基于行的模式匹配方法,继而提出基于重用和基于列的优化算法。基于重用的模式匹配通过对之前结果的重用实现效率的优化;基于列的模式匹配以实例表中的列为基本单元做计算,即使处理多行实例数据也能保证运行效率。(3)本文在IMDB数据集上进行了大量实验对本文提出的三种方法做了对比。实验证明了基于重用和基于列的优化方法的高效性。
1 相关研究
1.1 模式匹配
模式匹配技术[2-7]被用以匹配异构数据源的模式,确定不同数据源的属性之间的映射关系。模式匹配技术在数据整合、数据公开、数据共享、数据起源等领域起着至关重要的作用[11]。传统的模式匹配方法大体可以分为基于元数据的匹配[2,4]和基于实例的匹配[5-7]。在基于元数据的模式匹配中,算法利用数据源模式的元数据来构建源数据属性和目标数据属性之间的映射关系。基于实例的模式匹配使用统计学、文本分析或者机器学习方法计算数据源属性之间的相似性。无论是基于数据源模式元数据的方法还是基于实例的方法,本质上都是基于相似度的方法,在计算得到数据源之间的匹配之后仍需用户确认这些匹配的正确性,而且基于实例的方法忽略了用户给定实例中在同一行的数据的内部逻辑关联。QuickMig[3]虽然使用用户提供的样例来辅助构建数据源模式之间的映射,但是QuickMig和基于相似度的模式匹配方法在本质上没有区别,它并没有考虑用户构建的实例中的数据内部的逻辑关联。
1.2 查询逆向工程
本文工作和查询逆向工程(QRE)[8-10]相关。QRE在给定数据样例和数据库的情况下,找出可以生成给定数据样例的查询。然而模式匹配问题的目标是得到不同模式之间的匹配关系。尽管可以使用QRE技术逆向出生成给定数据样例的查询,再基于这些查询抽取出给定样例表列和数据库列之间的匹配关系,从而得到数据库模式匹配,但是从QRE逆向出来的不同查询可能对应着相同的模式匹配关系,不做改动地使用QRE技术做模式匹配会造成不必要的计算,增加运行成本。Shen等[9]的工作是QRE技术的一个代表,在给定样例和数据库的情况下,找出生成给定样例的SPJ查询。虽然他们已经做了查询逆向工程的执行优化,但用作模式匹配却依然有很大的优化空间。
2 问题定义
记用户给定的实例表为I,I的第j列为I·cj。对于实例表中的某一行数据ri∈I在列I·cj上的数据项,记为ri[I·cj]。
