
基于融合MODIS AOD 和LME 模型的京津冀地区PM2.5 季节浓度模拟
2020-10-17 01:53邵丝露孙艳玲马振兴付宏臣
天津师范大学学报(自然科学版) 2020年5期
邵丝露,孙艳玲,马振兴,陈 莉,毛 健,高 爽,张 辉,付宏臣,景 悦
(天津师范大学地理与环境科学学院,天津 300387)
经济的迅猛发展和城市化进程的加快在改善人类生活质量的同时造成了能源的大量消耗,导致环境污染日益严重,其中近年来频发的霾备受关注.PM2.5又称细颗粒物,其空气动力学直径≤2.5 μm,是霾的重要组分之一.有研究证实PM2.5不仅可以影响空气质量,还会造成光的散射和吸收,从而降低能见度[1],过度吸入会造成心、脑血管等方面的疾病,甚至威胁生命[2-3].因此,了解PM2.5浓度分布对治霾措施的选择以及心、脑血管疾病的病因分析均具有非常重要的作用.
时间序列的PM2.5浓度可由地面监测站点提供,但目前监测站点并非均匀分布,无法得到空间连续的监测值,对有限的站点数据进行空间插值又会产生较大误差.因此,利用卫星遥感(覆盖范围广、分辨率高)获取空间连续的气溶胶光学厚度(aerosol optical depth,AOD),进而反演PM2.5浓度成为国内外学者常用的方法.AOD 是气溶胶的消光系数在垂直方向的积分,可用于表征大气的浑浊程度. AOD 产品包括MODIS AOD、MISR AOD、MAIAC AOD、风云系列极轨卫星产品和环境一号卫星产品等,其中MODIS AOD 是应用最为普遍的产品之一.利用AOD 反演PM2.5浓度的方法主要为建立AOD-PM2.5关系模型,该模型经历了由简单线性回归到精度较高的土地利用回归以及地理加权回归等模型的转变. 早期研究假定AOD-PM2.5的关系是恒定不变的,而Lee 等[4]首次提出的线性混合效应模型则解释了其随时间变化的情况,研究模拟所得美国东北部PM2.5浓度的可决系数R2为0.97,极大地提高了拟合精度,证明该模型对AOD-PM2.5具有较高的拟合能力. 随后Xie 等[5]、Ma 等[6-7]、Zheng 等[8]和Yang 等[9]分别利用改进的线性混合效应模型模拟中国不同地区的PM2.5浓度(R2=0.71 ~0.85),均得到较高的拟合精度.
MODIS AOD 产品包括Terra 卫星的MOD04_L2和MOD04_3K 产品以及Aqua 卫星的MYD04_L2 和MYD04_3K 产品共四类.每一类AOD 产品由于云层、冰雪覆盖等原因都会或多或少出现缺失,而数据量的不足会影响PM2.5浓度的模拟.因此,对多种产品进行融合,即使用多星融合数据可以相互弥补缺失数据,提高模拟准确度.Zheng 等[8]将MOD04_L2 和MYD04_L2两类数据建立线性回归来预测缺失的AOD,反演得到精度较高的京津冀、长江三角洲和珠江三角洲的PM2.5浓度(R2=0.77 ~0.80).计羽西等[10]利用融合4 种气溶胶产品所得AOD 日均值对湖北省PM2.5浓度进行模拟,同样得到较好的拟合结果(R2=0.85 ~0.89).
京津冀是霾较为严重的地区,现有研究大多通过地理加权回归模型[11-12]和土地利用回归模型等[13-14]模拟该地区PM2.5浓度,均获得较好的拟合结果. 近些年,有研究将线性混合效应模型应用于京津冀地区的分析,郝静等[15]和景悦等[16]均利用该模型模拟了京津冀地区PM2.5浓度,但由于采用单颗星AOD,数据缺失较多,研究仅能分冷暖两季进行.本文同样以京津冀为研究区域,对MODIS AOD 的四类产品进行融合,增加了AOD 的覆盖范围,使得数据量可以按季节展开研究.因此,本研究基于融合的AOD 数据和PM2.5站点观测数据,按季节分别建立线性混合效应模型并估算PM2.5浓度、模拟不同季节PM2.5浓度的空间分布,以期为PM2.5浓度分布相关研究提供新的数据处理思路,也为流行病学的病源追溯研究提供更加全面的数据基础.
