
基于BERT模型的司法文书实体识别方法
2020-10-19 10:12闻英友马林涛
东北大学学报(自然科学版) 2020年10期
陈 剑, 何 涛, 闻英友, 马林涛
(东北大学 计算机科学与工程学院/东软研究院, 辽宁 沈阳 110169)
命名实体识别(named entity recognition,NER)问题是中文自然语言处理研究的一个重要领域,对于实体信息抽取[1]、关系抽取[2]、句法分析[3]、文本翻译[4]、知识图谱[5]构建等很多应用起到基础性作用.由于中文语言本身结构的特殊性,字词之间没有分隔符,实体描述方式多种多样,加大了中文命名实体识别的难度.
命名实体识别技术早期使用基于词典和规则的方法,根据词语的分布和语义规则进行计算打分,但需要人工完成复杂的特征建模.随着语料资源的丰富,基于统计学的机器学习算法广泛用于命名实体识别问题,典型应用包括隐马尔科夫模型[6]、最大熵模型[7]、条件随机场[8]、支持向量机[9]等.近年来,随着计算能力的提高及深度学习的发展,卷积神经网络、循环神经网络等方法被广泛地应用在实体识别领域.
Feng等[10]提出在嵌入词向量特征的基础上利用长短时记忆网络模型进行命名实体识别.Dong等[11]提出利用双向长短时记忆网络模型与条件随机场进行命名实体识别.Ma 等[12]提出结合双向长短期记忆模型、卷积神经网络和条件随机场,解决序列标注问题.Strubell等[13]在2017年提出迭代膨胀卷积神经网络(iterated dilated convolutional neural networks,IDCNN)来处理序列问题,IDCNN计算出每个词分类的概率,而条件随机场(conditional random field,CRF)层引入序列的转移概率.Vaswani等[14]提出基于多头自注意力机制的Transformer模型,提高了文本特征提取能力,为序列标注任务提出新的解决方法.Zhang等[15]提出了一种新型的Lattice LSTM(long short-term memory),将潜在的词语信息融合到基于字模型的传统LSTM+CRF中去,而其中潜在的词语信息是通过外部词典获得的.Yang等[16]提出了一种利用众包标注数据学习对抗网络模型的方法,构建中文实体识别系统.2018年10月底,Google公布BERT(bidirectional encoder representation from transformers)[17]在11项NLP任务中刷新纪录,BERT的成功引起业界的广泛关注.
司法文书命名实体识别是司法业务信息化和智能化的基础任务,是知识图谱构建、案情辅助研判、类案检索、法律法规推荐等上层功能的前提工作.目前司法文书命名实体识别的研究并不成熟,也没有公开的司法领域命名实体标注数据集,因此,开发司法实体标注工具和根据实际需求标注数据集也是本文需要完成的工作.
司法文书不同于普通文本,通常包含大量的人名,如被告人、受害人、证人、代理人等多种类型,并常常使用代称;专业术语较多,通常会出现法律法规条文;还要关注多义词问题,如“盗窃车钥匙一把”和“一把夺过行人的背包”,两个“一把”含义不同,归入的实体类型也不同.
为了解决上述问题,本文引入BERT模型,该模型是一个强大的预训练模型,通过双向训练Transformer编码器从海量的无标注语料中学习短语信息特征、语言学特征和一定程度的语义信息特征.BERT可以将丰富的语言学知识进行迁移学习,在规模较小的司法文书标注语料库上进行微调,同时其强大的词向量表征能力能够有效区分多义词在不同上下文中的含义.
本文提出一种融合BERT的多层次司法文书实体识别模型,实验结果表明,该模型与目前主流的实体识别模型BiLSTM(bi-directional LSTM)+CRF相比,F1分数可提高7.5%左右.
1 构建BERT+BiLSTM+CRF模型
BERT+BiLSTM+CRF模型的整体结构见图1.三层结构分别是:①BERT使用Transformer机制对输入数据进行编码,使用预训练模型获取字的语义表示;②BiLSTM在BERT输出结果的基础上进一步提取数据的高层特征;③CRF对BiLSTM层的输出结果进行状态转移约束.