给定关系型数据库G,在其对应的模式图(Schema Graph)中,关系表可以被视为一组节点V,表与表之间的主外键关系连接为一组边E。关系表Rm中的第n列记为Rm·cn。实例表I中的实例数据由数据库G经SPJ查询得到。如果在列Rm·cn中有任何值等于ri[I·cj],则记为ri[I·cj]∈Rm·cn。例如表1中数据项r1[I·C1]Harry Potter出现在图2所示源数据库的列R1·c2(Book·name)中,即记r1[I·c1]∈R1·c2。
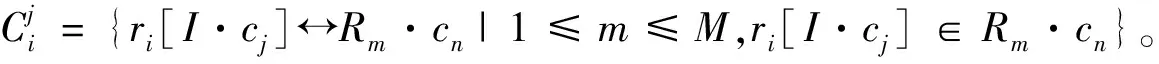
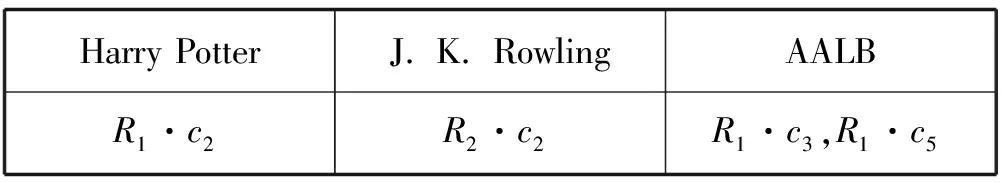
表2 实例表中的列匹配
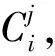
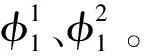

记Rm的列集合为Col(Rm),I的列集合为Col(I)。定义实例关系如下:
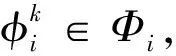
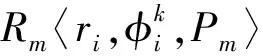
实例关系和中间关系的连接方式通过构造查询计划树来表示。实例关系和中间关系构成查询计划树中的节点。如果查询计划树的节点之间存在一条边,那么他们所对应的关系表在数据库G中一定有一条表示主外键关系的边。为了避免无效和重复,查询计划树应满足以下条件:
3)查询计划树中的叶子节点不能为中间关系Rm〈∅〉。
一个查询计划树T代表着一个查询,T中的节点表示子查询,边表示连接。执行T代表的查询,可以得到一张结果表(T)。给定一个数据行ri∈I,记其对应的一个列匹配组合所能产生的查询计划树集合为定义查询计划如下:
定义4查询计划。给定一个查询计划树T∈其对应的数据行是ri∈I,列匹配组合是则查询计划
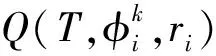
3 基于QRE方法的模式匹配及优化方法
本文提出了基于QRE方法的模式匹配方法。首先基于问题定义给出了基于行的模式匹配,对实例表的每个行求解出模式匹配集合,相交得到最终的结果集。然后在基于行的模式匹配方法的基础上,提出了基于重用的模式匹配方法,在求解下一行的模式匹配时,利用前一个行的模式匹配的结果。最后提出了同时处理多行实例数据的基于列的模式匹配方法。
3.1 基于行的模式匹配
