
基于多池化融合与背景消除网络的跨数据集行人再识别方法
2020-11-03 06:53李艳凤张斌孙嘉陈后金朱锦雷
通信学报 2020年10期
李艳凤,张斌,孙嘉,陈后金,朱锦雷
(北京交通大学电子信息工程学院,北京 100093)
1 引言
行人再识别[1-2]用于解决非重叠视域中人员匹配的问题,是智能视频分析技术的重要组成部分,可用于追踪犯罪嫌疑人、寻找走失人员等,具有广阔的应用前景[3]。近年来,行人再识别技术获得了广泛关注,成为计算机视觉领域的研究热点。
早期的行人再识别研究主要依靠传统方法,例如手工设计特征表达[4-5]和距离度量[6-7]。得益于深度学习的快速发展,越来越多的研究者使用深度学习来解决行人再识别问题。Yi 等[8]首次将深度神经网络应用于行人再识别,采用端到端的网络联合进行特征提取与度量学习。近年来,由局部生成行人的细粒度特征方法被广泛研究,并取得了较好的性能。Yao 等[9]提出部件损失网络(PL-Net,part loss network)以同时最小化分类风险与表示学习风险。Sun 等[10]提出对特征图进行均匀分割的基于部件的卷积基线(PCB,part-based convolutional baseline)网络框架用于行人再识别,该方法将特征图均分为多个局部特征图分支,每个分支分别与行人ID 标签计算损失。实现了图像局部特征的提取,但忽略了全局特征表示。Fu 等[11]提出了水平金字塔匹配(HPM,horizontal pyramid matching)行人再识别方法。该方法同时实现了行人的全局特征和局部特征表示,在局部特征表示中进行多尺度池化,并在池化方式上,将全局特征平均池化(GAP,global average pooling)和全局特征最大池化(GMP,global max pooling)相结合,但该方法中大量的池化支路导致特征向量维度较大,需要将特征压缩后再组合,从而造成信息丢失。
在实际应用场景中,监控视频的摄像头数量是不固定的,并且会增加,因此行人再识别是一个开放性的问题,其模型应具有适应开放环境的能力。为了更加符合实际场景的应用需求,研究人员开始关注跨数据集行人再识别方法。跨数据集行人再识别的任务是将一个数据集(源数据集)上训练好的模型转移到另一个数据集(目标数据集)上进行测试,希望获得较好的识别性能。目前跨数据集行人再识别方法主要有两类,具体如下。
1) 利用迁移学习知识减小源数据集与目标数据集数据分布的差异。Qi 等[12]关注摄像机之间不同的特征分布,利用迁移学习的思想设计了基于“相机感知”的域自适应方法,以减少2 个数据集之间的数据差异。Li 等[13]利用迁移学习中的最大平均差异度量损失使源数据集与目标数据集生成相似的特征分布来缩小2 个数据集间的差异。Huang 等[14]使用部件分割约束增强模型的泛化能力,实现域自适应行人再识别。Wang 等[15]提出迁移联合属性–类别深度学习(TJ-AIDL,transferable joint attributeidentity deep learning)的行人再识别方法。