
GARCH模型和随机森林模型预测能力对比
——以恒生指数为例
2020-10-24 10:44林锋权
福建质量管理 2020年19期
林锋权
(福建师范大学经济学院 福建 福州 350000)
一、ARCH族模型简介
金融时间序列的波动率会随着时间变化,这在实证金融中已经是广为熟悉和被接受的典型事实。但是,波动率的不可预测性使得度量和预测它成为一件难度非常大的任务。通常,以下三种经验观察推动了波动率模型的演变。
1.波动性聚集:它指的是金融市场上,大波动往往跟着大波动;小波动往往也跟着小波动。两者的界限和明显。
2.资产收益率的非正态性:实证分析显示,相对于正态分布,资产收益率分布趋向于厚尾性。
3.杠杆效应:这会导致一种现象,波动率对正价格变动或负价格变动的反应往往不同。价格下降时波动率的增大幅度大于相似规模的价格上涨带来的波动率的变动。
正是有了实证的观察,推动了无数的学者对金融时间序列的异方差性进行详细的实证研究,也使得一系列估计波动率的模型得以推出,其中就包括了著名的ARCH模型。ARCH模型(Autoregressive conditional heteroskedasticity model)全称“自回归条件异方差模型”,解决了传统的计量经济学对时间序列变量的第二个假设(方差恒定)所引起的问题。这个模型是获得2003年诺贝尔经济学奖的计量经济学成果之一。
ARCH模型的介绍:
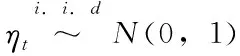
(1.1)
其中α0>0,αi≥0,i>0,即各期收益以非负数线性组合,常数项为正数。
GARCH模型的介绍:
如果方差用ARMA模型来表示,则ARCH模型的变形为GARCH模型(波勒斯勒(Bollerslev),1986年)
二、GARCH模型建模
(一)样本数据异方差性的检验
本次作业的样本数据选自恒生指数收盘价的月度对数收益率,时间从2000.01.01至2020.05.01。在做具体的建模过程之前,首先要做的就是对该时间序列数据进行简单又直观的观察。波动率的分析始于观察自相关以及偏相关函数,因此先计算出该序列以及平方后序列的ACF、PACF进行观察。结果如下图所示:
从图1可知,对数收益率的平方值出现了显著的自相关性。这意味着对数收益率不相关,也不独立。
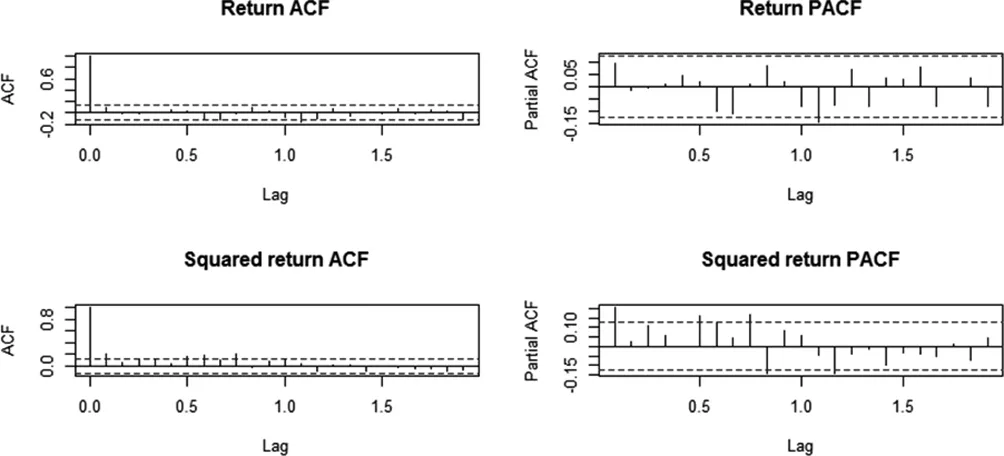
图1
(二)使用GACRH模型进行建模
GARCH模型可以用如下的公式表示
εt=σtηt
(3.2)
(3.3)
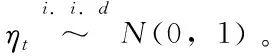