基于问题定义,提出基于行的模式匹配方法,具体算法如算法1所示。
算法1基于行的模式匹配方法
输入:实例表I和源数据库G。
输出:模式匹配Δ。
1. For eachri∈Ido
2.Δi←∅
3. 在G中搜索ri,并且枚举列匹配组合集合Φi
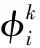
6. If ∃T∈
8. End If
9. End For
10. End For
11.Δ=∩Δi
12. ReturnΔ
基于行的模式匹配方法包含4个步骤:1)在数据库中搜索实例表中的每行数据得出相应的列匹配组合;2)对每个列匹配组合,生成查询计划树集合;3)由查询计划树得到查询计划,执行查询计划,验证列匹配组合的合法性,得到合法的模式匹配集合;4)将实例表中每行数据对应的合法模式匹配集合相交得到最终结果。
在数据库中搜索实例表中的数据项时,本文使用的是相等关系,用户可以设定自己需要的关系,比如用户若只能在实例表中提供书籍作者的姓氏,就可以使用数据库中的CONTAINS方法来处理包含关系。
算法2查询计划树生成
2. 将所有的实例关系节点初始化为候选查询计划树队列Q,初始化查询计划树结果集合
3. WhileQ≠∅ do
4.CurTree←Q.pop()
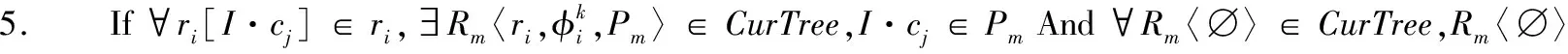
7. End If
8. For eachnode∈nodeListdo CurTree
9. For eachnode′∈CurTreedo
10. Ifnode和node′可以连接then
11. 将node连接到CurTree的node′,并且生成新的候选查询计划树CurTree′
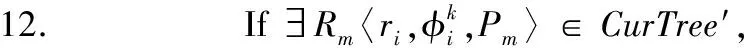
13. 丢弃CurTree′
14. Else
15.Q.add(CurTree′)
16. End If
17. End If
18. End For
19. End For
20. End While
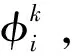