该方法使用双支路网络,上支路以行人类别信息作为标签进行特征提取,下支路以属性信息作为标签进行特征提取,然后将训练好的模型迁移到目标数据集进行行人识别方法。Lin 等[16]提出多任务中级特征对齐(MMFA,multi-task mid-level feature alignment)网络实现跨数据集行人再识别。该方法基于源域与目标域共享中层特征空间的假设,使用源域–目标域中层特征对齐正则化项对网络进行优化。Zhong 等[17]提出异质–同质学习(HHL,hetero-homogeneous learning)的行人再识别方法,通过同质学习实现相机不变性,通过异质学习实现域连通性。
2) 利用生成对抗网络(GAN,generative adversarial network)将源数据集图像转换为目标数据集图像的风格进行训练。Wei 等[18]提出行人迁移生成对抗网络(PTGAN,person transfer GAN),在保证行人本体前景不变的情况下,将源域图像的背景转换成目标域图像的背景风格进行训练。Deng 等[19]设计了相似度保持生成对抗网络(SPGAN,similarity preserving GAN),在图像生成过程中添加了自相似性及域不相似性限制。Liu 等[20]提出自适应迁移网络(ATNet,adaptive transfer network)来实现跨数据集行人再识别。该方法将复杂的跨数据集迁移分为3 个子问题,然后对每个子问题分别进行风格迁移。
现有跨数据集方法一般致力于减小2 个数据集之间的数据分布差异,忽略了背景信息对识别性能的影响。Tian 等[21]研究了图像背景对行人识别性能的影响,在使用仅包含背景的行人图像进行测试时,也获得了Rank-1 为5.2%的正确率。上述研究表明将整张行人图像输入行人再识别网络中进行训练,网络在学习行人特征的同时,也会学习相应的背景特征。为降低背景信息的影响,本文提出了一种基于多池化融合与背景消除网络的跨数据集行人再识别方法,该方法通过结合多池化融合(MPF,multi-pooling fusion)网络与特征级有监督背景消除网络,有效提升跨数据集行人再识别的性能。本文的主要贡献如下:1) 构建了一种多池化融合MPF 网络结构,能够兼顾全局特征和局部特征,同时实现特征的多细粒度表示;2) 设计了一种特征级有监督背景消除网络,将该网络的特征激活损失函数与行人分类损失函数相结合为多任务学习损失,以监督网络提取有用的行人前景特征。
2 本文方法
2.1 网络结构