1 数据来源与方法
1.1 研究区域概况
京津冀包括北京市、天津市以及河北省的保定、唐山、廊坊、石家庄、邯郸、秦皇岛、张家口、承德、沧州、邢台和衡水等11 个地级市,是我国重要的工业中心之一,也是政治中心和文化中心.该地区属暖温带大陆性季风气候,冬季盛行西北风,夏季盛行东南风,四季分明,夏季炎热多雨,冬季寒冷少雪,春多风沙,秋高气爽.地势由西北向东南倾斜,西北部为坝上高原、山地和丘陵,东南部为广阔平原,该地区的季风气候和地形皆不利于大气污染物的扩散,导致大气污染严重.
1.2 数据来源与处理
1.2.1 MODIS AOD 数据
用于融合的原始AOD 是由美国地球观测系统(EOS)中Terra 和Aqua 卫星搭载的中分辨率成像光谱仪(MODIS)提供的产品,该产品与大气颗粒物浓度有较好的相关性且对外免费. 上午轨道卫星Terra 过境时间约为地方时10 ∶30,下午轨道卫星Aqua 过境时间约为地方时13 ∶30,二者在时间上互补. MODIS AOD 产品包括10 km 和3 km 空间分辨率,分别由深蓝算法和暗像元算法反演得到,深蓝算法对城市和沙漠等明亮地区反演效果较好,暗像元算法在植被浓密区反演效果较好,二者融合可以弥补云层和冰雪等覆盖造成的数据缺失.
本研究采用从NASA 网站(https://ladsweb.modaps.eosdis.nasa.gov/search/)下载的C6.1 版本2016 年1 月1日—2016 年12 月31 日的MOD04_L2、MOD04_3K、MYD04_L2 和MYD04_3K 四类数据.首先利用ENVI5.3对其进行预处理,包括几何校正和拼接,然后对拼接后的数据进行融合.较高的空间分辨率有助于提高反演结果的质量[14],因此将空间分辨率为10 km 的MOD04_L2 和MYD04_L2 的数据分别重采样为3 km 分辨率的数据,并对重采样后的数据建立线性回归来填补缺失,而后对填补后的两类数据取均值得到融合后的3 km AOD(深蓝算法).MOD04_3 K 和MYD04_3K 同样建立线性回归填补缺失并取均值得到融合后的3 km AOD(暗像元算法).最后基于重采样后分辨率为3 km的土地覆盖类型数据为不同土地覆盖类型匹配相应的融合AOD 数据,得到空间分辨率为3 km 的优化后的日均AOD,用于PM2.5浓度的反演.
1.2.2 PM2.5数据
PM2.5监测数据来源于中国环境监测总站,时间分辨率为1 h.由于融合AOD 为日均值,PM2.5数据也由每小时值计算得到日均值,即2016 年1 月1 日—2016 年12 月31 日日均PM2.5数据.京津冀地区监测站点分布如图1 所示.由图1 可以看出,京津冀共有国家空气质量监测站点80 个,其中北京市12 个,天津市15 个,河北省53 个,分别位于保定、沧州、承德、邯郸、衡水、廊坊、秦皇岛、石家庄、唐山、邢台和张家口.