每一棵查询计划树都可以被翻译为一个具体查询。查询计划树中的边代表连接(join)方式,实例关系节点可以被转换为带有WHERE条件的子查询,中间关系节点可以被转换为没有WHERE条件的子查询。每棵查询计划树都可以进一步转换为查询计划。如果执行查询计划得到的结果表不为空,就代表着这个查询计划对应的列匹配组合是合法有效的,可以得到合法模式匹配。为了提升效率,在将查询计划转换为具体查询时,在查询后面加上“LIMIT 1”。
在验证某个列匹配组合的合法性时,一旦发现某个查询计划执行结果非空,就将该列匹配组合标记为合法,并输出模式匹配,同时停止对后续查询计划的验证。因为数据IO,在数据库上执行查询代价很大,避免执行不必要的查询可以显著提升运行效率。
3.2 基于重用的模式匹配
基于行的模式匹配方法的最后一步,是将根据实例表不同行得到的模式匹配集合相交得到最终的模式匹配结果。任何两个集合相交的结果不会超出相交前的任何一个集合。因此,在处理完一行数据之后,得到的模式匹配结果可以用作处理下一行数据时的列匹配搜索范围。假设处理完某行数据ri之后得到的模式匹配集合是Δi,对样例表中下一行数据ri+1在列I·cj上的数据项ri+1[I·cj]进行列匹配搜索时,不需要搜索整个数据库,只需要搜索Δi中I·cj在数据库中的映射列。然后依次进行查询计划树生成和查询计划验证,最终得到ri+1的模式匹配集合。处理完样例表中的所有数据行之后,将所有的模式匹配集合相交得到最终结果。
3.3 基于列的模式匹配
在基于行的方法和基于重用的方法中,随着需要处理的数据行的增加,模式匹配的整体时间成本会成倍增加。增加的时间成本主要来自查询计划树的生成和执行。为了减少查询计划树生成带来的时间成本,本文提出一种基于列的模式匹配方法,在处理不同数据行时共享查询计划树的结构而不需要针对每一行数据都进行一次查询计划树生成。
在生成共享查询计划树之前,先获得不同数据行的公共列匹配。公共列匹配定义如下:
定义5公共列匹配。给定列I·cj∈Col(I),实例表列I·cj中不同数据项ri[I·cj](∀ri∈I)在数据库G上的公共列匹配是Cj={I·cj↔Rm·cn|∀ri∈I,ri[I,·cj]∈Rm·cn}。
以表1的实例表和图2源数据库为例,列I·c1的公共列匹配C1={I·c1↔R1·c2},因为实例表列I·c1的数据都出现在源数据库的列R1·c2中。
公共列匹配组合被定义如下:
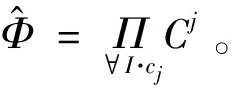
实现查询计划树共享的核心思想是采用占位符的方式来保留查询计划树结构但是不具体指定数据行,为此提出占位符实例关系。