本文方法的网络结构如图1 所示,包括多池化融合网络和特征级有监督背景消除网络。以ResNet50 网络[22]作为主干网络,以主干网络得到的特征图为输入,构建多池化融合网络,其包含4 个分支,其中,一个为全局特征分支,其他3 个为不同区域的局部分支。全局特征分支采用2 种不同细粒度的池化,且每种细粒度分别采用GAP 和GMP这2 种池化方式;其他3 个局部分支采用一种细粒度的GAP 和GMP 池化。输出特征进行连接,得到6 个分支的特征。每个分支分别连接全连接(FC,fully connection)层用于行人分类,得到的预测结果与行人类别标签进行计算交叉熵(CE,cross entropy)损失。特征级有监督背景消除网络中,首先通过行人分割获得行人掩码,然后对主干网络的特征图进行Sigmoid 激活,并计算激活结果与行人掩码的均方误差(MSE,mean square error)损失。将CE 损失与MSE 损失之和作为本文方案的最终损失,以实现网络模型提取有用的行人前景特征。
2.2 多池化融合网络
ResNet50 网络常被用于行人再识别的主干网络,但其单一的池化结构易造成大量信息丢失。为解决这一问题,提高特征的表征能力,本文构建了多池化融合网络,其结构如图1 下半部分所示。
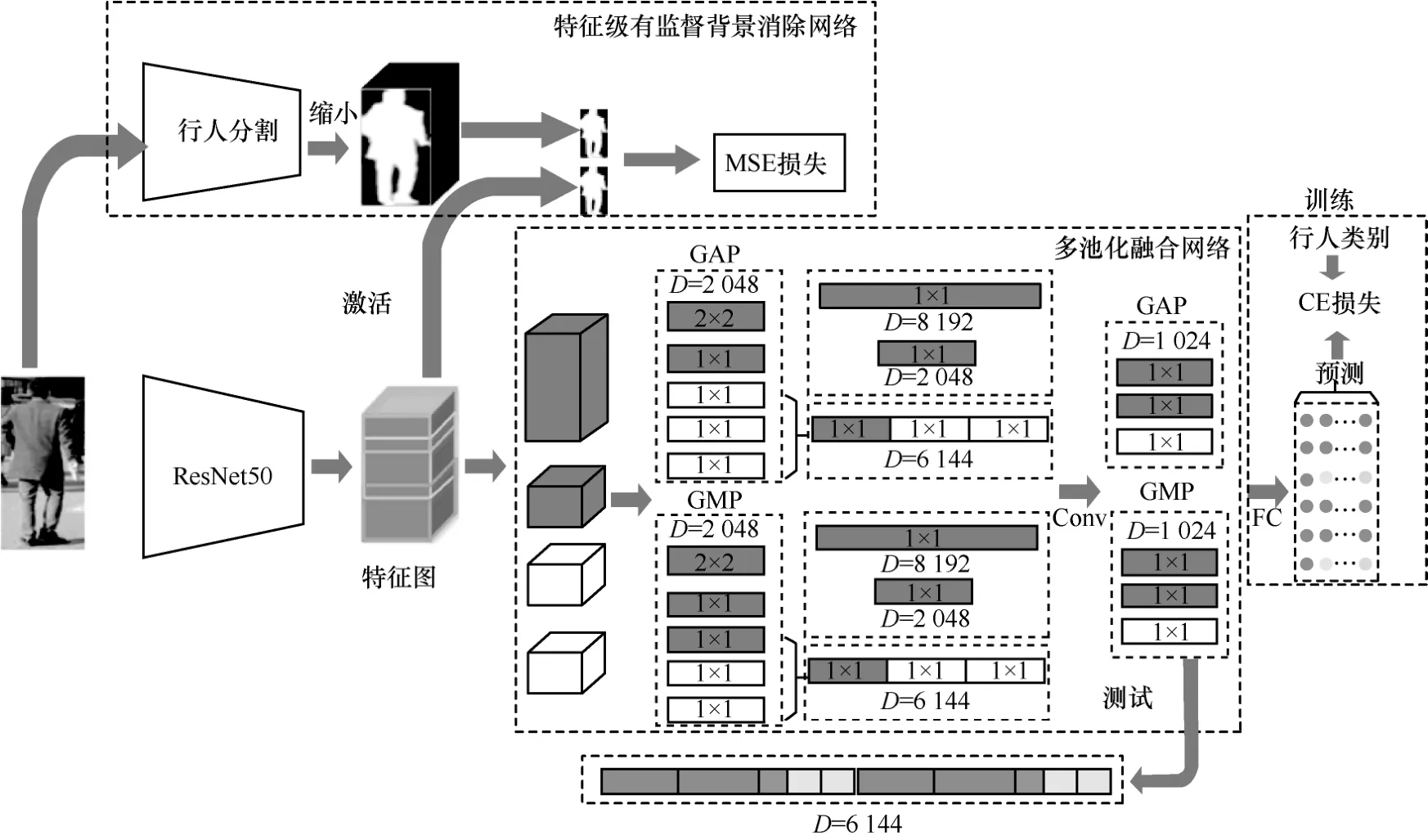
图1 网络结构
全局特征对行人进行整体性的描述,而局部特征则针对不同局部区域对行人进行描述,因此全局特征和局部特征结合可以提高特征的表征能力。行人图像通过ResNet50 网络生成的特征图被分为4个支路,一个支路为全局特征,3 个支路为不同区域的局部特征。为防止硬划分破坏局部特征之间的连续性,本文采用有重叠划分的方式来得到局部特征图,并将特征图有重叠地划分为上、中、下三部分。全局特征图和3 个局部特征图如图2 所示。

图2 全局特征图和局部特征图
不同的池化方式具有不同的特点,GMP 输出行人图像特征的最大响应点,GAP 有利于提取全局特征信息。本文融合了GAP 与GMP,有利于提升特征的表示能力,然后对4 个支路的特征图分别进行GAP 和GMP 处理。为了得到不同细粒度的特征表示,本文对全局特征图进行2 种不同尺寸的池化,宽、高、通道的尺寸分别为1×1×2 048 和2×2×20 48。因此全局特征将生成2 种池化方式、2 种池化尺寸,共4 个特征向量。对于局部特征,每个局部特征图的池化尺寸为1×1×2 048,分别采用GAP 和GMP这2 种池化方式,因此3 个局部支路共生成6 个尺寸为1×1×2 048 的特征向量。
将全局特征图池化得到的2 个尺寸为2×2×2 048的特征向量分别展开,得到2 个尺寸为1×1×8 192的特征向量。对于3 个局部特征图,将每种池化方式下的1×1×2 048 特征向量级联,形成2 个新的尺寸为1×1×6 144 的特征向量。经过上述操作后,共得到6 个特征向量(GAP 方式下的2 个全局特征向量和1 个局部特征向量,GMP 方式下的2 个全局特征向量和1 个局部特征向量)。为降低特征向量的维度,分别对6 个特征向量进行1×1 卷积,得到6 个1 024 维的特征向量。训练时,在6 个特征向量后分别连接全连接层用于分类,得到的分类结果分别与行人类别标签计算交叉熵损失,多分类交叉熵损失函数如式(1)所示。
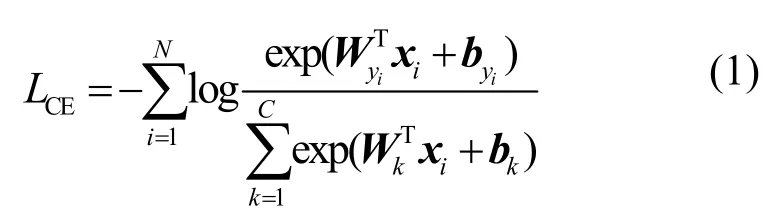