图1 京津冀地区国家空气质量监测点分布示意图Fig.1 Distribution diagram of national air quality monitoring points in Beijing-Tianjin-Hebei region
1.3 模型拟合与验证
1.3.1 线性混合效应模型
AOD 与PM2.5的关系受相对湿度、温度、边界层高度和地形等因素的影响,其中相对湿度、温度和边界层高度等皆逐日变化,因此AOD 与PM2.5的关系也呈现逐日变化的特点,而简单的模型只能解释AOD-PM2.5间的固定效应,无法表示逐日随机效应.已有研究表明线性混合效应模型可以较好地阐释这种逐日变化的随机效应[4-10],因此本研究选择利用线性混合效应模型模拟京津冀地区的PM2.5浓度,模型表达式为
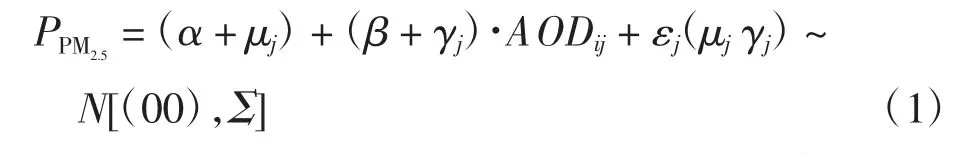
式(1)中:PPM2.5和AODij分别为监测站点i 在第j 天的颗粒物浓度和AOD 值;α 和β 分别为固定截距和固定斜率,其中β 代表AOD 对PM2.5浓度的固定影响,且不随时间发生变化;μj和γj分别为随机截距和随机斜率,其中γj代表第j 天AOD 对PM2.5浓度的随机影响,反映了时间上的差异;εj为第j 天的随机残差;Σ 为逐日变化的随机效应对应的方差-协方差矩阵.此模型的建立基于R 语言完成.
1.3.2 模型验证
为检验模型拟合是否存在过度拟合,采用留一交叉验证方法进行检验.在AOD-PM2.5匹配数据对构成的样本集中选取每一个样本轮流作为测试集,其余全部样本作为训练集训练模型,用测试集检验模型,不断重复训练模型、检验模型的过程,直至所有样本均做过一次测试集,最终取所有交叉验证结果的均值作为模型拟合的评价结果.
线性混合效应模型的拟合准确度通过PM2.5监测值与预测值间的可决系数R2和均方根误差(RMSE)来判断,其中

式(2)中:yi为第i 天PM2.5浓度的监测值为第i 天PM2.5浓度的预测值;n 为样本数.
2 结果与分析
2.1 描述性统计
融合AOD 数据与PM2.5匹配过程中,剔除当天数据对少于2 对的数据,AOD-PM2.5数据最终全年可匹配天数共317 d,春夏秋冬各79 d、76 d、80 d 和82 d.与使用单颗星的AOD 数据相比[16],融合AOD 与PM2.5的可匹配天数和样本量明显增多,尤其是AOD 数据严重缺乏的冬季.单颗星的AOD 数据由于缺失较多,建立模型时时间序列只能具体到冷暖季,而融合后的AOD 弥补了大量缺失的数据,因此本研究具有充足的样本量,可以将所有数据分为四季,分别建立线性混合效应模型模拟不同季节PM2.5浓度分布.
AOD-PM2.5匹配数据的描述性统计结果如表1 所示.由表1 可知,2016 年PM2.5浓度变化范围在3.000 ~688.690 μg/m3,年均值约为67.188 μg/m3,超过年均浓度一级标准,但未超过二级标准.四季AOD-PM2.5样本量均在2000 对以上,可以建立线性混合效应模型.PM2.5浓度均值冬季最高,为89.131 μg/m3,秋季次之,夏季最低,为42.287 μg/m3,此季节差异可能与冬季集中供暖有关.融合AOD 年均值约为0.241,全年AOD的数值变化范围为0.002~3.232.四季均值春季最高,为0.232,秋冬次之,夏季最低,为0.189.

表1 AOD-PM2.5 匹配数据的描述性统计Tab.1 Descriptive statistical of AOD-PM2.5 matching data
匹配京津冀地区日均PM2.5浓度和日均AOD,结果如图2 所示. 由图2 可以看出,日均AOD 与日均PM2.5浓度的变化趋势基本一致,尤其是夏季.PM2.5浓度有237 d 超过日均浓度的一级标准(35 μg/m3),108 d超过日均浓度的二级标准(75 μg/m3),说明2016 年京津冀地区PM2.5浓度严重超标,霾污染问题严峻.

图2 京津冀地区的日均PM2.5 和日均AOD 变化曲线图Fig.2 Daily average change graph of PM2.5 and AOD of Beijing-Tianjin-Hebei region
2.2 模型拟合与验证结果
本研究基于融合AOD 数据和PM2.5数据分别建立一元线性回归模型和线性混合效应(LME)模型,二者所得结果如表2 所示,2 种模型固定截距和固定斜率皆有统计学意义(p <0.0001).

