
测量误差分析及数据处理若干要点系列论文(五)——移动平均式数据处理
2020-10-30 03:11林洪桦
自动化与信息工程 2020年5期
林洪桦
特约论文
测量误差分析及数据处理若干要点系列论文(五)——移动平均式数据处理
林洪桦
(北京理工大学,北京 100081)
移动平均式数据处理具有广泛的应用领域,不仅可作为缓变型三非性数据处理的一般方法,还可作为常量测量的数据处理方法。阐述移动平均式算法基本思想,介绍动态测试和常量测量的移动平均式算法处理方法。
数据处理;误差分析;移动平均式算法
0 引言
在前系列论文已论述,现实的测量数据多属小样本,本质上均具有三非性(非线性、非高斯、非平 稳)[1-4]。移动平均式自适应数据处理有其广泛的应用领域,不仅可作为缓变型(缓时变性或无急剧变化,如,脉冲型、阶跃型等)三非性数据处理的一般方法,还可作为常量测量(实质上长过程常量测量数据也属于缓变型)数据处理方法。总之,当样本容量较大时,任何基本算法均可运用移动平均式数据处理。
在高准确度的动态测量中,尤其是纳米级测量、长过程测量(无论变量或常量)、在线测量等都存在不易确切掌握时变统计特性的测量数据,急需具有自动显示及判别统计特性的自适应数据处理方法。以往多用各种递推算法,却存在初始滞后、拟合误差累积、数值欠稳定等问题,难以满足高准确性要求。笔者自1987年开始采用一系列移动式成批算法、移动式递推平均算法及两者结合的算法,在算法参数选择合适情况下,可克服单纯递推算法的不足。对于非急剧变化的缓变型动态测试数据处理,可取得高准确度跟踪数据时变特性的效果[5-8]。即便是应用现代智能算法,由于多基于随机性全局搜索方法,计算结果具有随机性,予以平均精确化更佳。
移动平均式算法既具有跟踪缓时变的能力,又可充分利用样本信息,并能发挥成批算法数值稳定性及移动平均精确化效应等高准确度效果,但在计算速度上略逊于递推算法或原基本算法。上世纪九十年代初,已将移动算法归纳为自适应滤波的又一类算法。因此,探讨高准确度自适应数据处理方法已成为当前测试技术关注的问题。样本容量较大或长过程的常量测量存在缓变影响因素,易被忽视,本文着重说明在常量测量中的应用。
1 移动平均式算法基本思想
经典移动平均(moving average, MA)算法具有跟踪缓时变特性的能力,将其扩展应用于基本算法(basic algorithm, BA)(也称基础算法,含成批算法、递推算法及两者结合的算法)的移动平均算法,总称为移动平均式算法(BAMA),基本设想如图1所示。

图1 BAMA基本设想
由图1可见:直接对样本数据作MA算法,对样本数据先作分段BA,再对其进行BAMA。BAMA有分段数据量和重叠数据量两个主要参数。
的选择取决于BA的数据处理目的,若要表述数据所含确定性变化规律,则该个数据中应含有其确定性变化成分的主要信息;若要表述其随机性成分,则该个数据应体现出统计特性且近似具有平稳性。通常样本数据时变特性较复杂、较剧烈时,相应地取大些,但应受限于保持接近平稳性。由于BAMA能体现过程的缓时变特性,因而在满足上述BA的数据处理目的下,宜尽量偏小选择。至于的具体值取决于BA的需求及总数据量。通常要求移动5次以上,方能体现BAMA的效果,即<5。一般要求50~100。
的选择决定了BAMA的平均效果或准确性,还需兼顾时变的连续性与移动算法的最佳速度。通常宜选得偏大些,如,10~20。
至于BA有关参数的选择,则视样本数据模型化及所选定的具体算法而异,不在此赘述。笔者将其归纳为动态测试算法和常量测量算法2种类型。动态测试算法又可分为以回归或自回归为主构成的移动平均式成批算法;以各种递推算法为主且作移动平均精确化者为移动平均式递推算法。无论何种具体算法均涉及选择或自动识别阶数(或次数、项数等)这一重要参数,且因有移动平均形式体现缓时变性而可选得尽量偏小些。常量测量主要对多数据量或长测量过程而言。常量测量样本及测量误差均有缓变因素影响,采用BAMA处理更佳。其参数选择主要取决于测量误差的类型是随机变量还是平稳过程。若属后者,则无异于移动平均式成批算法,需建自回归模型,其阶数同前选。
在BAMA具体应用中,数学模型拟定是至关重要环节,且影响BAMA参数选定。BAMA处理方法的逻辑框图如图2所示。