其中,i表示行人图像索引,xi表示图像Ii的特征向量,yi表示图像Ii的行人ID 号,C表示训练集中行人ID 的总数量,N表示每个批次读取行人图像的数量,{W,b}表示分类层的权重和偏置。
多池化融合网络的损失函数LID为6 个支路损失函数之和,如式(2)所示,为第j个支路的损失。

本文设计的多池化融合网络对全局特征进行不同类型和不同尺寸的池化操作,使多个特征向量与特征图建立了不同的映射关系,实现了特征的多细粒度表示。对局部特征进行不同类型的池化操作,并以全局特征和局部特征对行人进行综合表示,可有效提升特征的表征能力。
2.3 特征级有监督背景消除网络
为降低背景信息的影响,本文构建了特征级有监督背景消除网络,其结构如图1 上半部分所示。本文方法并不是完全丢弃图像的背景信息,而是使网络自动学习适当消除背景,保留前景。
为了实现“背景消除”,首先需要对行人图像进行前景分割。本文将全卷积神经网络(FCN,fully convolutional network)[23]与宏–微对抗网络(MMAN,macro-micro adversarial network)[24]结合进行前景分割。FCN 可以得到低分辨率行人图像的大致分割轮廓,但分割不精细、对细节信息不敏感;对于高分辨图像可以得到精确的分割结果,但对于低分辨率图像易造成误分割,将二者相结合可以弥补各自的不足。本文首先在行人分割数据集LIP(look into person)[25]上对MMAN 和FCN 的网络模型进行训练,然后将训练得到的网络模型分割行人再识别数据集。
为使网络自动学习弱化背景,将ResNet50 网络得到的特征图进行Sigmoid 函数激活,生成二值激活结果图,以监督特征提取网络。二值分割结果要求图像最大值接近1,最小值接近0,但直接使用Sigmoid 函数对特征进行激活,其激活结果的最大值和最小值并不接近1 和0,因此需要先对特征图进行线性拉伸。根据Sigmoid 函数自变量与值域的关系,将特征图线性拉伸[5,5]的取值范围,则Sigmoid 函数的激活结果在(0,1)范围。特征值的线性拉伸如式(3)所示。
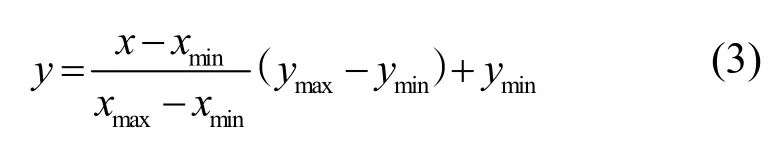
其中,x表示拉伸前的特征值,y表示拉伸后的特征值,xmax和xmin表示拉伸前特征值的最大和最小值,ymax和ymin表示拉伸后的最大和最小特征值,取值分别为ymax=5,ymin=5。将线性拉伸后的结果作为输入,经过Sigmoid 激活得到激活图。计算激活图和行人分割结果的MSE 损失,以监督网络更多地提取行人前景特征。MSE 损失LMSE计算式为
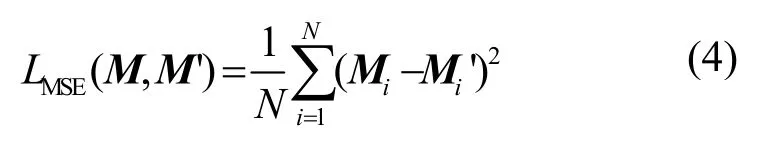
其中,Mi表示行人图像分割掩码的第i个像素点取值,表示激活图的第i个像素点取值,N表示图像像素点的数量。
将CE损失与MSE损失之和作为本文方法的总体损失,并将其作为损失函数对网络进行训练,损失函数L如式(5)所示。