表2 不同模型拟合结果Tab.2 Fitting results of different models
通过运行R 语言程序,得到PM2.5浓度各季节线性混合效应模型每日的随机斜率和随机截距.PM2.5浓度春季线性混合效应模型的随机斜率和随机截距变化范围分别为-171.074 ~532.461 和-49.054 ~94.474,标准差分别为103.658 和26.234;夏季的随机斜率和随机截距变化范围分别为-199.674 ~82.032 和-39.368 ~42.330,标准差分别为57.052 和21.903;秋季的随机斜率和随机截距变化范围分别为-246.985 ~444.934 和-68.509~150.466,标准差分别为134.600 和35.511;冬季的随机斜率和随机截距变化范围分别为-576.406 ~1151.724 和-66.886 ~458.905,标准差分别为302.570和73.309.由表2 可知,四季一元线性回归模型拟合的R2分别为0.105、0.127、0.198 和0.108,而线性混合效应模型拟合的R2分别为0.738、0.668、0.644 和0.760.对于简单一元线性回归模型而言,PM2.5浓度较低的季节的拟合效果优于PM2.5浓度较高的季节的拟合效果,而线性混合效应模型对PM2.5浓度较高的季节拟合效果显著.总体上,线性混合效应模型对AOD 和PM2.5浓度的拟合效果明显优于简单一元线性回归模型.
为判断模型是否存在过度拟合,采用留一交叉验证进行检验,结果如图3 所示,其中图3(a)、图3(c)、图3(e)和图3(g)分别为春夏秋冬四季的PM2.5浓度实测值和线性混合效应模型预测值的散点图,图3(b)、图3(d)、图3(f)和图3(h)分别为四季的留一交叉验证结果.对比图3 结果可知,各季节验证后的散点图较验证前更为分散,表明各季节的模型均存在过度拟合.
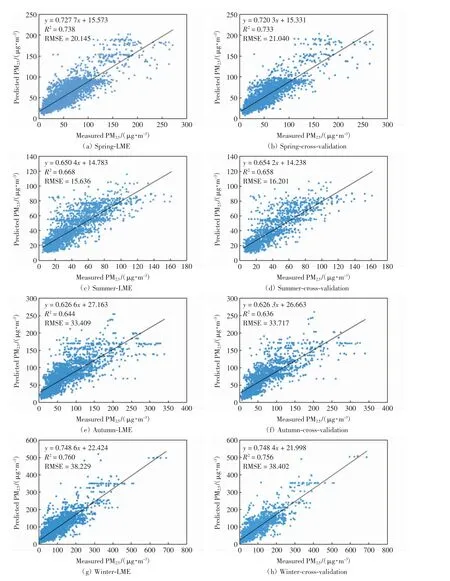
图3 四季线性混合效应模型结果和留一交叉验证结果Fig.3 Results of seasons linear mixed effect model and leave-one-out cross-validation
由图3 可以看出,进行留一交叉验证后,R2均有所下降,而RMSE 均有所上升,说明模型仅存在轻微过度拟合.春季和冬季R2的拟合效果较好,RMSE 冬季最高,这可能与冬季PM2.5浓度过高以及AOD 数据的融合有关.与其他应用该模型的多变量研究相比,本研究只使用单一变量,即融合后的AOD,拟合结果与他人研究[5-9](R2=0.71 ~0.85)比较接近,且过拟合程度较低,说明使用高分辨率的融合AOD 数据比增加变量更容易提高模型性能.
对于京津冀整体而言,基于监测站点实测所得PM2.5四季平均浓度分别为57.197、42.287、72.745 和89.131 μg/m3,线性混合效应模型预测所得PM2.5四季平均浓度分别为57.277、42.487、72.740 和88.952 μg/m3.季节平均浓度实测值与预测值非常接近,说明模型比较适用于京津冀地区的颗粒物浓度模拟.
京津冀地区共有13 个城市,各城市不同季节PM2.5的实际浓度平均值和预测浓度平均值如图4 所示.