1.1 BERT预训练模型
BERT预训练模型与其他词向量预训练模型如ELMO[18],GPT等不同,该模型是在多层Transformer编码器的基础上实现的.Transformer编码器作为文本特征提取器,很多研究证明其特征提取能力远远大于RNN和CNN模型,这也是BERT模型的核心优势所在.
Transformer是由Vaswani等[14]提出的一个完全依赖自注意力机制计算输入和输出的表示,而不使用序列对齐的递归神经网络或卷积神经网络的转换模型.自注意力的计算方法如下:从编码器的每个输入向量中创建三个向量:一个Query向量、一个Key向量和一个Value向量.这些向量是通过将词嵌入向量与三个训练后的矩阵Wq,Wk,Wv相乘得到的,维度默认为64.为了便于计算,将三个向量分别合并成矩阵,得到自注意力层的计算公式:
(1)
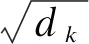
在Transformer的基础上,BERT使用Masked LM进行无监督预训练.一个深度双向模型要比单向的“左-右”模型或浅层融合“左-右”和“右-左”模型更高效.为了解决双向训练中每个词在多次上下文可以间接看见自己的问题,BERT采用随机遮掩一定百分比的输入token,然后通过预测被遮掩的token进行训练.
BERT的输入数据是基于字符级Embedding的线性序列,每个序列的第一个token是一个特殊的分类识符号,记作“[CLS]”,序列之间使用分隔符“[SEP]”分割.每个字符有三个Embedding:①Token Embedding,即每一个输入字符的Embedding;②Segment Embedding, BERT是一个句子级别的语言模型,这个标记对应一个句子的唯一向量表示;③Position Embedding,在自然语言处理任务中,序列的索引信息很重要.与Transformer不同,BERT并没有采用三角函数来表达句子中词语位置的方法,而是直接设置句子的固定长度去训练Position Embedding,在每个词的位置随机初始化词向量.最终把单词对应的三个Embedding叠加,形成BERT的输入,如图2所示.
1.2 BiLSTM层
由于在深度神经网络中使用反向传播算法,即根据损失函数计算的误差通过梯度反向传播的方式,指导深度网络权值的更新优化,随着网络深度的增加,常常出现梯度消失和梯度爆炸问题[19].LSTM在RNN的基础上进行改进,通过使用复杂的门机制解决了梯度消失/爆炸问题,加快训练收敛速度,并能很好地检测出序列中的长距离依赖.一个基本的LSTM单元结构如图3所示.图中:h(t)存储短期状态信息,c(t)存储长期状态信息.c(t-1)进入时间迭代t的神经元时,首先经过一个忘记门限,丢掉一些记忆,再通过输入门限有选择地增加一些新记忆,c(t)作为长期状态被传入下一个时间迭代t+1的神经元.同时,长期状态被复制并传入tanh函数,然后结果被输出门限过滤,产生短期状态h(t):
(2)
(3)
(4)
(5)
c(t)=f(t)⊗c(t-1)+i(t)⊗g(t),
(6)
y(t)=h(t)=o(t)⊗tanh(c(t)).
(7)
式中:Wxi,Wxf,Wxo,Wxg为每一层连接到输入向量x(t)的权重矩阵;Whi,Whf,Who,Whg为每一层连接到前一个短期状态h(t-1)的权重矩阵;bi,bf,bo,bg是每一层的偏差系数.
在处理序列标注问题时,神经网络模型不仅要关注上文信息,同样也要关注下文信息,将前向LSTM和后向LSTM结合起来,使得每一个训练序列向前和向后分别是两个循环神经网络,而且这两个网络连接着同一个输出层,这便是BiLSTM的优点,能够提供给输出层输入序列中每一个元素完整的上下文信息.