图2 BAMA处理方法的逻辑框图
2 动态测试的BAMA处理方法
BAMA处理方法主要应用于动态测试数据处理,可分为移动平均式成批算法和移动平均式递推算法。文献[5]~文献[10]对这些算法已有阐述,故在此仅简要略述及补充其与BAMA处理方法的有关要点。
2.1 预处理
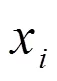

分解方法可采用MA中心平滑方法,即


2.2 时变规律性{}和随机性{}的模型化
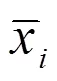

大多数现实问题应用这种线性化处理方法可满足准确度要求。仅当某些强非线性度问题不得已需采用非线性模型。总之,模型化遵从线性化优先原则。

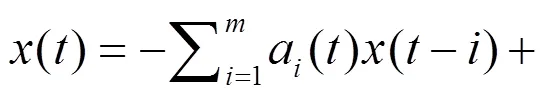

同理,随机性模型遵从线性化-平稳化优先原则。
2.3 动态测试的BAMA
动态测试的BAMA决定于对现实问题的样本数据进行模型化及最佳性原则的需求。详见文献[5]及此系列论文的论述,具体处理方法的示例可参考文献[6]~文献[10]。本文仅涉及现代数据处理方法的要点。

SVD:=ΣT,Σ= diag(1,2,…,σ,σ+1,…,σ),=+1
式中,和分别为左和右奇异矩阵;和分别为的行数和列数;1≥2≥…≥σ为的奇异值。其中大于σ者对应于显著性变量,且σ+1/1≤ 0.05或0.1即可判定阶数为;而σ+1,…,σ均对应着噪声或随机误差。如此判定阶数较为稳定、可靠。
2)时变分布统示法的应用:十多年前笔者对云南滇池某种水质指标两年的四季样本数据剔除异常数据后,做分布分段拟合(静态),估计结果分布参数有多处较剧烈变动。后改进采用BAMA处理方法(动态),估计分布参数呈平稳的缓变性。此即时变分布统示法的实际应用示例。另,由于其样本数据虽剔除异常数据后仍不时有所起伏,再改进为运用中位值滤波式BAMA处理方法将更佳。
时变分布统示法的具体BAMA处理方法,即将样本总数据量按<5分段,在数据量为分段内以本系列论文(三)中述及的分布矩估计方法为BA[3],再予以移动进行MA处理的方法。要点在于:
①简捷识别缓时变性:尽管有拟合优度检验、熵差异识别等较复杂的方法常用于概率分布检验。然而这里所需的是识别各分段分布参数(,,,)差异性的简捷方法。既然各分段的偏态-峰态系数均需估计,建议运用偏态-峰态系数差异性的识别概率分布不同的近似方法。这样兼有识别对称性而运用对称性优先原则与识别随机性分布差异性之优越性和简捷性。具体处理方法如下:
利用文献[5]中式(5.512)所得偏态-峰态系数估计的置信界限识别对称性与随机性分布差异性,即2个以上相邻分段的偏态-峰态系数估计超出此范围就视为有差异。对分布参数(,,,)需做缓时变性处理。

②若分布无时变性,在分段中按样本前四阶矩估计分布参数(,,,)时,其中(,) = (min-N,max-N)应恒按样本整体数据中的最小值和最大值估计。这样准确性、可靠性更高。同时,可用各分段分布参数(,,,)估计的均值作为其估计结果进行后续处理。显然这样可弥补按全样本数据一次估计分布参数(,,,)的不足。
③BA求解分布参数(,,,)算法探讨
求解分布参数(,,,)算法:现代BA多强调用基于全局优化随机搜索的智能化算法,求解分布参数(,,,),其结果具有随机性。样本数据量较大时,建议运用②所述具有平均效果的处理方法,以提高准确性和可靠性。若样本数据量不大,(,)不宜按数据中的最小值和最大值估计。建议按(μ,σ,3,4)与(,,,)关系的联立方程求解分布参数。
3)时变粒子滤波(PF)的应用:文献[10]中已阐述卡尔曼滤波(KF)作移动平均式处理的方法,并得出具有抑制随机误差即噪声的较显著效果;可适应缓时变性;具有平均效果等优点。然而,除计算速度略低外,还受制于高斯性。在现代数据处理中要求不能受制于线性和高斯性,显然可应用对粒子滤波(PF)作移动平均式处理的方法,即缓时变PF方法,取得上述优点。