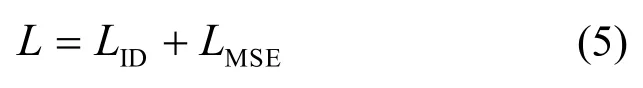
3 实验过程
3.1 数据集与评估方法
本 文 使 用 Market-1501[26]、DukeMTMCreID[27]、MSMT17[18]这3 个大规模行人再识别数据集评估本文方法的有效性。
Market-1501 数据集包含6 个摄像头拍摄得到的32 217 张固定尺寸行人图像,行人ID 数量为1 501 个。751 个行人ID 用于网络模型训练,750 个行人ID 用于测试。
DukeMTMC-ReID 数据集包含8 个摄像头拍摄得到的36 411 张多尺寸行人图像,行人ID 数量为1 404 个。训练集包含702 个行人,其余行人作为测试集。测试集中有2 228 张行人图像被选为查询图像,其余的17 661 张图像(包括702个作为测试的行人图像及408 个作为干扰的行人图像)作为候选集。
MSMT17 数据集包含15 个摄像头拍摄得到的126 441 张多尺寸行人图像,有效行人ID 数量为4 101。训练集包含1 041 个行人的32 621 张图像,测试集包含3 060 个行人的93 820 张图像。对于测试集,11 659 张图像作为查询集,其余82 161 张图像作为候选集。
使用累计匹配特性(CMC,cumulative match characteristic)和平均准确率(mAP,mean average precision)作为评价指标。CMC 曲线主要反映模型的准确率,常以Rank-n的形式表现,Rank-n表示前n个匹配结果中正确匹配的比例,本文使用Rank-1、Rank-5、Rank-10 作为参数。mAP 表示算法在全部测试数据上的平均性能,兼顾准确率和召回率。AP 是某个类别所有返回结果的平均准确率,如式(6)所示。
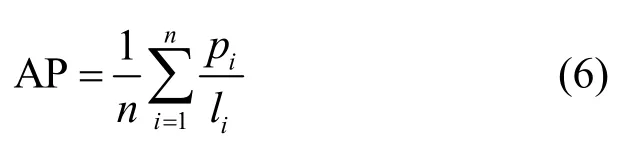
其中,pi表示第i个正确匹配的目标行人图像在查询序列中的位置,li表示第i个正确匹配的目标行人图像在候选集重新排序中的位置,n表示和查询图像正确匹配的图像个数。mAP 是所有类别AP 的平均值,如式(7)所示。
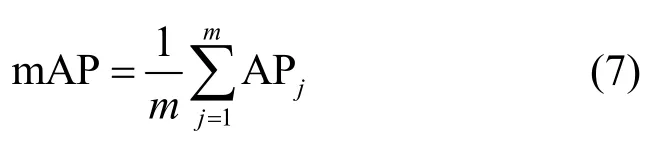
其中,m表示查询集中查询图像的总个数。
3.2 实验参数设置
实验所使用的硬件平台的CPU 为Inter Xeon E5-2620 v4,GPU 为10G NVIDIA GeForce GTX 1080Ti,使用的操作系统是Ubuntu16.04。实验使用的深度学习框架PyTorch 版本为1.01,数据处理包torchvision 版本为0.22,Python 版本为3.6,cudnn版本为8.0,cuda 版本为8.0。
训练时每个批次读取N=32 张图像,其中每个行人类别随机读取固定的图像数量。每个batch 读取8 个行人类别,每类行人的图像数量为4。使用图像随机水平翻转实现数据扩增,输入图像尺寸归一化为256×128。使用随机梯度下降(SGD,stochastic gradient descent)算法作为优化器,设置初始学习率为0.03,网络模型的训练迭代次数为60。