占位符实例关系代表一个参数化的查询,需要在WHERE条件中填入具体的数据行才能实例化为具体的查询。
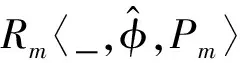
占位符查询计划树的生成过程只需将查询计划树生成过程中的实例关系节点替换为占位符实例关系节点即可。把占位符查询计划树转换成具体的查询计划时,要将数据行ri∈I组装到占位符查询计划树中的占位符实例关系,填充上WHERE条件上的参数,实例化数据行参数。
基于列的模式匹配方法始终将实例表的数据列作为一个整体,从公共列匹配组合的获取到占位符查询计划树的生成都是以列为数据单元。只有在把占位符查询计划树转换成具体查询计划时才分开处理每个数据行。这种方法避免了实例表中数据行增长所带来的数据搜索开销和查询计划树生成开销。
4 实 验
4.1 实验环境
代码基于Java 8实现。运行过程中的内存限制是8 GB。实验所用数据集为IMDB数据集,其包含大量的电影和评分数据。IMDB数据集大小为3.7 GB,共有7张表。实验中使用MySQL5.7存储数据。为了加速数据搜索的过程,本文给数据库的列建立了索引。
4.2 实验参数
查询计划树的最大大小(MaxSize)和用户给定实例表的列数量影响着本文方法的性能。在实验中对这两个参数设定不同的值。MaxSize取值3、4、5,默认大小为4;实例表列数量取值3、4、5,默认大小为4。为了研究各方法在实例表中有不同数量数据行时的表现,在不同行数量下进行了实验。实验中实例表的数据行数量取为1、5、10,默认数量为5。
实验中的实例表从IMDB数据集中随机采样生成。每一行实例数据都可以被某个查询生成。每组参数下都随机采样出15个实例表,实验结果数据取15组实验的平均值。
4.3 性能分析
(1)不同MaxSize下的性能比较。为研究查询计划树的最大大小MaxSize对本文三种方法的影响,实验比较了不同MaxSize值下不同方法的运行时间,结果如图3所示,“row”表示基于行的模式匹配,“reuse”表示基于重用的模式匹配,“column”表示基于列的模式匹配。
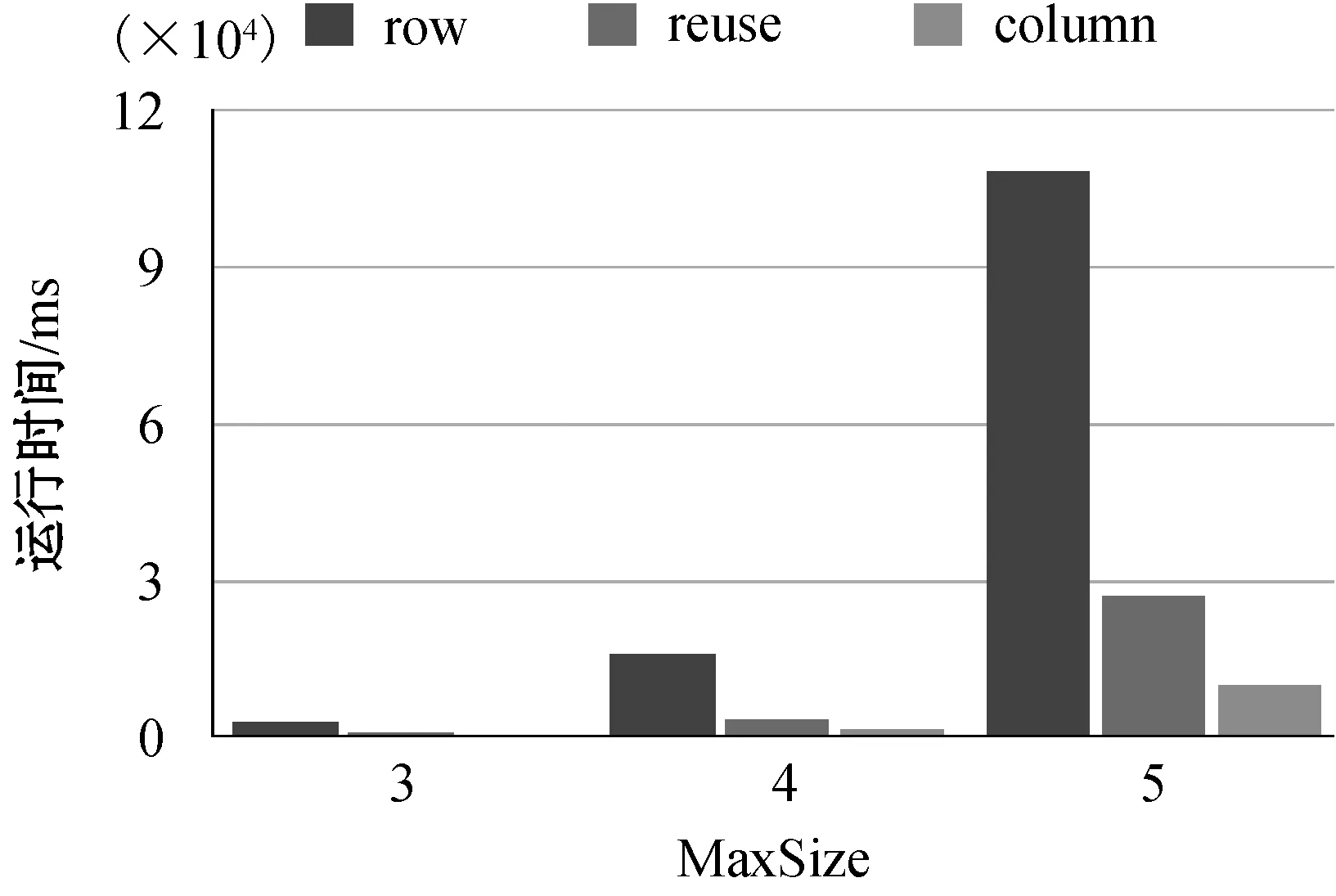
图3 不同MaxSize下的运行时间