3 常量测量的BAMA处理方法
多数据、长过程的常量测量有缓变,宜用BAMA处理,即使无缓变也具有平均效果。
示例:采用正偏态分布仿真数据作为长过程常量测量数据,如图3所示。整体数据200,取分段数据= 100,重叠数= 50(可有更佳选择),进行BAMA处理,处理结果如表1所示。对长过程常量测量数据的BAMA处理结果表明:经验证分段的相邻均值之间并无差异,即无时变性;BAMA处理方法优于一般的整体数据处理。对BAMA参数选择合适可取得更佳平均效果。还需指出,该例对重叠部分尚未作处理,显然还会有其平均效应。

图3 正偏态分布仿真数据作为长过程常量测量数据

表1 长过程常量测量数据BAMA处理方法分析
4 结语
不论何种基本算法均可运用移动平均式处理方法,可体现缓时变特性,得到平均效应,其重点在于合理设置参数()。
[1] 林洪桦.测量误差分析及数据处理若干要点系列论文(一)——现代数据处理基本观念与四字要诀[J].自动化与信息工程,2020,41(1):1-4,9.
[2] 林洪桦.测量误差分析及数据处理若干要点系列论文(二)——随机性分布统示法综论[J].自动化与信息工程,2020, 41(2):1-7.
[3] 林洪桦.测量误差分析及数据处理若干要点系列论文(三)——随机性分布统示法推荐应用[J].自动化与信息工程,2020,41(3):1-6,16.
[4] 林洪桦.测量误差分析及数据处理若干要点系列论文(四)——统计学习理论及支持向量机方法统用于形位误差评定[J].自动化与信息工程,2020,41(4):1-5.
[5] 林洪桦.动态测试数据处理[M].北京:北京理工大学出版社,1995.
[6] 林洪桦,王晓岩.应用自适应滤波抑制动态测试随机误差[J].计量学报,1992,13(3):176-183.
[7] 林洪桦,赵晓光.应用移动Marple法拟合动态测试数据的时变AR模型[J].计量学报,1994,15(2):92-98.
[8] 林洪桦,仲琇.动态测试数据自动处理方法[J].北京理工大学学报,1995,15(1): 67-74.
[9] 林洪桦.巧用移动式自适应数据处理[D].香港: Nano-metrology in Precision Engineering 精密工程中的纳米测量技术,135-138 .
[10] 林洪桦,荀烨.抑制动态测试随机误差的移动自适应滤波平均方法[C].全国现代误差理论及应用学术交流研讨会论文集,1997.
[11] 张贤达.现代信号处理[M].北京:清华大学出版社,1995.
Some Key Points of Measurement Error Analysis and Data Processing Series Papers (5)——Moving Average Data Processing
Lin Honghua
(Beijing Institute of Technology, Beijing 100081, China)
Moving average data processing has a wide range of applications. It can be used not only as a general method of data processing of slowly varying three non properties, but also as a data processing method of constant measurement. This paper expounds the basic idea of moving average algorithm and introduces the processing method of moving average algorithm for dynamic test and constant measurement.
data processing; error analysis; moving average algorithm
林洪桦,男,1932年生,教授,主要研究方向:测试误差分析及数据处理。
TP274
A
1674-2605(2020)05-0001-06
10.3969/j.issn.1674-2605.2020.05.001
猜你喜欢
——卡文迪什测定万有引力常量
农村青少年科学探究(2022年5期)2022-08-16
心理学报(2022年4期)2022-04-12
能源工程(2021年6期)2022-01-06
建材发展导向(2021年12期)2021-07-22
阅读与作文(英语初中版)(2019年11期)2019-09-10
新教育时代·教师版(2019年6期)2019-05-15
软件(2017年9期)2018-03-02
智富时代(2017年4期)2017-04-27
智富时代(2017年4期)2017-04-27
电子制作(2017年20期)2017-04-26