4 结果分析与讨论
4.1 多池化融合网络性能评价
首先对本文构建的MPF 网络的性能进行评价。为了深入分析MPF 网络相比于ResNet50 网络的性能提升,分别从兼顾全局特征和局部特征以及构建不同池化方式2 个角度进行消融实验。以G-L 网络表示兼顾全局特征和局部特征,但采用单一池化方式的方法。比较ResNet50 网络、G-L 网络和MPF网络在3 个数据集上的识别性能,如图3 所示。对于每张查询图像,展示前15 个识别结果,其中,“×”表示识别错误的行人,“√”表示识别正确的行人。由图3 可以看出,识别精度由高到低分别为MPF网络、G-L 网络、ResNet50 网络。
ResNet50 网络、G-L 网络和MPF 网络的定量实验结果如表1 所示。在3 个数据集中,G-L 网络的识别性能均明显优于 ResNet50 网络,Market-1501 数据集上的mAP 和Rank-1 分别提升了7.42%和5.57%,DukeMTMC-reID 数据集上的mAP 和Rank-1 分别提升了6.87%和4.24%,MSMT17 数据集上的Rank-1 和mAP 分别提升了5.15%和3.76%。实验结果表明,在特征提取时兼顾全局特征和局部特征可以提升行人再识别的性能。相较于G-L 网络,MPF 网络可进一步提升识别性能,在Market-1501 数据集上Rank-1 和mAP分别提升了3.93%和8.17%,在DukeMTMC-reID数据集上Rank-1 和mAP 分别提升了5.04%和7.19%,在MSMT17 数据集上Rank-1 和mAP 分别提升了6.07%和6.27%。因此在特征提取时采用不同的池化方式是有效的。MPF 网络结合了全局特征和局部特征且构建了不同的池化方式,从而可以提取更多的有用信息,相比于ResNet50 网络明显提升了行人再识别性能。

图3 ResNet50 网络、G-L 网络、MPF 网络在3 个数据集上的识别结果对比
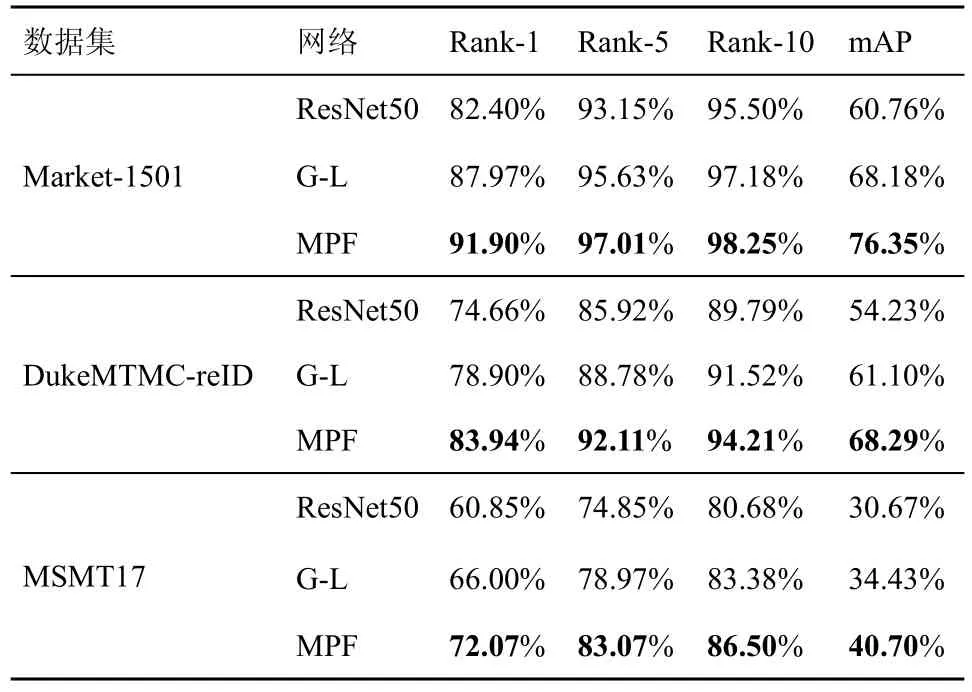
表1 MPF 网络消融实验
4.2 行人前景分割性能分析
本节比较FCN、MMAN 和本文采用的FCN 与MMAN 相结合的行人前景分割性能,分割结果示例如图4 所示。从图4 可以看出,在低分辨率图像中(图4 的前两列),MMAN 存在分割不完整的情况。对于行人前景与背景对比度较低的高分辨图像(图4 的后两列),FCN 存在分割不完整的情况。将FCN 与MMAN 结合,获得了更完整的行人前景。由于行人再识别数据集没有行人前景分割的标准,且本文主要目标是提升跨数据集行人再识别的性能,因此未对行人前景分割进行定量评价。
4.3 背景消除的跨数据集行人再识别性能评价