在实证研究中,GARCH(1,1)模型常常为数据提供了合适的拟合。它很好的捕捉到了波动的自回归特性(波动聚集性)和资产收益率分布的尖峰效应。而且GARCH模型中出现波动聚集符合经验观察的结果。模型中的ηt正且大的冲击会增大εt的值,进而会增加σt的值,并导致更大的εt并且冲击是会持续的。这就可以解释波动率的聚集效应。
在训练模型之前,为了验证模型的有效性以及与后面的随机森林模型进行横向对比。因此将样本数据划分成两大部分:训练集数据以及测试机数据。由于样本数据是从2000.01.-2020.03,因此将2000.1-2019.05作为训练集,共计232个样本;2019.06-2020.03共计9个样本。下面使用GARCH模型对序列数据进行拟合:在R中GARCH程序包包含了各种形式的数据分布假设,由于本文假设数据是服从正态分布的。故采用GARCH(1,1)-N模型进行模型参数的估计。
(三)GARCH模型的测试
上文中将原始数据划分成两部分:训练集(2000.1-2019.06),测试集(2019.06-2020.03)。在建立完GARCH(1,1)模型后,需要用测试集数据对其估计的结果进行检测。具体做法是:首先用模型进行估计,再计算出测试集数据的均值和标准差,最后,进行横向对比。下面给出具体的结果:
从表1,可以看出:虽然模型预测不可避免的会带来误差,但是GARCH模型仍然较好地拟合了测试集数据。其模型的预测能力明显优于ARIMA模型。但是其与机器学习的模型预测能力孰优孰劣,还要看下文的对比。

表1
三、使用随机森林算法进行建模
(一)模型概述
随机森林是基于决策树的组合模型。若因变量为连续变量则建立非线性回归分析模型,若因变量为分类变量则建立分类判别模型。随机森林在分类中返回得票数最多的分类选项,而在回归中返回所有决策树输出的平均值。它与bagging非常类似,也是Beriman(2001)发明的。随机森林是从原始数据提取有一定数量的自助法样本。对每一个样本都建立一棵决策树,其中每个节点都是随机选择竞争变量的,不需要人工选择竞争变量;随机森林的每棵树都不需要剪枝,让其充分的生长。最终预测结果是对所有决策树结果的加权平均。而且随机森林的这种随机选择少数自变量来竞争节点拆分变量的做法使得一些弱势变量也有机会参加建模,因此可能会揭示一些尚未被人们发现的数据规律。同时随机森林也可以计算OOB交叉验证误差,来从不同角度验证自变量的重要性。随机森林还能够处理所谓的“维数咀咒”问题,并能处理自变量具有高阶交互作用以及自变量相关的问题。
(二)模型变量的选择