1.3 CRF层
CRF是一种判别式概率图模型,在序列标注任务中通常使用线性链条件随机场.设随机变量序列x为观测序列,y为状态向量(标记序列),每一个(yi,xi)对为一个线性链上的最大团,并满足:
P(yi|x,y1,y2,…,yn)=P(yi|x,yi-1,yi+1).
(8)
给定一条观测序列x,使用CRF求解状态序列y的建模公式为
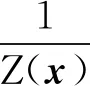
(9)
因为状态序列与前后Token之间存在限定关系,并与观测序列存在依赖关系,所以引入两类特征函数,转移特征函数集t和状态特征函数集s,建模公式可扩展为
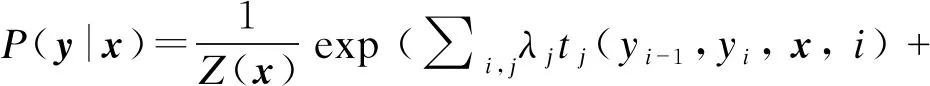
(10)
Z(x)=∑yexp(∑i,jλjtj(yi-1,yi,x,i)+∑i,lμlsl(yi,x,i)).
(11)
式中:Z(x)用来归一化;tj表示转移状态函数,对应权重为λj;sl为状态特征函数,对应权重为μl;k和l为特征函数的个数.
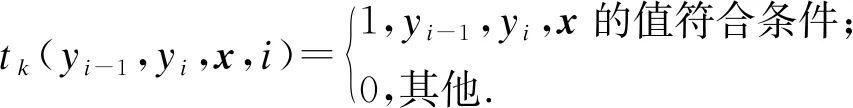
(12)
CRF是全局范围内统计归一化的条件状态转移概率矩阵,让底层深度神经网络在CRF的特征限定下,依照新的损失函数,学习出一套更合理的非线性变换空间.
2 实验结果分析
2.1 语料库收集与标注
本文所使用的标注语料库均是自主完成创建,所用语料均来自中国裁判文书网公开的裁判文书,搜集到的文书总数量达到10万份.司法文书实体提取问题,不同于传统的NER是对人名、地名、组织机构名等7类特定实体的识别,案件要素提取需要自己定义复杂的实体标签集,针对不同的犯罪类型,标签集包含的内容也各不相同.以盗窃罪为例,需要定义的实体有:公诉机关、被告人、犯罪时间、犯罪地点、作案工具、盗窃方式、盗窃物品、被盗物品价值、盗窃金额、销赃处置、销赃金额、抓获时间、赃物追回、认罪态度、谅解情况等共15类实体.
标注语料库的质量对训练深度学习模型的性能起到决定性作用,本实验从语料库中选取盗窃类型且内容较为详实的2 900份文书进行标注,所有的标注工作均由经过专业培训的人员手工标注完成.尽管不排除主观因素对实体标注边界的影响,但总体而言标注质量较高,非常适合用于模型的训练.
对于标注完成的语料,使用包含信息量更丰富的BIOES[20]标注体系转化为可供模型使用的数据集,即一个字符对应一个标签.B表示一个实体的开始, I表示实体内部, O表示不是标注的实体, E表示实体的结束, S表示这个字本身就是一个单独的实体.显然,标签之间存在顺序关系,比如在B之后不会出现O和S标签,在I之后只能出现I和E标签.CRF可以约束标签之间的依赖关系.
从数据集中随机抽取三部分作为训练集、验证集、测试集,三者的文书数量比例约为4∶1∶1.样本分布数据如表1所示.
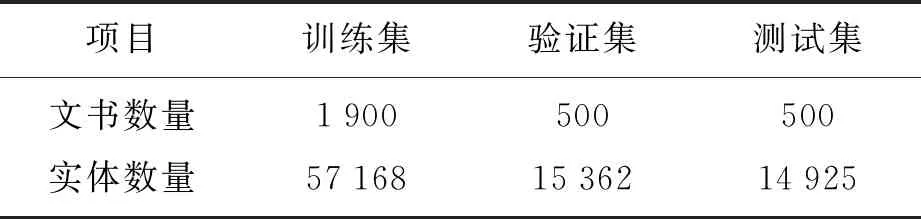
表1 盗窃案实体样本分布
2.2 结果对比
在机器学习中评估模型的性能通常使用精度P、召回率R,F1分数三个指标:
P=TP/(TP+FP),
(13)
R=TP/(TP+FN),
(14)
F1=2×P×R/(P+R).