本文方法的总体损失(total loss)函数为CE 损失与MSE 损失之和。MSMT17 数据集下,本文方法在训练过程中的CE loss、MSE loss 和total loss 如图5 所示。由图5 可知,随着训练过程的进行,CE loss、MSE loss 和total loss 逐渐降低。

图4 行人前景分割结果
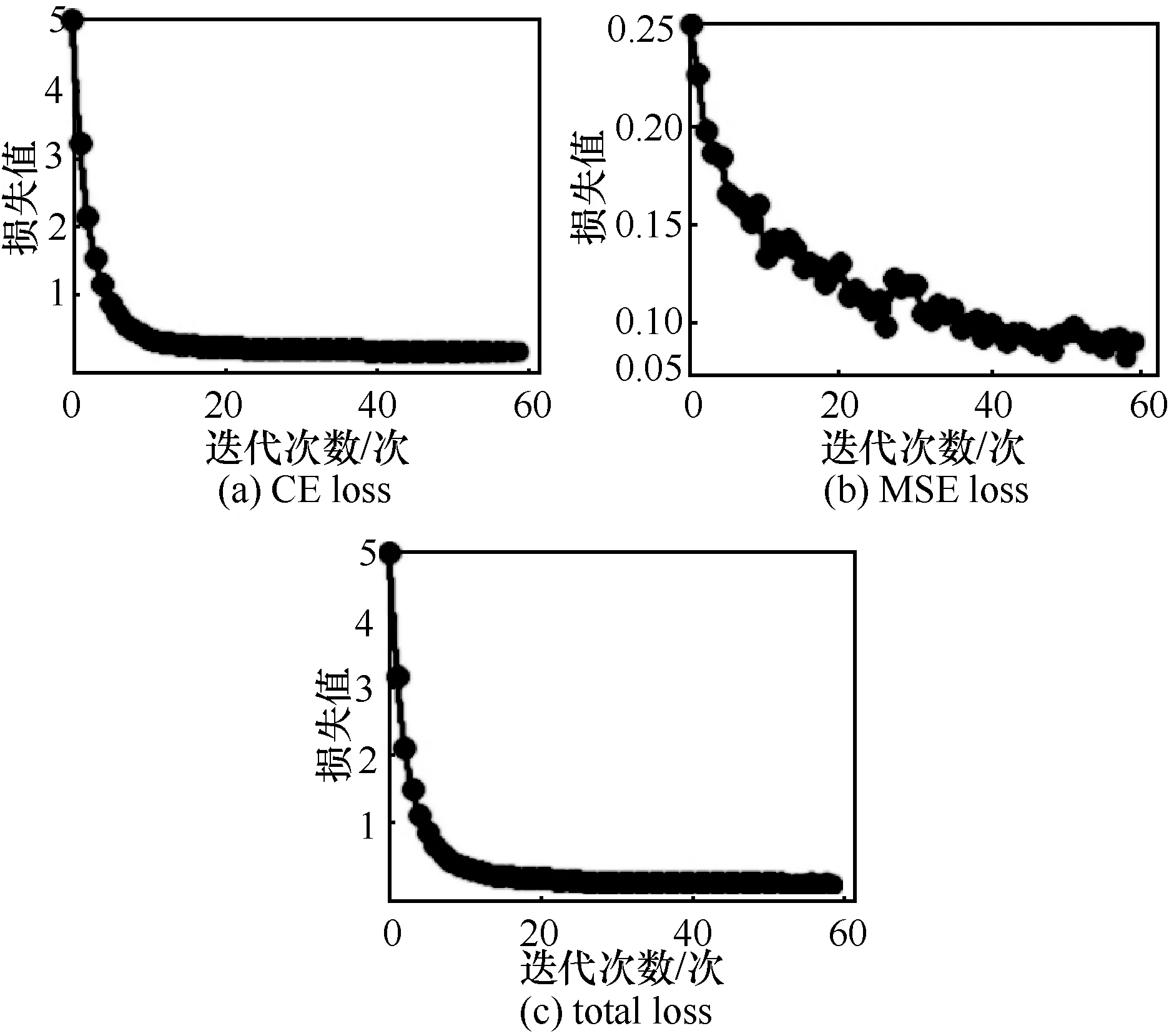
图5 MSMT17 的训练损失函数曲线
本节首先对特征图激活是否可以引导网络自动学习弱化背景信息进行定性分析。图6 为融合特征激活损失函数后主干网络得到的特征图。从图6可以看出,主干网络提取到的特征图主要关注前景的部分区域,背景区域特征图的取值很低,且不同图像背景信息的弱化是自适应的。

图6 融合特征激活损失后的特征图
然后对本文方法的跨数据集识别性能进行验证。为了深入分析MPF 网络和特征级有监督背景消除网络对性能的提升,进行如下消融实验。以MPF 网络表示仅使用MPF 网络,以MPF+背景消除网络表示使用本文方法,将上述方法与ResNet50网络进行比较。图7 和图8 给出了MSMT17 数据集作为训练集,测试集分别为 Market-1501 和DukeMTMC-reID 数据集的跨数据集行人再识别结果。可以看出,MPF+背景消除网络具有更高的识别精度。

图7 MSMT17→Market-1501 跨数据集识别结果对比

图8 MSMT17→DukeMTMC-reID 跨数据集识别结果对比
定量实验结果如表2~表4 所示。可以看出,在3 个数据集中,MPF 网络的跨数据集识别性能均明显优于ResNet50 网络,说明MPF 网络可以提升跨数据集行人再识别的性能。相较于MPF 网络,MPF+背景消除网络可进一步提升行人再识别的性能。当采用 Market-1501 作为测试集,DukeMTMC-reID 和MSMT17 作为训练集时,相比于MPF 网络,MPF+背景消除网络的mAP 和Rank-1分别提升了2.68%/4.37%、3.31%/5.52%。当采用DukeMTMC-reID 作为测试集,Market-1501 数据集和MSMT17 作为训练集时,MPF+背景消除网络的mAP/Rank-1分别提升了6.09%/12.52% 和4.48%/4.82%。当采用MSMT17 数据集作为测试集,Market-1501 数据集和DukeMTMC-reID 数据集作为训练集时,MPF+背景消除网络的mAP/Rank-1分别提升了2.89%/ 8.88%和3.83%/9.30%。实验结果说明,添加特征级有监督背景消除网络后,跨数据集行人再识别的性能得到了提升,表明构建的有监督背景消除网络的有效性。
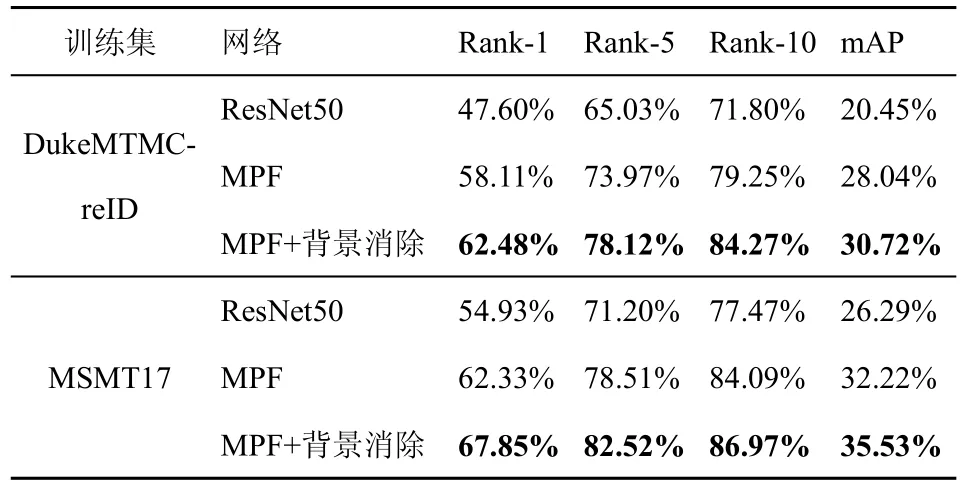
表2 Market-1501 的跨数据集再识别结果
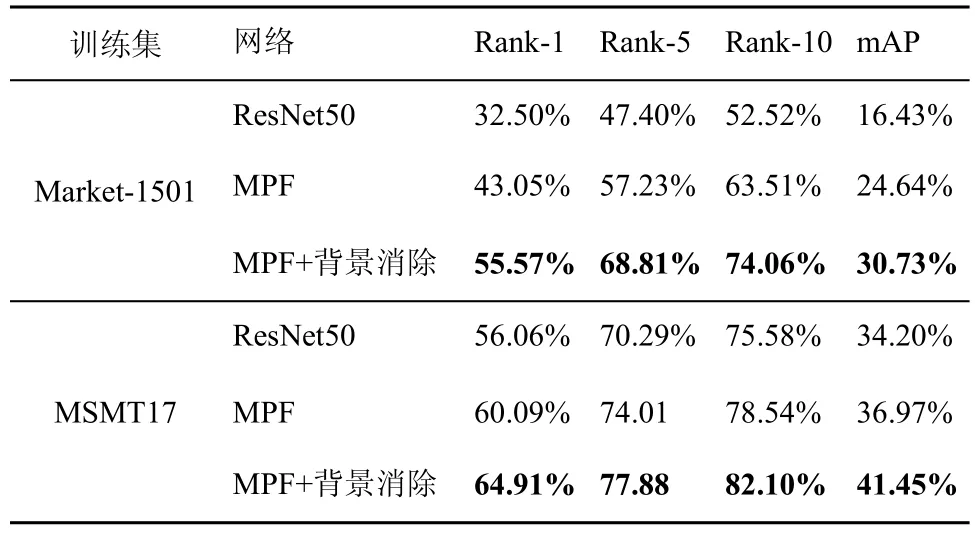
表3 DukeMTMC-reID 的跨数据集再识别结果
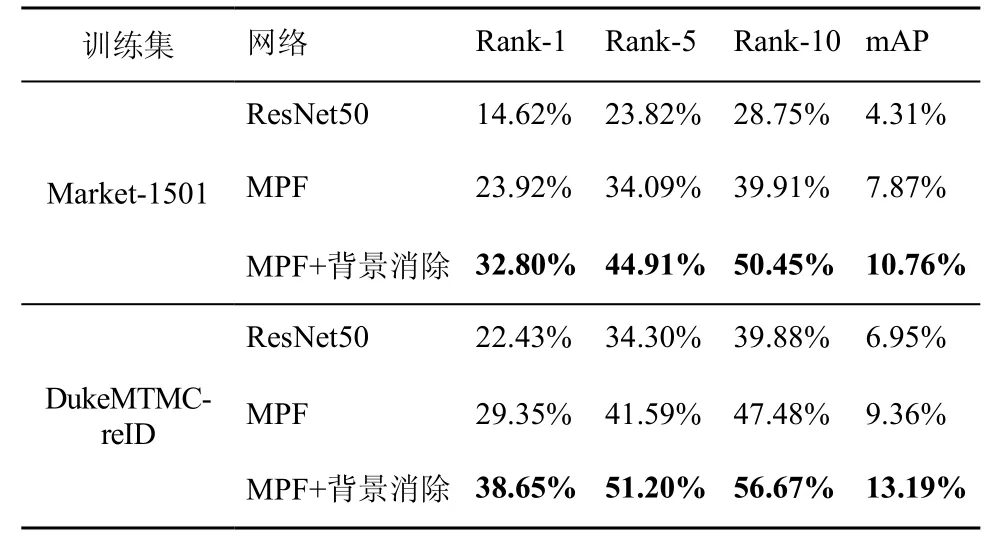