本次实验选择的因变量依旧是恒生指数,自变量选择了恒生指数滞后一阶、上证指数(SSEC)、日经225指数(N225)、道琼斯工业指数(DJI)以及标普500指数(SNP)。之所以选择这些变量的原因在于,在全球金融市场背景下,不同区域市场之间存在很强的联动性,但是区域市场也会有自己的独特的个性。
(三)模型拟合
采用R语言中的randomForest函数包进行拟合。下面展示变量的重要性:
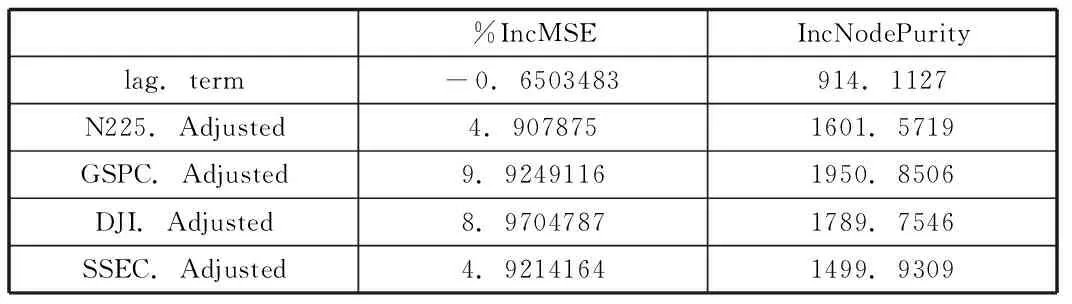
表2
从上表可以看出,对于恒生指数而言,自变量中标普500、道琼斯指数,以及上证指数对其影响较大,其滞后一阶的指数反而对其影响不大。这说明,香港的股票市场主要受到发达国家尤其是美国股市的影响,其次影响较大的是中国的股票市场。
从当前国内国外的金融局势来看,美国依旧是世界的金融中心,它的一举一动的确会对全球其他金融市场的股市产生比较大的影响。随着国内在香港上市的公司不断增加,国内股票市场也或大或小的影响着香港的股票市场。
根据误差的结果可以看到,随着随机森林决策树数目的增多,误差(MSE)会不断降低;同时随着解释变量的增多,误差(MSE)也在降低。但是如果用太多的决策树或者变量反而会出现过学习的结果。因此在此案例中,选择100棵决策树,且选择四个解释变量为最佳的方案。
(四)随机森林与GARCH模型的对比
本次案例节选了后面9期的数据作为测试集数据。
计算GARCH与随机森林模型各自的MSE后为了更加直观的看出两者的区别,画出两个模型MSE的散点图:
从图2可以得到K折交叉验证后的结果:在较短短期内,GARCH模型与随机森林模型预测能力相当;在较长期内,GARCH模型的误差显著的提高,而随机森林模型预测能力精度在提高。由此可以得到,时间期限较长的时,随机森林模型预测能力优于GARCH模型。
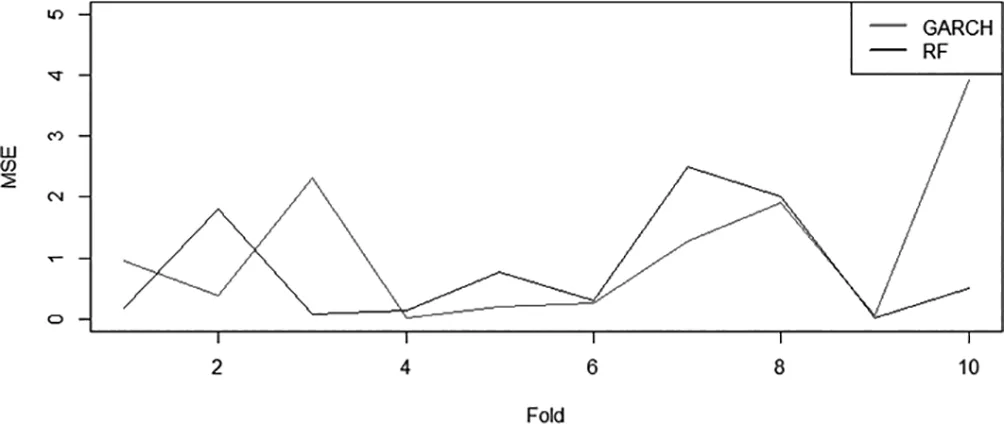
图2
猜你喜欢
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
成都信息工程大学学报(2019年3期)2019-09-25
今日农业(2019年12期)2019-08-13
中国外汇(2019年23期)2019-05-25
文学少年(原创儿童文学)(2019年1期)2019-05-23
中国化肥信息(2019年3期)2019-04-25
电子制作(2018年17期)2018-09-28
电子制作(2018年16期)2018-09-26
通信电源技术(2018年5期)2018-08-23
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