(15)
式中:TP表示真正类的数量;FP表示假正类的数量;FN表示假负类的数量;F1分数是精度P和召回率R的谐波平均值,只有当召回率和精度都很高时,才能获得较高的F1分数.
在验证集上各实体的F1分数随迭代次数而发生变化的情况如表2所示.
设置训练过程的epoch最大值为100,在每个epoch运行完以后,通过在验证集上综合全部实体识别的得分来获取性能最优的模型.训练完成后,使用该模型在测试集上获得各类实例的性能指标,其指标分布如表3所示.
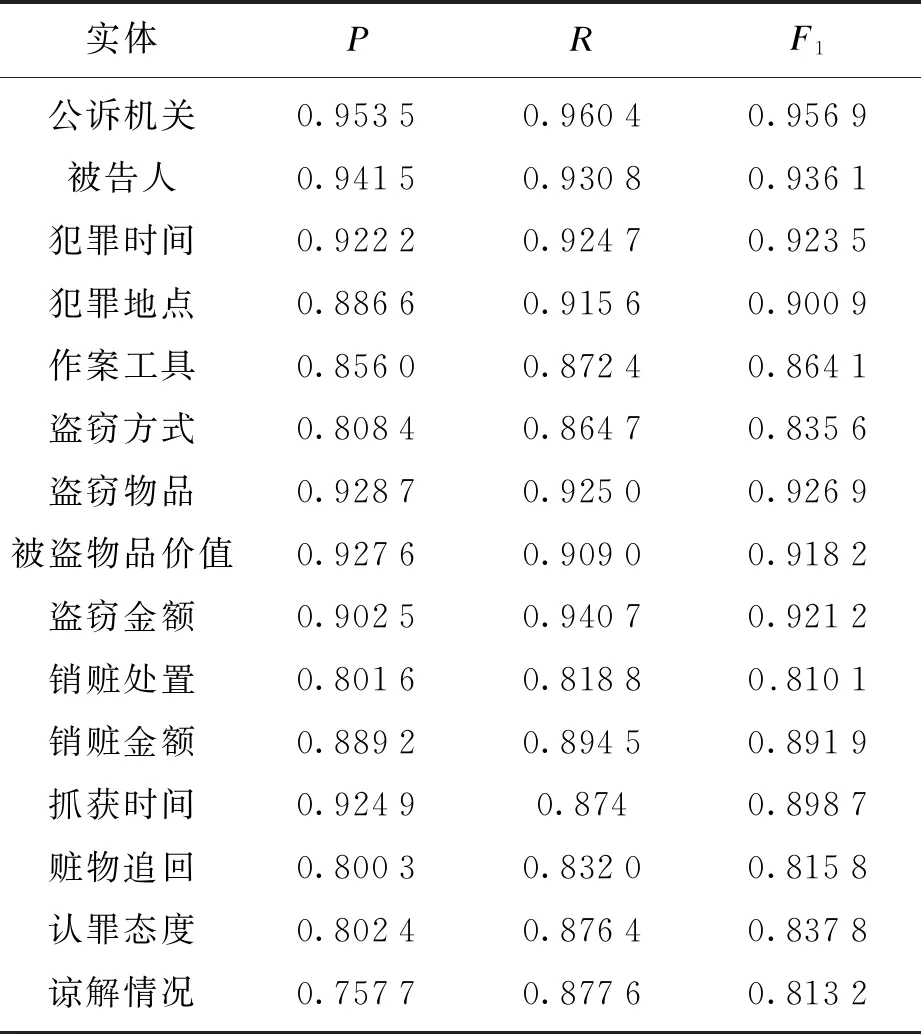
表3 15类实体的识别效果
该模型在各个实体类型上的得分会有较大的差异,比如“盗窃方式”的F1分数只有0.835 6,其原因是该类型实体在概念上不够明确,盗窃方式的描述多种多样,很难确定每种盗窃方式的边界,在标注的时候不像“盗窃时间”有明确的边界,导致在标注的过程中受到较大的主观因素和标注习惯影响;而“销赃处置”的F1分数较低是因为该类实体数量较少,模型学习得不够充分.