表4 MSMT17 的跨数据集再识别结果
最后对ResNet50 网络、MPF 网络和MPF+背景消除网络的训练时间进行比较,如表5 所示。MPF网络采用了多池化融合,其训练时间较ResNet50 网络明显有所增加。MPF+背景消除网络结合了MPF 网络与有监督背景消除网络,其训练时间进一步增加。

表5 不同数据集的训练时间
4.4 与现有跨数据集方法的性能比较
由于MSMT17 是行人再识别数据集,目前使用MSMT17 进行跨数据集实验的方法较少,因此本文仅使用Market-1501 数据集和DukeMTMCreID 数据集与现有跨数据集方法进行比较。表6 给出了训练集为 Market-1501 数据集,测试集为DukeMTMC-reID 的跨数据集对比结果;表7 给出了训练集为DukeMTMC-reID,测试集为Market-1501 的跨数据集对比结果;由表6 和表7 可以看出,在DukeMTMC-reID 数据集上测试时,MPF+背景消除网络的Rank-1 和mAP 分别达到了55.57%和30.73%,比现有性能最好的HHL 方法性能提升了8.67%和3.53%。在Market-1501 数据集上测试时,MPF+背景消除网络的Rank-1 和mAP 分别达到了62.48%和30.72%,与现有性能最好的HHL 方法持平。
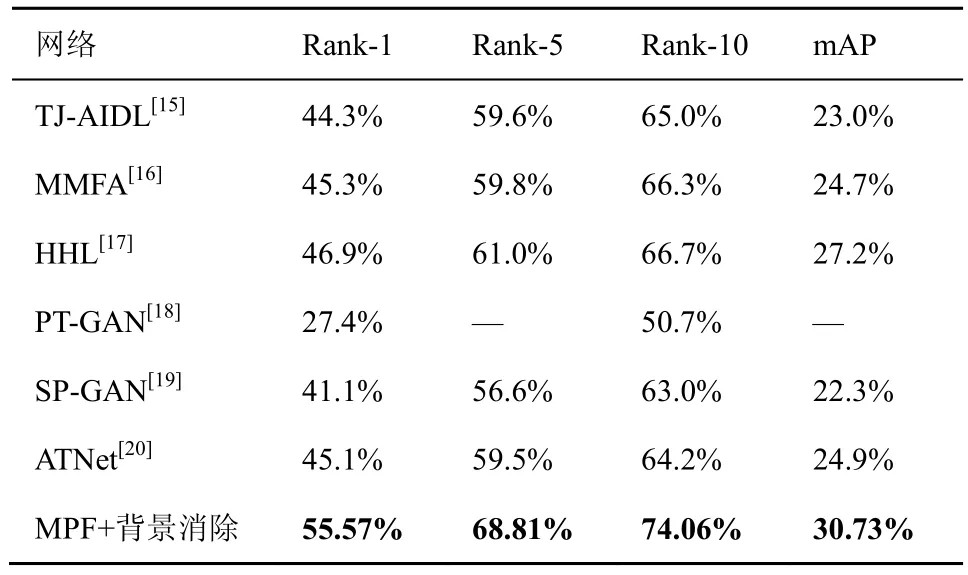
表6 Market-1501→DukeMTMC-reID 的跨数据集结果对比
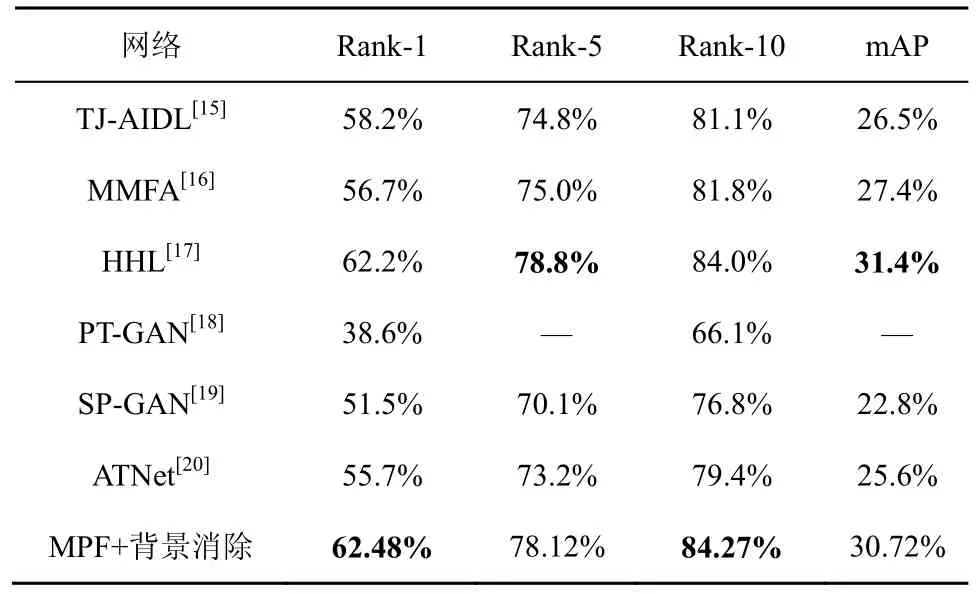
表7 DukeMTMC-reID→Market-1501 的跨数据集结果对比
5 结束语
为减弱背景信息对跨数据集行人再识别性能的影响,本文提出了结合多池化融合与背景消除网络的跨数据集行人再识别方法。本文构建的多池化融合网络兼顾了全局特征和局部特征,同时实现了特征的多细粒度表示,增加了特征向量的复杂性和多样性。构建了特征级有监督背景消除网络,结合该网络得到的特征激活损失与行人分类损失共同训练识别网络,减弱了背景信息对识别性能的影响。在 3 个行人再识别数据集 Market-1501、DukeMTMC-reID、MSMT17 上对本文方法进行评估,实验结果表明,本文方法能有效提升跨数据集行人再识别性能。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
计算机应用(2022年9期)2022-09-25
北京航空航天大学学报(2022年8期)2022-08-31
保定学院学报(2022年2期)2022-04-07
软件导刊(2022年3期)2022-03-25
计算机技术与发展(2019年1期)2019-01-21
数学学习与研究(2018年15期)2018-11-12
金桥(2018年4期)2018-09-26
智能计算机与应用(2018年2期)2018-05-23