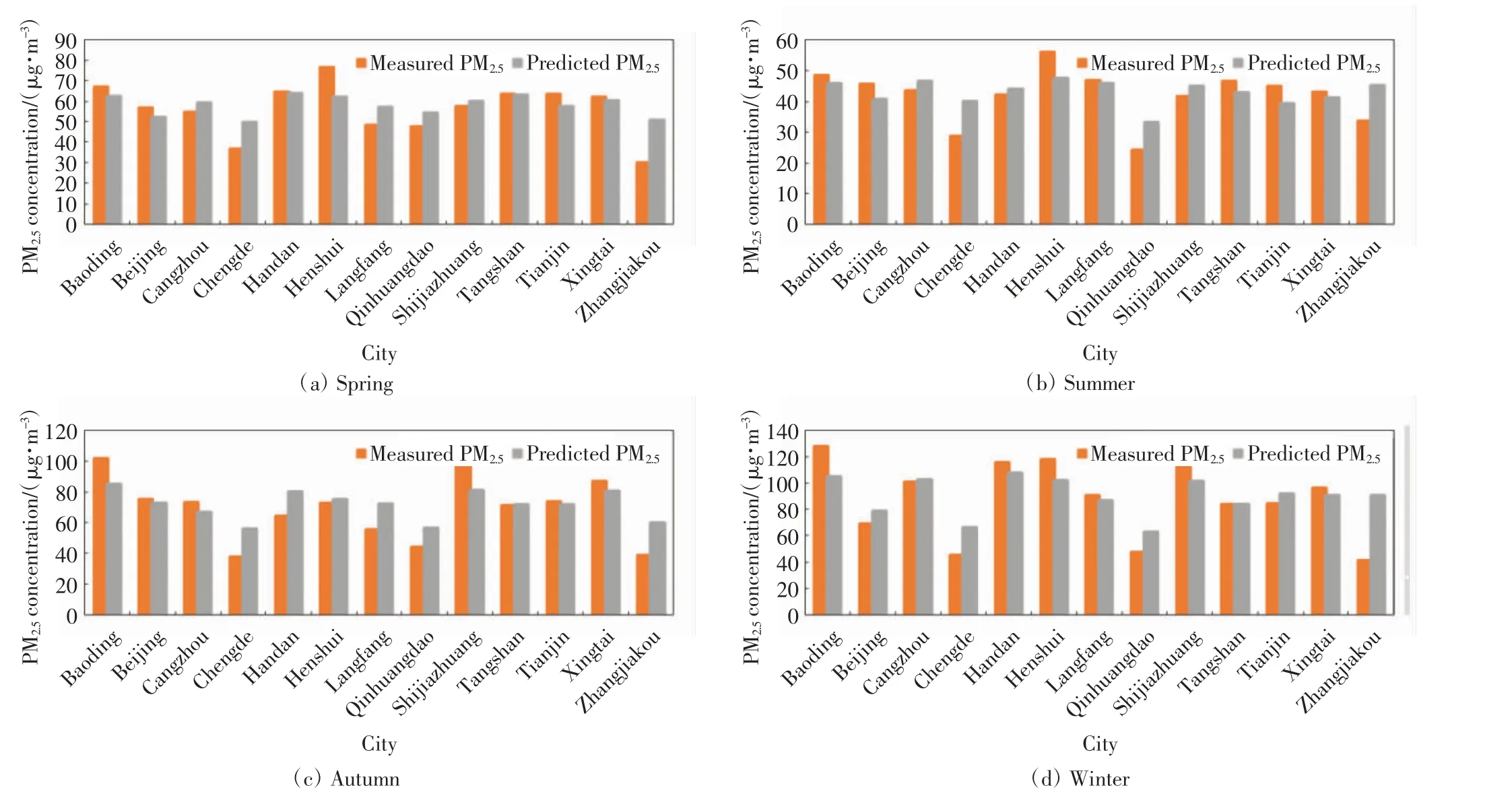
图4 不同季节各城市的PM2.5 平均监测浓度和平均模拟浓度Fig.4 PM2.5 average monitored concentration and average simulated concentration of each city in different seasons
由图4 可以看出,大多城市实测值与预测值比较接近,证明模型拟合较好.各季节实际浓度平均值最低的城市包括张家口市、承德市和秦皇岛市,这些城市人口密度小,工业占总产业比重较低,以旅游业为主,PM2.5排放量较低;此外,这些城市植被覆盖度较高、对PM2.5的吸附作用强也是原因之一.衡水市、保定市和石家庄市各季节实际浓度平均值较高,与人口密度大、工业企业数量多、尤其是高能耗企业和污染企业较多等因素有关,上述因素均导致PM2.5排放量较高.春夏季承德市、衡水市和张家口市实测值与预测值差异显著,秋冬季保定市、承德市、石家庄市和张家口市实际值与预测值差异显著,导致该现象的原因一方面是以上城市均为PM2.5实际浓度最低或最高的城市,而过低或过高的颗粒物浓度在一定程度上会降低线性混合效应模型拟合的准确度;另一方面,以上城市均为城市面积较大而环境监测站点数量较少的城市,通过有限的站点数据模拟区域浓度误差较大.