可以看出,随着MaxSize的增大,三种方法的运行时间都会增加。查询计划树最大大小MaxSize决定了查询计划树的生成数量,MaxSize越大,生成的查询计划树越多,需要执行的查询计划也就越多,运行时间就会增加。在不同的MaxSize下,三种方法中始终是基于行的方法运行时间最长,其次是基于重用的方法,基于列的方法运行时间最短。基于行的模式匹配方式的运行时间是基于重用的模式匹配方法运行时间的3~5倍,是基于列的模式匹配方法运行时间的10倍左右。这是因为基于行的模式匹配方法对每个数据行都需要在整个数据库搜索数据、生成查询计划树并且执行查询计划。基于重用的模式匹配方法重用了前面的模式匹配结果,缩小了数据搜索的范围,但是在处理每个数据行的时候仍需要重新生成所有的查询计划树。基于列的模式匹配方法将整个实例表中的列视为一个整体,只生成一次查询计划树,降低了查询计划树生成成本。同时,公共列匹配组合的使用减少了查询计划树的生成,降低了查询计划的数量,降低了运行成本。
(2)不同列数量下的性能比较。实验通过改变实例表中的列数量来研究其对三个方法运行时间的影响,实验结果如图4所示。
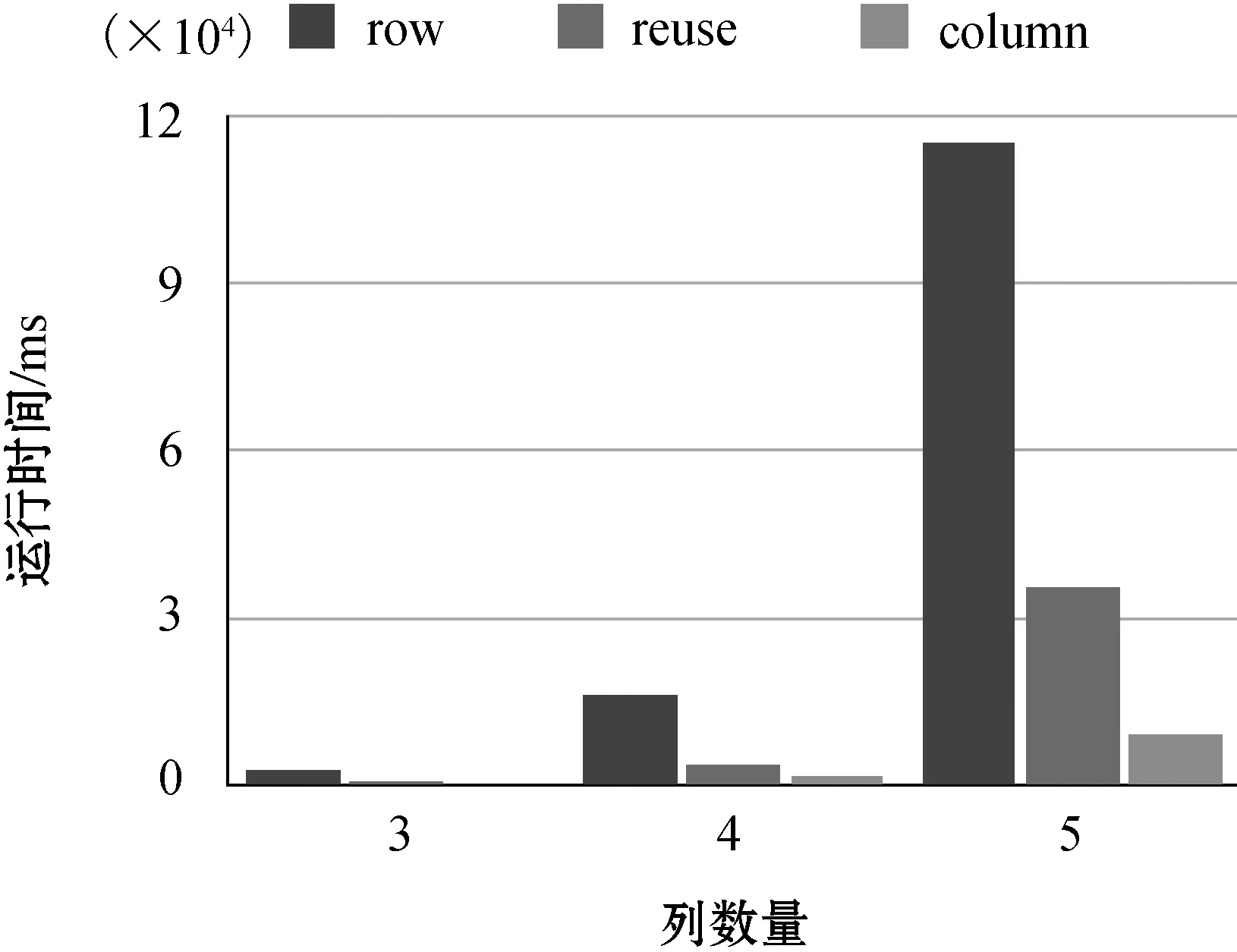
图4 不同列数量下的运行时间
可以看出,实验运行时间随着列数量的增加而增长。列数量增加之后,列匹配组合的数量会增加。此外,列匹配组合中的列增多了之后,生成查询计划树输入的实例关系节点会增加,每一个列匹配组合生成的查询计划树数量随之增长。最终需要执行的查询计划数量增多,执行时间加长。在不同的列数量下,基于行的方法、基于重用的方法和基于列的方法的执行时间依次变短。基于行的方法用时是基于重用的方法用时的3~5倍,是基于列的方法用时的6~10倍。
(3)不同行数量下的性能比较。为了比较三种方法处理不同数量数据行时的效率,在不同行数量下进行了实验,各方法运行时间如图5所示。
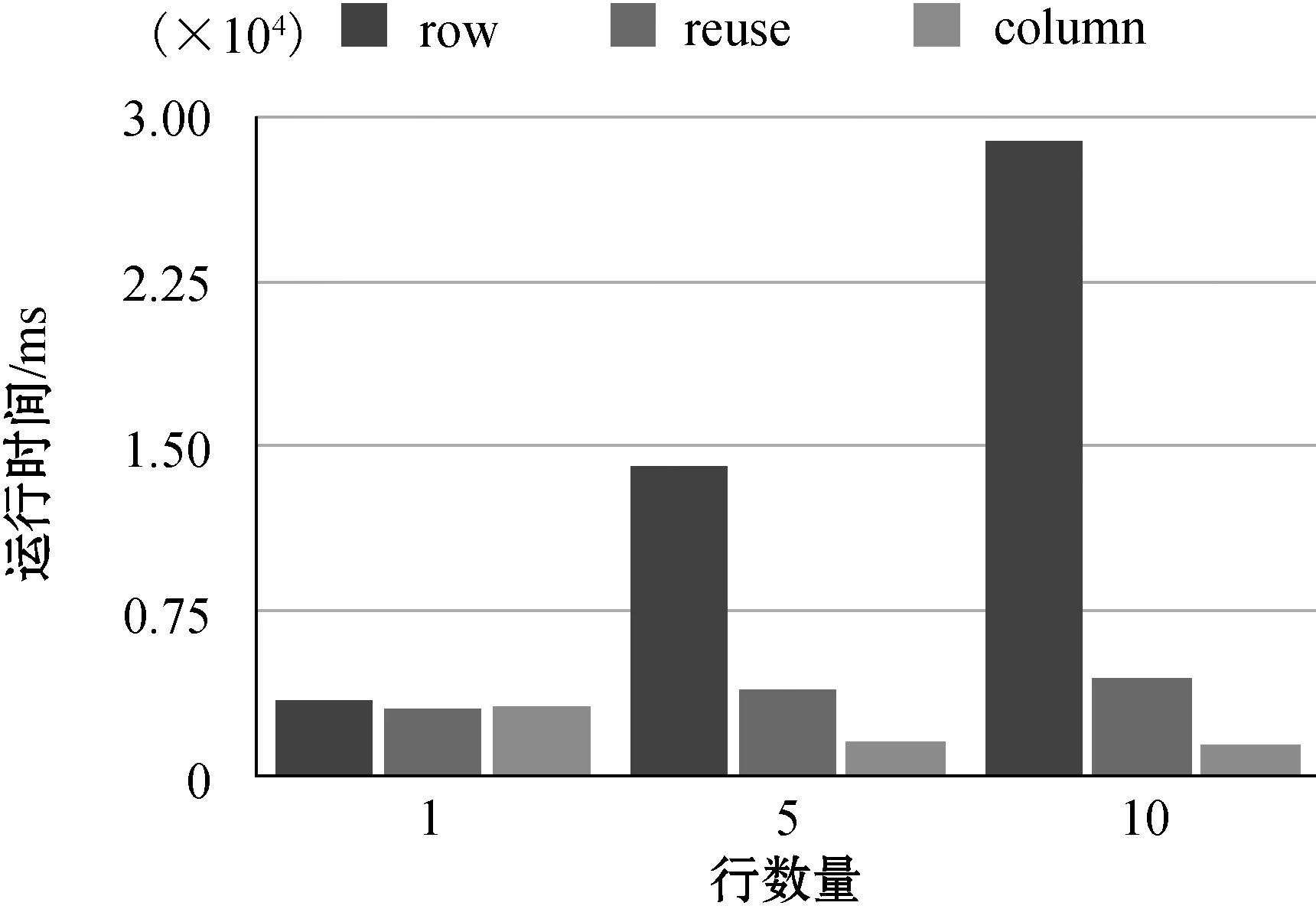
图5 不同行数量下的运行时间
当行数量为1时,三种方法所用时间基本相同,这符合文中方法设计原理。随着行数量增加,基于行的方法运行时间成倍增长,因为在此方法中对每一行数据的处理过程完全相同,所以数据行数量的成倍增加会造成运行时间的成本增长。基于重用的方法所用时间随着数据行数量的增长缓慢增长。每次数据行的数据搜索范围来自上一个数据行的模式匹配结果,这不仅会减少数据搜索时间,也会减少列匹配组合的数目,从而减少需要执行的查询数量。