为了证明本文提出的模型在性能方面的优越性,在相同数据集上,与以下模型进行比较:
1) IDCNN+CRF模型:迭代扩张卷积神经网络通过融合空洞卷积方法,实现序列化特征的卷积提取与上下文特征传递.
2) BiLSTM+CRF模型:序列标注问题使用主流模型,使用BiLSTM获取文本特征并输出各个标签取值的概率,CRF对标签间的顺序关系做约束.
3) BERT+CRF模型:通过每个字符左边和右边的上下文信息,BERT层可以学到句子中每个字符最可能对应的实体标注是什么,CRF可以调整违反标注规则的结果,降低错误率.
本文将命名实体识别领域广泛使用的三个模型与BERT+BiLSTM+CRF模型的性能指标进行统计对比,各模型性能如表4所示.
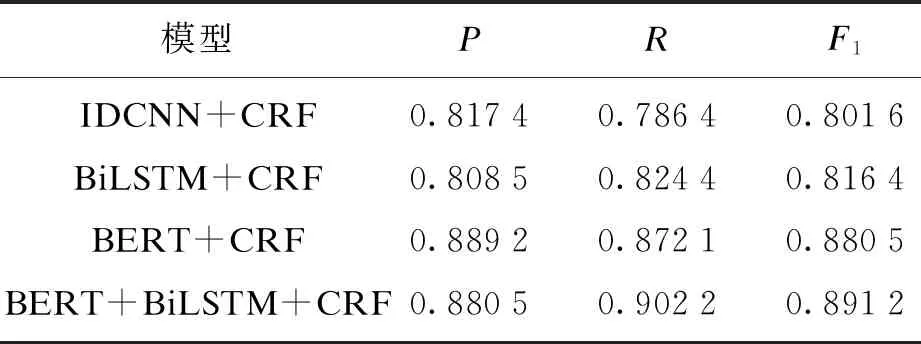
表4 4种模型结果对比
从统计数据可以看出,前三个模型的F1分数分别达到了0.801 6,0.816 4,0.880 5,相差并不明显.本文提出的模型F1分数达到了0.891 2,比目前广泛应用的BiLSTM+CRF提高7.5%,从另一个角度来看,实体识别的错误率下降40%,性能有了显著提升.BERT+BiLSTM+CRF模型比BERT+CRF模型的F1分数高出1.07%,两者的结果非常接近,这也说明BERT的特征提取能力非常强大,在计算资源有限的情况下,BERT+CRF应用于实体识别也是一种很好的选择.
3 结 论
1) 为解决检察业务标注语料规模较小、案件文本实体提取困难的问题,提出一种将BERT, BiLSTM与CRF相结合,进行案件实体提取的方法.该方法利用BERT预训练学习的语义句法知识,在标注的数据集上进行微调,再利用BiLSTM的序列建模能力和CRF的状态转移约束功能进一步优化.实验表明,该方法优于目前几种主流的实体识别模型,在性能上得到大幅提升.
2) 下一步的任务是如何将该模型应用到检察案件文本的智能标注上及如何在云平台上提供高效可信的文本标注服务和实体提取服务.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
艺术品鉴(2020年6期)2020-08-11
西夏研究(2020年1期)2020-04-01
中国外汇(2019年18期)2019-11-25
当代陕西(2019年5期)2019-03-21
小天使·一年级语数英综合(2018年6期)2018-06-22
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
高中生学习·高三版(2016年9期)2016-05-14