各城市不同季节PM2.5浓度的拟合结果如表3 所示.

表3 不同季节各城市PM2.5 拟合结果对比Tab.3 Comparison of PM2.5 fitting results of different cities in different seasons
由表3 可知,各城市春季PM2.5实测值与线性混合效应模型预测值的R2为0.406 ~0.903,春季RMSE 为14.817 ~30.097 μg/m3,平均值分别为0.718 μg/m3和20.294 μg/m3;夏季R2为0.397~0.825,RMSE 为11.666~21.334μg/m3,平均值分别为0.666μg/m3和15.290μg/m3;秋季R2为0.394~0.819,RMSE 为21.569~36.071 μg/m3,平均值分别为0.677 μg/m3和29.256 μg/m3;冬季R2为0.433~0.875,RMSE 为27.484 μg/m3~57.922 μg/m3,平均值分别为0.720 μg/m3和39.389 μg/m3.总体上,各城市均为春季和冬季的拟合效果较好,说明线性混合效应模型应用于PM2.5浓度模拟时,在浓度较高的季节表现更优. 由于监测站点数量相对较多、建模数据缺失较少以及大气污染略重等原因,廊坊市、北京市和天津市在模拟不同季节PM2.5浓度时结果均较为理想.除张家口市以外,其余城市不同季节PM2.5浓度拟合的R2均大于0.5,大部分城市拟合效果比较理想.由于冬季AOD 数据通过融合方式补充较多,故各城市冬季RMSE 较高,绝大部分城市RMSE 在30 μg/m3以上.
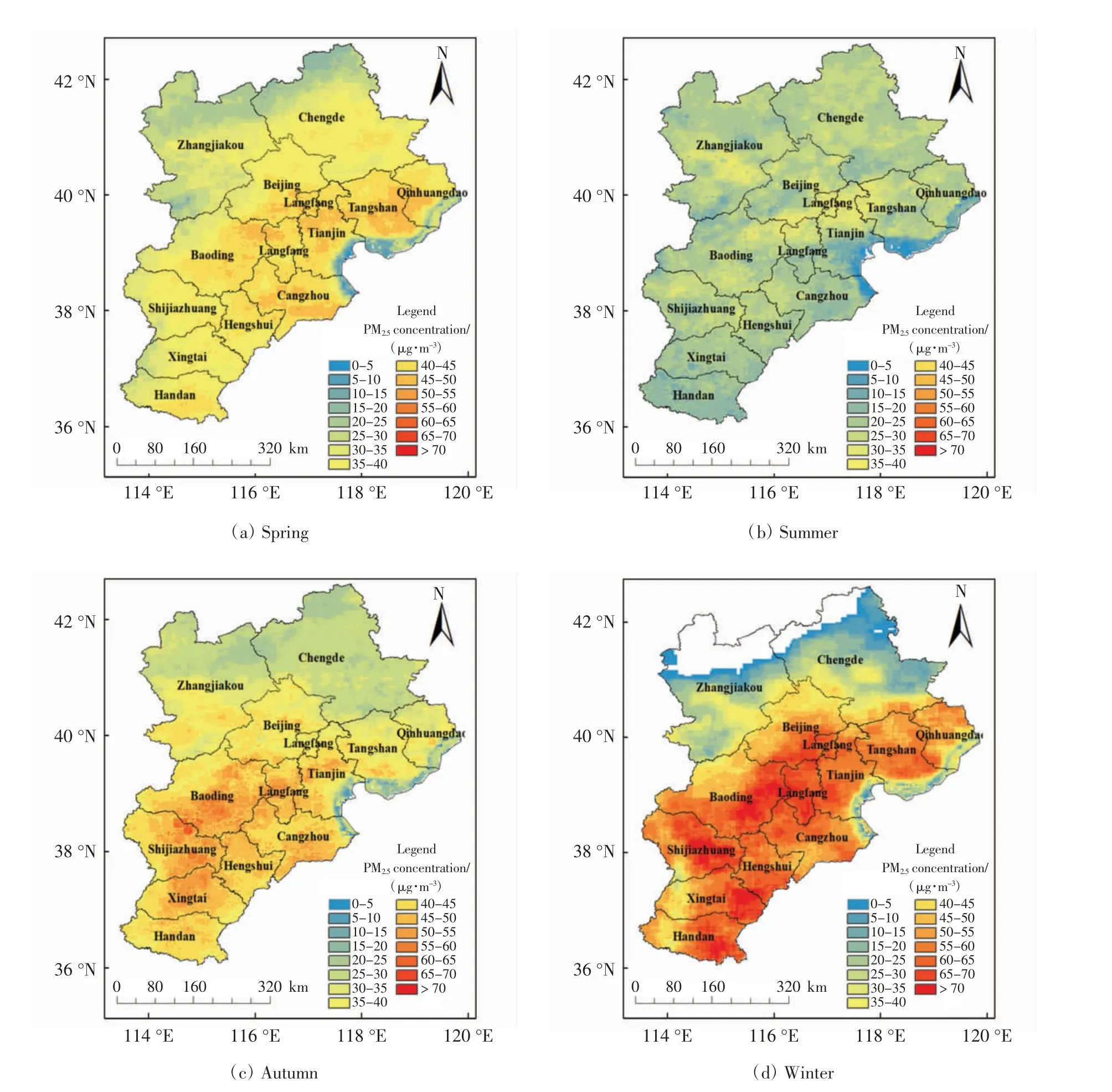
图5 2016 年京津冀地区PM2.5 季节浓度模拟Fig.5 Seasonal concentration simulation of PM2.5 of Beijing-Tianjin-Hebei region in 2016
2.3 PM2.5 季节浓度分布模拟