基于列的方法在行数量为1的时候用时为3 214 ms,在行数量为5和10的时候用时为1 500 ms左右,是行数量为1时用时的一半。在生成查询计划树之前,基于列的方法将各个数据行的列匹配相交得到公共列匹配,行数量增加时,公共列匹配会减少,则公共列匹配组合会减少,生成的查询计划树数量也随之降低。因此,随着行数量的增加,基于列的方法所用时间反而降低。
通过以上实验可得,提出的基于重用和基于列的优化方法在不同最大大小和不同列数量下都有很好的效率,基于列的模式匹配方法表现最好。相比于基于行的模式匹配方法和基于重用的模式匹配方法,基于列的模式匹配方法即使在行数量较多的情况下也有很好的表现,能够处理多行数据的情况。
5 结 语
数据库模式匹配在数据共享、数据公开等领域起着至关重要的作用。本文通过查询逆向工程的方法,根据用户提供的符合目标模式的实例数据以及源数据库,计算出源数据库生成给定实例的查询,在实例数据列和源数据库列之间建立映射关系,帮助用户自动完成数据库模式匹配,此方法不要求用户对源数据库有任何了解。依照定义提出的基于行的模式匹配方法在分别处理实例表中各数据行后取各数据行模式匹配结果的交集。基于重用的优化方法将上一行数据的模式匹配结果作为处理下一行数据的输入,减小数据搜索范围和生成的查询计划数量,提升执行效率。基于列的优化方法将整个实例表作为一个整体,以列为单位进行搜索和查询计划树的生成,实现了效率的大幅提升,能够很好地处理实例表中有多行数据的情况。实验验证了本文提出的优化方法的高效性。未来研究仍有如下问题值得思考:在很多情况下,用户提供的样例表不一定完全准确无误,如何处理这些错误数据是一个巨大的挑战。此外,在模式匹配中处理经过加工或者格式转换的数据也是一个非常值得研究的部分。
猜你喜欢
小学生学习指导(低年级)(2019年3期)2019-04-22
电脑爱好者(2018年14期)2018-08-05
初中生世界·七年级(2017年2期)2017-01-20
电脑知识与技术(2016年8期)2016-05-19
小猕猴智力画刊(2016年6期)2016-05-14
科教导刊·电子版(2016年6期)2016-04-19
电脑爱好者(2015年20期)2015-09-10
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