基于线性混合效应模型得到各个季节京津冀地区的逐日PM2.5浓度分布,利用ArcGIS10.2 对各季节的逐日PM2.5浓度分别进行加和平均,得到京津冀地区PM2.5各季节平均浓度分布如图5 所示,图5(d)中,由于冬季受冰雪覆盖影响,北部山区一些地区数据缺失.
由图5 可以看出,PM2.5季节浓度总体上冬季最高,春秋次之,夏季最低.春季PM2.5浓度高值区主要集中在京津冀中部和南部,邯郸、唐山以及保定东南部PM2.5浓度较高,分别为63.922、62.969 和62.397 μg/m3;承德和张家口PM2.5浓度较低,分别为49.794 μg/m3和50.735 μg/m3.夏季受以东南风为主的夏季风影响,颗粒物向西北扩散,加之供暖期已过,污染物排放量减少,故PM2.5浓度明显下降且各城市差异较小,衡水、保定和廊坊PM2.5浓度较高,分别为47.336、45.821 和45.795 μg/m3;秦皇岛和天津PM2.5浓度较低,分别为33.117 μg/m3和39.305 μg/m3. 秋季各城市PM2.5浓度普遍上升,高值集中在京津冀中南部地区,保定、石家庄和邢台PM2.5浓度较高,分别为84.988、80.600 和80.367 μg/m3;承德和秦皇岛PM2.5浓度较低,分别为55.675 μg/m3和56.282 μg/m3.冬季进入供暖期,污染物排放量增多,PM2.5浓度进一步提高,受冬季西北季风的影响,颗粒物集中分布于东南部城市,西北部城市PM2.5浓度显著下降,邯郸、保定、沧州、衡水和石家庄一带PM2.5浓度较高,分别为107.096、104.656、101.908、101.667 和101.055 μg/m3;秦皇岛和承德PM2.5浓度较低,分别为62.633 μg/m3和65.765 μg/m3.图4 和图5均表明京津冀地区的PM2.5浓度存在明显的季节差异以及地区差异.本文对京津冀地区PM2.5浓度分布的模拟结果与孟晓艳等[17]、温佳薇等[18]对该区域PM2.5浓度变化特征的研究结果相近,说明本研究所得PM2.5浓度分布的模拟结果合理.
此外,由图5 还可知,四季PM2.5浓度均为北部低、南部高.太行山和燕山的阻挡使南部的PM2.5难以向北扩散,且张家口和承德两市以旅游业为主,污染物排放少,因此张家口市和承德市大部分区域PM2.5浓度较低,这一现象与图4 所得结果相吻合. 渤海沿岸PM2.5浓度也较低,这一方面是由于沿海风力较大,有利于沿海地区的污染物扩散;另一方面沿海气象条件复杂,所用数据和模型应用于沿海地区可能存在误差. PM2.5浓度较高的地区主要为石家庄、保定、廊坊和唐山等城市,这些城市均以第二产业为主,污染物排放量较高.同时,私家车保有量逐年增加、冬季大量燃煤供暖、建筑扬尘以及二次颗粒物等都是导致PM2.5浓度高居不下的原因.
3 讨论
基于融合AOD 数据,本文利用线性混合效应模型模拟的京津冀地区2016 年PM2.5季节平均浓度的结果(各季节交叉验证的R2分别为0.733、0.658、0.633、0.756)与其他使用同种模型的国内研究[6-10,15-16,19-20]结果相近,但低于Lee 等[4]的研究结果,这可能是因为本研究没有对数据进行筛选处理以及研究区域PM2.5浓度过高、AOD 数据融合产生误差等原因所致.与应用广义相加模型、BP 神经网络、结合MODIS AOD 的LUR 时空模型等模型或方法的研究[11,14,21-23]相比,本研究所得结果与较高级统计模型结果相近,但仍低于一些应用改进的高级模型的研究[12,24],如混合时空地理加权回归模型和地理加权回归空间降尺度方法等.虽然使用改进的融合AOD 数据提高了模拟精度,但本研究只使用AOD 一个变量模拟PM2.5浓度,而应用高级模型的研究基本都使用土地利用、气象因素、人口密度和道路等多变量进行模拟,结果证明应用较多变量在一定程度上可以提高模型拟合精度,这也是本研究今后的改进方向之一.此外,也可以考虑对AOD 数据进行湿度订正和垂直订正,以降低数据给模型带来的误差,从而获得更优的研究结果.
4 结论
本研究对AOD 四种产品的数据进行融合,基于线性混合效应模型对京津冀地区全年4 个季节分别建立模型,估算并模拟PM2.5浓度的分布情况,得到以下结论:
(1)京津冀地区PM2.5浓度春季交叉验证后R2为0.733,RMSE 为21.040 μg/m3;夏季R2为0.658,RMSE 为16.201μg/m3;秋季R2为0.633,RMSE 为33.717μg/m3;冬季R2为0.756,RMSE 为38.402 μg/m3.和验证前相比,各季节的模型仅存在轻微过度拟合,且拟合结果较为理想.
(2)除承德、衡水、张家口和石家庄外,各城市四季实际值与预测值接近,且各城市均为春冬季的拟合效果较好,这表明线性混合效应模型应用于PM2.5浓度模拟时,在浓度较高的季节表现更优.
(3)PM2.5四季浓度的分布情况大致为北部低、南部高,其中张家口市和承德市PM2.5浓度较低,而石家庄、保定、廊坊和唐山等城市PM2.5浓度较高;季节浓度总体上冬季最高,春秋次之,夏季最低.以上结果说明在气候、地形、经济和人口等多种因素的综合影响下,京津冀地区的PM2.5浓度存在季节差异和地区差异.
猜你喜欢
中等数学(2021年9期)2021-11-22
中学生数理化·高一版(2021年2期)2021-03-19
快乐作文(1.2年级)(2019年3期)2019-09-10
英语文摘(2019年5期)2019-07-13
幼儿画刊(2018年10期)2018-10-27
卷宗(2018年14期)2018-06-29
领导决策信息(2018年7期)2018-05-22
民生周刊(2017年19期)2017-10-25
小雪花·成长指南(2016年2期)2016-03-16
